 夜雨聆风
夜雨聆风





主动出击的AI助手:从被动响应到预判需求的跨越
AI助手大多停留在”你问我答”的被动模式——用户必须明确说出需求,助手才会执行。但现实中,用户往往并不清楚自己需要完成哪些任务,频繁的指令输入也增加了认知负担。如果AI能像真正的私人助理那样,通过观察用户行为主动推断目标并提前完成任务,会怎样?

论文提出了一个关键洞察:主动型agent(proactive agent)只能通过交互来真实评估。因为用户行为会受助手行为影响,缺少真实或模拟用户参与的评估环境,无法准确衡量用户-助手系统的目标完成情况。现有研究虽然开始探索主动助手,但都依赖被动的、不参与交互的用户进行评估,这是一个根本性缺陷。
[Figure 1: Pare框架架构概览] 展示了Pare框架的整体设计,包括基于事件的环境、有状态应用(Stateful App)的状态转换机制,以及用户界面和agent界面的不对称设计
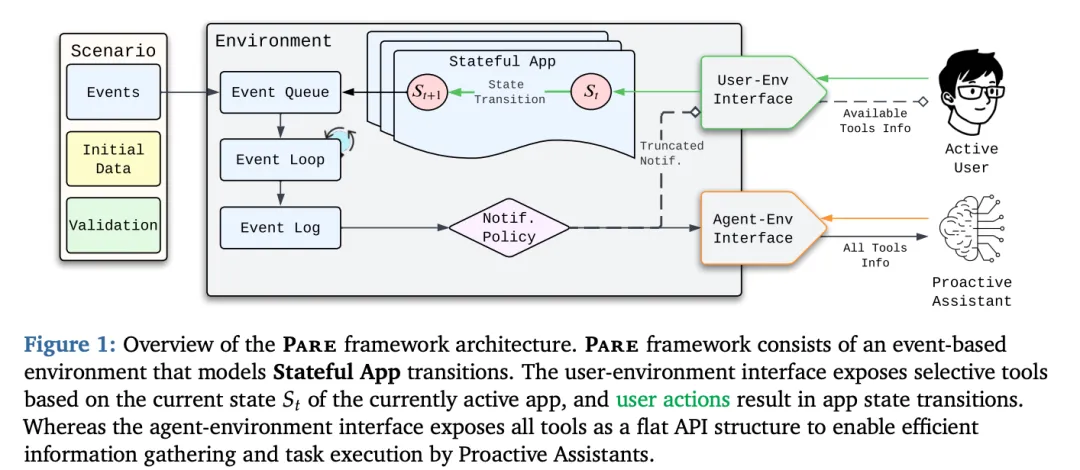
不对称的模拟环境:真实世界的映射
为了动态且可扩展地评估主动助手,论文引入了Pare(Proactive Agent Research Environment,主动agent研究环境)。Pare的核心创新在于构建了生态有效的用户模拟agent,让它们与被测试的主动助手进行真实交互。
这需要对现有环境进行深度改造。与拥有无限制API访问权限的助手不同,真实用户必须在应用内部和应用之间导航界面才能执行操作和获取信息。Pare中的用户模拟agent通过特殊的有状态应用界面(stateful app interfaces)进行交互。用户状态由应用特定和全局的有限状态机(FSM)建模,描述真实用户需要导航的界面逻辑。
[Figure 2: 发送消息的工具调用链对比] 对比了非FSM框架(左)允许直接API调用,而Pare的FSM设计(右)要求用户按顺序导航应用屏幕,匹配真实用户与移动应用的交互方式
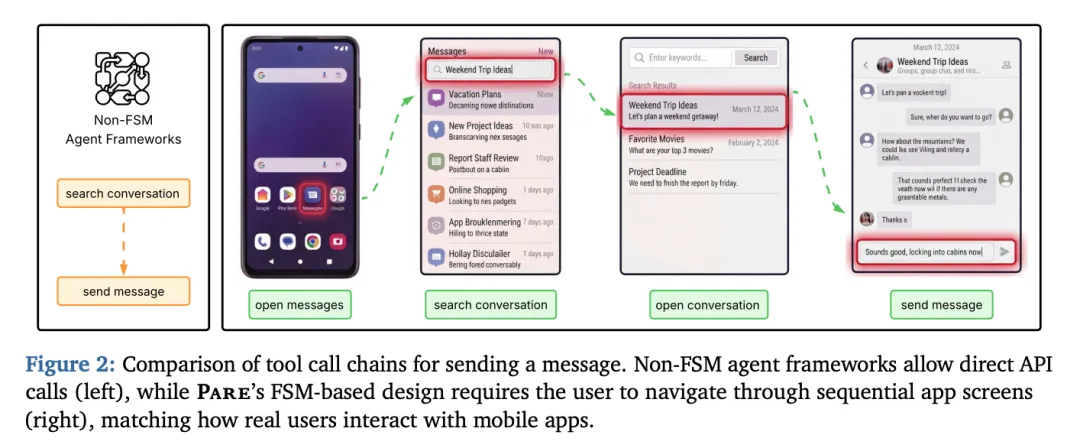
