 夜雨聆风
夜雨聆风





文献笔记|关于人类对AI接受度的元分析洞见
* 后台发送关键词“260426”即可获取相关文献
文献分享
题 目: From Tools to Agents: Meta-Analytic Insights into Human Acceptance of AI
作 者: Bingqing Li, Edward Yuhang Lai, Xin (Shane) Wang
来 源: Journal of Marketing (2026)
1
摘要
这篇论文讨论的不是“AI 好不好用”这么简单,而是当 AI 开始具备自主性、社会性和代理性之后,人们会如何重新评估它。作者用 61 篇文献、136 个研究、287 个效应量、119,358 名参与者做三层 meta-analysis,给出一个相当清楚的结论:整体上,当 AI 与人类被直接比较时,人们仍对 AI 保留小幅但稳健的负向反应(d = -0.150,95% CI [-0.220, -0.080]),但这种 reluctance 正在随时间减弱。
更重要的是,论文没有停在“AI aversion 仍然存在”这个层面,而是把影响接受的因素系统拆开:能力是最强的正向驱动;执行型角色与拟人化会显著压低接受;输入透明、generalist AI 与激励机制能在一定条件下提升接受;而道德相关和隐私相关任务会显著抬高接受门槛。
这篇文章最核心的贡献,不只在于量化效应,更在于重新组织问题。它把 AI 接受研究从单纯的 technology adoption 逻辑,推进到“AI as a tool + AI as an agent”的双重视角,并用 AI-task-user 加 UCD 的框架把设计、使用情境与用户条件放到同一张解释地图里。放在当前营销 AI 研究里,这是一篇很难绕开的核心文献。
2
研究背景
(一)为什么 AI 接受会成为营销与消费者研究的核心问题
从营销场景看,AI 早就不只是后台算法。它正在进入推荐、客服、内容生成、价格决策、金融建议、医疗辅助、招聘筛选、教育辅导等前台触点。只要 AI 开始直接影响消费者判断、用户体验或组织决策,‘人愿不愿意接受它’就不再是技术问题,而是市场问题、关系问题,也是制度问题。
