 夜雨聆风
夜雨聆风





大规模AI网络的光学Shuffle架构
01
引言
随着AI训练丛集持续扩展至数十万GPU规模,实体层互连基础设施面临复杂性挑战。传统网络架构在小规模部署中表现良好,但在现代AI超级计算机所需的大量光纤数量、交换机埠需求和部署管理方面遇到困难。光学通道shuffling技术已成为解决这些挑战的关键技术,同时降低成本、功耗和网络延迟[1]。

02
AI网络的扩展性挑战
现代AI训练工作负载,特别是大型语言模型和神经网络训练,需要运算节点之间极高的频宽和低延迟通讯。扁平化网络架构可最小化GPU之间的跳数,对于实现最佳效能已不可或缺。2层leaf-spine网络相较于传统3层leaf-spine-core架构,减少了2个交换机跳数,直接降低网络对尾端延迟的影响——这是分散式训练效率的关键指标。
然而,扩展这些扁平化网络带来显著挑战。在没有进阶互连策略的情况下,连接数万个GPU需要大量交换机和光收发器,造成资本支出和运营功耗的瓶颈。这正是光学通道breakout和shuffling发挥作用的地方。
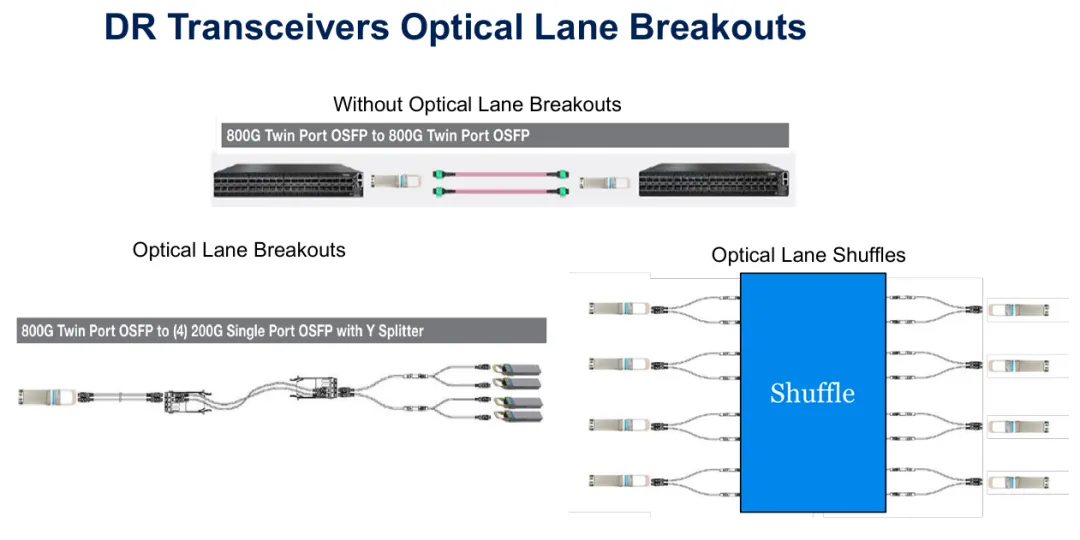
图1:传统点对点连接与光学通道breakout及shuffle的比较,展示单一多通道收发器如何连接到多个端点。
03
理解光学通道Breakout
光学通道breakout从根本改变了高速收发器在网络Fabric中的连接方式。传统的1.6T收发器以8×200G运作,将所有8个通道连接到单一对等设备的点对点配置。透过光学breakout,这8个通道可分配到不同交换机埠跨多个设备,使单一收发器同时与最多8个独立端点建立连接。
这项能力改变了网络拓扑设计。网络架构师不再需要将整个收发器专用于单一连接,而可以将通道分配到交换层之间,创造更丰富的连接模式。例如,GPU节点的1.6T连结可以breakout,使不同的200G通道连接到不同的leaf交换机,立即增加路径多样性并实现更复杂的负载平衡策略。
实际实施需要专门的光学基础设施。Breakout线缆整合了Y型分路器和扇出组件,将多通道连接中的各个波长或光纤对实体分离。结合shuffling——策略性重新映射哪些通道连接到哪些埠——这些breakout可实现传统点对点布线无法达成的网络拓扑。
04
量化效益
