 夜雨聆风
夜雨聆风





开源免费用!WPS 多维表格 AirScript 影刀指令合集,百万数据查询仅 10 分 35 秒
一、前言
WPS 多维表格 AirScript 作为国产轻量化高效自动化接口,完美适配影刀 RPA 自动化流程,全套覆盖数据查询、新增、批量新增、数据更新、批量删除、图片文件获取六大业务场景,对应影刀标准化流程:
二、WPS AirScript 多维表格核心指令
AirScript 是 WPS 多维表格专属在线脚本引擎,兼容标准 JS 语法,配套影刀 Python 封装 SDK,一站式搞定多维表全流程自动化。
1. 多维表格核心业务指令
-
记录全量 CRUD:单条 / 批量新增、多条件筛选查询、更新、删除多维表数据
-
智能分页拉取:超大数据集自动分段循环查询,避免接口超时、页面卡顿
-
跨字段关联联动:多表数据自动匹配、汇总计算、实时同步
2. 高级拓展指令
-
云文档互通:跨多维表格、跨文档数据调用、文件归档管理
-
HTTP 网络请求:对接第三方系统、Webhook 双向数据流转
-
自动化触发:定时任务、事件触发脚本,无人值守批量处理数据
-
附件图片管理:Base64 上传图片、获取文件永久下载链接
三、WPS VS 钉钉 & 飞书:三大碾压级核心优势
1. 接口永久免费,无额度、无会员门槛
-
WPS 多维表格:AirScript 开放接口全免费使用,不限调用次数、不限数据量级,个人 / 企业均可零成本对接集成
-
飞书多维表格:高级 API、批量接口、Webhook 联动必须开通 VIP 付费,免费版严格限制接口频次与数据权限
-
钉钉多维表格:接口权限单独付费申请,免费版仅基础读写功能,大数据批量接口全面收费
2. 毫秒级极速响应,低延迟高并发不卡顿
WPS 自研分布式高性能引擎,日常接口响应极低,千级并发、多人协同依旧流畅不锁表。
钉钉、飞书同等数据规模下,接口响应延迟更高,频繁批量调用极易卡顿、请求超时。
3. 百万级大数据超强算力,实测仅 10 分 35 秒
同等百万行海量业务数据,WPS AirScript 获取百万数据仅耗时 10 分 35
秒钉钉单表数据行数硬性上限极低,大数据处理严重受限;飞书百万数据处理耗时远高于 WPS,成本更高、稳定性更差。
WPS AirScript VS 钉钉 / 飞书多维表格核心优势
-
零成本永久免费
WPS 全量 AirScript 接口无调用次数限制、无数据量级门槛、无需开通付费 VIP;钉钉 / 飞书批量大数据、高级筛选、Webhook 联动全部单独收费,免费版严重限流限数据。
-
接口响应极速低延迟
原生分布式引擎,日常接口毫秒级响应,高并发调用不卡顿、不超时,远优于钉钉飞书高延迟接口。
-
百万数据超强算力
同等百万行全量业务数据,WPS 分页遍历全流程仅10 分 35 秒;钉钉单表行数硬性上限极低,飞书大数据处理耗时翻倍、极易接口崩溃。
-
影刀深度适配
完美匹配影刀 RPA 全流程自动化,6 大标准化 flow 模块开箱即用,不用二次开发即可落地企业全场景数据自动化。
WPS 多维表格 AirScript × 影刀 RPA 全套 Python 调用使用说明
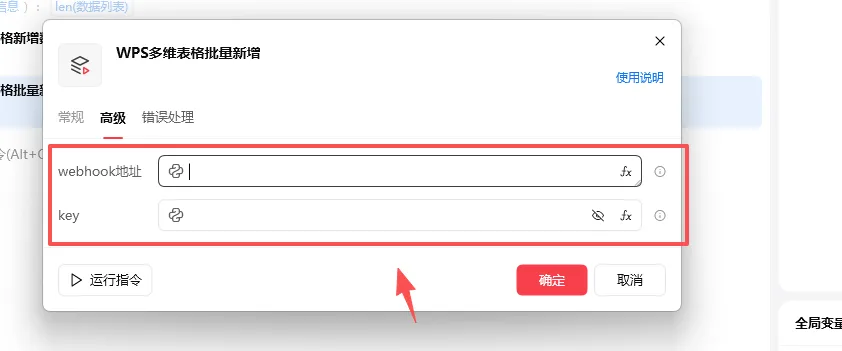
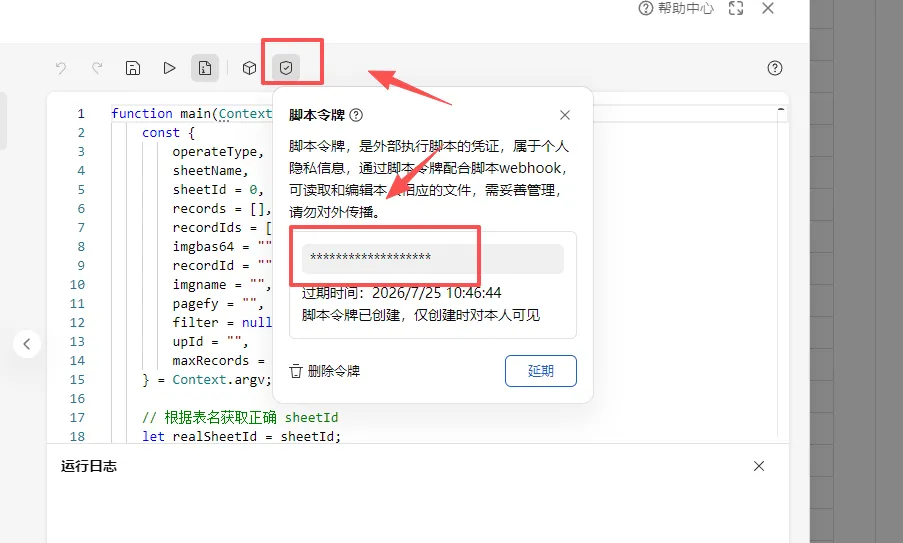
每个自定义指令都要两个参数
webhook地址
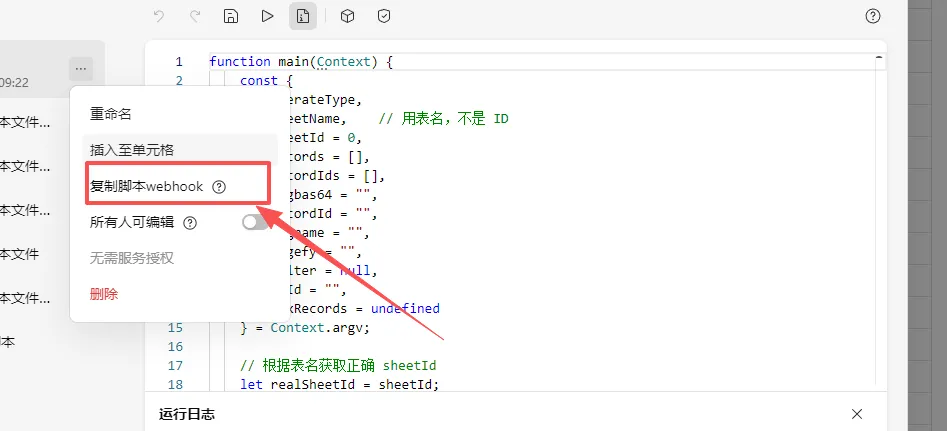
key密钥地址
WPS 多维表格查询数据.flow
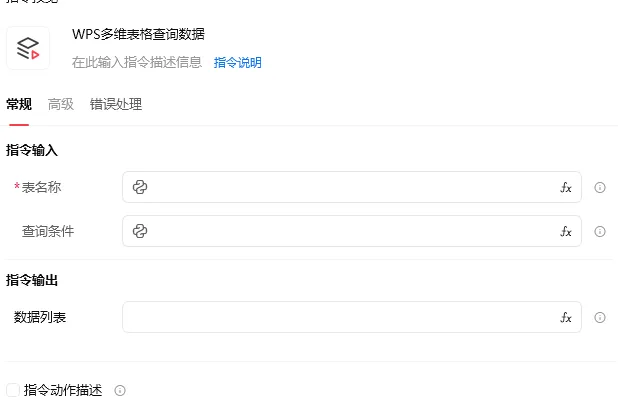
查询条件就是数据表筛选格式如下
[(“字段1″,”条件”,”条件内容”),(“字段2″,”条件2″,”条件2内容”)]
条件包含一下
等于
不等于
大于
大于等于
小于
小于等于
介于取等
介于不等
开头是
结尾是
包含
不包含
指定值
为空
不为空
案例展示:
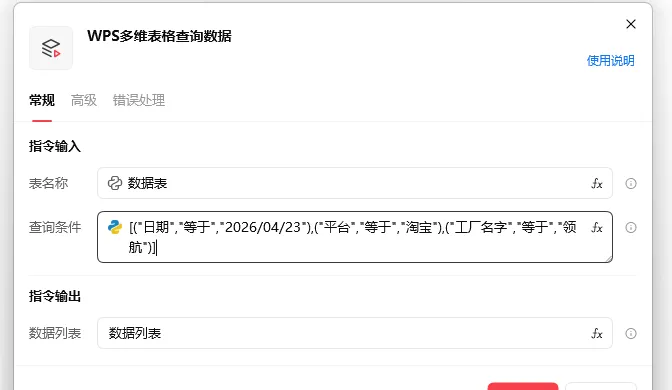