过去几年关于 AI 的文献一直有一个明显分歧:有的研究强调 algorithm aversion,认为人们宁愿信人也不愿信 AI;也有研究强调 AI appreciation,发现当 AI 被描述为更准确、更客观或更高效时,用户会主动偏向 AI。作者认为,真正的问题不是哪一边“最终正确”,而是既有研究把太多不同情境混在一起讨论,却没有一个足够整合的解释框架。
这篇论文切入的时间点也很关键。随着 generative AI 和 agentic AI 发展,AI 已经越来越不像一个静态工具,而越来越像一个会交互、会行动、会做初步判断、甚至会代表用户执行任务的对象。也正因此,单纯用 TAM、DOI 或 UTAUT 去解释 AI 接受,解释力已经开始不够。
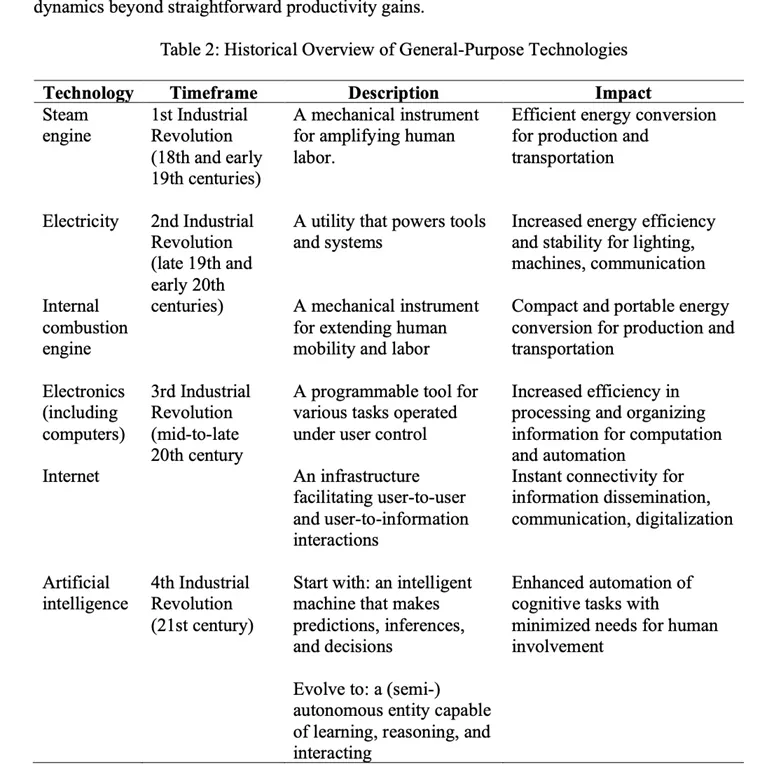
作者用 General-Purpose Technology 的历史脉络说明:与蒸汽机、电力、互联网等技术相比,AI 的特殊之处不只在于提升效率,更在于它逐步拥有了决策与互动特征。换句话说,AI 不是普通意义上的“更强工具”,而是开始带着代理性进入人的工作和消费流程。这正是本文需要重写 AI 接受问题的根本原因。
3
文献综述与理论基础
(一)既有研究主要沿着两条线展开
第一条线是 AI as a tool。它沿着技术接受与创新扩散的传统思路,关注 perceived usefulness、ease of use、compatibility、cost、reliability 等因素。站在这条线上,AI 被视为一种技术工具,人们会像评估其他技术一样评估它:是否好用,是否省事,是否值得采用。
第二条线是 AI as an agent。它更多借助社会回应理论与 CASA(Computers Are Social Actors)范式,强调当 AI 使用自然语言、具备人格线索、能够互动甚至代替人执行任务时,用户会像面对一个社会性对象那样回应它。此时,角色、控制感、拟人化、威胁感、自主权等变量就会进入判断。
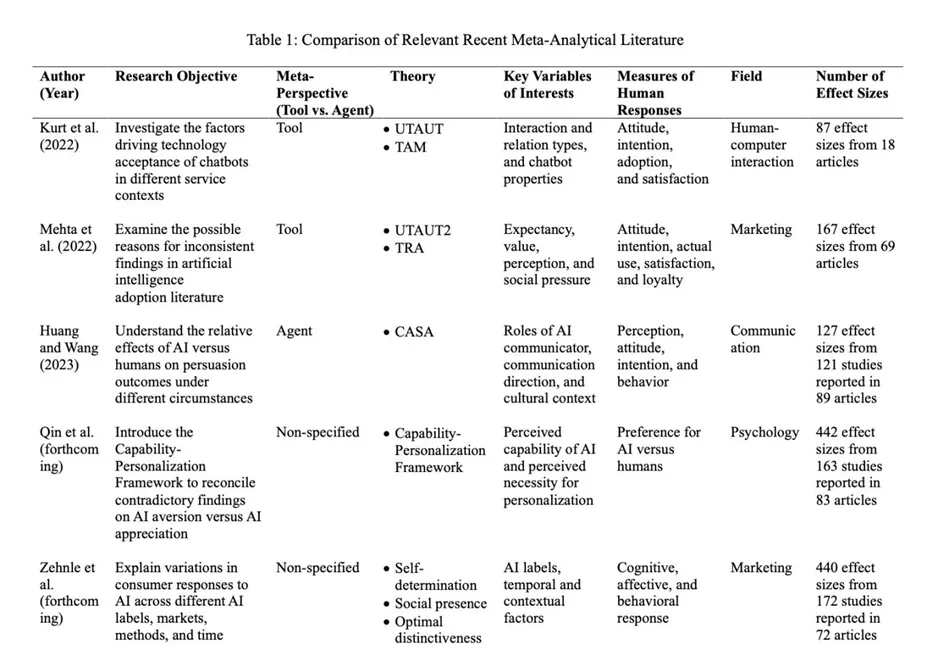


