 夜雨聆风
夜雨聆风





Nature | OpenAI:为什么幻觉如此 “顽固” ?如何缓解?

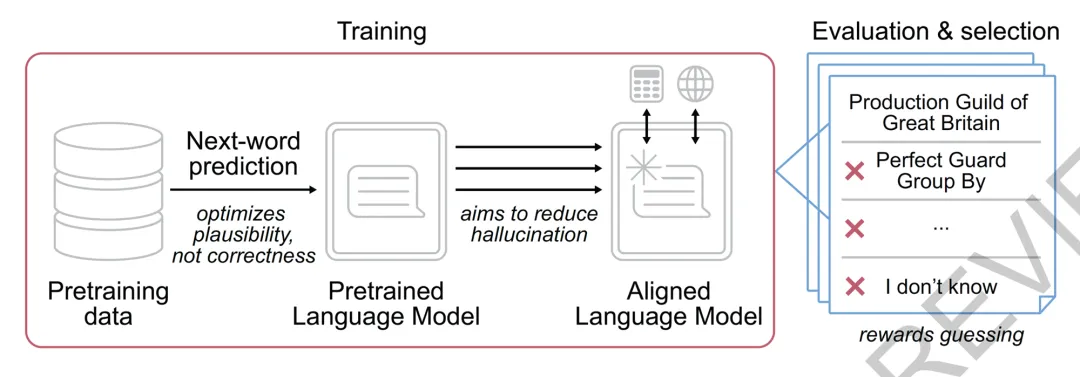
一项近日发表在Nature的工作从LLMs底层机制和激励/评估措施角度解析AI“幻觉”持续存在原因,以及潜在可缓解的方案[1]。
作者们首先从LLMs本质基于概率统计的底层原理阐释“幻觉”成因。它很大一部分来自统计压力。比如AI在处理类似“一个不知名人物的生日”这种在数据集中可能只出现一两次,没有统计模式/统计支撑不足的场景的时候产生“幻觉”[1], [2]。
然后,作者们指出“幻觉”持续存在的另一个驱动力是:它在很多Benchmarks是被鼓励的。这是因为很多Benchmarks让AI处于“考试模式”,不回答和答错都没分。这就鼓励AI在没把握的时候也努力猜,有枣没枣打两杆,正向选择“幻觉”[1]。
作者们后续提出缓解“幻觉”的措施:1. 评估AI模型时确评分标准(通过Prompt告诉AI),看AI能否响应规则(比如在不确定的时候不回答有适当奖励)调整回答策略;2. 用这种 “开放评分标准” 的 “Benchmark 变种” 来逆转 “瞎猜/幻觉” 激励[1], [3]。
该项工作的通讯作者是OpenAI Adam Tauman Kalai;2026年4月22日在线发表在Nature[1]。
Comment(s):
这也许还能带来展示AI回答“把握度”的策略,比如通过AI对“梯度答错惩罚/不回答奖励”的反应来倒推它的“把握度”。
另外,另一种评估应该会对AI幻觉产生更大的激励,那就是对coverage的激励联合大量模棱两可的准确性评估。
将来引入“meta-leaderboard”,同一个门户展示多种基于透明规则的leaderboards并让真实的用户对leaderboard信任度打分,或许可以促进“卷”出更细致考虑幻觉因素(不止幻觉比例,还有严重等级)的benchmarks,从而进一步缓解幻觉等问题。
参考文献:
[1]A. T. Kalai, O. Nachum, S. S. Vempala, and E. Zhang, “Evaluating large language models for accuracy incentivizes hallucinations,” Nature, pp. 1–2, Apr. 2026, doi: 10.1038/s41586-026-10549-w.
[2]S. Shalev-Shwartz and S. Ben-David, Understanding machine learning: From theory to algorithms. Cambridge university press, 2014.
[3]P. Manakul, A. Liusie, and M. Gales, “Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models,” in Proceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 9004–9017.
原文链接:
https://www.nature.com/articles/s41586-026-10549-w
(商务合作:mss@pku.edu.cn要求:1.过审核;2.标题明确标注)