 夜雨聆风
夜雨聆风





4月24日AI日报|4K高清AI视频一键生成,可灵开放4K模式!DeepSeek-V4与Open GPT-5.5齐上场!腾讯混元Hy3 preview 开源!
AI资讯要点
【要闻筛选】
- OpenAI :发布 GPT-5.5 和 GPT-5.5 Pro 模型
- DeepSeek-V4 :全新系列模型发布并开源,包括高性能的 V4‑Pro 与更轻量的 V4‑Flash 两款模型
其他AI资讯
【AI 创作】
- 可灵 :开放 4K 模式,AI 视频进入原生 4K 时代
【AI 应用/模型】
- Codex:支持 GPT-5.5,实现五大能力升级
- 腾讯:混元 Hy3 preview 语言模型发布并开源
- Claude:宣布 Managed Agents 内置记忆功能开启公开测试
- Google:在 Gemini 上线对话分支功能(部分用户推送)
- Claude:扩展 Connectors,新增 15 款日常应用
- 蚂蚁百灵: 发布 Ling-2.6-1T 模型,提供试用并计划开源
👇进群,不错过每日最新AI资讯噢~


💡主要内容
OpenAI :发布 GPT-5.5 和 GPT-5.5 Pro 模型
OpenAI 发布其迄今为止最强大的 Agent 编码模型 GPT-5.5,以及更高级的 GPT-5.5 Pro 模型。GPT‑5.5 擅长撰写和调试代码、在线研究、分析数据、创建文档/电子表格,并能操作软件、在多工具之间切换直至完成任务。
此次模型在不牺牲速度的前提下,实现了智能水平的显著提升,尤其在智能编码、计算机使用、知识工作和早期科学研究等领域表现突出。

- 性能卓越:
GPT-5.5 是 OpenAI 迄今为止最强大的 Agent 编码模型。在 Terminal-Bench 2.0 评测中,其准确率达到 82.7%,在 SWE-Bench Pro 中,其端到端解决任务的比例达到 58.6%,并且在 Expert-SWE 上的表现也超越了 GPT-5.4。GPT-5.5 在所有三项评估中都比 GPT-5.4 有所提升,同时使用了更少的 token 。
