 夜雨聆风
夜雨聆风





Spring AI Alibaba:国内大模型生态完整接入指南
Spring AI Alibaba:国内大模型生态完整接入指南
适读人群:需要接入通义/百炼/国内大模型的Java工程师
阅读时长:约16分钟
文章价值:Spring AI Alibaba完整配置,国内主流模型一网打尽
先说一件真实的事
老王他们公司给政府客户做了一个AI助手项目,甲方要求:必须用国内的AI服务,数据不能出境,最好是阿里云或者华为云的产品。
老王之前用Spring AI接的是OpenAI,好在Spring AI Alibaba的API设计和Spring AI高度一致,切换成本不大。但他还是折腾了两天,卡在了几个地方:API Key的格式、模型名称的写法、以及怎么同时接多个国内模型做路由。
把他踩过的坑整理成这篇文章。不只是通义千问,把国内主流模型的接入方式都梳理清楚。
国内大模型生态全景
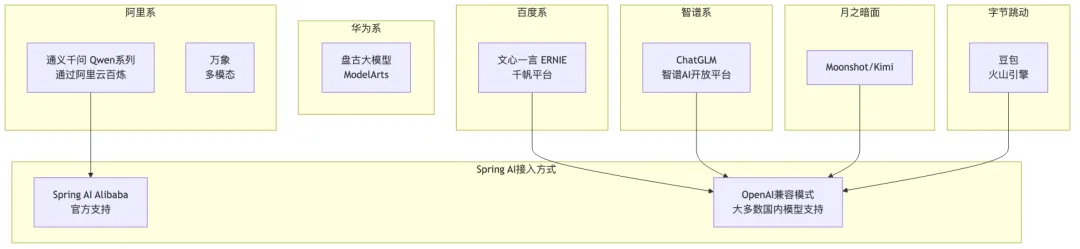
大多数国内模型都提供了兼容 OpenAI 格式的 API,这意味着可以直接用 Spring AI 的 OpenAI 接入,只需改 base-url 和模型名称。
Spring AI Alibaba 接入通义千问
Spring AI Alibaba 是阿里官方维护的 Spring AI 扩展,对通义/百炼系列有最好的支持。
快速开始
第一步:获取API Key
登录 阿里云百炼控制台,在”API KEY管理”中创建Key。
第二步:添加依赖
<dependencyManagement> <dependencies><!-- Spring AI Alibaba BOM --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-bom</artifactId> <version>1.0.0.2</version> <type>pom</type> <scope>import</scope> </dependency><!-- Spring AI BOM --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>1.0.0</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies></dependencyManagement><dependencies><!-- Spring AI Alibaba --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter</artifactId> </dependency><!-- 如果需要向量数据库 --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-pgvector-store-spring-boot-autoconfigure</artifactId> </dependency></dependencies>第三步:配置
spring:ai:dashscope:api-key: ${DASHSCOPE_API_KEY} # 从环境变量读取,不要硬编码chat:options:model: qwen-max # 可选:qwen-max/qwen-plus/qwen-turbotemperature: 0.7max-tokens: 2048enable-search: false # 是否开启互联网搜索embedding:options:model: text-embedding-v3 # 最新的Embedding模型通义系列模型选型:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
第四步:基础代码
@ConfigurationpublicclassAlibabaChatConfig {@BeanpublicChatClient chatClient(DashScopeChatModel chatModel) {returnChatClient.builder(chatModel) .defaultSystem("你是一个专业助手,请用简洁准确的中文回答问题。") .build(); }}@Service@Slf4jpublicclassQwenChatService {privatefinalChatClient chatClient;privatefinalDashScopeChatModel chatModel;publicQwenChatService(ChatClient chatClient, DashScopeChatModel chatModel) {this.chatClient = chatClient;this.chatModel = chatModel; } /** * 普通对话 */publicString chat(String message) {return chatClient.prompt() .user(message) .call() .content(); } /** * 流式对话 */publicFlux<String> streamChat(String message) {return chatClient.prompt() .user(message) .stream() .content(); } /** * 动态切换模型(比如简单问题用turbo省钱) */publicString chatWithModel(String message, String modelName) {return chatClient.prompt() .options(DashScopeChatOptions.builder() .withModel(modelName) .build()) .user(message) .call() .content(); }}接入百炼向量模型(RAG必备)
通义的Embedding模型质量不错,特别是 text-embedding-v3:
@ConfigurationpublicclassEmbeddingConfig {@BeanpublicVectorStore vectorStore(DashScopeEmbeddingModel embeddingModel,JdbcTemplate jdbcTemplate) {// 使用PGVector存储,Embedding用通义的模型PgVectorStoreConfig config = PgVectorStoreConfig.builder() .withTableName("ai_vectors") .withEmbeddingDimension(1536) // text-embedding-v3的维度 .build();returnnewPgVectorStore(jdbcTemplate, embeddingModel, config); }}@ServicepublicclassQwenRagService {privatefinalChatClient chatClient;privatefinalVectorStore vectorStore;publicString queryWithRag(String question) {return chatClient.prompt() .advisors(newQuestionAnswerAdvisor(vectorStore,SearchRequest.defaults().withTopK(5))) .user(question) .call() .content(); }}兼容OpenAI格式接入其他国内模型
大多数国内模型都提供了兼容OpenAI格式的API,直接用Spring AI的OpenAI接入器:
# ============ 百度千帆(文心一言)============spring:ai:openai:api-key: ${QIANFAN_API_KEY}base-url: https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshopchat:options:model: ernie-4.0-8k---# ============ 智谱AI(ChatGLM)============spring:ai:openai:api-key: ${ZHIPU_API_KEY}base-url: https://open.bigmodel.cn/api/paas/v4/chat:options:model: glm-4-flash # 免费模型---# ============ Moonshot(Kimi)============spring:ai:openai:api-key: ${MOONSHOT_API_KEY}base-url: https://api.moonshot.cn/v1chat:options:model: moonshot-v1-8k---# ============ 豆包(字节跳动)============spring:ai:openai:api-key: ${DOUBAO_API_KEY}base-url: https://ark.cn-beijing.volces.com/api/v3chat:options:model: doubao-pro-32k代码层面完全一样,只是配置不同,这就是Spring AI抽象层的价值。
多模型路由:按业务场景选最优模型