原文 Table 1 很有价值,因为它并不只是列前人文献,而是在说明本文到底补了什么缺口。已有 meta-analysis 往往要么站在工具视角,要么站在代理人视角,要么只讨论标签、市场、时间等外部差异。本文的不同在于:它把两条线合起来,并且把注意力放在 engineerable AI features 上,也就是企业、平台和设计者真正能改、能调、能沟通的 AI 属性。
(二)本文如何把两条理论线合到一起
作者没有简单把 tool 和 agent 两套理论并排摆放,而是进一步借助 Burton-Jones 等人的 system usage framework,并把它落到 User-Centered Design(UCD)框架里。这样一来,AI 接受就被理解为 AI 系统、任务情境和用户特征三者交互的结果,而不是某一个单点变量决定的。
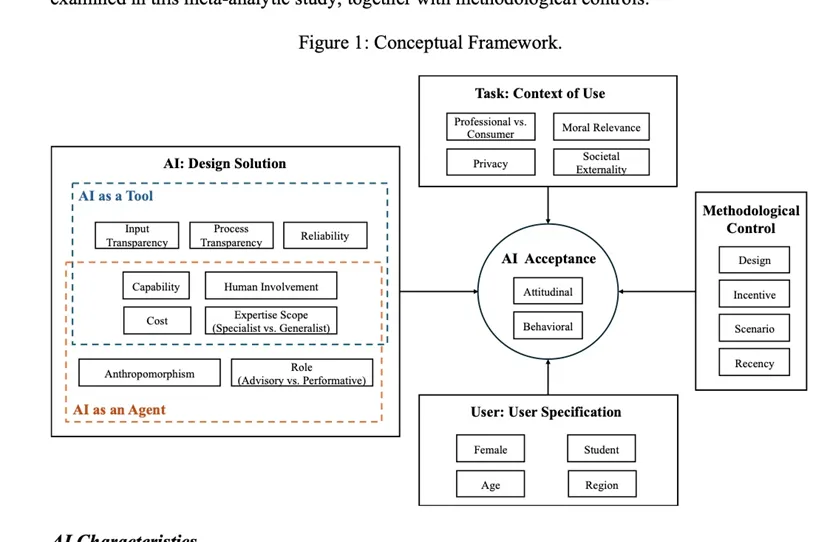
Figure 1 是全文最重要的结构图。它把 AI characteristics、task characteristics、user characteristics 与 methodological controls 放进同一张图里,同时把 capability、cost、human involvement 这类变量放在 tool 和 agent 的交叉地带。这个处理非常关键,因为它说明:很多变量之所以在不同研究里方向不一致,不一定是研究做错了,而是它们在不同心理视角下本来就可能产生相反作用。
(三)对文献综述部分的进一步理解
如果用更平实的话说,本文在做的事其实是:把“AI 到底是一个被人使用的工具,还是一个会与人发生角色关系的对象”这个问题,明确拉到台前。过去的 AI 接受研究更像在问‘它好不好用’,而这篇文章开始问‘人愿不愿意把事情交给它,以及交到什么程度’。这两种问题看起来只差一步,但解释逻辑其实已经变了。
4
研究问题、变量与文章结构
(一)核心研究问题
结合全文,作者实际在回答三个层层推进的问题。第一,人们整体上到底更偏向 AI,还是更偏向人类?第二,哪些 AI 特征会系统性影响接受,而且这些特征里哪些是可以被设计者主动调节的?第三,当 AI 从工具走向代理人时,原来的 adoption 逻辑会在哪些地方失效,或者至少需要被扩展?
