 夜雨聆风
夜雨聆风





上线就翻车!AI 接口调用超时、限流、429 错误完整解决方案
作者:洛水石
标签:#AI开发 #接口调用 #超时处理 #限流 #429错误 #Java #Python
────────────────────────────────────────────────────────────
一、为什么你的 AI 项目上线必翻车?
你花了两周写好了 AI 功能,本地测试丝滑流畅,兴冲冲部署上线。
结果:
-
用户一多,接口开始超时,前端白屏 -
高并发下疯狂报 429 Too Many Requests -
偶发性 503 Service Unavailable,日志一片红 -
老板发来消息:「你这啥破玩意儿?」
本文是我踩过这些坑之后总结的完整解决方案,覆盖 Java、Python 两种技术栈,拿走即用。
────────────────────────────────────────────────────────────
二、AI 接口的三大天敌
2.1 超时(Timeout)
为什么 AI 接口容易超时?
普通 REST 接口通常 100ms 以内返回,但 AI 大模型接口:
|
场景 |
典型耗时 |
|
GPT-4 单次问答(非流式) |
8~30 秒 |
|
Claude 长文生成 |
15~60 秒 |
|
本地部署的 Llama 推理 |
5~120 秒(取决于硬件) |
|
图片识别/多模态 |
10~45 秒 |
默认的 HTTP 客户端超时时间通常是 5~10 秒,直接不够用。
2.2 限流(Rate Limit)
AI 服务商对调用频率有严格限制:
|
服务商 |
免费额度 |
付费限制示例 |
|
OpenAI GPT-4 |
3 RPM / 200 RPD |
500 RPM (Tier 4) |
|
Anthropic Claude |
5 RPM |
1000 RPM (Enterprise) |
|
百度文心 |
2 QPS |
根据套餐而定 |
|
阿里通义 |
1 QPS |
10 QPS (商业版) |
RPM = Requests Per Minute,RPD = Requests Per Day,QPS = Queries Per Second。
2.3 429 错误
429 就是限流的 HTTP 表现形式:
HTTP/1.1 429 Too Many RequestsRetry-After: 30Content-Type: application/json{ “error”: { “message”: “Rate limit reached for gpt-4”, “type”: “rate_limit_error”, “code”: “rate_limit_exceeded” }}
────────────────────────────────────────────────────────────
三、超时问题:完整解决方案
3.1 合理配置超时时间
Java(OkHttp):
OkHttpClient client = new OkHttpClient.Builder() .connectTimeout(10, TimeUnit.SECONDS) // 连接超时 .writeTimeout(30, TimeUnit.SECONDS) // 写入超时 .readTimeout(120, TimeUnit.SECONDS) // 读取超时(AI接口关键!) .build();
Java(Spring WebClient):
@Beanpublic WebClient aiWebClient() { HttpClient httpClient = HttpClient.create() .option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 10_000) .responseTimeout(Duration.ofSeconds(120)) .doOnConnected(conn -> conn .addHandlerLast(new ReadTimeoutHandler(120)) .addHandlerLast(new WriteTimeoutHandler(30))); return WebClient.builder() .baseUrl(“https://api.openai.com”) .clientConnector(new ReactorClientHttpConnector(httpClient)) .build();}
Python(httpx):
import httpx# 推荐使用 httpx 代替 requests,支持异步和流式client = httpx.Client( timeout=httpx.Timeout( connect=10.0, # 连接超时 read=120.0, # 读取超时(最重要) write=30.0, # 写入超时 pool=5.0 # 连接池等待超时 ))
3.2 流式输出(Streaming):超时的根本解法
非流式调用等模型生成完整内容再返回,一次性等 30 秒;流式调用边生成边返回,首字节延迟只需 1~3 秒。
Java(流式 SSE):
@GetMapping(value = “/chat/stream”, produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> streamChat(@RequestParam String prompt) { return webClient.post() .uri(“/v1/chat/completions”) .bodyValue(buildRequest(prompt, true)) // stream: true .retrieve() .bodyToFlux(String.class) .filter(chunk -> !chunk.equals(“[DONE]”)) .map(this::extractContent) .onErrorReturn(“生成出现错误,请重试”);}private String buildRequest(String prompt, boolean stream) { return “”” { “model”: “gpt-4”, “stream”: %b, “messages”: [{“role”: “user”, “content”: “%s”}] } “””.formatted(stream, prompt.replace(“\””, “\\\””));}
Python(OpenAI SDK 流式):
from openai import OpenAIclient = OpenAI()def stream_chat(prompt: str): “””流式输出,实时推送给前端””” with client.chat.completions.create( model=”gpt-4″, messages=[{“role”: “user”, “content”: prompt}], stream=True, timeout=120, ) as stream: for chunk in stream: content = chunk.choices[0].delta.content if content: yield content # 通过 FastAPI StreamingResponse 推送
3.3 前端超时兜底