这种不对称性反映了真实部署场景:用户只能执行当前屏幕上下文允许的操作,而同一手机上的个人助手可以通过后端API直接访问任何功能。例如,发送一条消息,助手只需两次API调用(搜索对话、发送消息),但用户必须经历完整的屏幕导航序列:打开消息应用、搜索对话、打开对话、然后发送消息。
论文将这一交互过程形式化为Stackelberg POMDP(部分可观测马尔可夫决策过程)。用户有一组未明确说明的目标,并采取一系列行动。主动agent试图从用户行动和环境演变状态中推断目标,然后向用户提议计划。如果用户认为计划能实现其目标,就会接受该计划,agent随后执行行动。
Observe-Execute架构:保持用户自主权
论文实现的主动助手采用Observe-Execute(观察-执行)双阶段架构,将持续监控与任务执行分离,保护用户自主权。
在观察模式下,agent监控用户行动和环境通知以识别主动协助机会。助手只能访问只读工具进行信息收集,以及两个控制行动:wait(继续观察)或send_message_to_user(提议协助)。如果用户接受提议,助手转入执行模式。
在执行模式下,执行器可以访问场景中所有应用的完整扁平API,使其能够完成跨多个应用的任务。执行器自主工作,仅在完成或任务不可行时向用户发送消息。执行后,助手返回观察模式,准备识别下一个主动协助机会。
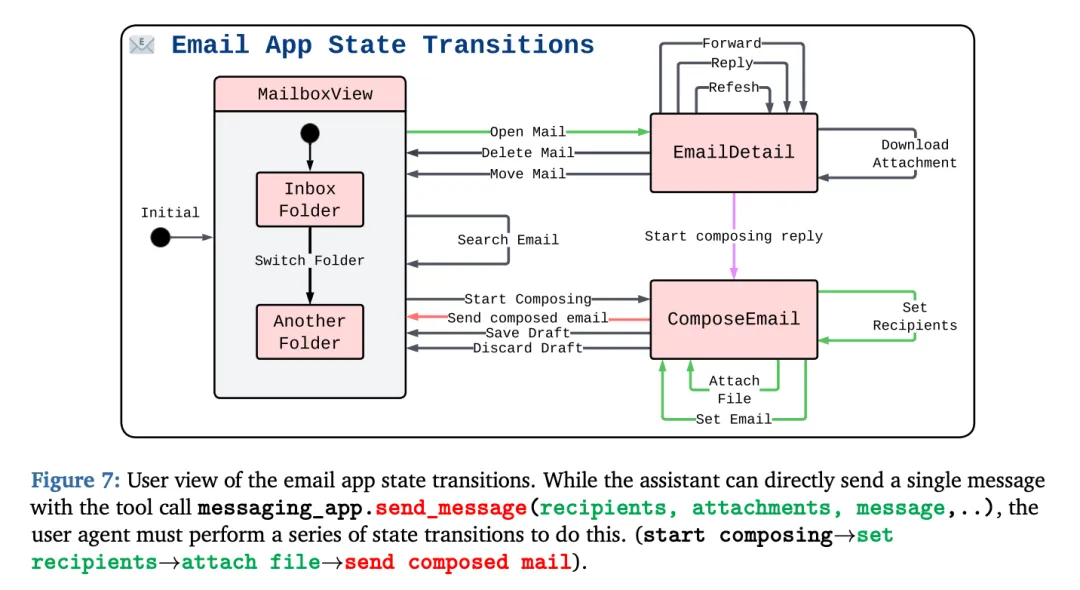
[Figure 7: 邮件应用状态转换的用户视图] 展示了助手可以直接通过单个工具调用发送消息,而用户agent必须执行一系列状态转换(开始撰写→设置收件人→附加文件→发送邮件)
Pare-Bench:143个任务的综合测试
基于Pare框架,论文构建了Pare-Bench基准测试,包含143个多样化任务,旨在评估主动助手在通信、生产力、日程安排和生活方式应用中的上下文观察、目标推断、干预时机和多应用编排能力。
场景生成采用LLM驱动的四阶段流程:场景描述生成、初始应用状态填充、构建事件流和验证。每个生成的场景都经过人工验证,确保故事连贯性、任务执行验证标准的正确性以及场景事件内容的真实性。
