 夜雨聆风
夜雨聆风





智算中心建设项目规划方案(WORD)
温馨提示

关注【无忧智库】微信公众号,文末附资料下载方式。


|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




-
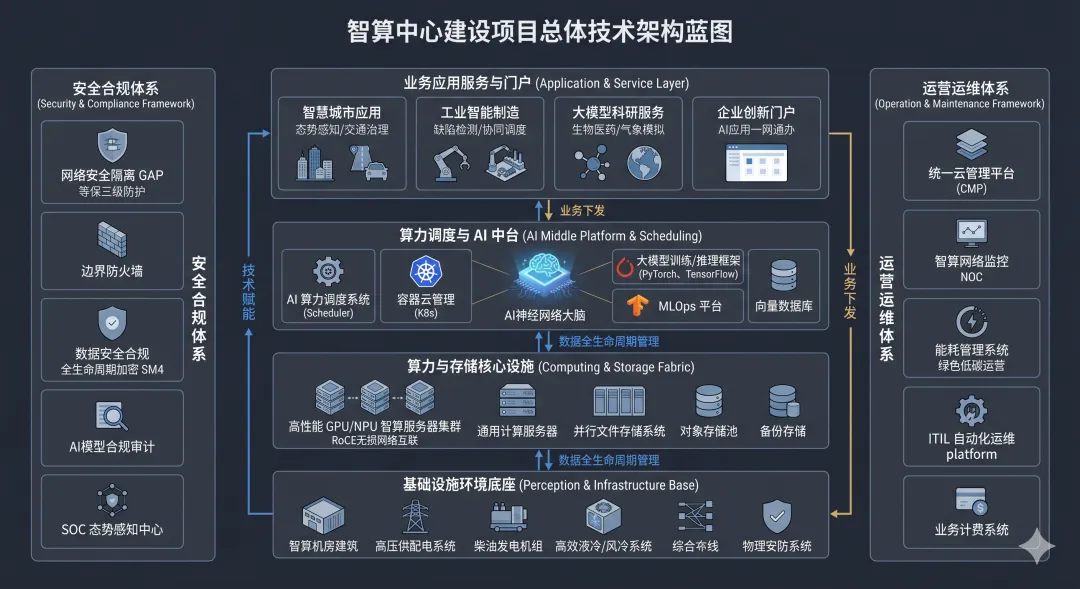
基础设施运维团队:负责电力、空调、消防、安防等物理设施的日常监控与维护
-
IT系统运维团队:负责服务器、存储、网络设备的维护,以及系统软件的升级和故障处理
-
算力调度团队:负责Kubernetes集群管理、资源调度优化、用户工单处理
-
安全团队:负责网络安全监控、数据合规管理、应急响应
-
客户服务团队:负责客户需求对接、方案定制、服务质量保障
-
商务拓展团队:负责市场开拓、客户签约、行业解决方案销售

-
市场需求调研,明确目标客户群体和服务定位
-
技术可行性分析,完成选址评估(电力、网络、土地)
-
完成概念方案设计,通过专家评审
-
资金预算和融资方案设计
-
取得必要的政府审批和政策支持

-
土地与场地费用:因地区差异极大,一线城市核心区和西部地区可能相差5-10倍
-
基础设施建设:机房建造、电力改造、空调或液冷系统,通常占建设成本的30-40%
-
计算设备采购:GPU服务器是大头,一张NVIDIA H100 GPU的市场价格在8-15万元人民币,100台GPU服务器(每台8张GPU)的设备成本就高达6-10亿元
-
网络设备:高速交换机、InfiniBand设备、安全设备,通常占设备总成本的10-15%
-
软件与系统集成:调度平台、监控系统、安全系统,通常占建设成本的5-8%
-
电力费用:通常是最大的单项运营成本,高端智算中心的年电费可能占运营成本的40-60%
-
人力成本:技术运维、安全、客服、商务团队的薪资,占运营成本的20-30%
-
设备维护与折旧:GPU设备更新迭代快,折旧周期通常按3-5年计
-
网络带宽费用:外部互联网带宽,以及跨数据中心专线费用
-
保险与合规成本:等级保护测评、数据安全合规审查等




































































































































资料下载方式
1、标题标注【免费下载】的资料,点击上方关注“无忧智库”公众号,公众号后台回复关键字:“报告”,免费获取资料下载网盘链接。
2、没有标注【免费下载】的,点击加入知识星球无忧智库 · 数字化行业方案库,获取下载21万+份可精选行业资料,涵盖低空经济、AI大模型、数字经济、具身智能、Agent智能体、智慧城市、数字政府、城市生命线、5G、大数据、区块链、物联网、数字孪生、智能制造、数据要素等前沿领域的 Word/PPT 方案、行业报告、地方数字化政策及招标文件。
⚠️ 特别提示:苹果IOS手机用户➕微信:www_zku51_com
知识星球部分资料示例(由于资料数量庞大且持续更新,此处仅展示):
知识星球介绍
1、【无忧智库 · 数字化行业方案库】,数字工作者必备的专业行业智库。星主历时5年+,聚合多个行业渠道,系统归类整理,沉淀内容超 21万份、总大小 1T+,坚持每日更新,是您工作中的得力助手,助您迅速成为行业方案专家。
2、现在加入即享十四大核心会员权益:
-
【权益一】星球索引:星球往期资料打包一键下载,更新至1-1786期
-
【权益二】海量合集:任选20个海量专题合辑,涵盖低空经济、AI大模型等热门方向
-
【权益三】全行业研报:6年全行业研究分析报告,235G+,12万份+
-
【权益四】高峰论坛:各大行业峰会、论坛、会议PPT及视频
-
【权益五】高端PPT模板:9000多份各行业PPT精选模板
-
【权益六】标准规范:国家/行业/地方标准规范三库合一
-
【权益七】弱电图纸:各行业弱电、图纸、建筑标准图集
-
【权益八】产品原型:各行业原型资源(元件库、大厂标准、模板、案例
-
【权益九】图集:建筑、工程、规划等多类专业图集
-
【权益十】开发利器:低代码平台源码(JAVA和.NET双擎)
-
【权益十一】行业地图&产业图谱:各行业地图、产业图谱可视化资源
-
【权益十二】Excel可视化模板:700套Excel可视化信息图表模板
-
【权益十三】行业软件:数字工作者必备行业软件及工具
-
【权益十四】VISO素材&图标库:海量VISIO图库素材、图标库
 本站所载文章纯属作者个人观点,仅供参考,不代表无忧智库立场。
本站所载文章纯属作者个人观点,仅供参考,不代表无忧智库立场。