(二)变量体系与理论预期
AI 特征方面,作者重点考察 capability、input transparency、process transparency、reliability、anthropomorphism、expertise scope、human involvement、role 与 cost。任务特征包括 professional vs. consumer、moral relevance、privacy、societal externality;用户特征包括 gender、age、region、student;方法控制变量包括 behavioral vs. attitudinal、design、scenario、incentive 与 recency。
(三)文章结构
从文章结构上看,这篇论文并不是传统的‘Study 1、Study 2、Study 3’式实验论文。它的逻辑是:先澄清 AI 作为 tool 与 agent 的双重定义,再回顾一般用途技术与 AI 接受相关研究,随后提出 conceptual framework;接着进入 literature search、inclusion criteria、coding scheme 与 three-level meta-analysis;最后再把结果收束到 UCD roadmap、theoretical implications 和 future research。
•先讲概念与理论背景,再给出统一框架。
•随后说明文献搜集、纳入标准、编码方式与统计模型。
•在结果部分先看总体效应,再看 AI / task / user / methodological controls 的回归系数。
•最后把发现翻译成 user-centered design 与未来研究议程。
5
研究设计、编码与分析策略
(一)文献搜集与纳入标准
作者采用了三步式搜集策略。第一,在 EBSCO Business Source Complete 中做系统搜索,并把 business、HCI、psychology、sociology 等相关学科一起纳入;第二,追踪三篇关于 algorithm aversion 的系统综述做前向与后向检索;第三,补充 ad-hoc 搜索,把更新近但前两轮未覆盖的文章找出来。最终初始样本共 2,488 篇。
