 夜雨聆风
夜雨聆风





DeepSeek V4 的真正革命:当AI竞争从“算法跑分”进入“全栈战争”
一个模型的发布,让英伟达的市值蒸发千亿,让国产AI芯片的份额从5%跃升至45%——这不是算法的胜利,这是技术栈的降维打击。
当整个行业还在为DeepSeek V4的基准测试分数、百万级上下文窗口和MoE稀疏架构而兴奋时,大多数人可能都看错了重点。V4最革命性的突破,从来不是“又一个更强的模型”,而是它首次完成了万亿参数大模型从芯片、框架到集群的100%国产化技术栈闭环。
这意味着什么?意味着中国AI产业第一次有了不依赖任何海外技术、从硬件到软件的完整自主技术栈。这不是优化,是重构;不是追赶,是换道。
一、 算法的民主化:模型层已无“代差”可言
让我们先正视一个现实:在大模型领域,算法的护城河已经消失。
今天的GPT、Claude、DeepSeek乃至国内所有主流模型,底层都是Transformer架构的变体。稀疏化、长文本优化、MoE混合专家——这些技术创新在全球范围内实时同步,通过论文、开源代码和人才流动,以月为单位迅速扩散。
一个顶尖团队的核心成员跳槽,几个月后竞品就能复现出性能相当的技术方案。模型能力已经变成对称竞争:你有千亿参数,我也可以有;你的上下文长,我很快也能做到。这种对称优势,决定了单靠模型本身,再也无法形成真正的壁垒和溢价。
DeepSeek V4的性能再强,也只是“更好”,而非“不同”。真正的胜负手,早已不在模型层。
二、 全栈国产化:斩断“CUDA依赖症”的手术
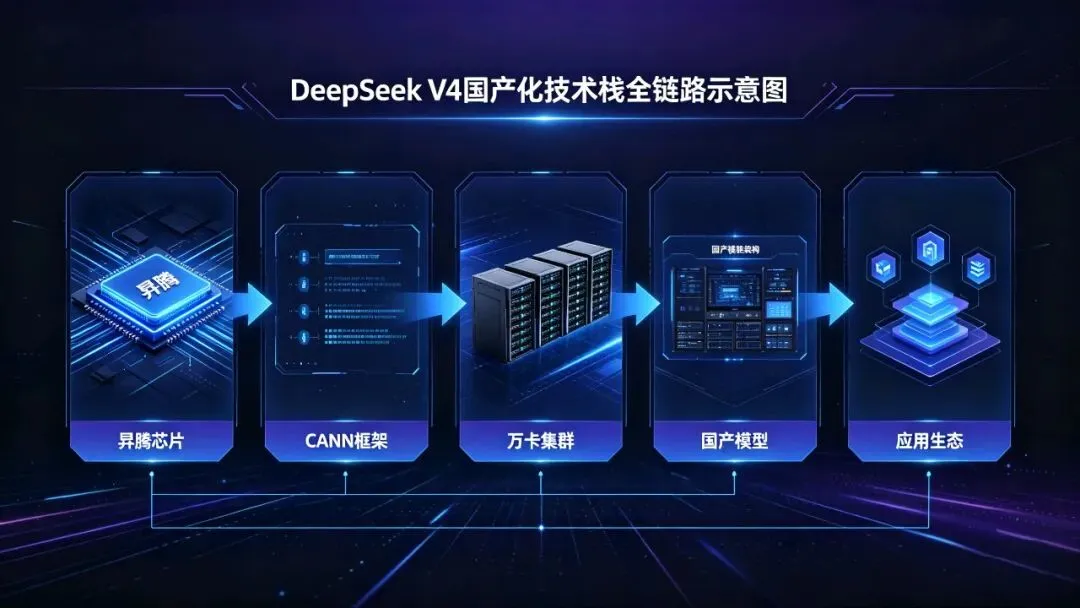
DeepSeek V4最具颠覆性的成就是:彻底脱离英伟达的CUDA生态,实现了从训练到推理的全链路国产化。
这不是简单的“换块芯片”,而是一场触及AI基础设施灵魂的系统性重构:
硬件层的迁移:V4的训练基于昇腾910C万卡集群,推理全面适配昇腾950PR芯片,全程零英伟达GPU依赖。实测数据显示,昇腾950PR的单卡性能是英伟达H20的2.87倍,而部署成本仅为H20的1/31。这组数字背后,是性价比的彻底逆转。
框架层的重写:底层从CUDA全面转向华为CANN框架,团队重写了200多个核心算子、数十万行代码,完成了从训练到推理的全流程适配。CANN框架兼容95%的CUDA代码,配合一键迁移工具,将原本需要数月的迁移工作缩短至小时级——这不是替代,是进化。
集群层的突破:攻克了国产芯片在万卡级分布式训练中的通信瓶颈、负载均衡和稳定性难题,构建了完整的国产训推闭环。这证明了中国企业有能力在最复杂的大规模AI工程问题上实现自主可控。
生态层的转向:V4拒绝了英伟达的早期访问请求,优先向华为、寒武纪等国产芯片厂商开放适配。这一选择带动了阿里、字节、腾讯等巨头批量采购昇腾芯片,直接导致英伟达在华的AI芯片份额从95%的绝对垄断,暴跌至55%——而这一切,只用了不到一年。
这就是黄仁勋“五层架构”理论在现实中的印证:真正的壁垒从来不是最上层的应用或模型,而是软硬件深度绑定、不可复制的全栈生态。DeepSeek V4打通的,正是这个生态闭环。
三、 不对称壁垒:国产技术栈的三重溢价权
全栈国产化构建的,是算法对称时代最珍贵的资产:不对称壁垒。这种不对称,直接转化为三个维度的溢价权:
1. 安全溢价:自主可控的“政治正确”
在地缘技术管制常态化的今天,依赖英伟达生态意味着随时面临“断供”风险。从芯片禁售到框架限用,任何一个环节的卡脖子,都可能导致整个AI业务停摆。
