 夜雨聆风
夜雨聆风





AI 药物研发论文背后的数据源地图:从序列、结构、活性到靶点证据
AI 药物研发论文背后的数据源地图:从序列、结构、活性到靶点证据
摘要: 读懂一篇 AI 药物研发论文,不能只看模型结构和指标。更关键的是追问:它用的序列、结构、活性和靶点证据分别来自哪里,证据等级如何,能否支撑作者的结论。
很多 AI 药物研发论文看起来很完整:有一个新模型,有漂亮的 benchmark,有分子生成结果,有 docking 图,有靶点解释,最后再给出几个候选化合物。
但真正读到方法部分时,经常会遇到一个更基础的问题:这些结论背后的数据到底来自哪里?
一个模型说某个分子“可能有效”,它可能引用了 ChEMBL 的活性数据;一个靶点被认为“值得关注”,可能依赖 UniProt 的蛋白注释、PDB 的实验结构、AlphaFold 的预测结构,或 Open Targets 的疾病证据整合。每个数据库都很有用,但它们回答的问题并不一样。
如果把这些数据源混在一起看,就容易把“序列存在”“结构可见”“活性相关”“靶点有证据”写成同一种确定性。对科研工作者来说,读懂一篇 AI 药物研发论文,第一步不是看模型多复杂,而是先把它的数据源地图画清楚。
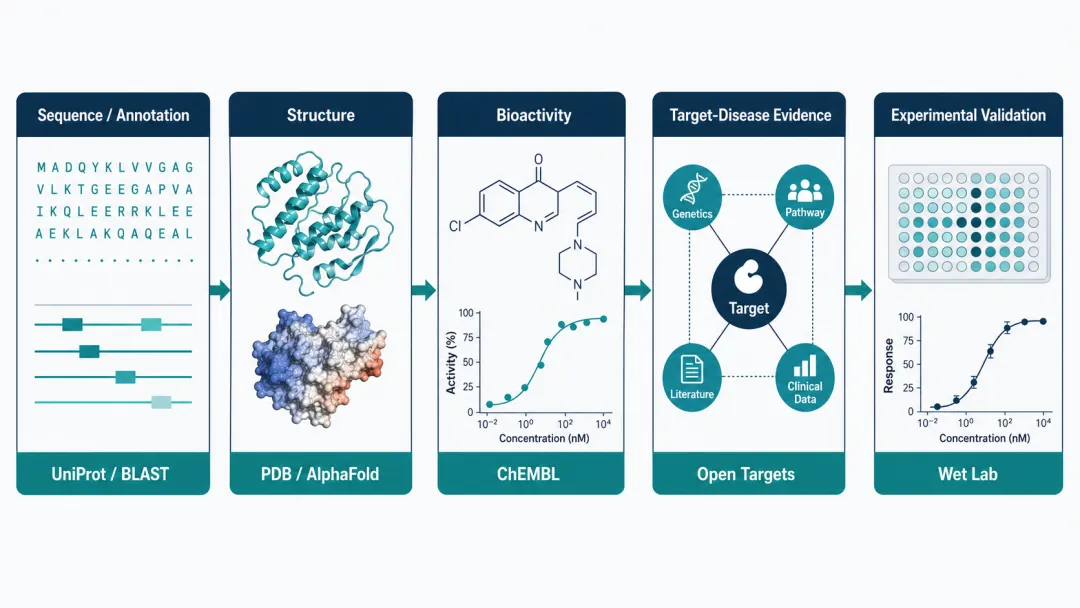
一、UniProt 回答的是:这个蛋白是谁,它有什么已知功能
AI 药物研发论文里,一个靶点通常首先会被映射到一个蛋白。这个时候,UniProt 往往是最基础的入口。
UniProt 的价值不只是给出一条蛋白序列。它更重要的作用是把蛋白名称、基因、物种、功能注释、结构域、亚细胞定位、变体、交叉引用和证据等级组织在一起。对于药物研发论文来说,这相当于给靶点建立了一个“身份档案”。
但读 UniProt 时要注意一个细节:不是所有条目的证据强度都一样。
UniProtKB/Swiss-Prot 是人工审阅条目,通常注释质量更高;UniProtKB/TrEMBL 主要是自动注释条目,覆盖面更广,但需要更谨慎使用。论文如果只写“根据 UniProt 注释,该蛋白具有某功能”,读者还要继续追问:这是 reviewed 还是 unreviewed?功能注释来自实验,还是同源推断?有没有对应的文献和证据标签?