[(“日期”,”等于”,”2026/04/23″),(“平台”,”等于”,”淘宝”),(“工厂名字”,”等于”,”领航”)]
获取数据表名称 日期字段为2026/04/23和平台为淘宝,工厂名称为领行的数据
WPS 多维表格更新数据.flow
先要获取修改数据的id可以通过查询筛选拿到
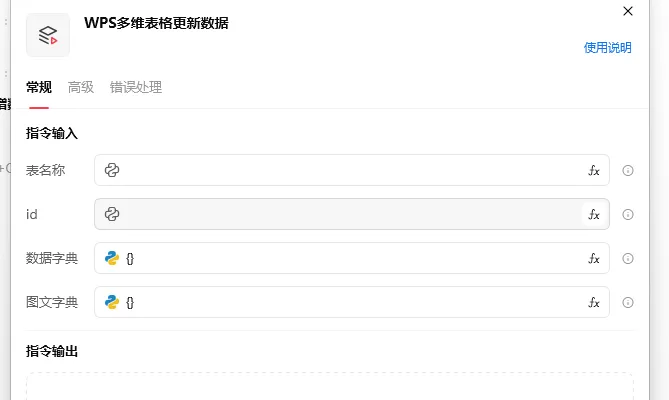
数据字典:{“字段名称”:”字段内容”,”字段名称1″:”字段内容1″}
图文字典: {“文件字段名称”:”文件路径地址”,”文件字段名称1″:”文件路径地址1″}
WPS 多维表格获取图片或文件.flow
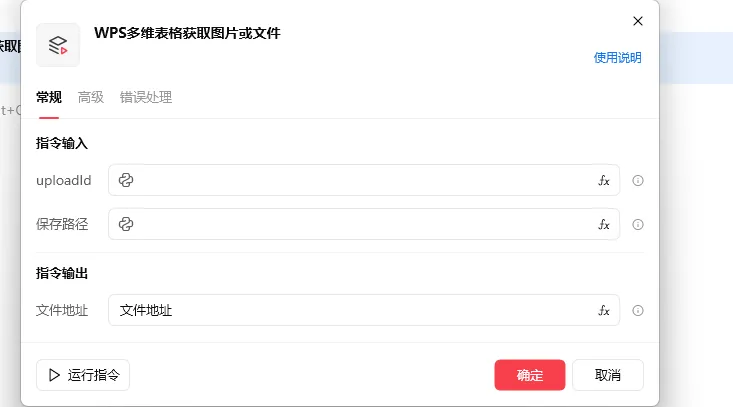
uploaid 可从查询数据源获取图片获取
WPS 多维表格批量删除.flow
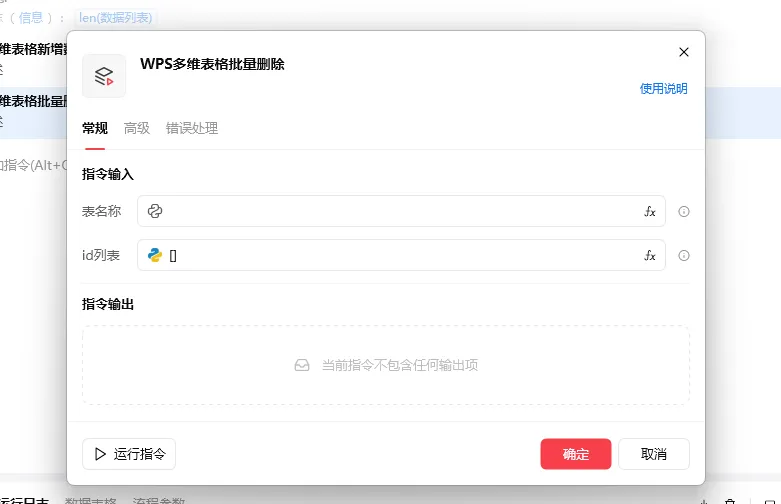
通过查询数据拿到要删除的id列表实现批量删除
WPS 多维表格批量新增.flow
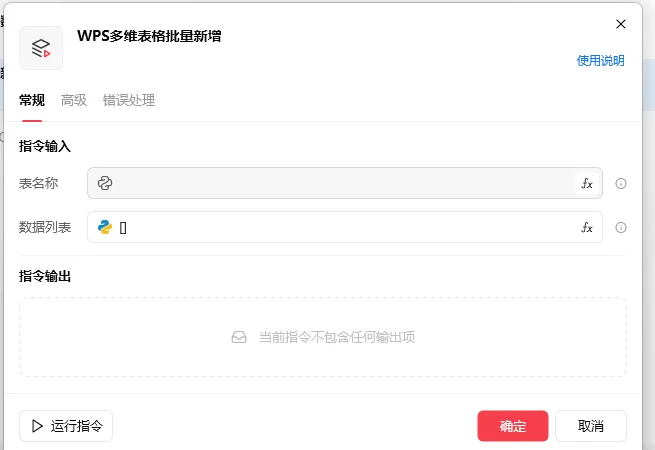
数据列表 批量上传数据字典即可
WPS 多维表格新增数据.flow
数据字典和图文字典和更新一致,数据字典为必填项,图文字典需要上传图片填写不上传图片不填写
对比钉钉、飞书多维表格接口,WPS AirScript接口永久免费无额度限制、响应速度更快、百万级海量数据处理实测仅需 10 分 35 秒,零成本即可实现企业全流程数据自动化对接。
js代码
function main(Context) {const {operateType,sheetName, // 用表名,不是 IDsheetId = 0,records = [],recordIds = [],imgbas64 = "",recordId = "",imgname = "",pagefy = "",filter = null,upId = "",maxRecords = undefined} = Context.argv;// 根据表名获取正确 sheetIdlet realSheetId = sheetId;if (sheetName) {const allSheets = Application.Sheet.GetSheets();for (let i = 0; i < allSheets.length; i++) {const s = allSheets[i];if (s.name.trim() === sheetName.trim()) {realSheetId = s.id;break;}}}// 只新增:根据表名获取索引function getSheetIndexByName(name){const sheets = Application.Sheet.GetSheets();for(let i=0;i<sheets.length;i++){if(sheets[i].name.trim() === name.trim()){return i+1; // 索引从1开始}}return 1;}if (operateType === "query") {function fetchAllRecords() {let allRecords = [];let offset = pagefy ? pagefy : null;let pageCount = 0; // 计数,控制每次只查3页// 最多查2页就停止,防止超时while ((allRecords.length === 0 || offset) && pageCount < 2) {const queryParams = {SheetId: realSheetId,Offset: offset,PageSize: 1000, // 严格遵守最大1000,不动!MaxRecords: maxRecords};if (filter) queryParams.Filter = filter;if (!maxRecords) delete queryParams.MaxRecords;const recordsResult = Application.Record.GetRecords(queryParams);offset = recordsResult.offset;allRecords = allRecords.concat(recordsResult.records);pageCount++; // 页数+1if (!offset) break;}// 返回当前查到的所有数据 + 下一页offset,给Python继续拉return [offset, allRecords];}return fetchAllRecords();}// 上传图片(只修改这里:使用索引)其他完全不动if (operateType === "ym") {return Application.Sheets(getSheetIndexByName(sheetName)).Views(1).RecordRange(recordId, `@${imgname}`).Value = Application.DBCellValue([{fileData: imgbas64,fileName: `${recordId}.png`}]);}// 获取图片下载地址if (operateType === "xz") {return Application.Record.GetAttachmentURL({UploadId: upId,Source: "upload_ks3"});}// 新建if (operateType === "create") {return Application.Record.CreateRecords({SheetId: realSheetId,Records: records});}// 删除if (operateType === "delete") {return Application.Record.DeleteRecords({SheetId: realSheetId,RecordIds: recordIds});}// 更新if (operateType === "update") {return Application.Record.UpdateRecords({SheetId: realSheetId,Records: [{id: recordId,fields: records[0].fields}]});}throw new Error("不支持的操作类型:" + operateType);}return main(Context);
pythonimport xbotfrom xbot import print, sleepfrom . import packagefrom .package import variables as glvimport requestsimport base64import asyncioimport aiohttp# ======================== 中文条件映射(官方标准) ========================CONDITION_MAP = {"等于": "Equals","不等于": "NotEqu","大于": "Greater","大于等于": "GreaterEqu","小于": "Less","小于等于": "LessEqu","介于取等": "GreaterEquAndLessEqu","介于不等": "LessOrGreater","开头是": "BeginWith","结尾是": "EndWith","包含": "Contains","不包含": "NotContains","指定值": "Intersected","为空": "Empty","不为空": "NotEmpty"}# ======================== 同步统一请求 ========================def