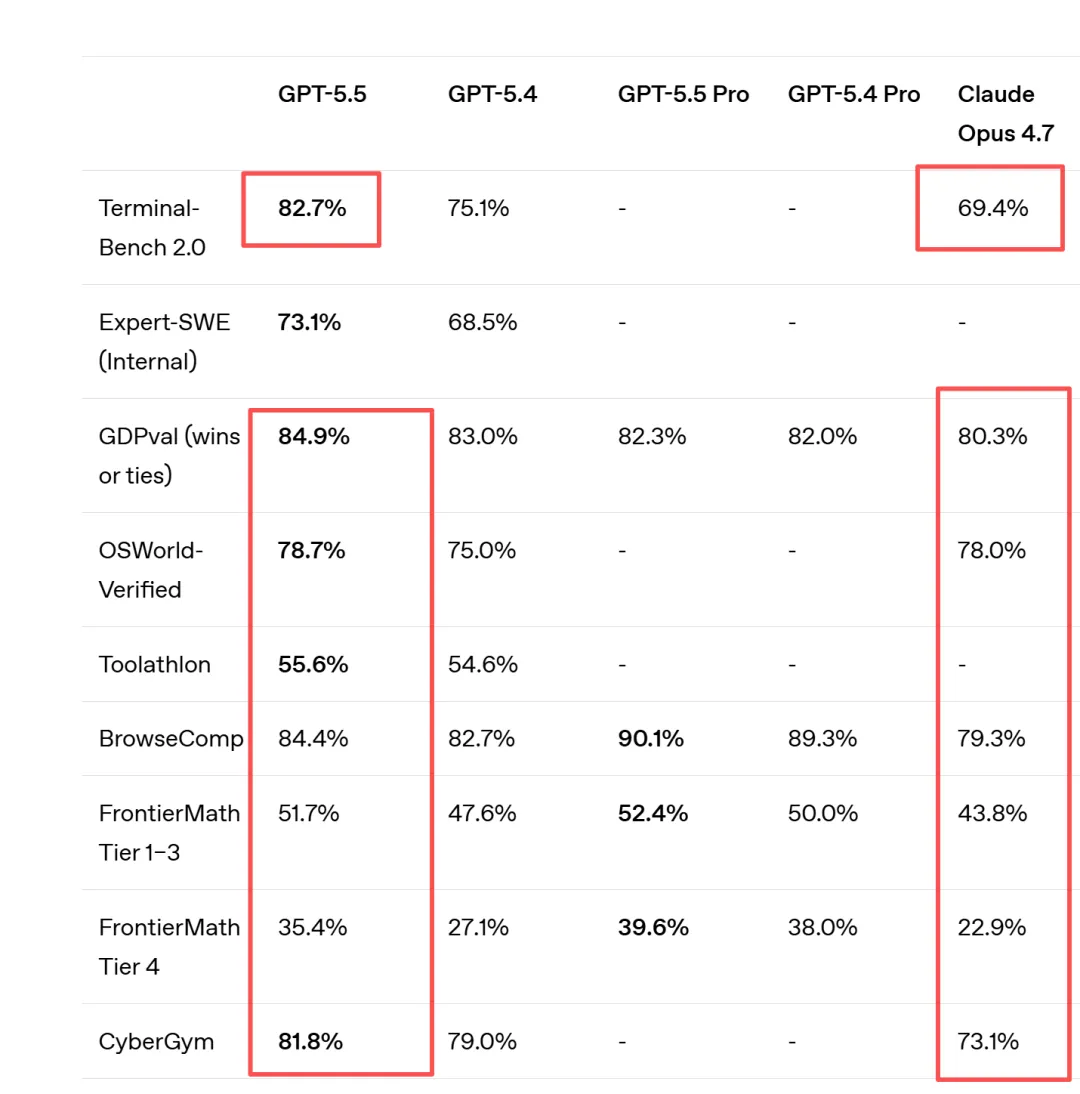
- 智能编码能力:
GPT-5.5 在编码方面的优势尤为明显,能够胜任从实现、重构到调试、测试和验证等工程工作。早期测试表明,GPT-5.5 在理解大型系统上下文、推理模糊故障、使用工具检查假设以及在整个代码库中进行更改方面表现更佳 。
- 知识工作能力:
GPT-5.5 在日常计算机工作中的表现同样强大。它能更自然地完成知识工作的整个流程:查找信息、理解重点、使用工具、检查输出,并将原始材料转化为有用内容。在 Codex 中,GPT-5.5 在生成文档、电子表格和幻灯片演示文稿方面优于 GPT-5.4 。
- 成本效益:
在 Artificial Analysis 的 Coding Agent Index 上,GPT-5.5 达到了最高智能水平,而成本仅为同级别竞品的一半
- 使用方式:
GPT-5.5 将面向 ChatGPT 和 Codex 的 Plus、Pro、Business 和 Enterprise 用户推出,GPT-5.5 Thinking 版本面向 Plus、Pro、Business 和 Enterprise 用户开放。
GPT-5.5 Pro 也将面向 ChatGPT 的 Pro、Business 和 Enterprise 用户推出。
API即将推出
Codex 中,GPT-5.5 适用于 Plus、Pro、Business、Enterprise、Edu 和 Go 套餐,上下文窗口为 400K。GPT-5.5 还提供快速模式,生成令牌的速度提升 1.5 倍,但费用也增加 2.5 倍。
⭐项目地址
https://openai.com/index/introducing-gpt-5-5/DeepSeek-V4 全新系列模型发布并开源