光学通道shuffling的效率增益在大规模时变得显著。考虑一个支援32,768个GPU的网络,使用512埠交换机。在没有任何通道breakout的情况下,此配置需要128个leaf交换机和64个spine交换机。仅在交换机之间实施breakout就将网络增加到512个leaf和256个spine——交换机数量增加4倍——但关键是,这支援相同的32,768个GPU,采用2层架构而非需要3层设计。
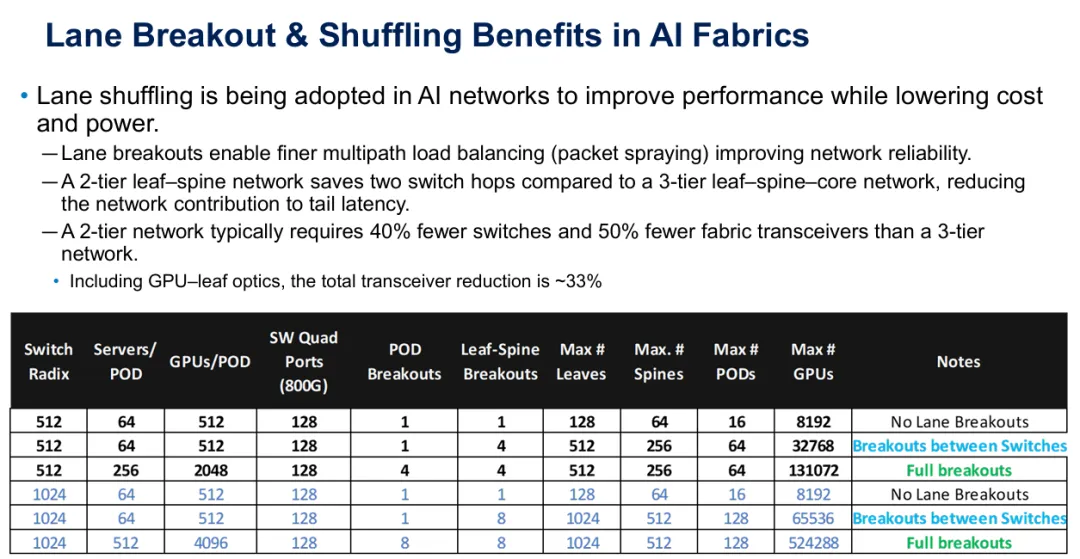
图2:比较表格展示通道breakout如何实现大规模扩展,配置范围从8,192到超过500,000个GPU。
真正的突破来自在node-to-leaf和leaf-to-spine两层都实施完整breakout。使用512埠交换机和两层都采用4路breakout,网络可扩展到131,072个GPU,同时相较于等效的3层架构需要少40%的交换机和少50%的Fabric收发器。当GPU到leaf光学器件纳入计算时,总收发器减少达到约33%。
这些减少直接转化为更低的功耗和资本成本。在超大规模AI部署中,数千千瓦通过网络设备,消除三分之一的收发器代表有意义的能源节省。减少的交换机数量同样降低了采购成本和维护基础设施的持续运营负担。
05
网络架构演进
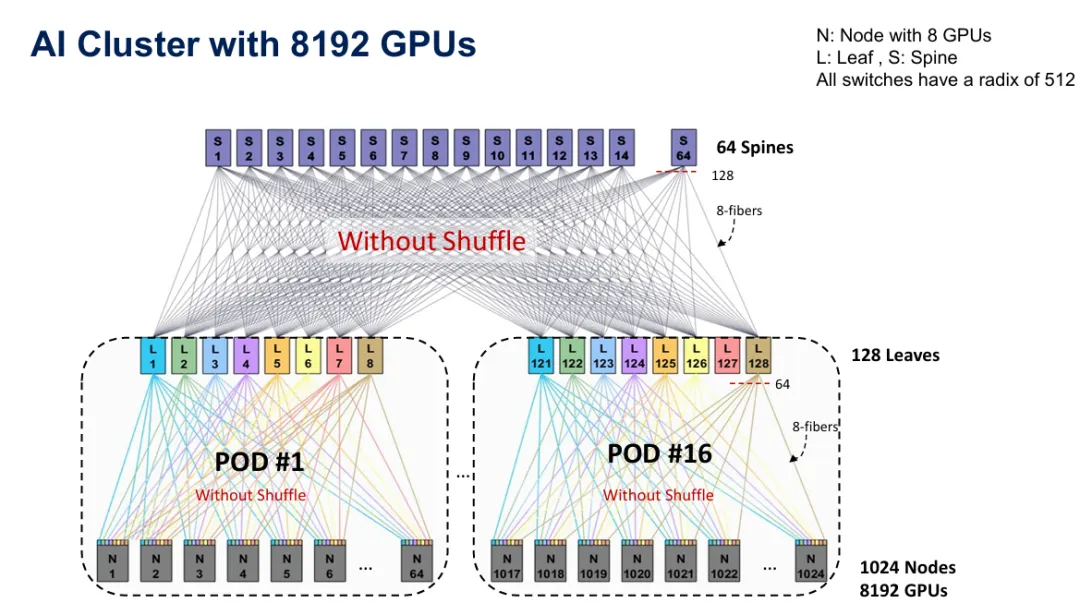
图3:8,192个GPU丛集组织成2层leaf-spine架构,未使用shuffling,显示64个spine和128个leaf,使用512埠交换机。
检视特定架构可说明shuffling如何实现扩展。一个8,192 GPU丛集使用512埠交换机且无shuffling,组织成16个POD,每个包含512个GPU,分布在64个节点上,每个节点有8个GPU。这个基线配置使用128个leaf交换机向下连接节点,64个spine交换机提供POD间连接。Leaf-spine连接使用8光纤阵列承载聚合流量。
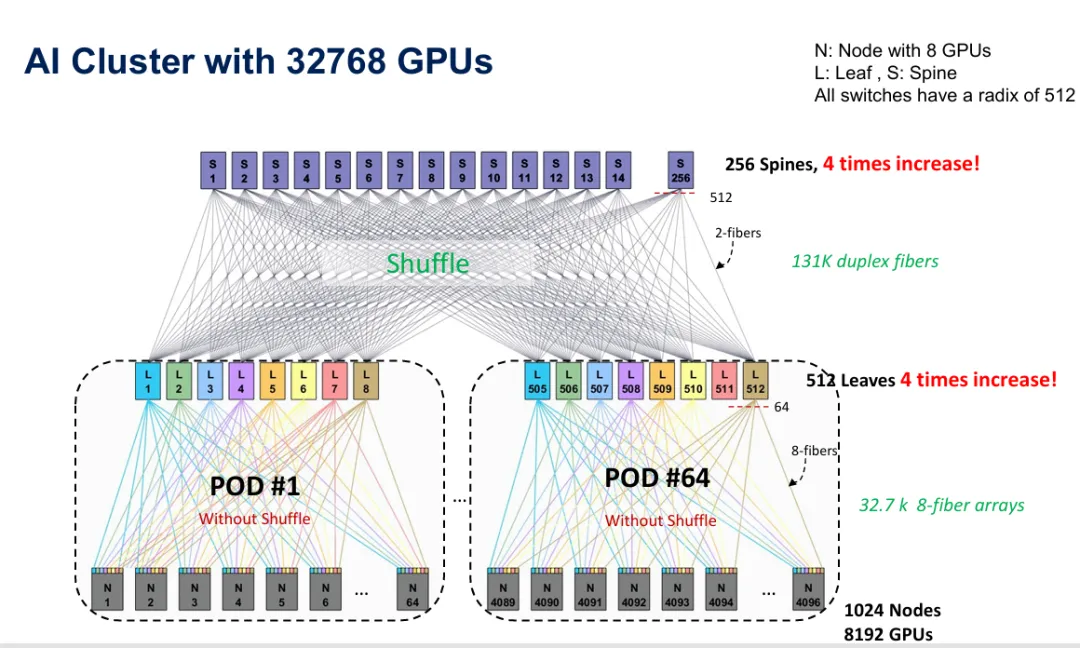
图4:扩展到32,768个GPU,在leaf-spine层采用光学shuffling,增加到512个leaf和256个spine,同时维持2层拓扑。
将此扩展到32,768个GPU并采用leaf-spine shuffling需要256个spine交换机——增加4倍——和512个leaf交换机——同样增加4倍——但关键是维持2层架构。Leaf和spine之间的shuffle层执行通道重新映射,将每个leaf的上行链路分配到多个spine,反之亦然。此部署需要131,000条双工光纤,组织成32,700个8光纤阵列,代表如果没有结构化shuffle模块,基本上不可能正确部署的大规模实体设施。