在 AI 药物研发里,序列和注释常常是模型输入的第一层。如果这一层本身存在错误映射、同源误判或物种差异,后面的结构预测、分子筛选和靶点解释都会被放大偏差。
一个稳妥的读法是:UniProt 提供的是蛋白身份和功能背景,不是药物靶点有效性的最终证明。
二、PDB 回答的是:有没有实验结构,它的质量如何
结构生物学读者通常会自然区分实验结构和预测结构,但 AI 药物研发论文有时会把二者放在同一个图里展示,给人一种证据等级相近的印象。
PDB 的核心价值在于实验测定的三维结构。X-ray crystallography、cryo-EM、NMR 等方法得到的结构,为结合口袋、构象状态、配体相互作用和结构域组织提供了直接证据。
但“有 PDB 结构”并不等于“结构可以直接用于药物设计”。至少要继续看几个问题:
-
结构来自哪个物种? -
是全长蛋白,还是某个结构域? -
分辨率或模型质量如何? -
是否包含配体、辅因子或关键突变? -
构象是否对应生理状态? -
口袋区域是否完整、可信、可用于 docking?
很多 AI 论文会用 PDB 结构作为训练数据、benchmark 数据、docking 模板或结果解释依据。这里最容易出现的问题,是把一个局部结构、低分辨率结构或非生理构象,当成完整靶点结构来解释。
所以 PDB 提供的是结构层面的强证据,但它仍然需要质量检查和上下文判断。实验结构越接近研究问题,证据价值越高;结构越偏离真实生物场景,解释空间就越大。
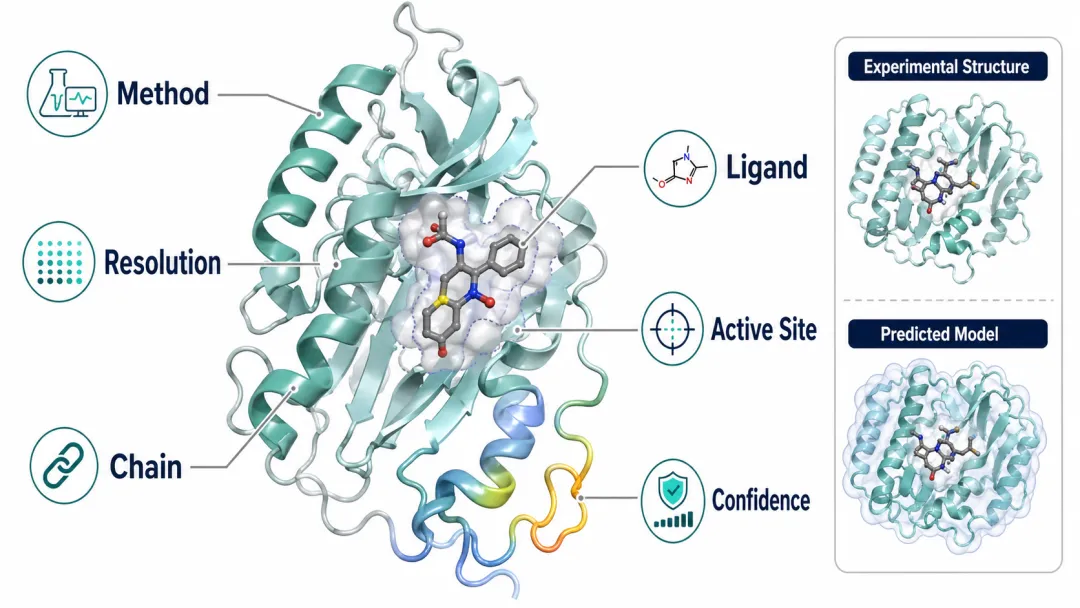
三、AlphaFold 回答的是:在缺少实验结构时,可能的折叠是什么
AlphaFold 数据库让大量蛋白拥有了可访问的结构预测模型,这对药物研发和功能假设生成非常有价值。尤其在没有 PDB 结构的蛋白、低研究程度蛋白和跨物种比较中,AlphaFold 可以显著降低结构探索的门槛。
但 AlphaFold 预测结构和 PDB 实验结构不能直接等价。
AlphaFold 更擅长预测单个蛋白或结构域的折叠。对于高度柔性区域、无序区域、构象变化、配体诱导构象、膜环境、蛋白复合物界面和真实结合口袋,仍需要谨慎解释。即使数据库已经扩展到大量蛋白结构预测和蛋白复合物预测,预测结构依然是计算证据,不是实验测定。
读 AI 药物研发论文时,如果作者用 AlphaFold 结构做 docking 或口袋分析,至少要看:
-
口袋区域的置信度是否足够高? -
关键残基是否位于低置信度区域? -
该蛋白是否有明显无序区? -
预测构象是否可能对应活性状态? -
是否有 PDB 同源结构、突变实验或功能实验支持? -
docking 结果是否经过湿实验验证?