request_api(api_url, api_token, op_type, argv_data):HEADERS = {"Content-Type": "application/json","AirScript-Token": api_token}res = requests.post(api_url,json={"Context": {"argv": {"operateType": op_type, **argv_data}}},headers=HEADERS)result = res.json()data = result.get("data", {})err = result.get("error", "").strip()res_data = data.get("result")if res_data is None or err:if err != "运行超时":if err:raise Exception(err)return res_data# ======================== 异步高性能请求(大数据提速专用) ========================async def _async_request_api(session, api_url, api_token, op_type, argv_data):HEADERS = {"Content-Type": "application/json","AirScript-Token": api_token}async with session.post(api_url,json={"Context": {"argv": {"operateType": op_type, **argv_data}}},headers=HEADERS) as resp:result = await resp.json()data = result.get("data", {})err = result.get("error", "").strip()res_data = data.get("result")if res_data is None or err:if err != "运行超时":if err:raise Exception(err)return res_data# ======================== 全表数据查询(自动分页循环) ========================def query_all(api_url, api_token, sheet_name):async def run():all_data = []page = ""async with aiohttp.ClientSession() as session:while True:res = await _async_request_api(session, api_url, api_token, "query",{"sheetName": sheet_name, "pagefy": page})offset, records = resall_data += recordsif not offset:breakpage = offsetreturn all_datareturn asyncio.run(run())# ======================== 单条件筛选查询 ========================def query_filter(api_url, api_token, sheet_name, field, cn_op, value):op_en = CONDITION_MAP[cn_op]filters = {"mode": "AND","criteria": [{"field": field, "op": op_en, "values": [value]}]}async def run():all_data = []page = ""async with aiohttp.ClientSession() as