 夜雨聆风
夜雨聆风





【论文速递】CoG:给AI加装上结构指南针,破解知识图谱推理僵局
【文献信息】
-
题目:CoG: Controllable Graph Reasoning via Relational Blueprints and Failure-Aware Refinement over Knowledge Graphs
-
作者:Yuanxiang Liu, Songze Li, Xiaoke Guo, Zhaoyan Gong, Qifei Zhang, Huajun Chen, Wen Zhang (Zhejiang University)
-
发表期刊:arXiv预印本(2026年4月)
-
关键词:知识图谱推理、双系统理论、关系蓝图、可控推理、大模型智能体
笔记整理:杭州智慧矩阵
论文链接:
https://arxiv.org/pdf/2601.11047
01
研究背景
在大模型应用的落地过程中,我们常常惊叹于LLM(大语言模型)强大的语言生成能力。然而,在面对需要严谨逻辑的知识图谱问答(KGQA)任务时,LLM却经常“翻车”。
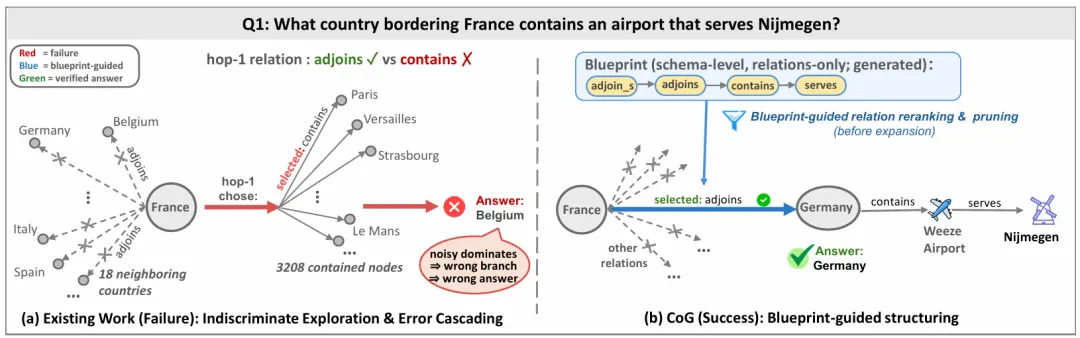
为什么?因为LLM容易陷入“认知僵化”(Cognitive Rigidity)。在复杂的图谱搜索中,模型往往采用单一的搜索策略,一旦遇到邻居节点的噪声干扰,或者因为局部语义匹配而选错了路径,就会导致“一步错,步步错”的级联错误,最终陷入死循环无法自拔。现有的图谱Agent(如ToG, PoG等)虽然灵活,但在复杂场景下表现极不稳定。主要存在两大痛点:
-
盲目探索导致的错误级联:Agent像无头苍蝇一样,仅凭局部语义相似度去扩展节点。一旦早期选错(比如把“包含”误认为“毗邻”),就会暴露在巨大的噪声候选集中,导致不可逆的轨迹偏离。
-
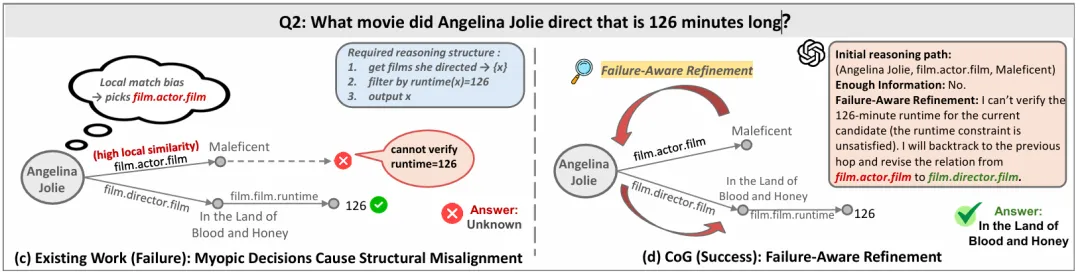
近视决策导致的结构错位:过分依赖局部的语义匹配,往往忽略了全局的逻辑约束。模型容易陷入局部最优解,选出看似相关但逻辑结构错误的关系(例如在需要“导演”的地方选了“演员”),导致推理停滞。
今天要介绍的这篇来自浙江大学的论文 CoG,提出了一套极具启发性的解决方案。它借鉴了人类的“双系统理论”(直觉与理性),让AI拥有了“结构指南针”和“纠错安全网”,在多项基准测试中大幅超越了现有的SOTA方法。
02
研究问题
论文提出了一个核心挑战:如何在充满噪声的邻居节点和不完整的图谱结构中,实现可控且稳健的推理?