预览版本“DeepSeek‑V4”系列正式上线并同步开源,包括高性能的 V4‑Pro 与更轻量的 V4‑Flash 两款模型。登录官网 chat.deepseek.com 或官方App,即可使用
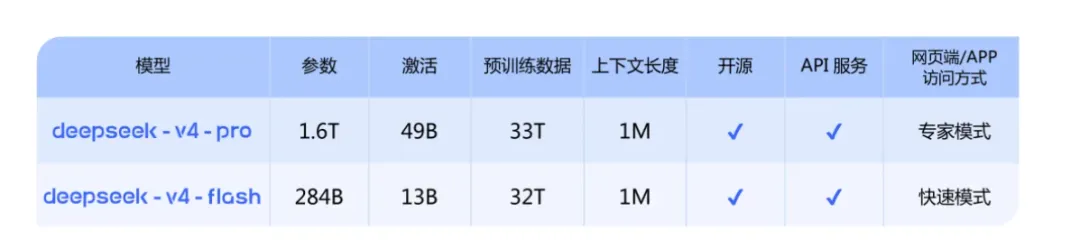
这些模型采用 混合专家+多重注意力 设计,在推理过程中可以激活更少的参数,支持 100 万 token 级超长上下文,并针对 Claude Code、OpenClaw 等主流 Agent 框架进行了优化。发布团队表示,V4‑Pro 的推理能力接近业内顶级闭源模型,仅在世界知识方面略逊于 Gemini‑Pro‑3.1,而 V4‑Flash 兼顾速度与成本,为开发者提供实用的 API 服务。
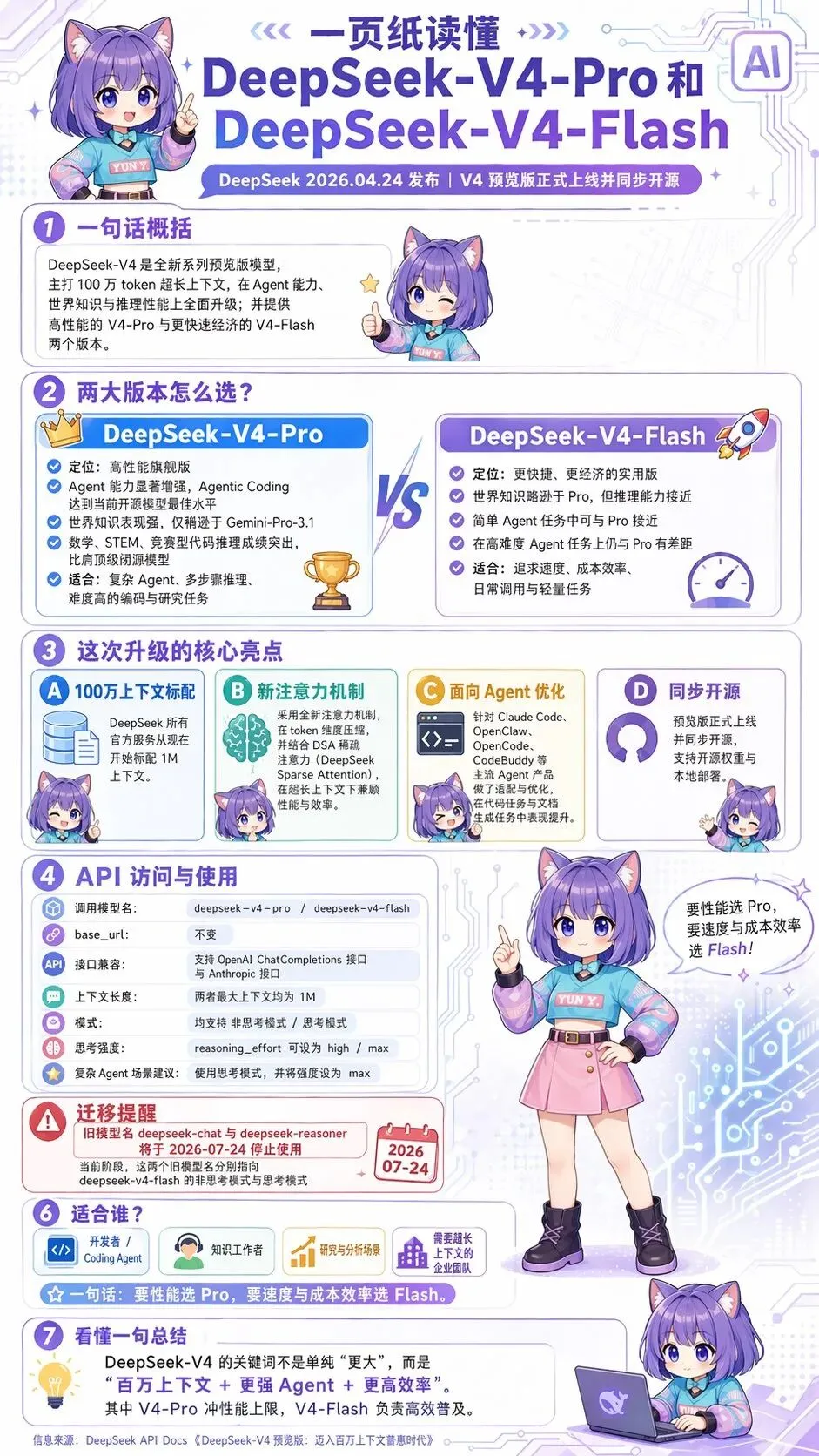
- 百万上下文能力: DeepSeek-V4 全线支持 100 万 token 上下文,这意味着模型能够处理极长的文本输入,这对于长程 Agent 任务的连贯性提供了保障。这一能力得益于其新的注意力机制,通过 token 维度压缩和 DSA 稀疏注意力,显著降低了单 token 推理 FLOPs 和 KV cache 的消耗 。
- V4-Pro (1.6T 总参、49B 激活)性能卓越:
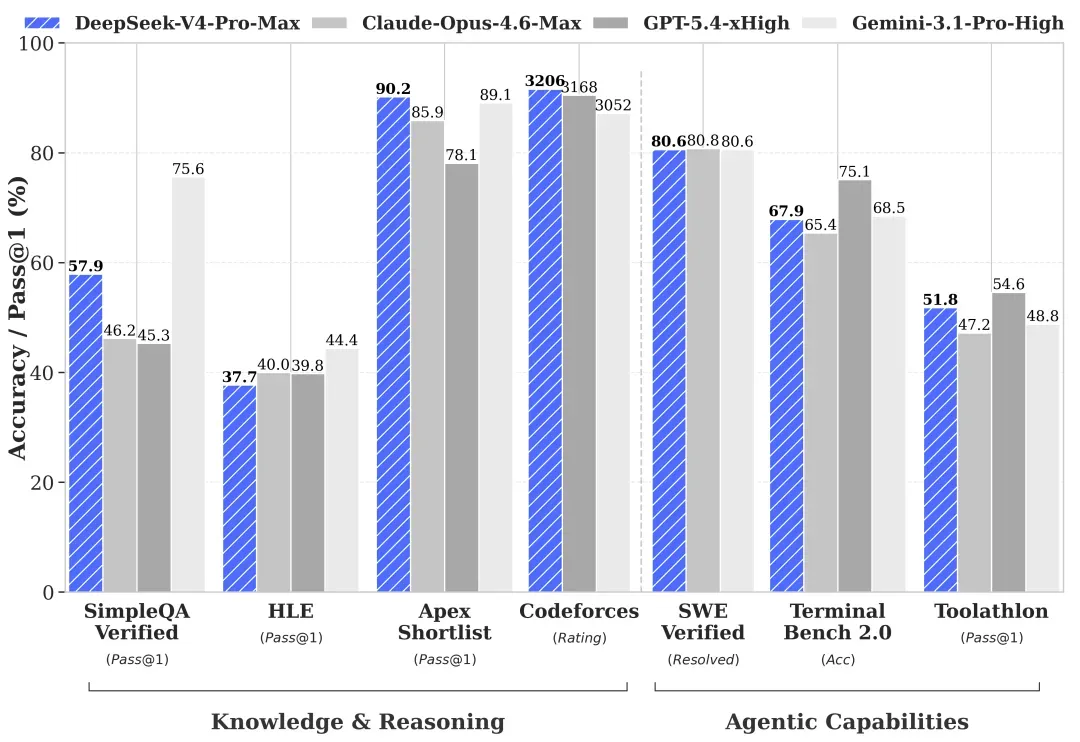
V4-Pro 在 Agent 能力、世界知识和推理性能上表现出色。在 Agentic Coding 评测中,V4-Pro 达到了当前开源模型的最佳水平,内部反馈优于 Sonnet 4.5,接近 Opus 4.6 的非思考模式。其推理能力已追平顶级闭源模型,世界知识仅次于 Gemini-Pro-3.1。在数学、STEM、竞赛代码等评测中,V4-Pro 超过所有已公开评测的开源模型,并与世界顶级闭源模型持平 。
- V4-Flash (284B 总参、13B 激活)轻量经济:
V4-Flash 版本更轻量、更经济,旨在提供快速响应的 API 服务。尽管其知识题表现稍逊于 V4-Pro,但在简单的 Agent 任务下,其素质与 V4-Pro 旗鼓相当,且推理能力接近 V4-Pro,具有高性价比