session:while True:res = await _async_request_api(session, api_url, api_token, "query", {"sheetName": sheet_name,"pagefy": page,"filter": filters})offset, records = resall_data += recordsif not offset:breakpage = offsetreturn all_datareturn asyncio.run(run())# ======================== 多条件组合筛选查询 ========================def query_filter_multi(api_url, api_token, sheet_name, conditions, mode="AND"):criteria = []filters = {}if conditions:if len(conditions) != 0:for field, cn_op, value in conditions:op_en = CONDITION_MAP[cn_op]criteria.append({"field": field, "op": op_en, "values": [value]})filters = {"mode": mode, "criteria": criteria}async def run():all_data = []page = ""async with aiohttp.ClientSession() as session:while True:res = await _async_request_api(session, api_url, api_token, "query", {"sheetName": sheet_name,"pagefy": page,"filter": filters})offset, records = resall_data += recordsif not offset:breakpage = offsetreturn all_datareturn asyncio.run(run())# 单条新增数据def create_data(api_url, api_token, sheet_name, fields):return request_api(api_url, api_token, "create", {"sheetName": sheet_name,"records": [{"fields": fields}]})# 批量新增海量数据def batch_create(api_url, api_token, sheet_name, records_list):formatted_records = [{"fields": item} for item in records_list]return request_api(api_url, api_token, "create", {"sheetName": sheet_name,"records": formatted_records})# 更新单行数据def update_data(api_url, api_token, sheet_name, record_id, fields):return request_api(api_url, api_token, "update", {"sheetName": sheet_name,"recordId": record_id,"records": [{"fields": fields}]})# 单条删除def delete_data(api_url, api_token, sheet_name, record_id):return request_api(api_url, api_token, "delete", {"sheetName": sheet_name, "recordIds": [record_id]})# 