 夜雨聆风
夜雨聆风





AI如果只是概率,那何来的智能呢?


Hello 各位朋友们,周末愉快哈!你有没有听过这样一个关于AI的科普说法:现在的大模型本质上只是一个概率模型,它不过是在按概率预测下一个Token(字或词)……
面对这个说法,很多人心里都会产生一个疑问~如果大模型仅仅是在玩“概率接龙”,它为什么会表现得那么聪明?它有时不仅比你我更会讲道理,甚至还能说出一些我们自己都没想明白的深刻见解!
从预测下一个字到“智能涌现”,这中间到底发生了什么?“基于概率预测下一个字”这可以说是近年来关于大模型科普里最准确但也最容易产生误导的说法了~
这种表述给人一种错觉,😂仿佛大模型就像手机里的“输入法联想”一样,只是在后台查一个频率表,然后选出最常见的那个词填上去。
但实际上,为了能够正确且有逻辑地预测出下一个字,大模型背后要做的事情远比查表复杂得多,它必须去学习海量的知识、规律和逻辑!
咱们可以想象一下大模型的训练过程:
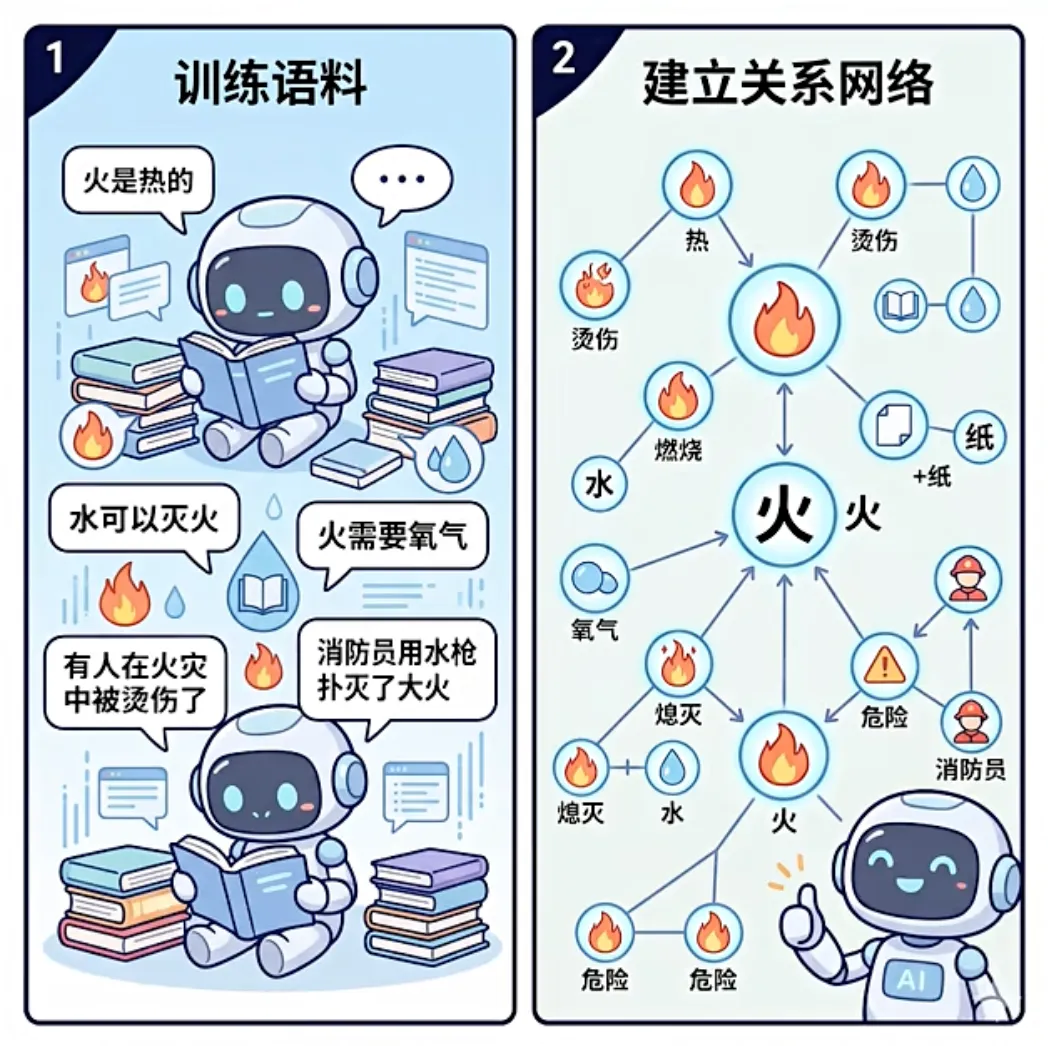