- API相关
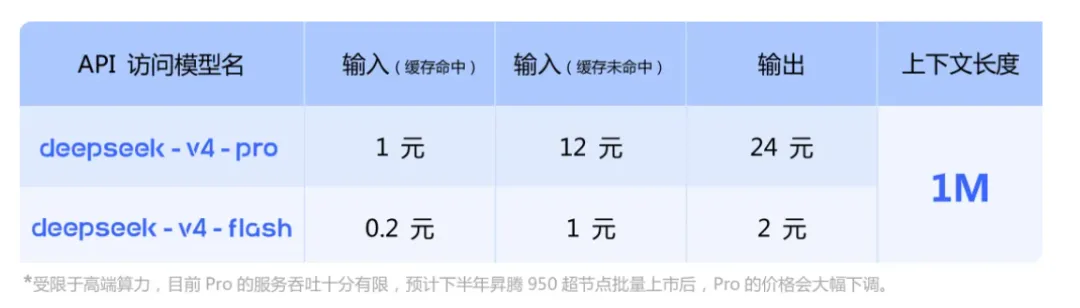
目前,DeepSeek API 已同步上线 V4-Pro 与 V4-Flash,支持 OpenAI ChatCompletions 接口与 Anthropic 接口。访问新模型时,base_url 不变, model 参数需要改为 deepseek-v4-pro 或 deepseek-v4-flash。
V4-Pro 与 V4-Flash 最大上下文长度为 1M,均同时支持非思考模式与思考模式,其中思考模式支持 reasoning_effort 参数设置思考强度(high/max)。对于复杂的 Agent 场景建议使用思考模式,并设置强度为 max。
⭐更多信息
https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg?scene=1&click_id=77🤖️AI 创作
可灵 :开放 4K 模式,AI 视频进入原生 4K 时代
快手旗下的 Kling AI 宣布 Video 3.0 系列加入 原生 4K 模式,可生成 15 秒、60 fps 的 4K 视频并同步音频,是迄今支持最大分辨率的 AI 视频模型。
- 4K 模式能够提供更清晰的视觉效果、更丰富的细节和电影级别的画质,专为大屏幕和高端制作而设计 。
- 该模式在主体、文本、风格和光照方面具有强大的视觉一致性 。
目前所有订阅用户和团队计划用户享受 4K 生成 20% 的折扣。
⭐信息来源:
https://x.com/i/status/2047329661705973851🤖️AI 应用/模型
Codex: 支持 GPT-5.5,实现五大能力升级
随着 GPT‑5.5 上线,OpenAI 的桌面应用 Codex 也进行了重大升级,支持新模型并增加多项功能。用户可以通过 Codex 直接操控电脑、浏览网页、生成图像等,形成完整的“AI 助理”。