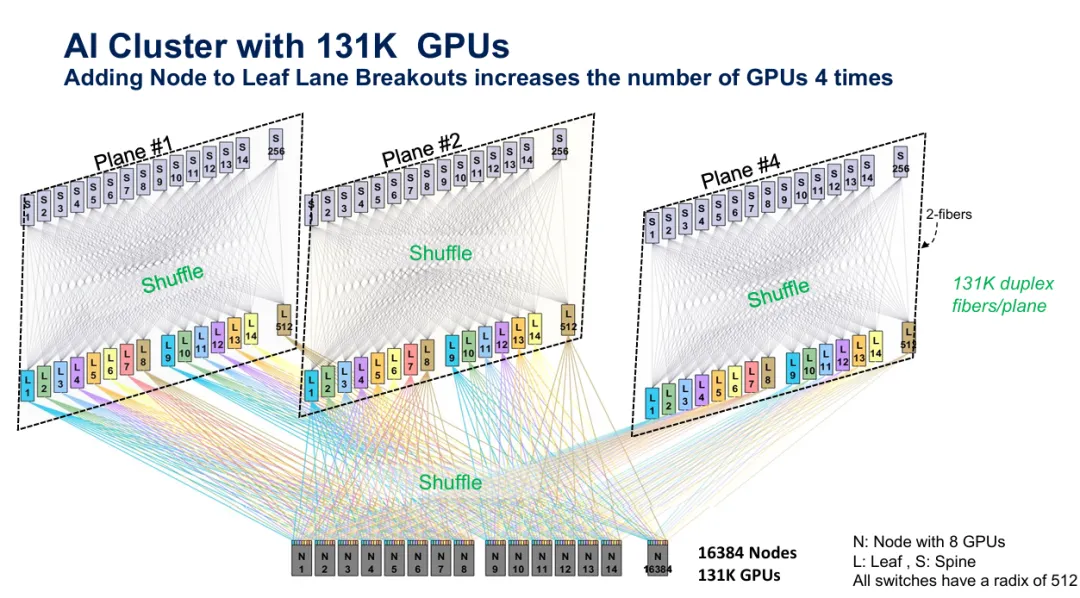
图5:131,072个GPU丛集在node-to-leaf和leaf-to-spine两层都使用shuffle,跨多个平面组织。
在leaf-to-spine shuffling之外实施node-to-leaf breakout,将规模推进到131,072个GPU,跨16,384个节点。此配置采用多个网络平面——独立的平行Fabric——每个都有自己的spine和leaf层。Shuffle模块出现在节点层级和网络层之间,创造高度网状拓扑,其中每个GPU可以透过多个不同路径到达任何其他GPU。
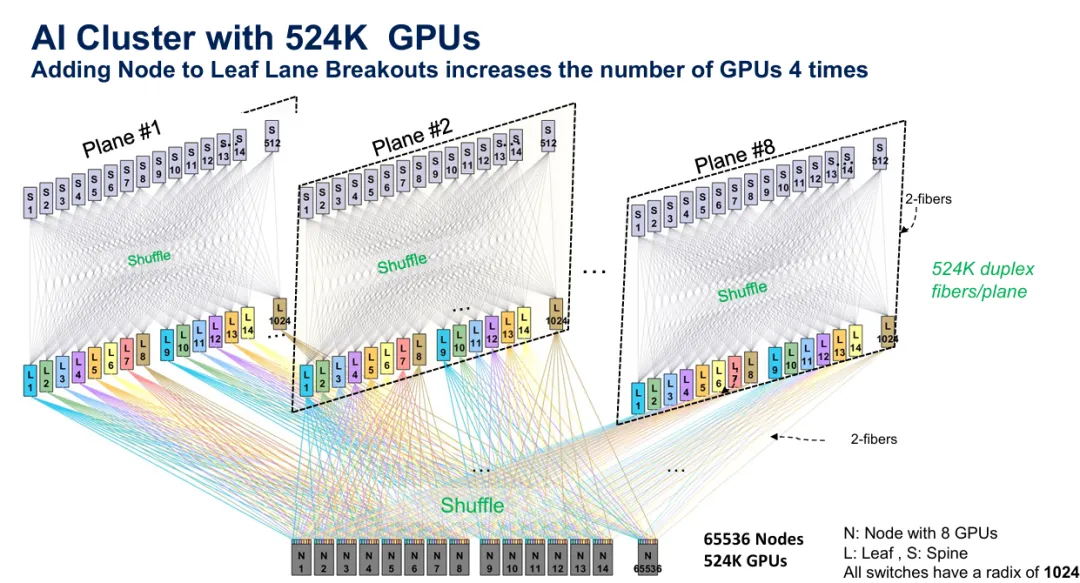
图6:使用1024埠交换机和所有层的全面shuffling,524,288个GPU跨65,536个节点的终极扩展范例。
架构可以使用更高埠数的交换机进一步扩展。使用1024埠交换机而非512埠可实现524,288个GPU跨65,536个节点的配置。在此规模下,shuffle基础设施变得绝对必要——根本没有可行的方法手动布线每个平面524,000条双工光纤对,同时维持正确的通道分配以实现最佳流量分配。
06
透过模块化Shuffle简化部署
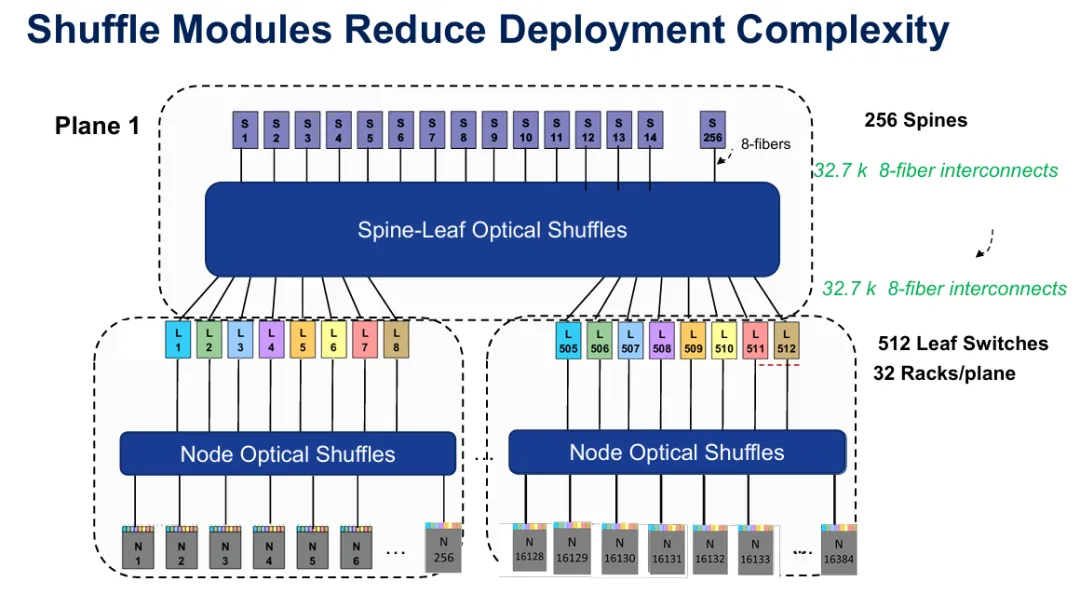
图7:模块化shuffle箱如何透过将复杂的通道重新映射整合到标准化模块中来简化部署的概念视图。
在此规模下实施shuffling的实体实现需要结构化、模块化的方法。网络营运商开发了三种主要实施策略,各有不同的权衡。Shuffle线束将breakout和shuffle接合点直接整合到专用线缆中,具有交错的分支,连接到不同的交换机或埠。这种方法透过消除中间连接点来节省机架空间,但使故障排除更困难,因为shuffle模式嵌入在线缆组件本身中。
网状盒(mesh cassette)提供小型模块,技术人员可以手动或机器人方式排列光纤连接以实现所需的通道映射。这些盒体提供模块化和相对容易的故障排除——故障连接可以在盒体层级识别和更换——但对于较大的网络,众多盒体累积消耗的空间变得低效。

图8:光学shuffle的三种实施方法,展示shuffle线束、网状盒和shuffle箱/模块。
