 夜雨聆风
夜雨聆风





AI 时代的多模态数据湖基础设施

导读本文根据腾讯云 TBDS 大数据存储团队核心成员张帅在 Data for AI Meetup(深圳站)的技术演讲整理而成。在 AI 大模型时代,数据处理正面临前所未有的范式转移。随着多模态数据需求的爆发式增长,传统数据湖在存储效率、计算灵活性及治理精细度上的局限性日益凸显。腾讯云大数据处理套件(TBDS)针对这些挑战,提供了一套从底层存储、弹性计算到智能治理的全链路解决方案,深度解析 TBDS 如何通过多模态原生支持、高性能向量检索及异构资源调度,构建 AI 时代的多模态数据湖基础设施,为海量异构数据的价值释放提供坚实支撑。
1. 引言:AI 时代多模态数据湖的挑战与机遇
2. TBDS 的创新实践:构建 AI 原生多模态数据湖
3. 架构视角:全新一代 AI 湖仓产品体系
4. 落地实践:从知识库构建到行业深度应用
5. 深度洞察:技术趋势与总结
6. 结论
分享嘉宾|张帅腾讯云 TBDS 大数据存储团队核心成员
出品社区|DataFun
01
引言:AI 时代多模态数据湖的挑战与机遇
AI 技术的演进深刻重塑了数据处理逻辑,形成了“AI for data”与“Data for AI”的双向赋能关系。在多模态数据膨胀的今天,数据湖不仅要处理传统的结构化数据,更要应对文本、图片、音视频及向量 Embedding 等异构数据的存储与检索。这不仅是数据类型的扩展,更是对存储性能、计算资源利用率及治理自动化水平的全面挑战,要求数据湖实现从传统架构向 AI 原生基础设施的跨越式升级。
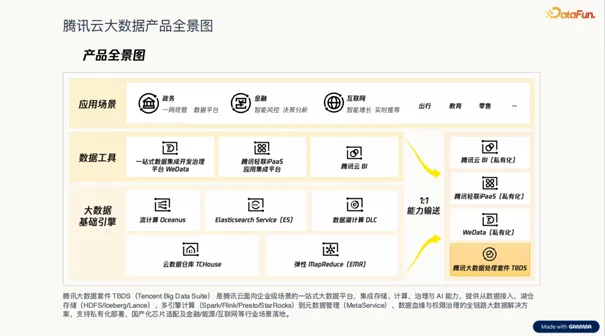
作为腾讯云大数据产品体系的核心,TBDS 旨在为企业级用户提供一站式大数据平台服务。它深度整合了大数据基础引擎、工具、管理与 AI 能力,特别针对私有云场景下的政务、金融、互联网等行业进行了深度优化。TBDS 的核心优势在于其强大的集成能力,能够将底层的 HDFS、S3 存储与上层的 Spark、Flink、Presto 等计算引擎无缝衔接,并通过统一的元数据管理和权限治理,为企业构建起一套高效、稳定、安全的 AI 数据底座,极大地降低了构建复杂 AI 数据基础设施的门槛。
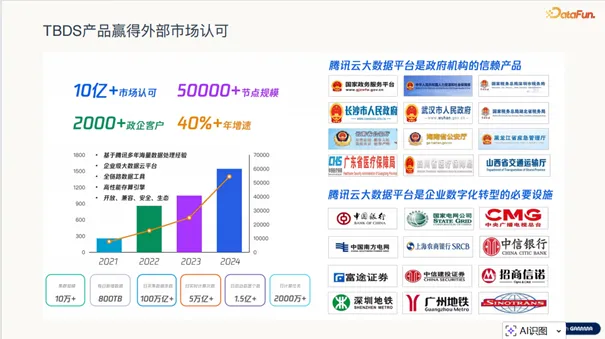
TBDS 的市场表现有力地证明了其技术实力。截至 2024 年底,TBDS 已累计服务近 2000 家客户,管理节点规模突破 5 万个,年增速保持在 40% 以上。从国家政务服务平台到中国银行、中信证券,TBDS 在众多关键行业实现了规模化落地。张帅特别强调,TBDS 在实际应用中展现了显著的提效价值,尤其是在硬件资源节省方面,帮助客户在数据量激增的背景下有效控制了 IT 投入成本,成为企业应对 AI 时代数据挑战的首选平台。

过去 20 年,数据湖主要处理的是结构化业务表和半结构化日志,主要服务于传统的批处理分析。然而,AI 时代对数据类型的需求已转向多模态。文本语料、图片、音视频、向量 Embedding 以及标注与版本数据,共同构成了 AI 时代的数据图景。这些新型数据不仅规模巨大,且对随机访问性能、语义检索能力及版本回溯提出了极高要求。数据湖正从单纯的存储库进化为智能化基础设施,这要求我们在存储格式、计算范式及管理机制上进行深刻创新。