V4提供的国产化全栈方案,为政企、金融、能源、军工等关键领域提供了绝对安全可控的AI底座。这种“不会突然消失”的确定性,是任何海外模型无法提供的价值。在特定行业中,这不再是比较优势,而是准入资格。
2. 成本溢价:极致性价比的“商业革命”
全栈国产化带来的成本优化是颠覆性的。V4的推理成本仅为GPT-4的1/70,训练成本降低50%以上。这得益于昇腾芯片的采购成本优势,以及全链路的算子优化和集群调度优化——算力利用率高达85%,能耗降低40%。
当企业可以用1/10的成本解决95%的实际需求时,商业逻辑就被改写了。这种“高性能+低成本”的组合,正在全球AI市场形成碾压性的价格优势,直接挑战由英伟达和OpenAI制定的原有定价体系。
3. 生态溢价:闭环成型的“护城河”
DeepSeek V4的成功适配,为国产芯片做了顶级“质量认证”,点燃了整个国产生态的信心。从芯片(昇腾、寒武纪)、框架(CANN、TileLang)到模型(DeepSeek)、应用,国产化技术栈首次形成了完整闭环。
开发者基于这套国产技术栈开发的应用,可以无缝迁移到任何国产芯片平台,彻底摆脱了以往生态碎片化的困境。这种“用了就离不开”的生态锁定效应,需要数十年、万亿级投入才能构建,是人才挖不走、代码抄不走的终极护城河。
四、 行业洗牌:从“模型竞赛”到“生态战争”
DeepSeek V4的全栈突破,正在引发连锁反应,重新定义AI产业的竞争规则:
对芯片厂商:昇腾等国产芯片从“备胎”变为“首选”。性能验证和生态完善,让国产芯片在可靠性上不再被质疑,开始进入主流采购清单。
对云服务商:阿里云、腾讯云、华为云等纷纷推出基于国产芯片的AI算力服务,成本大幅降低,推动了AI能力在中国企业的普惠化落地。
对应用开发者:一次开发,多芯片部署成为可能。开发者不再被绑定在CUDA生态上,有了更多议价权和选择空间。
对全球竞争格局:中国AI产业第一次拥有了从硬件到软件的完整技术主权。这意味着在未来的标准制定、协议定义、生态规则上,中国公司有了参与甚至主导的资格。
五、 冷静审视:挑战与未来
当然,全栈国产化之路才刚刚开始,依然面临挑战:
开发者生态的完善:CUDA经过十余年积累,拥有成熟的工具链和海量开发者。国产技术栈需要时间构建同样繁荣的社区和生态。
软件栈的深度优化:从编译器、驱动到各类专业库,国产技术栈还需要更多“踩坑”和优化,才能达到极致的性能表现。
全球兼容性:在强调自主可控的同时,如何保持与全球开源生态的兼容与互动,避免走向技术孤立,是需要持续平衡的课题。
但无论如何,DeepSeek V4已经证明了一件事:中国AI可以走出一条不依赖CUDA、不依赖英伟达的全栈自主道路。而且这条道路,在性能、成本、安全性上,都显示出强大的竞争力。
结语
DeepSeek V4的发布,表面上看是一个模型的升级,本质上是中国AI产业的“独立宣言”。它标志着中国AI竞争的主战场,正在从表面的“算法跑分”,转向深层的“全栈战争”。
未来的AI领导者,不再只是拥有最强算法的公司,更是掌握完整技术栈、定义生态规则、构建产业闭环的体系性玩家。这场竞争,比的不是谁跑得更快,而是谁的路修得更坚实、更自主、更可持续。
DeepSeek V4的价值,不在于它今天跑赢了哪个基准测试,而在于它为中国AI修通了一条完全自主的高速公路。这条路上跑什么车、定什么交规、通向哪些目的地——话语权,第一次真正掌握在了自己手中。
这,才是真正的颠覆。
「一哥行走杂谈」
一个中年架构师的观察与思考