Shuffle箱或模块代表最高密度的方法。这些单元将许多shuffle连接封装到紧凑的外壳中,透过标准化界面简化安装,如果损坏仍相对容易更换。对于100,000+ GPU规模的部署,shuffle模块变得必不可少——提供唯一实用的方法来管理压倒性的光纤数量,同时维持连接准确性。
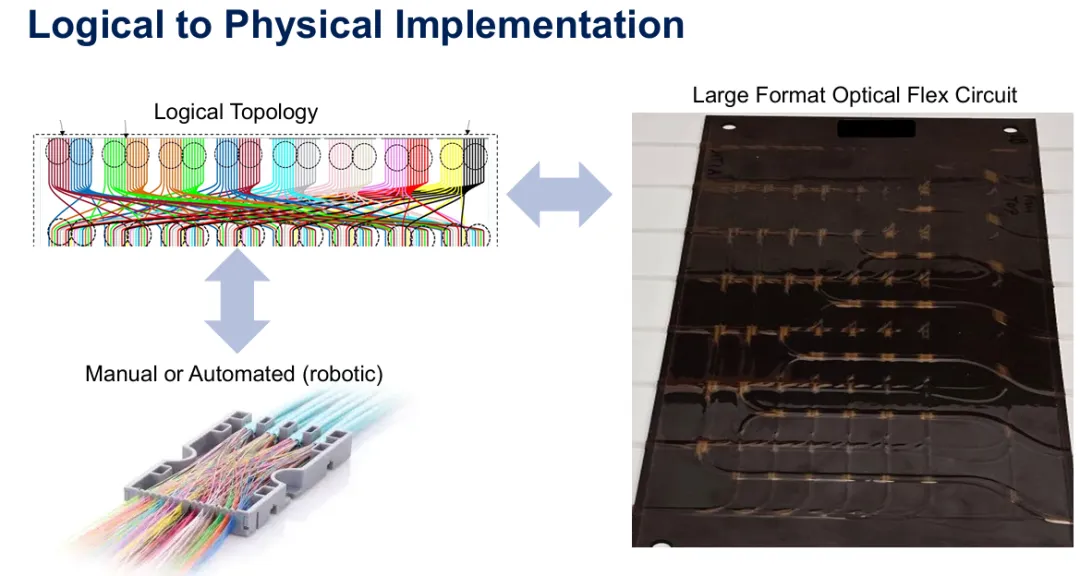
图9:从逻辑网络拓扑到实体实施的转换,使用手动/机器人assembly或大型光学软性线路。
从逻辑网络拓扑到实体shuffle模块的转换可以遵循手动assembly制程,其中技术人员或机器人根据shuffle映射图定位单根光纤,或者越来越多地,制造商采用大型光学软性线路。这些软性线路使用光刻或雷射直写制程创建实施shuffle的波导图案,然后封装到两侧具有适当连接器的模块中。
07
新颖方法:3D波导Shuffle
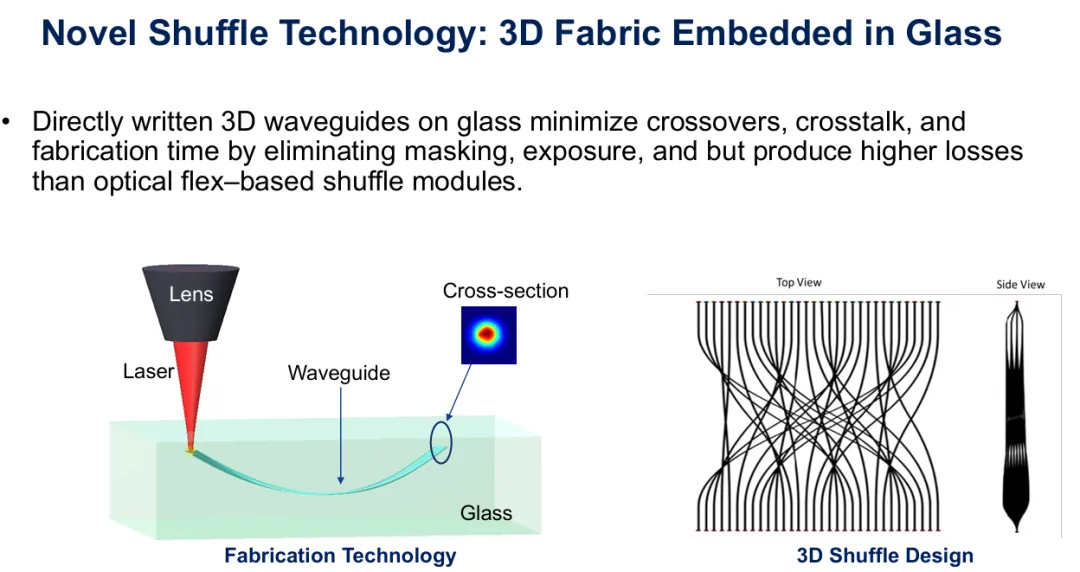
图10:雷射直写在玻璃基板中制作3D波导,展示制造制程和产生的三维shuffle图案。
先进制造技术正推动shuffle技术朝新方向发展。直写雷射系统可以将三维波导图案直接刻写到玻璃基板中,创造以嵌入式光子结构而非光纤组件存在的shuffle Fabric。聚焦雷射束沿其路径改变玻璃的折射率,创造永久性波导。透过控制光束的三维轨迹,制造商可以书写复杂的交叉图案,其中波导在真正的3D空间中相互跨越上下。

图11:制造的3D玻璃shuffle原型照片,展示紧凑的form factor和整合的连接器界面。
这种方法提供几个优势。三维几何形状相较于平面设计最小化交叉点,潜在减少通道之间的串扰。直写制程消除了屏蔽和曝光步骤,缩短制造时间。然而,光纤界面与嵌入式波导之间的耦合损耗往往高于传统基于光纤的shuffle模块,创造了限制应用于较短距离或较低损耗预算的效能权衡。
08
网络效能改善
除了实现规模扩展之外,光学shuffling直接改善网络效能特性。透过将每个GPU的通道分配到多个leaf交换机,shuffle架构自然增加路径多样性。当封包需要从一个GPU传输到另一个GPU时,透过不同的spine交换机存在多条有效路径。这种多样性可实现更有效的封包喷洒(packet spraying)——在多条路径上分配封包流以平衡负载并避免热点的技术。
路径选择中更高的熵与AI训练网络中更好的尾端延迟效能相关。主导AI工作负载网络流量模式的集体通讯操作(如all-reduce)从能够在许多平行路径上分散流量而非透过有限的spine互连集中流量中获益良多。