// 前端设置合理超时,并展示友好提示const controller = new AbortController();const timeoutId = setTimeout(() => controller.abort(), 120000);fetch(‘/api/chat/stream’, { method: ‘POST’, signal: controller.signal, body: JSON.stringify({ prompt })}).then(response => { clearTimeout(timeoutId); // 处理流式响应…}).catch(err => { if (err.name === ‘AbortError’) { showToast(‘AI 正在思考中,请稍等或重试…’); }});
────────────────────────────────────────────────────────────
四、限流问题:令牌桶 + 重试的组合拳
4.1 令牌桶限流(客户端主动限速)
在调用 AI 接口之前,在客户端主动限速,避免触发服务端 429。
Java(Guava RateLimiter):
@Componentpublic class AiRateLimiter { // OpenAI GPT-4 限制 500 RPM ≈ 8.3 RPS,留20%余量取 6 RPS private final RateLimiter rateLimiter = RateLimiter.create(6.0); @Autowired private OpenAiClient openAiClient; public String chat(String prompt) { // 等待令牌,超时则抛异常 if (!rateLimiter.tryAcquire(5, TimeUnit.SECONDS)) { throw new RateLimitException(“系统繁忙,请稍后重试”); } return openAiClient.chat(prompt); }}
Python(令牌桶实现):
import timeimport threadingfrom dataclasses import dataclass@dataclassclass TokenBucket: “””线程安全的令牌桶””” rate: float # 每秒补充令牌数 capacity: float # 桶容量 _tokens: float = 0 _last_time: float = 0 _lock: threading.Lock = None def __post_init__(self): self._tokens = self.capacity self._last_time = time.monotonic() self._lock = threading.Lock() def acquire(self, timeout: float = 5.0) -> bool: deadline = time.monotonic() + timeout while time.monotonic() < deadline: with self._lock: now = time.monotonic() self._tokens = min( self.capacity, self._tokens + (now – self._last_time) * self.rate ) self._last_time = now if self._tokens >= 1: self._tokens -= 1 return True time.sleep(0.1) return False# 使用示例:6 RPS,桶容量 10ai_limiter = TokenBucket(rate=6.0, capacity=10.0)def safe_chat(prompt: str) -> str: if not ai_limiter.acquire(timeout=5.0): raise RuntimeError(“系统繁忙,请稍后重试”) return call_openai(prompt)
4.2 指数退避重试(Exponential Backoff)
收到 429 时,不要立刻重试,要等待一段时间后再试,且等待时间指数增长。
Java(Spring Retry + 指数退避):
// pom.xml 引入// <dependency>// <groupId>org.springframework.retry</groupId>// <artifactId>spring-retry</artifactId>// </dependency>@Configuration@EnableRetrypublic class RetryConfig {}@Servicepublic class AiService { @Retryable( retryFor = {RateLimitException.class, HttpClientErrorException.class}, maxAttempts = 4, backoff = @Backoff( delay = 1000, // 初始等待 1 秒 multiplier = 2.0, // 每次翻倍:1s → 2s → 4s → 8s maxDelay = 30000, // 最大等待 30 秒 random = true // 加随机抖动,避免雷同重试 ) ) public String chat(String prompt) { return openAiClient.chat(prompt); } @Recover public String recover(Exception e, String prompt) { log.error(“AI接口重试耗尽,prompt={}”, prompt, e); return “AI服务暂时不可用,请稍后重试”; }}
Python(tenacity 库):
from tenacity import ( retry, stop_after_attempt, wait_exponential, retry_if_exception_type, before_sleep_log)import logginglogger = logging.getLogger(__name__)@retry( retry=retry_if_exception_type((RateLimitError, APIConnectionError)), wait=wait_exponential(multiplier=1, min=1, max=30), # 1→2→4→8→16→30s stop=stop_after_attempt(4), before_sleep=before_sleep_log(logger, logging.WARNING),)def chat_with_retry(prompt: str) -> str: “””带指数退避重试的 AI 调用””” response = client.chat.completions.create( model=”gpt-4″, messages=[{“role”: “user”, “content”: prompt}], ) return response.choices[0].message.content
────────────────────────────────────────────────────────────
五、429 错误完整处理流程
5.1 解析 Retry-After 头