纳入标准有四条,也相当严格:其一,必须是 experimental 或 quasi-experimental 研究,而且比较的是人对 AI 与人类代理的接受差异;其二,因变量必须测量 attitudinal 或 behavioral acceptance;其三,发表出口需要是高质量同行评审期刊或会议;其四,必须提供足够信息来统一计算 effect size。最后进入分析的,是 61 篇文献中的 136 个研究和 287 个效应量。
(二)编码方案
编码方面,作者先让两位编码者独立编码一个包含 54 个 effect sizes 的小样本,之后比较差异并讨论统一,再由一位编码者依照最终 coding scheme 完成剩余样本。这个流程虽然看起来常规,但对 meta-analysis 非常关键,因为一旦变量口径不稳,后面的模型再漂亮也没有意义。
Table 3 非常清楚地展示了本文‘怎么把不同研究压成同一套语言’。例如 role 被编码为 performative vs. advisory,anthropomorphism 被编码为是否具有人类外貌或语言线索,behavioral 则区分为行为测量还是态度测量。对后续做类似研究的人来说,这张表几乎可以直接当作变量设计参考。
(三)效应量、模型与稳健性检验
效应量统一使用 Cohen’s d,并设定 human equivalent 为基准组。也就是说,当 d 为正时,表示相较于人类,参与者对 AI 反应更积极;当 d 为负时,表示更偏向人类。作者强调,由于 effect sizes 嵌套在 studies 中,studies 又嵌套在 manuscripts 中,数据天然具有层级结构,因此不能简单用普通回归或传统两层模型带过。
因此采用 three-level hierarchical linear model。这个选择是合理的,因为它同时处理 study 内异质性和 study 间异质性。结果也显示,这个数据集的异质性很高:I² = 93.3%,Cochran’s Q = 4260.25,p < .0001。换句话说,这组文献本来就高度不一致,所以作者不是要把异质性消掉,而是要解释异质性来自哪里。
稳健性方面,作者做了 VIF 检查、改用 Hedges’ g、不同模型规格、Leave-One-Out、Least Absolute Deviation 估计以及发表偏差检验。总体结论是:除了 cost 变量稳定性较弱之外,其余主要发现方向相当稳,发表偏差也较小。这一点提高了全文结果的可信度。
严格说,这篇论文没有传统意义上的“实验部分”;它的实质方法,是把大量实验与准实验研究放进一套统一的编码与三层 meta-analysis 框架中重新分析。对文献笔记来说,这一点必须讲清楚,否则会误把一篇整合型研究写成单篇实验论文。
6
主要结果