消除交换层带来的延迟减少与负载平衡改善相结合。更少的跳数意味着更低的基线延迟,而更好的负载分配防止导致延迟变异的队列累积。对于由最慢GPU决定迭代时间的同步训练算法,降低尾端延迟直接加速训练吞吐量。
09
实际部署范例
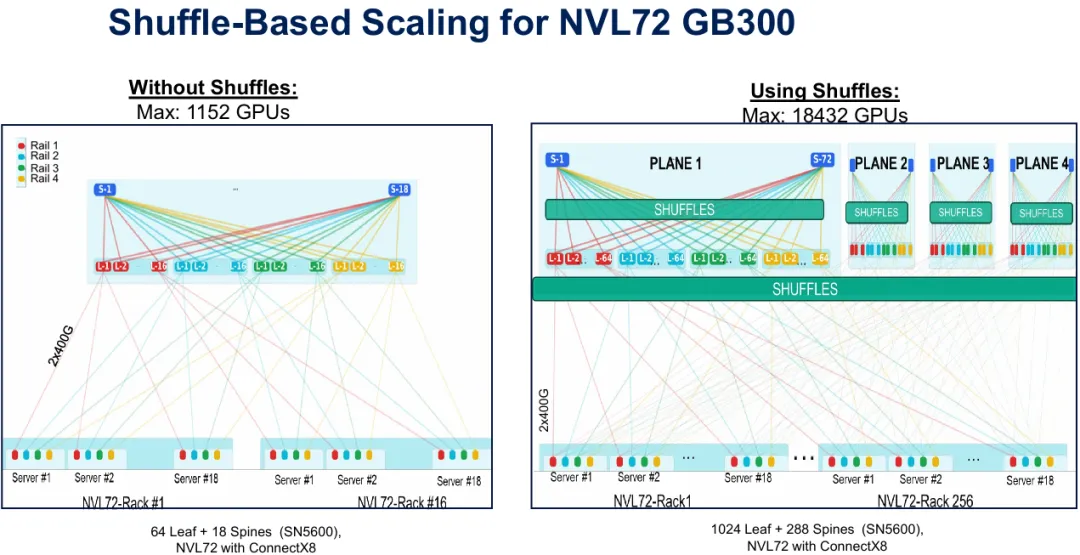
图12:实际部署范例,展示NVIDIA NVL72 GB300从无shuffle的1,152个GPU扩展到跨4个网络平面使用全面shuffling的18,432个GPU。
NVIDIA的NVL72 GB300平台提供了shuffle扩展的具体范例。在没有shuffle的情况下,使用SN5600交换机的配置在单一平面中实现1,152个GPU,跨64个leaf交换机和18个spine交换机。在多层实施全面shuffling可使相同的交换机类型支援18,432个GPU——增加16倍——使用分布在4个独立平面上的1,024个leaf交换机和288个spine。每个GPU透过以2×400G运作的ConnectX-8网络卡连接,通道被breakout和shuffle以创造丰富的连接网状结构。
10
光学Shuffle的实施选项细节
在大规模AI丛集中实施shuffle需要仔细考虑实体层的各个方面。Shuffle线束方法将breakout功能直接嵌入线缆assembly中,使用交错长度的分支连接到不同的交换机埠。这种整合式设计节省了机架空间,因为不需要独立的shuffle模块或配线盘。然而,当特定连接出现问题时,故障排除变得更加困难。技术人员无法简单地重新配置单一光纤连接——整个线束可能需要更换。对于数万条连接的部署,这种缺乏灵活性可能带来营运挑战。
网状盒方法提供了更大的灵活性。每个盒体容纳相对较小数量的连接——通常是几十到几百条光纤——技术人员可以在盒体内手动重新排列连接以修改shuffle模式。一些先进的盒体设计整合了小型光学软性线路,提供预先配置的shuffle模式,同时仍维持模块化。这种方法的优势在于维修和修改时的粒度——单一故障连接可以在盒体层级隔离和修复,而不影响更广泛的网络。
对于超大规模部署,shuffle箱或模块提供必要的密度。单一shuffle模块可能处理数百甚至数千条光纤连接,将复杂的重新映射封装在紧凑、工程化的封装中。这些模块通常在两侧使用高密度多光纤连接器,例如MPO或其他多光纤界面。内部结构可能基于光纤带状线、光学软性线路或先进的情况下基于玻璃基板中的3D波导。