基于这些内容,模型建立起了一套极其复杂的关系网络:它知道了火和“热”有关,热和“烫伤”有关;它明白了火需要氧气,隔绝氧气就能灭火;它推导出火加纸等于燃烧,而这种危险状态需要消防员的介入。
在这里,模型其实并没有死记硬背下原始语料中的每一个句子,而是从中提炼出了深层的关系和规律!
同样的道理,从“火”延伸到整个世界,模型阅读了互联网上几乎一切的文本:
为了在所有的领域都能够精准预测下一个Token,它在内部建立起了一个跨越所有领域的巨大关系网。这个网络就是我们所说的“世界的压缩模型”!它不是真实的世界本身,但它内部装载着这个世界如何运转的大量规律、知识和逻辑。
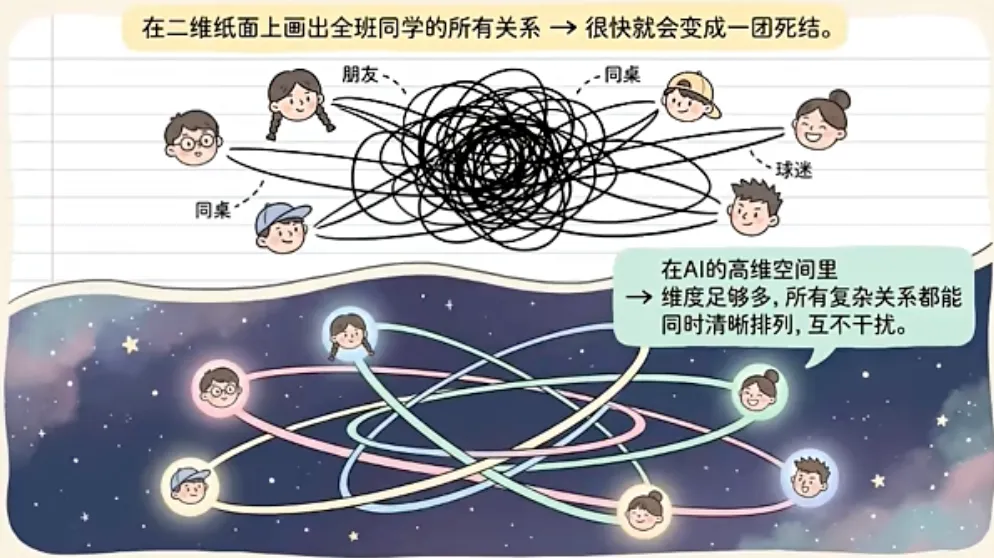
你可以想象这个庞大的关系网络复杂到了什么程度——它的维度已经远远超过了人类能够直观理解的范畴!

我们人类理解世界习惯于用二维、三维去思考,最多到四维基本上就是认知极限了。但大模型的工作空间是几千甚至上万个维度!每一个概念在里面都是一个坐标点,概念之间的关系变成了复杂的几何结构。
维度极高有一个巨大的好处:它能够同时表达极其海量的关系。打个简单的比方哈:
但如果给你足够多的维度,所有的关系就能在同一时间被清晰地表达出来!