@Componentpublic class OpenAiClient { private static final Logger log = LoggerFactory.getLogger(OpenAiClient.class); public String chat(String prompt) { try { // … 发起请求 } catch (HttpClientErrorException e) { if (e.getStatusCode() == HttpStatus.TOO_MANY_REQUESTS) { // 解析 Retry-After String retryAfter = e.getResponseHeaders() .getFirst(“Retry-After”); long waitSeconds = retryAfter != null ? Long.parseLong(retryAfter) : 30L; log.warn(“触发 429,等待 {}s 后重试”, waitSeconds); throw new RateLimitException(“Rate limit exceeded”, waitSeconds); } throw e; } }}
5.2 多 Key 轮询(Pool 策略)
当单个 API Key 限制不够用时,使用多个 Key 轮询:
@Componentpublic class ApiKeyPool { private final List<String> apiKeys; private final AtomicInteger index = new AtomicInteger(0); // 记录每个 Key 的下次可用时间 private final Map<String, Long> coolingKeys = new ConcurrentHashMap<>(); public ApiKeyPool(@Value(“${ai.api-keys}”) List<String> keys) { this.apiKeys = Collections.unmodifiableList(keys); } /** * 获取可用的 API Key * 轮询策略 + 冷却跳过 */ public String getAvailableKey() { int size = apiKeys.size(); for (int i = 0; i < size; i++) { int idx = index.getAndIncrement() % size; String key = apiKeys.get(idx); Long coolUntil = coolingKeys.get(key); if (coolUntil == null || System.currentTimeMillis() > coolUntil) { return key; } } throw new RateLimitException(“所有 API Key 均在冷却中,请稍后重试”); } /** * 标记某个 Key 进入冷却 */ public void markCooling(String key, long seconds) { coolingKeys.put(key, System.currentTimeMillis() + seconds * 1000); log.warn(“Key {} 进入冷却 {}s”, key.substring(0, 8) + “****”, seconds); }}
5.3 全局异常处理(Spring Boot)
@RestControllerAdvicepublic class GlobalExceptionHandler { @ExceptionHandler(RateLimitException.class) public ResponseEntity<ErrorResponse> handleRateLimit(RateLimitException e) { ErrorResponse body = ErrorResponse.builder() .code(“RATE_LIMIT_EXCEEDED”) .message(“AI 服务繁忙,请 ” + e.getRetryAfter() + ” 秒后重试”) .retryAfter(e.getRetryAfter()) .build(); return ResponseEntity.status(HttpStatus.TOO_MANY_REQUESTS) .header(“Retry-After”, String.valueOf(e.getRetryAfter())) .body(body); } @ExceptionHandler(AiTimeoutException.class) public ResponseEntity<ErrorResponse> handleTimeout(AiTimeoutException e) { return ResponseEntity.status(HttpStatus.GATEWAY_TIMEOUT) .body(ErrorResponse.builder() .code(“AI_TIMEOUT”) .message(“AI 响应超时,请稍后重试”) .build()); }}
────────────────────────────────────────────────────────────
六、生产级架构方案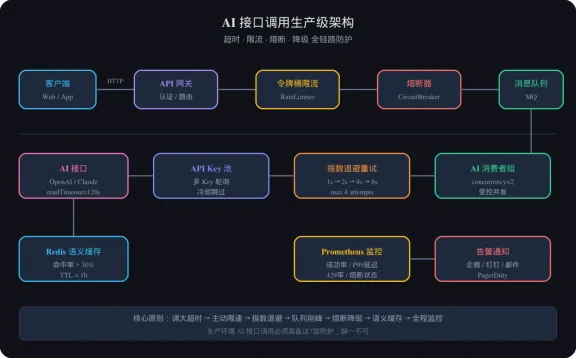
图1:AI接口调用生产级架构全景
6.1 异步队列削峰
高并发场景下,不要让请求直接打到 AI 接口,用队列解耦:
// 生产者:接收请求,放入队列@RestController@RequestMapping(“/api/ai”)public class AiController { @Autowired private RabbitTemplate rabbitTemplate; @PostMapping(“/chat/async”) public ResponseEntity<String> asyncChat(@RequestBody ChatRequest request) { String taskId = UUID.randomUUID().toString(); request.setTaskId(taskId); // 推入队列,立即返回 taskId rabbitTemplate.convertAndSend(“ai.exchange”, “ai.chat”, request); return ResponseEntity.accepted() .body(“”” {“taskId”: “%s”, “status”: “queued”} “””.formatted(taskId)); } // 前端轮询结果 @GetMapping(“/chat/result/{taskId}”) public ResponseEntity<ChatResult> getResult(@PathVariable String taskId) { ChatResult result = resultStore.get(taskId); if (result == null) { return ResponseEntity.accepted() .body(ChatResult.pending(taskId)); } return ResponseEntity.ok(result); }}// 消费者:受控并发处理 AI 请求@Component@RabbitListener(queues = “ai.chat.queue”, concurrency = “2”) // 限制并发数为 2public class AiChatConsumer { @RabbitHandler public void process(ChatRequest request) { try { String result = aiService.chat(request.getPrompt()); resultStore.put(request.getTaskId(), ChatResult.success(result)); } catch (Exception e) { resultStore.put(request.getTaskId(), ChatResult.failed(e.getMessage())); } }}