AlphaFold 的正确用法,是帮助提出结构假设、缩小实验搜索空间,而不是替代结构测定和活性验证。
四、ChEMBL 回答的是:小分子和靶点之间有哪些已知活性证据
如果说 UniProt 和 PDB/AlphaFold 回答的是“靶点是什么、结构可能是什么”,ChEMBL 更接近药物研发中另一个核心问题:小分子和生物系统之间有没有可检索的活性数据。
ChEMBL 收录的是经过整理的生物活性信息,包括小分子、靶点、assay、结合或功能测定、ADMET 相关信息等。很多 AI 药物研发模型会用 ChEMBL 训练分子活性预测模型、构建 benchmark、寻找已知 ligand,或评估生成分子的相似性。
但 ChEMBL 的数据不能被简单理解为“某分子对某靶点有效”。它更像是一组结构化实验记录。不同 assay 之间差异很大:
-
binding assay 和 functional assay 回答的问题不同; -
IC50、Ki、Kd、EC50 不能随意混用; -
cell-based assay 可能包含膜通透性、代谢、毒性等复合因素; -
不同实验室、不同条件、不同蛋白构建体之间可能不可直接比较; -
inactive 数据和 negative data 是否完整,会影响模型判断。
很多 AI 论文的问题,不是用了 ChEMBL,而是没有说清楚怎么清洗 ChEMBL。比如是否去重,如何处理多个活性值,如何区分 assay 类型,如何避免同一化合物或高度相似化合物跨训练集和测试集泄漏。
对读者来说,看到 ChEMBL 训练集时,不妨先问一句:作者是在学习真实的药效规律,还是在学习数据库里重复出现的化学骨架和 assay 偏差?
五、Open Targets 回答的是:靶点和疾病之间有多少层证据
药物研发不是只要一个蛋白能结合一个小分子就够了。真正的问题是:调控这个靶点,是否有理由影响某种疾病?
Open Targets 的价值在于整合不同类型的 target-disease evidence。它可以把遗传学、基因组学、转录组、药物、动物模型、通路、文献等信息放到一个靶点-疾病关联框架中,帮助研究者做靶点优先级判断。
这类证据整合对 AI 药物研发尤其重要。因为模型可能会提出很多候选靶点或候选分子,但如果靶点和疾病之间缺乏遗传学、功能实验或临床相关证据,再漂亮的分子生成结果也只能停留在早期假设。
不过,Open Targets 的分数也不能被当作最终答案。它整合的是不同来源、不同证据等级、不同偏差结构的数据。文献挖掘、表达差异、动物模型、遗传关联和已知药物证据的含义并不相同。
更稳妥的方式是把 Open Targets 当作证据地图,而不是裁判。它帮助你发现证据来自哪里、集中在哪些维度、是否存在缺口。真正的靶点判断,还要回到具体疾病、机制、可成药性、安全性和实验验证。
六、一篇 AI 药物研发论文的数据链条应该这样拆
如果把这些数据源放在一起看,一篇 AI 药物研发论文常见的数据链条大致是:
Sequence / Annotation UniProt, Ensembl, BLAST
↓ Structure PDB, AlphaFold
↓ Bioactivity ChEMBL, assay records, ligand-target data
↓ Target-Disease Evidence Open Targets, literature, genetics, omics
↓ Model Task binding prediction, virtual screening, molecule generation, target prioritization
↓ Experimental Validation biochemical assay, cell assay, animal model, structural validation
这个链条里,每一层都能产生知识,也都可能引入偏差。
序列层可能有同源误判。结构层可能有构象问题。活性层可能有 assay 异质性。靶点证据层可能有疾病注释和文献偏倚。模型层可能有数据泄漏。验证层可能缺少真正独立的实验支持。
读论文时,最重要的不是把这些数据库名称背下来,而是判断作者有没有把不同证据层级分清楚。
如果一篇论文用 UniProt 说明蛋白功能,用 AlphaFold 做结构建模,用 ChEMBL 训练活性预测模型,再用 Open Targets 支持疾病相关性,那么它至少应该解释四件事:
-
蛋白身份和功能注释是否可靠; -
结构证据是实验结构还是预测结构; -
活性数据是否经过合理清洗和任务定义; -
靶点-疾病证据是否足以支持后续药物研发假设。
缺少任何一环,结论都应该相应降级。
七、读论文时的自检清单
以后看到 AI 药物研发论文,可以用下面这张清单快速扫一遍。
1. 靶点身份是否清楚
-
是否给出 UniProt accession 或 Ensembl ID? -
蛋白条目是 reviewed 还是 unreviewed? -
功能注释来自实验,还是自动推断? -
是否区分物种、isoform 和蛋白结构域?