面对多模态浪潮,传统数据湖在实际应用中暴露出“存不好、算不动、管不住、治不了”的四大痛点。在存储层面,Parquet 等列式格式对多模态文件压缩不透明,导致随机访问效率低,且缺乏向量索引支持。在计算层面,传统引擎缺乏对 GPU 等异构资源的调度能力,且数据预处理与模型训练流程割裂。管理上,依赖文件夹或陈旧的 Hive Metastore,性能与权限控制薄弱。治理方面,向量索引维护困难、版本管理混乱及存储空间膨胀,都阻碍了企业释放数据价值。
02
TBDS 的创新实践:构建 AI 原生多模态数据湖

为化解传统架构积弊,TBDS 团队在存储、计算、管理和治理四个关键维度展开了深度探索。通过引入 AI 原生的存储格式、弹性计算框架及标准化的元数据管理,TBDS 旨在构建一套支撑大模型全生命周期的数据基础设施,实现从海量原始数据到高质量 AI 资产的高效转化。
1. 存储革新:Lance 格式的深度集成

在存储层面,TBDS 深度集成了专为 AI 设计的 Lance 格式。Lance 采用存算分离架构,重新定义了多模态文件的编码方式,实现了定长元素的 O(1)搜索和不定长元素的极速检索,解决了读取时的碎片化问题。更关键的是,Lance 原生内置了 IVF、HNSW 等高性能向量索引,支持毫秒级语义检索。配合 TBDS-FS 的分布式缓存加速,Lance 在处理海量向量与多模态数据时展现出卓越的性能与成本优势,实现了存储性能与硬件消耗的完美平衡。
2. 计算演进:增强型 Ray 框架的弹性调度

针对计算资源割裂,TBDS 通过集成并增强 Ray 框架,实现了异构资源的统一调度。Ray 原生支持 CPU 与 GPU 混合调度,TBDS 在此基础上进行了定制化优化,使其能够跨多个 K8S 集群动态分配算力。这种弹性伸缩能力确保了海量数据预处理时的资源高效利用。同时,Ray 的 Python-Native 特性贴合 AI 开发者习惯,实现了预处理与训练的一体化,大幅减少了数据在系统间的搬运成本,提升了 AI 研发的整体效率。
3. 管理升级:Gravitino 引领的元数据标准化

在元数据管理方面,TBDS 协同开发了 Gravitino(内部称为 Meet Service),提供一站式异构数据源管理方案。Gravitino 为 Lance 等新型格式建立了标准化的 Catalog,相较于 Hive Metastore 更加轻量且具备强大的 IBC 权限控制,有效避免了高并发场景下的锁竞争。作为多模态数据湖的“导航塔”,Gravitino 实现了表、函数、文件集及模型的统一发现与访问,提升了资产可视化水平,为企业构建了安全合规的 AI 数据环境。
4. 治理智能:Lakekeeper 的全自动生命周期管理
针对数据治理的复杂性,TBDS 推出了 Lakekeeper 治理方案,实现了智能化运维。Lakekeeper 能自动监控增量数据,构建并评估向量索引的健康状态,确保检索的实时性。同时,利用 Ray 集群的分布式能力,高效处理小文件合并与旧版本数据清理,遏制了数据膨胀。配合 TBDS-FS 的缓存加速,Lakekeeper 为用户提供了常驻、高性能的检索服务,将复杂的数据治理转化为后台自动化流程,让开发者专注于业务创新。
03
架构视角:全新一代 AI 湖仓产品体系
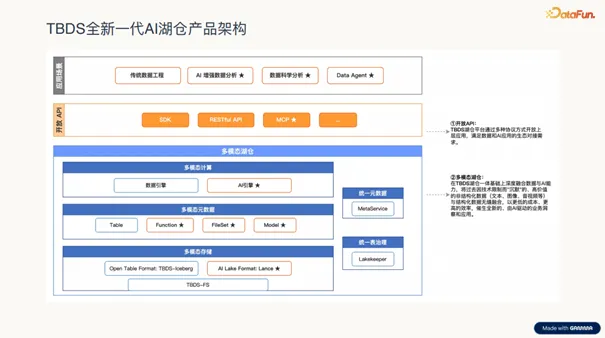 TBDS 构建了一个分层明确、高度开放的 AI 湖仓体系。最底层的 TBDS-FS 统一存储层屏蔽了 HDFS、S3 等存储差异,支持 Iceberg 与 Lance 等格式。中间的元数据层与计算层,通过 Gravitino 与 Ray 实现了管理与算力的深度融合,支持 CPU/GPU 异构调度及智能治理。上层的开放 API 层则通过多种接口,为数据工程、AI 分析及 Data Agent 提供了丰富的服务。这种架构不仅灵活可扩展,更实现了从结构化数据分析到多模态 AI 应用的全场景覆盖。
TBDS 构建了一个分层明确、高度开放的 AI 湖仓体系。最底层的 TBDS-FS 统一存储层屏蔽了 HDFS、S3 等存储差异,支持 Iceberg 与 Lance 等格式。中间的元数据层与计算层,通过 Gravitino 与 Ray 实现了管理与算力的深度融合,支持 CPU/GPU 异构调度及智能治理。上层的开放 API 层则通过多种接口,为数据工程、AI 分析及 Data Agent 提供了丰富的服务。这种架构不仅灵活可扩展,更实现了从结构化数据分析到多模态 AI 应用的全场景覆盖。
04
落地实践:从知识库构建到行业深度应用
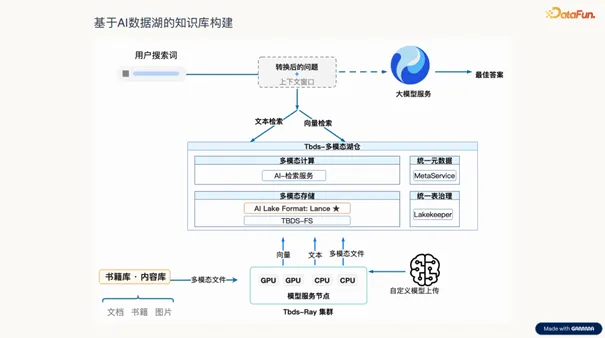
TBDS 在基于 AI 数据湖的知识库构建(RAG)场景中展现了核心价值。针对大模型的“幻觉”问题,RAG 通过引入外部知识库进行精准检索。这一过程对数据湖的多模态处理能力要求极高,需要高效管理海量文本切片、图片及向量数据,确保检索的准确性与实时性。
在具体的 RAG 流程中,TBDS 展现了闭环处理优势。数据入库阶段,Ray 集群调度算力进行预处理与向量化,并将结果存入 Lance 表。用户查询阶段,系统通过文本检索与向量检索的双路召回机制,既能精准匹配关键词,又能深度理解语义。这种方案显著提升了知识召回质量,让大模型生成的答案更加可靠,真正让企业知识资产转化为智能生产力。