- 浏览器操控:
Codex 现在可以直接操作网页应用,包括点击页面、填写表单、截图查看结果,并能根据看到的内容进行迭代,直到任务完成。例如,它可以自行测试注册流程并报告问题 。
- 文档能力:
Codex 能够直接在 Microsoft Office 和 Google Drive 中生成电子表格、幻灯片和文档,并且质量有所提升。应用内新增的文件预览器允许用户直接查看和调整效果 。
- 计算机使用(Computer Use):
随着 GPT-5.5 的增强,Codex 能够查看屏幕内容、点击、打字,并在不同应用之间传递上下文,进一步提升了其在计算机操作方面的能力 。
- 自动审查(Auto-review):
新增的“自动审查”模式允许 Codex 连续执行更长的任务链。当遇到高风险操作时,它会启动一个独立的审查智能体进行检查,通过后才继续执行,从而减少人工干预并控制风险 。
- gpt-image-2 整合:
图像生成模型 gpt-image-2 已整合进 Codex,这意味着在制作应用原型或演示文稿时,可以直接生成配图,无需切换到其他工具
⭐信息来源:
https://x.com/dotey/status/2047403459717320819腾讯:混元 Hy3 preview 语言模型发布并开源
腾讯混元 Hy3 preview 语言模型正式发布并开源,该模型是一个融合了快慢思考的混合专家模型,Agent 能力大幅提升,是混元重建后训练的首个模型。
- 模型特性:
Hy3 preview 是一个总参数 295B,激活参数 21B 的混合专家模型,最大支持 256K 上下文长度。其设计遵循能力体系化、评测真实性和性价比追求三个原则 。
- Agent 能力大幅提升:
该模型在代码和智能体方向的提升最为显著。在 SWE-Bench Verified、Terminal-Bench 2.0 等主流代码智能体基准以及 BrowseComp、WideSearch 等主流搜索智能体基准中取得了强竞争力。在 ClawEval 和 WildClawBench 等评测中表现突出,表明其智能体能力的全面与实用性 。