批量删除多行数据def batch_delete(api_url, api_token, sheet_name, record_ids):return request_api(api_url, api_token, "delete", {"sheetName": sheet_name,"recordIds": record_ids})# 上传本地图片至多维表格def upload_img(api_url, api_token, sheet_name, record_id, field_name, img_path):with open(img_path, "rb") as f:b64 = base64.b64encode(f.read()).decode()return request_api(api_url, api_token, "ym", {"sheetName": sheet_name,"recordId": record_id,"imgname": field_name,"imgbas64": f"data:image/png;base64,{b64}"})# 获取图片文件下载地址def get_image_url(api_url, api_token, sheet_name, upload_id, source="upload_ks3"):return request_api(api_url, api_token, "xz", {"sheetName": sheet_name,"upId": upload_id,"source": source})# 新增数据同时附带多张图片def create_with_imgs(api_url, api_token, sheet_name, fields, img_dict):rid = create_data(api_url, api_token, sheet_name, fields)[0]["id"]for field, path in img_dict.items():for i in range(3):try:upload_img(api_url, api_token, sheet_name, rid, field, path)breakexcept Exception as e:pass# 更新数据同时替换多张附件图片def update_with_imgs(api_url, api_token, sheet_name, rid, fields, img_dict):update_data(api_url, api_token, sheet_name, rid, fields)for field, path in img_dict.items():for i in range(3):try:upload_img(api_url, api_token, sheet_name, rid, field, path)breakexcept Exception as e:pass# ===================== 实战调用示例 =====================def main(args):# 读取影刀全局变量配置API_URL = glv["hook"]API_TOKEN = glv["密钥"]# 多条件筛选:查询所有带有图片附件的数据conditions = [("图片和附件", "不等于", ""),]data = query_filter_multi(API_URL, API_TOKEN, "测试", conditions, mode="AND")print([i["fields"]["图片和附件"][0]["uploadId"] for i in data])print(get_image_url(API_URL, API_TOKEN, "测试", [i["fields"]["图片和附件"][0]["uploadId"] for i in data][1]))