2. 结构证据是否足够匹配问题
-
使用的是 PDB 实验结构还是 AlphaFold 预测结构?
-
结构覆盖的是全长蛋白还是局部结构域?
-
关键口袋或界面区域置信度如何?
-
是否考虑配体、辅因子、膜环境或构象变化?
3. 活性数据是否定义清楚
-
ChEMBL 数据来自 binding assay 还是 functional assay?
-
IC50、Ki、Kd、EC50 是否被混用?
-
是否处理重复记录、冲突记录和单位标准化?
-
是否避免相似化合物或同源靶点导致的数据泄漏?
4. 靶点-疾病证据是否分层
-
遗传学证据、表达证据、动物模型证据和文献证据是否被区分?
-
Open Targets 分数是否被解释为证据整合,而不是结论?
-
是否有功能实验支持靶点调控能影响疾病相关表型?
5. 型结果是否经过真正验证
-
benchmark 是否有外部测试集?
-
生成分子是否只是 docking 分数高,还是有实验活性?
-
是否报告失败案例和负结果?
-
是否公开代码、数据切分和模型参数?
这张清单的作用不是否定 AI 药物研发,而是帮助我们把“有趣的模型结果”和“可靠的药物研发证据”分开。
结尾:数据源不是装饰,而是论证结构
很多论文会把数据库名称写在方法部分,读者扫一眼就过去了。但在 AI 药物研发里,数据源不是背景材料,而是整篇论文论证结构的一部分。
UniProt 解决蛋白身份和功能注释问题。PDB 提供实验结构证据。AlphaFold 扩展结构假设空间。ChEMBL 连接小分子、靶点和活性记录。Open Targets 帮助把靶点放回疾病证据网络。
它们共同构成了一张从序列到结构、从活性到疾病证据的地图。
真正需要警惕的是,把这张地图上的不同层级压平成一句话:AI 发现了新药。
更准确的表达应该是:AI 基于已有序列、结构、活性和靶点证据,提出了一个值得进一步验证的候选假设。这个假设能走多远,取决于数据质量、证据等级和实验验证,而不是模型图画得多漂亮。
参考文献
-
ChEMBL,ChEMBL database homepage,https://www.ebi.ac.uk/chembl/。
-
ChEMBL,What is ChEMBL?,https://www.ebi.ac.uk/training/online/courses/chembl-quick-tour/what-is-chembl/。
-
ChEMBL,How is ChEMBL data curated?,https://www.ebi.ac.uk/training/online/courses/chembl-quick-tour/what-is-chembl/how-is-chembl-data-curated/。
-
UniProt / EMBL-EBI,About UniProt,https://www.ebi.ac.uk/uniprot。
-
UniProt,What is UniProt?,https://www.ebi.ac.uk/training/online/courses/uniprot-exploring-protein-sequence-and-functional-info/what-is-uniprot/。
-
UniProt,The UniProt databases,https://www.ebi.ac.uk/training/online/courses/uniprot-exploring-protein-sequence-and-functional-info/what-is-uniprot/the-uniprot-databases/。
-
RCSB PDB,About RCSB PDB,https://www.rcsb.org/pages/about-us/index。
-
RCSB PDB,RCSB PDB homepage,https://www.rcsb.org/。
-
AlphaFold Protein Structure Database,About AlphaFold DB,https://alphafold.com/。
-
EMBL,Millions of protein complexes added to AlphaFold Database shed light on how proteins interact,https://www.embl.org/news/science-technology/first-complexes-alphafold-database/。
-
Open Targets,Open Targets homepage,https://www.opentargets.org/。
-
Open Targets Platform Documentation,Target-disease associations,https://platform-docs.opentargets.org/associations。