在某大型金融机构案例中,TBDS 展现了卓越的降本增效能力。该机构面临超 10TB、近1 0 亿量级的海量文本切片,传统的存算一体架构在存储大规模向量时成本极高,且在业务低谷期造成资源浪费。这种“存多算少”的矛盾,限制了其 AI 应用的规模化推广。
针对金融机构痛点,TBDS 构建了存算分离的 AI 数据湖架构。通过 Lance 格式对双路检索的统一支持,以及计算资源的弹性伸缩,客户在硬件成本上实现了超过 70% 的节省。更重要的是,基于 TBDS 构建的内部知识库,为大模型提供了精准语料支撑,大幅提升了业务咨询与决策支持的智能化水平,为行业转型提供了可复制的范式。
05
深度洞察:技术趋势与总结
存储与搜索的融合是 AI 时代的必然,TBDS 通过存算分离架构,在保证海量存储的同时提供了超越传统搜索引擎的效率与成本优势。对于文件管理,TBDS 倾向于通过强大的单表性能减少分表复杂性。在模型选择上,TBDS 保持了基础设施的开放性,兼容不断演进的 AI 算法生态。
06
结论
腾讯云 TBDS 通过在存储、计算、管理及治理维度的创新,成功构建了面向AI时代的多模态数据湖基础设施。从 Lance 格式到 Ray 框架,从 Gravitino 到 Lakekeeper,TBDS 不仅解决了多模态数据处理难题,更通过金融等行业的成功实践证明了其在降本增效方面的巨大价值。TBDS 将继续作为坚实的数据底座,助力企业释放数据无限可能。


关于 Data for AI 社区
Data for AI 是一个聚焦数据与人工智能基础设施生态的技术交流社区。
社区的分享嘉宾来自全球数据与人工智能领域众多头部厂商与新锐创业团队,包括 Alibaba、Anyscale、AWS、Bilibili、ByteDance、Databricks、Datastrato、eBay、IBM、Intel、LanceDB、Lilith、Meta、Microsoft、NVIDIA、OpenAI、Pinterest、Roku、Tencent、Uber、Xiaomi、Zilliz 等企业。如此多方参与,让社区能持续输出高质量、贴近行业一线的技术内容。我们的组织者来自 Linux 和 Apache 等知名开源基金会和社区。这让 Data for AI 在保持开放友好氛围的同时,也具备中立、可信、专业的技术讨论基础。
Data for AI 的目标,是为数据工程、AI & Data Infra 等领域的开发者打造一个轻松而专业的交流平台。通过线上线下的活动,大家可以一起探索前沿趋势、分享实践经验、拆解真实业务案例,打破行业信息壁垒,连接优质同行伙伴,共同构建一个持续成长、价值共生的技术社群网络。
如您希望加入 Data for AI 社区,请联系社区主理人 Richard(微信:OPQRichard)沟通交流。


往期推荐

点个在看你最好看
SPRING HAS ARRIVED