(一)总体效应:AI 仍有轻微但稳健的接受阻力
截距模型显示总体效应 d = -0.150,95% CI = [-0.220, -0.080]。这意味着,当 AI 与人类被直接比较时,人们整体上仍略微更偏向人类而不是 AI。这里的关键词是“小幅但稳健”。它不是那种压倒性的拒绝,但也绝不是‘大众已经全面拥抱 AI’。
进一步拆分后,attitudinal acceptance 的效应是 d = -0.122,behavioral acceptance 的效应是 d = -0.174,而且两者没有统计显著差异。这说明人们不仅在态度上保留,而且一旦要真的行动,保留会更明显一些。换句话说,真正落到行为层面,AI 的门槛并没有比态度表述低。
(二)AI 特征结果
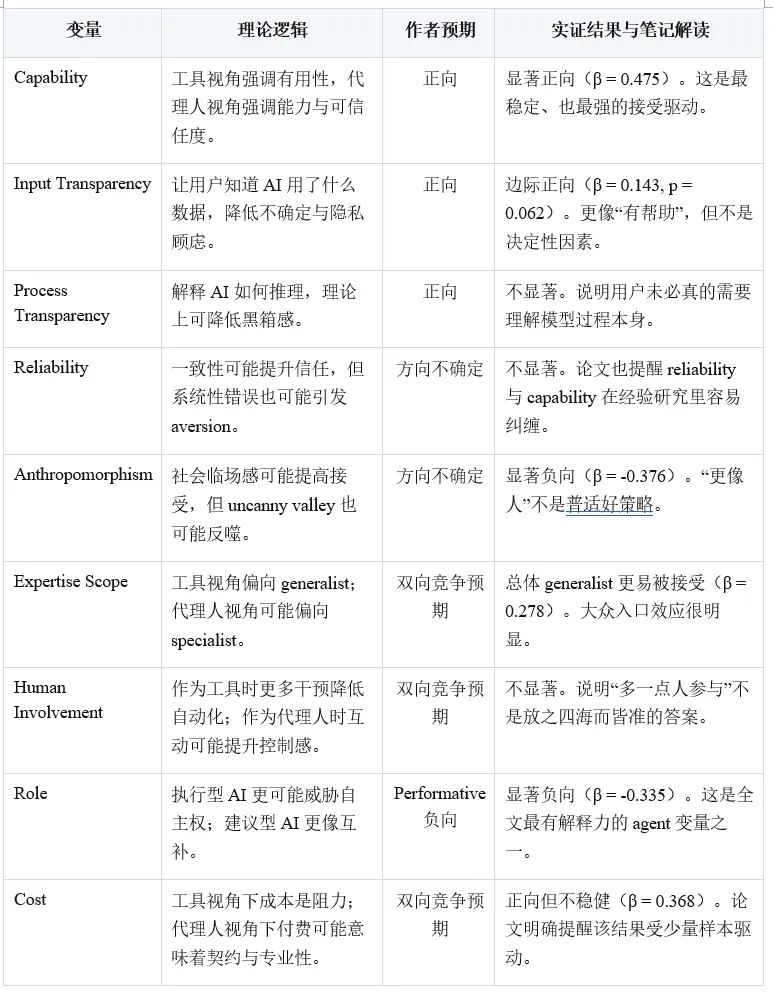
AI 特征里,capability 的系数最大也最稳(β = 0.475, p < .001)。这说明即使本文强调 agent 视角,工具逻辑也并没有过时。用户首先还是会问:你到底能不能做得更好?在任何想推广 AI 的场景里,这个问题都绕不过去。
Input transparency 边际正向,而 process transparency 不显著,这个组合很有现实意味。很多用户未必要理解模型结构,但会在意 AI 输入了什么数据、这些数据是否与自己的目标一致、是否触碰隐私边界。相比之下,纯算法过程解释未必能真正转化成接受。
Agent 视角下最关键的两个结果,是 performative role 的显著负向和 anthropomorphism 的显著负向。前者表明,用户会区分“AI 帮我想”与“AI 替我做”;后者则提醒我们,越像人的 AI 并不一定越讨喜,尤其当它的拟人程度不足以支撑高社会性期待时,反而会引发不适和戒备。
另外,generalist AI 的正向系数也很值得注意。作者原本讨论的是双重视角下可能出现的反向预期,但最终数据更支持 generalist。这和过去两年大模型扩散路径高度一致:对大多数用户来说,一个‘先什么都能帮一点’的通用入口,比一个起步就高度专门化的 AI 更容易被接受。
(三)任务、用户与方法控制变量
任务变量里,moral relevance 与 privacy 都显著负向。这两个结果非常关键,因为它们说明当任务牵涉伦理判断与敏感信息时,人们不是简单从效率出发,而是会把责任、公平、解释性与被对待方式一起带进来。相比之下,societal externality 在总体模型里并不显著。