实际项目中经常需要同时使用多个模型,比如简单问题用便宜快速的,复杂问题用贵但准确的:
@ConfigurationpublicclassMultiModelConfig {// 高质量模型(贵,慢)@Bean("premiumChatClient")publicChatClient premiumChatClient(DashScopeChatModel chatModel) {returnChatClient.builder(chatModel) .defaultOptions(DashScopeChatOptions.builder() .withModel("qwen-max") .build()) .build(); }// 经济模型(便宜,快)@Bean("economyChatClient")publicChatClient economyChatClient(DashScopeChatModel chatModel) {returnChatClient.builder(chatModel) .defaultOptions(DashScopeChatOptions.builder() .withModel("qwen-turbo") .build()) .build(); }}@Service@Slf4jpublicclassSmartModelRouter {@Qualifier("premiumChatClient")privatefinalChatClient premiumClient;@Qualifier("economyChatClient")privatefinalChatClient economyClient; /** * 根据任务复杂度自动选择模型 */publicString smartChat(String message) {TaskComplexity complexity = assessComplexity(message); log.info("任务复杂度: {},使用模型: {}", complexity, complexity == TaskComplexity.HIGH ? "qwen-max" : "qwen-turbo");return complexity == TaskComplexity.HIGH ? premiumClient.prompt().user(message).call().content() : economyClient.prompt().user(message).call().content(); }privateTaskComplexity assessComplexity(String message) {// 简单规则判断(可以用更复杂的分类模型)if (message.length() > 500) returnTaskComplexity.HIGH;if (message.contains("分析") || message.contains("对比") || message.contains("总结") || message.contains("推理")) {returnTaskComplexity.HIGH; }returnTaskComplexity.LOW; }enumTaskComplexity { HIGH, LOW }}通义的特有能力:联网搜索
通义千问支持联网搜索,在需要实时信息的场景非常有用:
@ServicepublicclassSearchAwareChatService {privatefinalDashScopeChatModel chatModel; /** * 开启联网搜索,获取实时信息 */publicString chatWithSearch(String question) {DashScopeChatOptions options = DashScopeChatOptions.builder() .withModel("qwen-max") .withEnableSearch(true) // 开启互联网搜索 .build();ChatResponse response = chatModel.call(newPrompt(List.of(newUserMessage(question)), options));return response.getResult().getOutput().getContent(); }}注意:开启联网搜索会增加延迟(通常1-3秒额外延迟),按需使用。
费用估算与成本控制
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
成本控制关键代码:
@ServicepublicclassCostAwareChatService {privatefinalChatClient chatClient;privatefinalMeterRegistry meterRegistry;// 每用户每日Token预算privatestaticfinalintDAILY_TOKEN_BUDGET = 10000;privatefinalMap<String, AtomicInteger> userTokenUsage = newConcurrentHashMap<>();publicString chatWithBudget(String userId, String message) {// 检查预算int usedTokens = userTokenUsage .computeIfAbsent(userId, k -> newAtomicInteger(0)) .get();if (usedTokens >= DAILY_TOKEN_BUDGET) {return"今日AI使用额度已用完,请明天再试。"; }// 预估Token数int estimatedTokens = estimateTokens(message);if (usedTokens + estimatedTokens > DAILY_TOKEN_BUDGET) {return"本次请求可能超出今日额度,请缩短问题或明天再试。"; }String response = chatClient.prompt() .user(message) .call() .content();// 更新用量 userTokenUsage.get(userId).addAndGet(estimatedTokens + estimateTokens(response));return response; }privateint estimateTokens(String text) {// 简单估算:中文字符约1.5 token,英文约0.3 token/字符long chineseCount = text.chars() .filter(c -> c >= 0x4E00 && c <= 0x9FFF) .count();long otherCount = text.length() - chineseCount;return (int)(chineseCount * 1.5 + otherCount * 0.3); }}常见问题
|
|
|
|
|---|---|---|
|
|
|
sk-xxx,确认没有多余空格 |
|
|
|
|
|
|
|
|
|
|
|
max-tokens配置 |
|
|
|
|
小结
Spring AI Alibaba 让接入国内大模型变得极其简单,核心就两步:加依赖、改配置。代码层面几乎不需要改。
选型建议:
-
默认用 qwen-plus:性价比最好 -
高质量场景用 qwen-max -
简单高频场景用 qwen-turbo降成本 -
Embedding 用 text-embedding-v3
其他国内模型都支持 OpenAI 兼容格式,只需改 base-url 和 model,对接成本极低。
老王的那个政府项目顺利上线了,甲方很满意,国产化要求全部满足,系统稳定运行。
觉得有收获,点个在看让更多人看到。
还没关注的,欢迎关注「老张聊AI转型」,设为星标不错过每一篇更新。
遇到类似问题或有不同思路,欢迎在评论区留言,我认真回每一条。
本文由「老张聊AI转型」原创发布,转载请注明出处