作者认为,不能仅仅依赖LLM的参数化知识,也不能盲目地遍历图谱。我们需要一种机制,既能给LLM一个“全局导航”,又能让它在撞南墙时知道“回头是岸”。
03
论文贡献
CoG 的核心贡献在于它是一个无需训练(Training-free)的框架,它通过模拟人类的思维模式,完美解决了上述问题:
-
关系蓝图(System 1):模仿人类的“快思考”(直觉),利用从历史数据中提取的关系蓝图,作为软性结构约束,快速稳定搜索方向,过滤噪声。
-
失败感知优化(System 2):模仿人类的“慢思考”(理性),当检测到推理受阻或证据不足时,主动介入,进行反思和回溯,修正错误路径。
-
性能卓越:在CWQ、WebQSP和GrailQA等多个基准测试中,CoG不仅显著优于PoG、ToG等现有方法,还展现了极强的零样本(Zero-shot)泛化能力。
04
研究方法
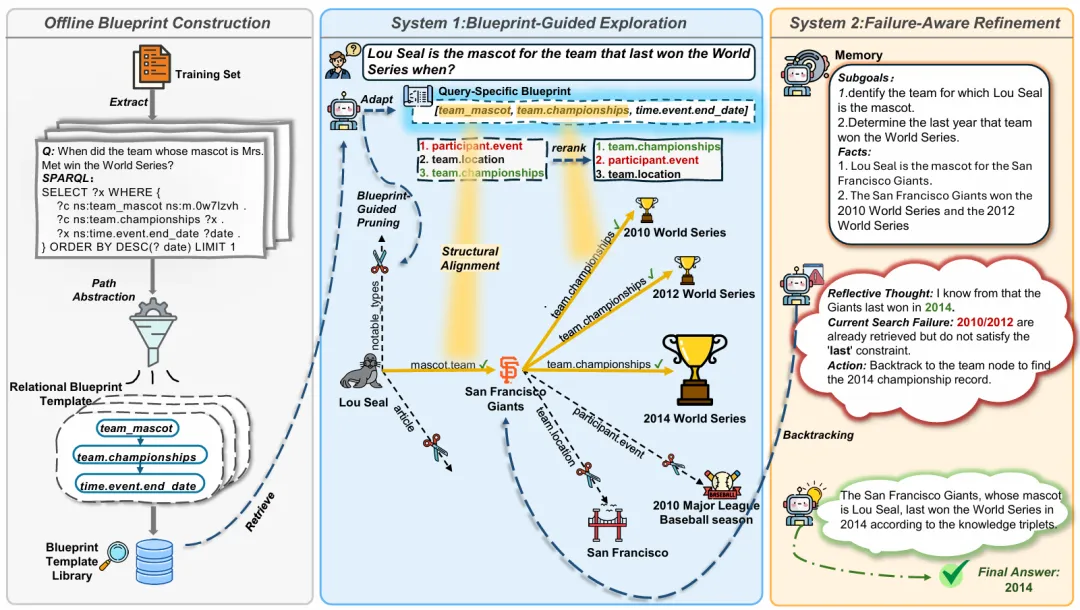
CoG 的设计灵感来源于诺贝尔奖得主丹尼尔·卡尼曼的双系统理论。它将推理过程拆解为两个协同工作的系统。
-
离线构建“关系蓝图”库
-
在推理开始前,CoG 会先对训练数据进行“脱敏”处理。它剥离具体的实体,只保留关系路径的逻辑结构(例如:出生地 -> 首都),构建出一个“关系蓝图模板库”。
-
作用:这就像是给AI准备了一本“地图册”,虽然没见过具体的路,但知道路的结构应该是怎样的。
-
在线蓝图引导探索 (System 1:直觉导航)