用户变量里,gender 与 age 没有稳定差异,English-speaking countries 的接受略高(β = 0.191, p = .012)。方法上,behavioral outcome 的系数显著更低,incentive 显著提升接受,recency 呈正向趋势。这几个结果合在一起说明:AI 接受既受真实任务回报影响,也在随社会使用经验累积而变化。
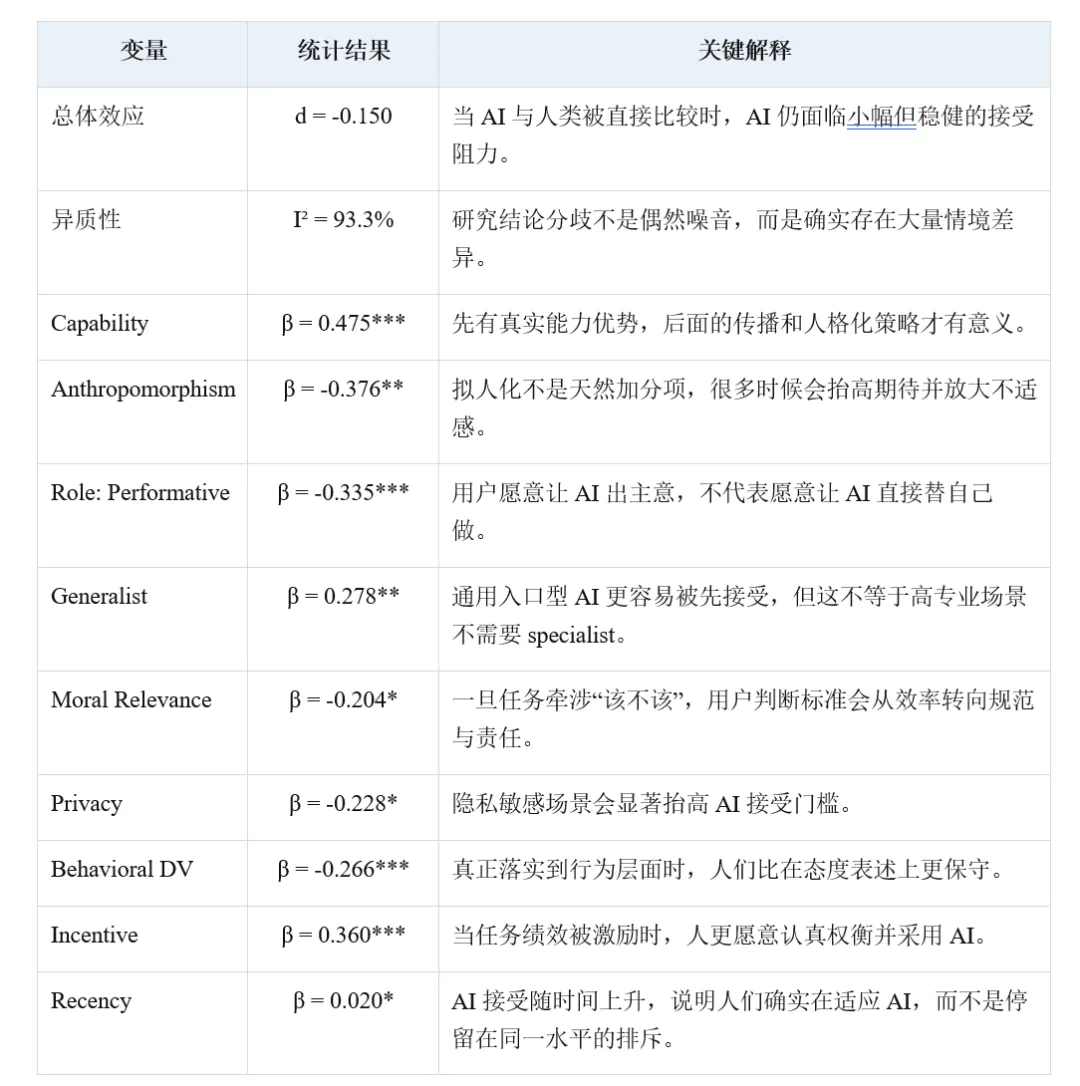
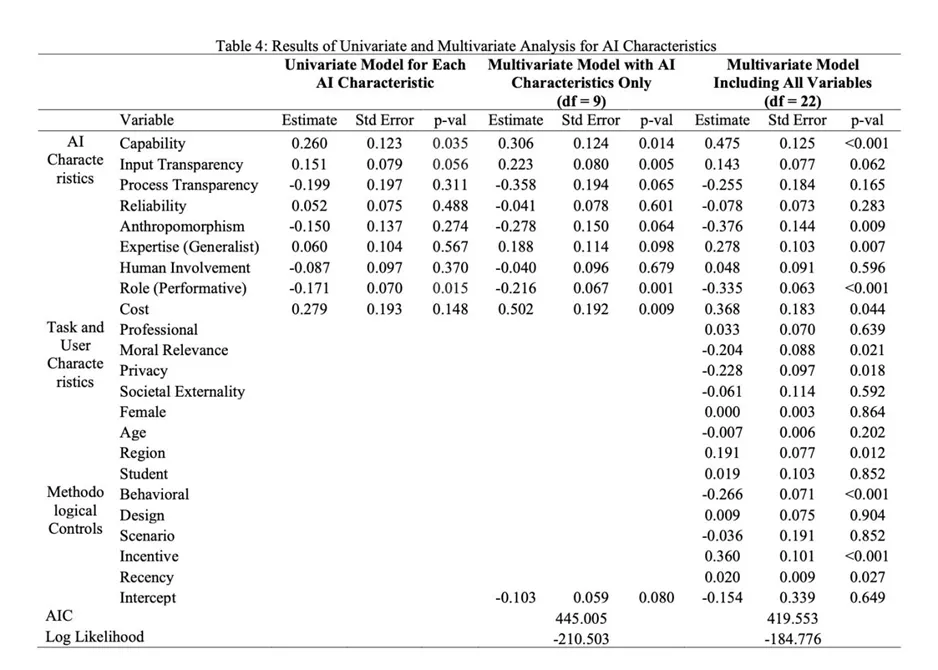
如果只用一句更平实的话概括结果,可以写成:人们并不是天然排斥 AI,而是在不同场景里用不同标准衡量它 。当 AI 只是帮手时,大家主要看能力与便利;当 AI 开始像代理人一样行动时,大家会突然在意角色、边界、控制感、伦理和隐私。
7
理论贡献与管理启示
(一)理论贡献
第一,本文最重要的理论推进,是把 AI 接受明确区分为 tool perspective 和 agent perspective。传统 adoption 模型更擅长解释‘有没有用、好不好学、值不值得采用’,而 agent 视角开始解释‘它是否越界、是否威胁自主权、是否被当作社会对象来评价’。这两套机制并不是互斥的,而是会在同一个 AI 系统上同时发生。
第二,论文把 engineerable AI features 作为核心切口,而不是只讨论感知变量。这个处理很有营销价值,因为 capability、role、transparency、anthropomorphism、cost 这些都不是抽象态度,而是设计者和企业真的可以调节、配置、包装和沟通的属性。
第三,作者把 AI、task、user 放进同一套 UCD 框架里,使得 AI 接受研究不再只是单一变量解释,而更像一个系统设计问题。对后续文献来说,这种组织方式很重要,因为它给出了一个能够继续扩展的研究母框架。
(二)管理启示
就管理实践而言,这篇文章至少有五条非常直接的启示。第一,优先提升 capability,而不是过早押注人格化包装。能力优势仍然是最硬的接受基础。第二,AI 产品在落地时更适合先以 advisory 形态进入用户流程,而不是一开始就做成高自主的 performative agent。
第三,透明设计要优先回答‘你用了什么数据、这些数据从哪里来、会不会留下’这类输入边界问题,而不是默认用户最关心模型推理细节。
第四,generalist AI 在扩散初期有明显优势,但越进入高专业、高责任、高风险场景,就越需要重新考虑 specialist、human oversight 与制度安排。