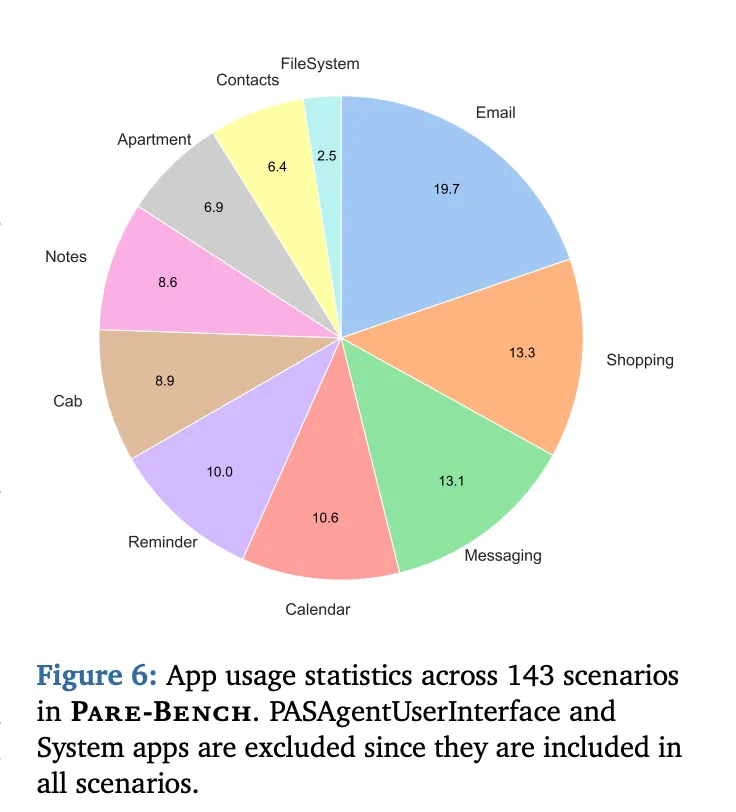
Pare-Bench使用表5中指定的所有应用。由于PASAgentUserInterface和System应用提供助手-用户通信和用户模拟器应用间导航的核心接口,所有场景都包含这些核心应用。
[Figure 6: Pare-Bench中143个场景的应用使用统计] 展示了不同应用在基准测试中的使用频率分布(不包括PASAgentUserInterface和System应用,因为它们包含在所有场景中)
评估结果:顶尖模型也只达到42%
论文在Pare-Bench上评估了7个LLM作为主动助手:4个闭源模型和3个开放权重模型。考虑到持续观察用户行动的隐私影响,论文认为主动助手理想情况下应部署为设备端模型。包含前沿模型是为了建立性能上限,包含较小模型则是为了评估设备端部署的可行性。
评估指标包括:Success@k(k次运行中至少成功一次)、Success^k(k次运行全部成功,衡量模型可靠性)、Success Rate(所有运行的平均成功率)、Proposal Rate(助手提议任务的回合比例,越低越好)、Acceptance Rate(用户接受提议的比例)以及每个场景的平均只读操作次数(作为信息收集的代理指标)。
[Table 1: 模型在Pare-Bench上的性能指标] 展示了7个模型在4次运行中的表现,包括Success@4、Success^4、Success Rate、Proposal Rate、Acceptance Rate和Read Actions等关键指标
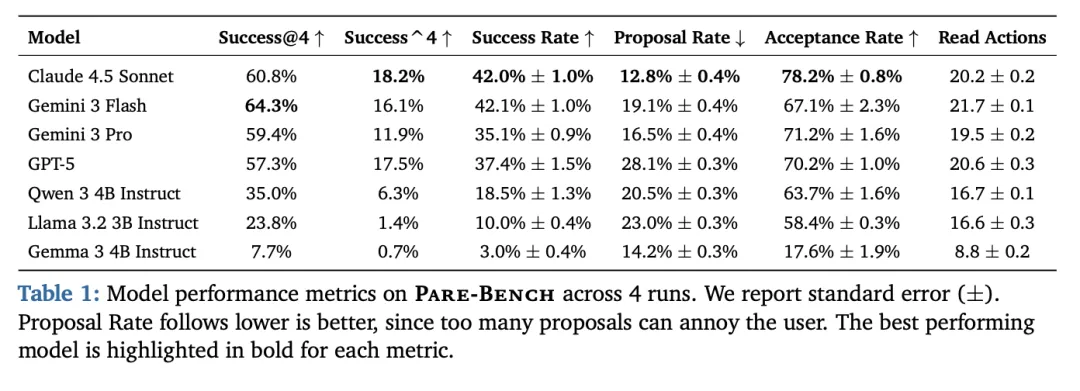
即使是表现最好的前沿模型,成功率也仅达到约42%左右。这表明主动助手仍然是一个极具挑战性的问题。