- 复杂推理能力:
Hy3 preview 在 FrontierScience Olympiad、IMO Answer Bench 等高难度理工科推理任务中表现突出,并在最新的清华大学求真书院数学博资考和全国中学生生物学联赛中取得优异成绩 。
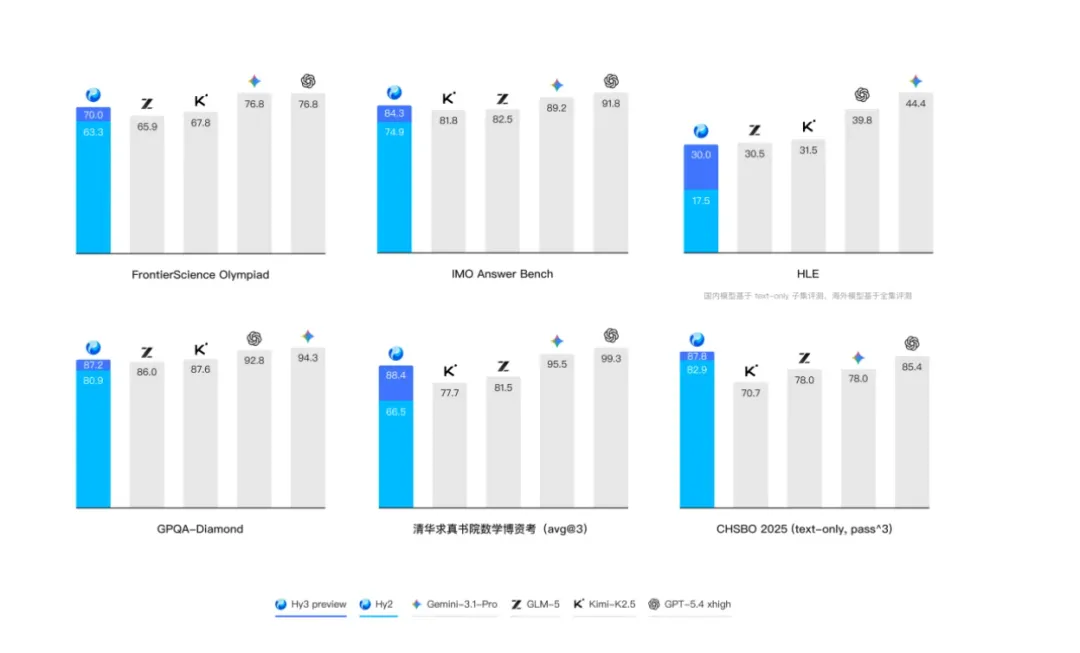
- 上下文学习和指令遵循:
模型显著提升了上下文学习和指令遵循能力,能够更好地理解杂乱冗长的上下文并遵从复杂多变的规则 。
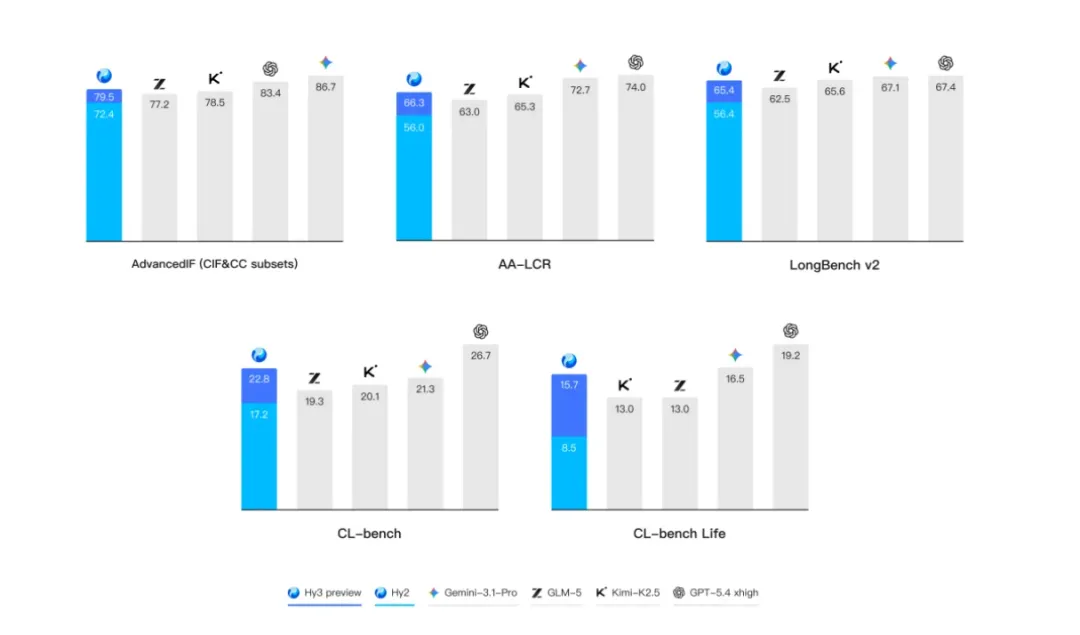
Hy3 preview 已在元宝、CodeBuddy、WorkBuddy、QQ、ima、QQ浏览器、腾讯文档、腾讯乐享等产品上线,并支持 OpenClaw、OpenCode、KiloCode 等流行的开源智能体产品
⭐项目地址:
https://github.com/Tencent-Hunyuan/Hy3-previewClaude: 宣布 Managed Agents 内置记忆功能开启公开测试
Claude 宣布其 Managed Agents 的内置记忆功能已开启公开测试。这一功能允许 Agent 从每次会话中学习,通过智能优化的记忆层平衡性能与灵活性。由于记忆以文件形式存储,开发者可以导出和管理,并完全控制 Agent 所保留的信息。
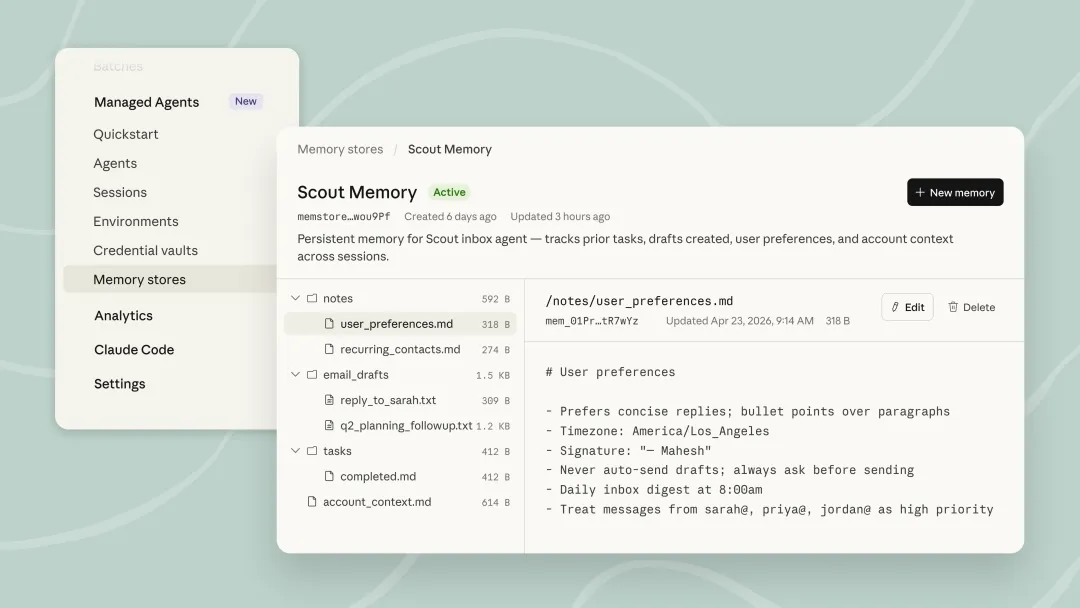
要点:
- 跨会话学习: Managed Agents 的记忆功能使其能够跨会话学习,通过内部基准测试进行优化,以支持长期运行的 Agent,这些 Agent 可以在会话之间进行改进并共享所学知识 。
- 文件系统记忆: 记忆功能直接挂载到文件系统上,因此 Claude 可以利用其现有的 bash 和代码执行能力。基于文件系统的记忆使得模型能够保存更全面、组织更良好的记忆,并能更准确地判断在给定任务中需要记住什么 。