第五,在 moral 和 privacy 敏感场景中,企业不能只靠 persuasion 去提升接受,更需要治理、审计、责任分配与制度背书。
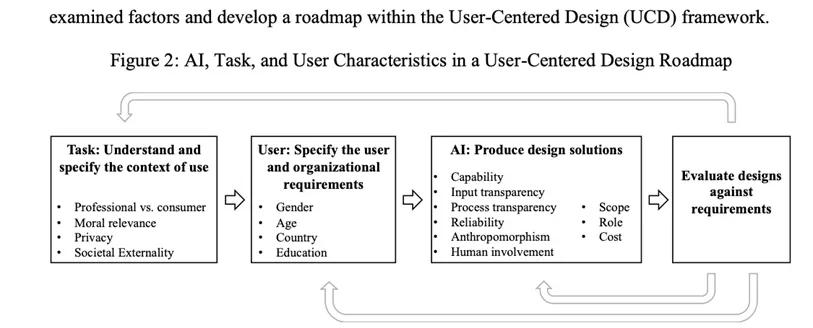
Figure 2 的价值在于把结果真正翻译成 design roadmap。它提醒实践者:先界定任务情境,再明确用户要求,然后再配置 AI 特征,最后持续评估设计是否满足要求。也就是说,AI 接受不是一句广告语能解决的,而是一个从任务定义到产品设计再到市场沟通的系统工程。
8
局限、未来研究与讨论总结
(一)局限与未来研究
这篇文章的局限并不小,但也都很诚实。第一,meta-analysis 只能分析文献中已经被操作化和可提取的变量,因此 personalization、social influence、prior AI experience 等很多今天很重要的因素,还没有被充分纳入。第二,process transparency 与 cost 的样本变异较少,作者也明确指出 cost 结果不够稳定。
第三,用户维度整体仍偏粗,只覆盖 gender、age、region、student 这类基础变量,而没有更深入地展开 psychographic 与 behavioral heterogeneity。第四,本文虽然讨论 tool 与 agent 两套视角,但它本质上仍是在既有文献上做统合,未来更理想的做法,是直接在新实验里操纵‘用户把 AI 看成工具还是代理人’,更明确地识别因果机制。
(二)讨论与总结
从研究议程来看,AI 接受研究的重心,正在从 adoption 逻辑慢慢转向 boundary 逻辑。以前更常问的是‘AI 能不能替代人、效率高不高、用户会不会采用’,现在更常问的其实是‘人愿不愿意把什么事交给它,以及交到什么程度’。这个变化非常细,但一旦看清楚,很多看似矛盾的文献结果就会变得容易理解。
作者对拟人化与执行型角色的提醒尤其值得重视。现实里很多团队会本能地把 AI 往“更像人、更会做事”方向推,因为这看起来更先进。但这篇论文表明,用户并不一定按‘更先进’来评价,而是会先问:系统是否动到了自己的控制权,是否要求把责任也一起交出去。
如果用一句更平实的话总结全文,可以写成:当 AI 还只是工具时,人主要看能力和效率;当 AI 开始像代理人时,人开始看角色、边界、控制、伦理与隐私。这也是为什么这篇文章不只是一篇总结文献,而更像是在给下一阶段的 AI 营销研究换问题框架。

分享作者 | GPT5.4
推送编辑 | 李秀秀