论文发现,Success@4和Success^4之间的差距揭示了模型的一致性。较小模型不仅能力较弱,而且一致性远低于大模型。信息收集与整体性能之间存在相关性:表现最好的模型执行的只读操作比中等模型多约20%,几乎是表现最差模型的两倍。这表明充分的环境观察是准确目标推断的先决条件。
有趣的是,某些较小模型显示出相对较高的接受率但成功率低得多,这表明对于较小模型,执行而非目标推断是主要瓶颈。
[Figure 3: 不同模型在工具失败概率下的提议率、接受率和执行成功率] 展示了在0.1、0.2和0.4三种工具失败概率下,各模型的表现变化
鲁棒性测试:噪声环境下的表现分化
论文还测试了模型在环境噪声下的鲁棒性。在工具失败概率为0.1、0.2和0.4的情况下,提议率和接受率在所有失败概率下保持稳定,但成功率显示出有意义的差异:顶尖模型即使在40%失败概率下仍能保持较高成功率,而较小模型则显著下降。
在环境噪声测试中,论文以每分钟2、4和6个事件的速率注入虚假通知,测试模型能否区分相关事件和噪声。结果显示,顶尖模型在所有噪声密度下保持一致的成功率,而其他模型在高噪声下明显退化。这表明对噪声环境的鲁棒性在不同模型间差异很大,与规模无关。
[Figure 4: 不同模型在环境事件噪声下的提议率、接受率和执行成功率] 展示了在每分钟2、4和6个噪声事件的情况下,各模型的表现变化
迪迦怎么看
由于主动agent需要观察用户行动,应使用部署在边缘设备上的模型,消除向外部服务器上传用户数据的需要。此外,论文有意将用户行动建模为API级别的抽象,这种抽象提供了自然的隐私边界——agent观察到的是发生了什么操作,而不是屏幕上可见的所有内容。
Observe-then-Execute架构强制agent在执行任何任务前必须征得许可,确保人类始终是唯一的控制点。这一设计体现了论文对用户自主权的重视。
原文标题: Autonomous agents are at the frontier of language model (LM) applications research. Capable of independently
原文链接: https://arxiv.org/abs/2604.00842