在回答新问题时,CoG 会从“地图册”中检索或生成一个针对该问题的关系蓝图 。
-
蓝图适配:即使问题没见过,CoG 也能利用LLM将历史蓝图改写适配到新问题上。
-
引导重排:在图谱搜索的每一步,CoG 不仅看局部语义(哪个像),更要看结构对齐度(哪个符合蓝图)。它通过计算候选关系与蓝图槽位的对齐分数,来重新排序候选节点。
-
效果:这就像是给搜索加上了“磁力导航”,即使周围有很多干扰项(噪声),只要不符合全局结构,就会被自动过滤掉。
-
失败感知优化 (System 2:理性纠偏)
这是CoG的“安全阀”。System 1虽然快,但遇到图谱不完整或蓝图失效时也会犯错。
-
诊断:当搜索陷入停滞(Stagnation)或无法验证约束时,System 2会被触发。
-
反思与回溯:LLM会充当“裁判”,审查当前的推理轨迹,诊断出导致偏离的“高风险决策点”,然后进行受控回溯(Controlled Backtracking),修正之前的错误选择,重新探索。
-
兜底:如果实在找不到验证路径,System 2会基于已验证的片段进行有根据的推断,避免模型胡编乱造。
05
实验过程
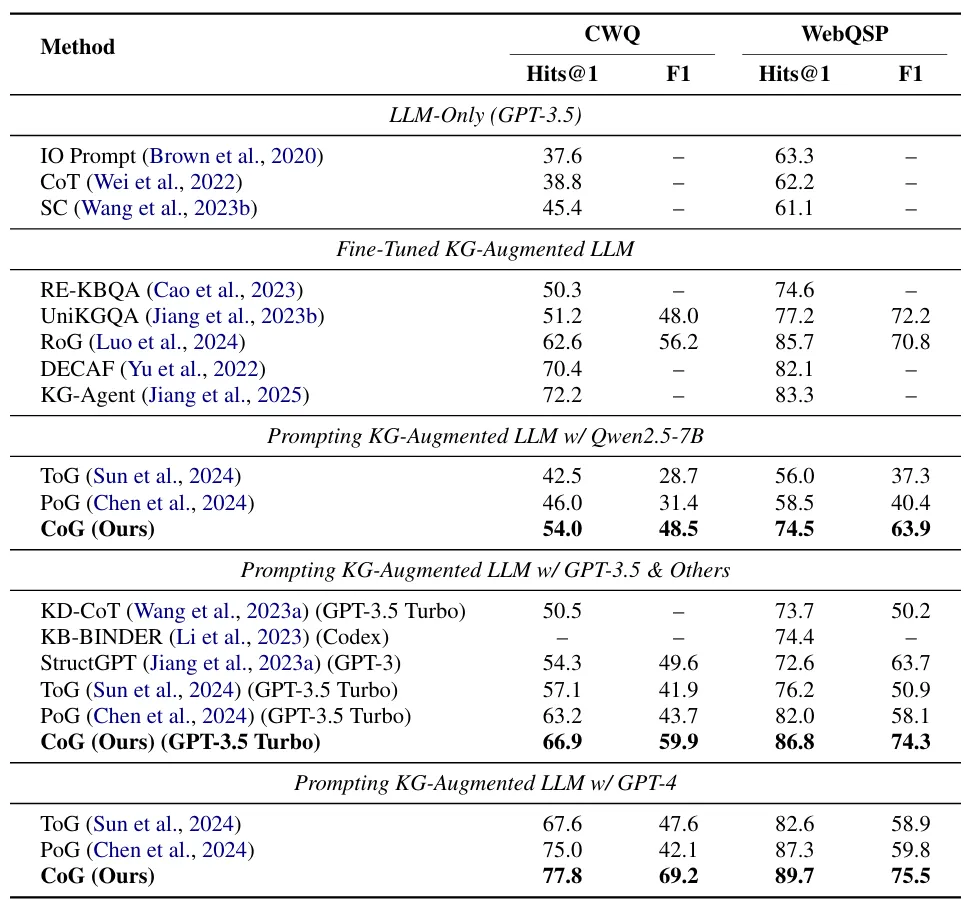
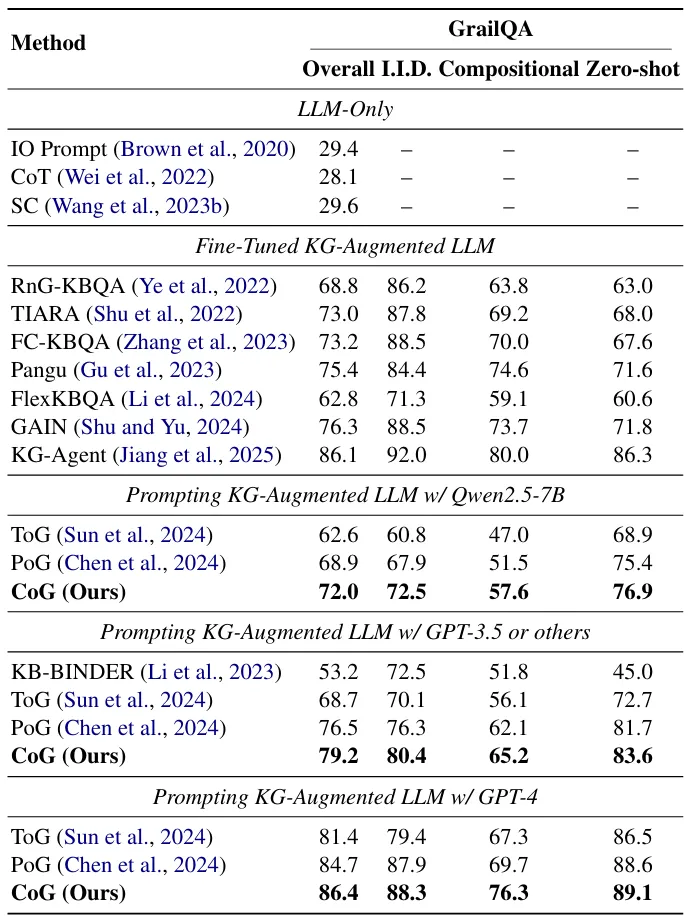
研究团队在三个代表性的多跳KGQA基准上对CoG进行了评估:CWQ(复杂Web问题)、WebQSP(简单多跳)和GrailQA(泛化能力测试)。