- 企业级部署: 记忆功能专为企业部署而设计,具备范围权限、审计日志和完整的程序化控制。记忆存储可以在多个具有不同访问范围的 Agent 之间共享,例如,组织范围的存储可以是只读的,而每个用户的存储则允许读写 。
- 可移植性与控制: 记忆以文件形式存储,可以通过 API 导出和独立管理,赋予开发者完全的控制权。所有更改都会通过详细的审计日志进行跟踪,开发者可以回溯到早期版本或从历史记录中编辑内容。更新也会在 Claude Console 中显示为会话事件,方便开发者追踪 Agent 的学习过程和来源
- ⭐信息来源:
https://claude.com/blog/claude-managed-agents-memoryGoogle: 在 Gemini 中上线对话分支功能
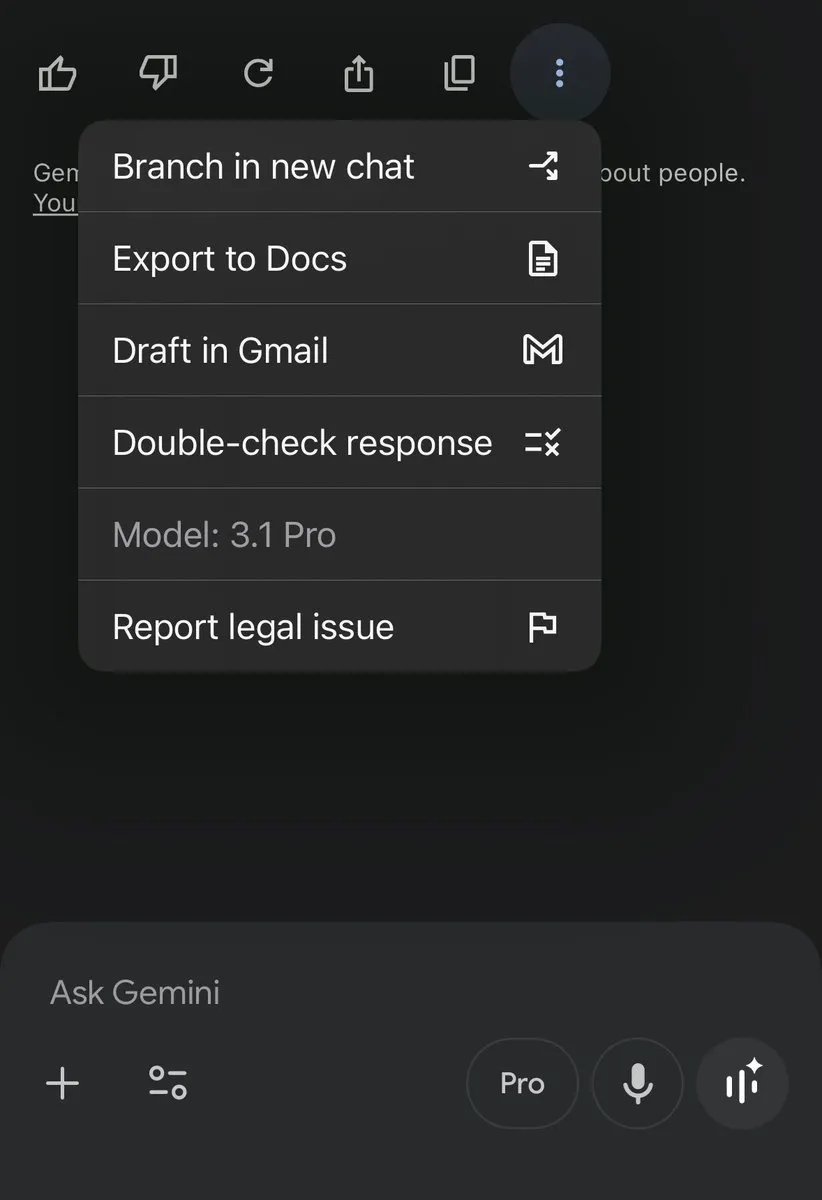
Google 在 Gemini 应用中上线 对话分支 功能,让用户可以从当前对话任意节点分出新的分支,会话历史不被覆盖。Google 副总裁 Josh Woodward 在 X 平台发文称该功能已向 20% 用户推送,正在逐步扩大范围。
用户在聊天页面可点击菜单中的“Branch in new chat”按键,从当前对话创建一个新的分支,方便在不同主题间切换而不影响原线程,有助于探索不同的思路或保存特定对话路径。
⭐信息来源:
https://x.com/joshwoodward/status/2047147030351642914Claude: 扩展 Connectors,新增 15 款日常应用
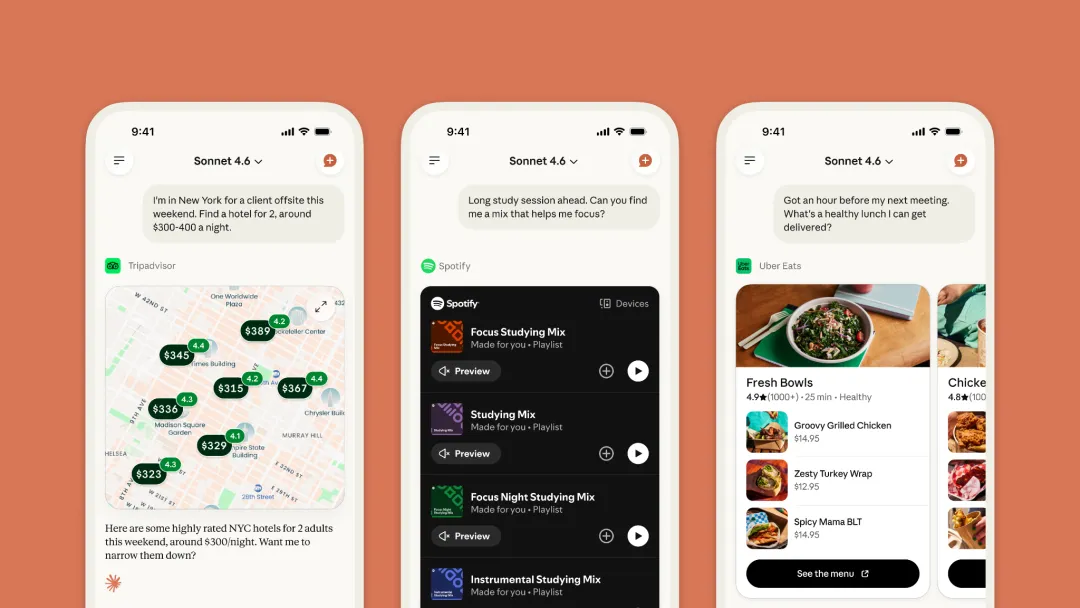
Claude 宣布扩展其 Connectors 功能,新增了 15 款日常生活应用,使用户能够将 Claude 连接到更多日常工具,从而在工作和个人生活中获得更广泛的帮助。