模块化方法还简化了安装流程。技术人员不是在现场路由和端接单根光纤,而是连接预先制造和测试的模块。这减少了部署时间并提高了可靠性,因为模块在受控的工厂环境中经过验证。对于需要在紧迫时间表内上线的大型AI丛集,这种部署速度的改善具有实际价值。
11
从逻辑到实体的转换过程
网络设计始于逻辑拓扑——定义哪些节点连接到哪些leaf交换机、哪些leaf连接到哪些spine以及流量如何流动的抽象图。对于采用shuffling的网络,此逻辑设计指定每个多通道连接的通道如何breakout并重新映射到不同的目的地。
将此逻辑设计转换为实体实施需要创建详细的连接映射。对于32,000个8光纤连接的部署,这意味着追踪256,000条单根光纤的源和目的地——这是一项如果手动执行将不可行的任务。自动化工具采用逻辑拓扑规范并生成精确的制造指令,用于创建实施所需shuffle模式的模块。
制造制程本身可以遵循几种路径。手动assembly涉及技术人员根据生成的指令路由和端接光纤。这种方法提供灵活性并可以处理客制化要求,但规模有限且容易出现人为错误。机器人assembly系统自动化光纤处理,提高一致性和吞吐量,同时仍然基于相同的光纤带状线和连接器技术。
大型光学软性线路代表更整合的方法。这些元件使用类似于电子软性印刷电路板的制程制造,但波导取代了铜走线。光刻定义波导图案,多个层可以堆栈以创建复杂的路由。制造完成后,连接器被附加到软性线路的边缘,创建一个完整的shuffle模块。这种方法在大量生产时提供良好的可重复性,但需要先期工具投资。
12
3D波导技术的深入探讨
在玻璃中直写3D波导代表了shuffle技术的前沿发展。该制程使用飞秒雷射,其极短的脉冲持续时间在玻璃基板中产生非线性吸收。在焦点处,雷射能量改变材料的折射率,创造一个永久性波导核心,光可以在其中传播。
透过在3D空间中精确移动雷射焦点,系统可以书写任意波导路径。这包括在不同深度交叉的路径,使波导能够在彼此上方和下方通过,而实际上不会在交叉点相交。这种真正的三维路由最小化了传统平面光学线路中发生的交叉数量,在平面线路中波导交叉会引入损耗和串扰。
从制造角度来看,3D直写具有优势。不需要光罩——设计变更可以透过更新雷射扫描程序实现。不需要多个制程步骤来创建不同的层——所有波导在单次扫描操作中书写。对于需要快速迭代设计或需要客制化shuffle模式的原型应用,这种灵活性很有价值。
然而,耦合损耗仍然是挑战。将光从标准单模光纤有效耦合到玻璃中的直写波导需要仔细的模场匹配。直写波导的模场形状和大小可能与光纤显著不同,导致耦合界面处的损耗。先进的技术,如在波导末端整合透镜结构或使用渐变折射率轮廓,可以改善耦合,但增加了制造复杂性。