大模型就工作在这样一个高维空间里,因此很多在我们人类看来毫无关系的东西,在模型的高维空间里可能是紧挨着的;很多我们以为差不多的东西,在模型空间里也可能离得比较远。
从某种意义上说,模型确实看到了我们看不到的一些隐秘关系和模式,因为它工作的维度比我们高得多。这就是为什么大模型有时会显得极其聪明,不仅能帮助我们思考,甚至能帮助我们提升认知!
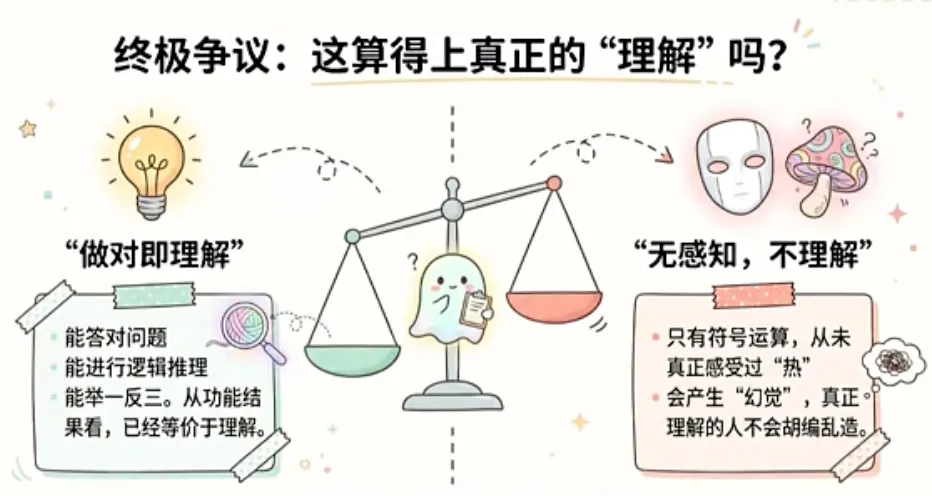
不过,关于“大模型的智能问题”在学术界其实一直存在深刻的争议:模型到底有没有真正“理解”这些规律和知识?
有一派的观点认为“功能等价于理解”!
你问它问题它能答对,你给它难题它能推理、能举一反三,既然从结果来看它已经做到了,那这就等同于它已经理解了。
但另一派观点认为这根本不叫理解!
首先,大模型没有物理世界的感知基础。你教它“火是热的”,但它这辈子从来没有真正感觉过“热”是什么。它所有的行为只是高级的“符号操作”,它并不知道符号背后指向的真实物理体感是什么,所以不能叫理解。
更重要的是它还时不时会产生“幻觉”,一个真正理解事实的人是不会犯那种低级错误的。这个问题目前全世界最聪明的大脑们也没有想明白,更没有达成共识。所以客观地说,大模型构建了一个异常强大的“功能性世界模型”~
在功能表现上,它已经足够出色,好到可以完成很多以前只有人类真正理解后才能完成的任务。但它是不是具备了和人类同等意义上的“理解”呢?这其实取决于我们如何定义“理解”本身。
大模型的出现不仅是一场技术突破,它更像是一面镜子,正在倒逼我们去重新思考:智能到底是什么?
欢迎关注我们《商业分析家》研究团队,可以私信或者在评论区留言探讨交流,用数据还原真相,助你打破信息差 🔎看透商业本质!






免责声明:本文仅供探讨交流,行业及专家调研数据可能存在偏差与局限;在任何情况下,本公众号所载信息、意见不构成对任何人的投资建议,所述买卖的出价或征价,评级、目标价、估值、盈利预测等分析判断亦不构成对具体证券或金融工具在具体价位、具体时点、具体市场表现的投资建议。对任何直接或间接使用本公众号所载信息和内容或者据此进行投资所造成的任何一切后果或损失,公众号《商业分析家》及作者本人不承担任何法律责任,感谢您的关注!