新增的 15 款日常生活应用包括:
AllTrails、Instacart、Audible、TripAdvisor、Intuit TurboTax、Booking.com、Intuit Credit Karma、Resy、Spotify、StubHub、Taskrabbit、Thumbtack、Uber、Uber Eats 和 Viator
- 智能提示:Claude 会在对话中根据用户意图动态提出适合的连接器建议,用户可以选择调用或忽略。
- 隐私保证:采用明示授权方式,用户完全控制数据分享与交互内容,Anthropic 承诺不将数据用于训练目的
⭐信息来源:
https://claude.com/blog/connectors-for-everyday-life蚂蚁百灵:发布 Ling-2.6-1T 模型,提供试用并计划开源
蚂蚁百灵发布其万亿参数旗舰模型 Ling-2.6-1T,该模型已提供试用,并计划开源。
Ling-2.6-1T 旨在为需要快速执行和高效率的真实世界 Agent 提供支持,通过“快速思考”方法显著降低成本,同时保持顶级的性能。
要点:
- 模型定位: Ling-2.6-1T 是 inclusionAI 的万亿参数旗舰模型,专注于为需要快速执行和高效率的真实世界 Agent 设计 。
- 性能与效率: 该模型采用“快速思考”方法,将成本降低至同类模型的约四分之一,同时保持顶级的性能。在 AIME26 和 SWE-bench Verified 等基准测试中取得了最先进的结果 。
- 应用场景: Ling-2.6-1T 非常适合高级编码、复杂推理和大规模 Agent 工作流,在这些场景中,能力和效率都至关重要 。
- 上下文与输出: 模型支持 262.1K 的总上下文和 32.8K 的最大输出。
⭐信息来源:
https://openrouter.ai/inclusionai/ling-2.6-1t:free⚠️部分内容由AI生成,可能存在偏差
💗有任何疑问,请提前联系邮箱:alolg@163.com