即使存在这些挑战,3D波导shuffle技术在特定应用中显示出前景。对于可以容纳适度额外损耗的短距离互连,紧凑的form factor和制造灵活性提供了引人注目的优势。随着直写技术的成熟和耦合方法的改善,这种方法可能在未来的shuffle实施中发挥更大的作用。
13
网络效能优化的机制
光学shuffling改善网络效能的机制超越了简单的拓扑考虑。透过在多个leaf交换机上分配每个GPU的通道,架构创造了路径多样性的基础条件。当来自GPU-A的封包需要到达GPU-B时,可能存在透过leaf-1到spine-X、leaf-2到spine-Y或几个其他组合的路径。
这种路径多样性与先进的负载平衡算法结合使用。封包喷洒技术将来自单一流的封包分配到多条路径,根据实时网络条件选择路由。当一条路径经历拥塞时,流量可以转移到替代路径。这种动态负载平衡在处理AI训练工作负载的突发流量模式时特别有效。
集体通讯操作对路径多样性特别敏感。在all-reduce操作中,每个GPU必须与网络中的所有其他GPU交换资料。在没有足够路径多样性的情况下,某些spine链路可能饱和,而其他链路未充分利用,创造瓶颈。透过shuffle实现的增加的路径选择可在可用频宽上更均匀地分散此流量。
延迟分布,而不仅仅是平均延迟,在同步训练场景中最为重要。每个训练步骤的完成由最慢的GPU决定——尾端延迟直接影响总吞吐量。透过减少拥塞热点和提供多条路径绕过临时瓶颈,shuffle架构有助于收紧延迟分布并减少异常值。
14
规模经济与实施考量
虽然shuffle基础设施增加了前期复杂性和成本,但规模经济在较大部署中变得有利。考虑到交换机和收发器的成本。在32,768 GPU部署中,2层shuffle架构相较于3层非shuffle设计可节省约40%的交换机。在交换机成本达到数万美元的情况下,这种减少转化为数百万美元的资本支出节省。
收发器节省同样显著。高速光学器件——特别是800G和1.6T收发器——代表网络资本支出的主要组成部分。减少33%的收发器数量直接影响底线。此外,更少的收发器意味着更低的持续功耗。以每个收发器10-20瓦的功耗,消除数千个收发器可节省数十千瓦——在多年营运中具有实质的能源成本影响。
营运复杂性考量平衡了这些节省。Shuffle网络需要更仔细的规划和说明文件。每条连接必须正确映射和验证。错误的shuffle配置可能导致无法检测的连接问题或次优的流量分配。然而,模块化shuffle元件透过减少现场需要做出的决策数量来缓解这些风险——技术人员连接预先验证的模块而不是路由单根光纤。