实验结果亮点:
-
全面超越:在GPT-3.5和GPT-4上,CoG均显著优于最强的基线方法PoG。例如在CWQ上,GPT-4版本的CoG比PoG高出近4个点(77.8 vs 75.0),且F1分数大幅提升,说明CoG能找到更完整的答案集。
-
零样本鲁棒性:在GrailQA的Zero-shot(零样本)设置下,CoG展现了惊人的泛化能力,准确率高达83.6%,远超ToG(72.7%)和PoG(81.7%)。这证明了“关系蓝图”不是死记硬背,而是真正学到了逻辑结构。
-
小模型也适用:即使在Qwen2.5-7B这样的小模型上,CoG依然优于基线,证明了该方法不依赖于模型规模,而是方法论的胜利。
06
总结与启示
CoG 的研究为我们开发高可靠性的Agent提供了新的范式:结构化的约束优于盲目的搜索,给AI一个“导航地图”并教会它“知错能改”,是通往可控推理的必经之路。
-
引入“先验结构”:在做复杂的逻辑推理任务时,不要只靠LLM的“语感”。引入外部的结构化约束(如蓝图、Schema)能极大地提升推理的稳定性。
-
拥抱“双系统”架构:未来的Agent设计,应该区分“执行/探索”和“监控/反思”两个模块。让LLM在出错时能自我诊断和回头,是解决幻觉的关键。
-
无需训练的红利:CoG证明了通过精巧的Prompting和搜索策略,我们可以在不微调模型的情况下,解锁模型更强大的推理能力。
杭州智慧矩阵