维护和故障排除程序必须适应shuffle架构。传统的点对点网络可以在连接两端使用简单的线缆追踪方法。Shuffle网络需要参考shuffle映射说明文件以了解通道如何路由。完善的说明文件和清晰的标签变得必要,而非可选。
15
结论
光学通道shuffling技术已从有趣的优化转变为大规模AI基础设施的必要需求。该技术实现了原本不可能的2层网络架构,透过大幅减少交换机和收发器需求降低了资本和营运成本,并透过增加的路径多样性和降低的延迟改善了网络效能。
随着AI丛集持续扩展至百万GPU部署,shuffle架构将变得越来越复杂。模块化shuffle箱和3D波导刻写等先进制造技术为这些大规模网络提供了实体层基础,而仔细的拓扑设计确保增加的复杂性转化为有意义的效能和效率增益。
对于大规模部署AI基础设施的组织而言,理解光学shuffle架构及其实施选项与选择正确的GPU或交换机芯片同样重要。布线层曾被视为简单的商品,现在代表了一个关键组件,智慧设计可以释放可观的价值。
参考文献
[1] J. M. Castro, “Optical Shuffle Architectures for Large AI Networks,” presented at the IEEE 802.3 New Ethernet Applications Ad Hoc Ethernet for AI Assessment, Feb. 2026.
END
NOTICE
点击左下角“阅读原文”马上申请
欢迎转载
转载请注明出处,请勿修改内容和删除作者信息!
关注我们
 |
 |
 |
关于我们:
深圳逍遥科技有限公司(Latitude Design Automation Inc.)是一家专注于半导体芯片设计自动化(EDA)的高科技软件公司。我们自主开发特色工艺芯片设计和仿真软件,提供成熟的设计解决方案如PIC Studio、MEMS Studio和Meta Studio,分别针对光电芯片、微机电系统、超透镜的设计与仿真。我们提供特色工艺的半导体芯片集成电路版图、IP和PDK工程服务,广泛服务于光通讯、光计算、光量子通信和微纳光子器件领域的头部客户。逍遥科技与国内外晶圆代工厂及硅光/MEMS中试线合作,推动特色工艺半导体产业链发展,致力于为客户提供前沿技术与服务。
http://www.latitudeda.com/
(点击上方名片关注我们,发现更多精彩内容)