6.2 熔断降级(Resilience4j)
@Configurationpublic class CircuitBreakerConfig { @Bean public CircuitBreakerRegistry circuitBreakerRegistry() { CircuitBreakerConfig config = CircuitBreakerConfig.custom() .failureRateThreshold(50) // 失败率超50%触发熔断 .slowCallRateThreshold(80) // 慢调用率超80%触发 .slowCallDurationThreshold(Duration.ofSeconds(30)) // 超30s算慢调用 .waitDurationInOpenState(Duration.ofSeconds(60)) // 熔断持续60s .slidingWindowSize(10) // 滑动窗口10个请求 .build(); return CircuitBreakerRegistry.of(config); }}@Servicepublic class AiService { private final CircuitBreaker circuitBreaker; public AiService(CircuitBreakerRegistry registry) { this.circuitBreaker = registry.circuitBreaker(“openai”); } public String chat(String prompt) { return CircuitBreaker.decorateSupplier( circuitBreaker, () -> openAiClient.chat(prompt) ).get(); }}
6.3 缓存相同问题(语义缓存)
对于重复或相似的问题,直接返回缓存结果,节省费用和时间:
@Servicepublic class SemanticCacheService { @Autowired private StringRedisTemplate redis; @Autowired private EmbeddingService embeddingService; // 向量化服务 /** * 语义缓存查询 * 相似度 > 0.95 视为命中 */ public Optional<String> getCache(String prompt) { String key = “ai:cache:” + hashPrompt(prompt); // 精确匹配 String exactResult = redis.opsForValue().get(key); if (exactResult != null) { return Optional.of(exactResult); } // TODO: 向量相似度匹配(接入 Redis VectorSearch 或 Pinecone) return Optional.empty(); } public void setCache(String prompt, String result) { String key = “ai:cache:” + hashPrompt(prompt); // 缓存 1 小时 redis.opsForValue().set(key, result, Duration.ofHours(1)); } private String hashPrompt(String prompt) { return DigestUtils.md5DigestAsHex(prompt.getBytes(StandardCharsets.UTF_8)); }}
────────────────────────────────────────────────────────────
七、监控与告警
7.1 关键指标
生产环境必须监控这些指标:
|
指标 |
告警阈值 |
说明 |
|
AI 接口成功率 |
< 95% |
触发告警 |
|
AI 接口 P99 延迟 |
> 60s |
检查模型或网络 |
|
429 错误率 |
> 5% |
调低并发或增加 Key |
|
队列积压量 |
> 100 |
检查消费者 |
|
熔断器状态 |
OPEN |
立即告警 |
7.2 Micrometer 埋点(Spring Boot)
@Servicepublic class AiMetricsService { private final MeterRegistry registry; private final Counter successCounter; private final Counter rateLimitCounter; private final Timer responseTimer; public AiMetricsService(MeterRegistry registry) { this.registry = registry; this.successCounter = Counter.builder(“ai.requests.total”) .tag(“status”, “success”).register(registry); this.rateLimitCounter = Counter.builder(“ai.requests.total”) .tag(“status”, “rate_limit”).register(registry); this.responseTimer = Timer.builder(“ai.response.duration”) .description(“AI接口响应时间”) .register(registry); } public String chatWithMetrics(String prompt) { return responseTimer.recordCallable(() -> { try { String result = aiService.chat(prompt); successCounter.increment(); return result; } catch (RateLimitException e) { rateLimitCounter.increment(); throw e; } }); }}
────────────────────────────────────────────────────────────
八、完整解决方案速查表
|
问题 |
根因 |
解决方案 |
|
接口超时 |
默认超时太短 |
调大 readTimeout 到 120s |
|
用户等待焦虑 |
非流式响应 |
改用流式 SSE 输出 |
|
频繁 429 |
超出 RPM 限制 |
客户端令牌桶 + 指数退避重试 |
|
高并发崩溃 |
请求直打 AI 接口 |
MQ 异步队列削峰 |
|
AI 服务不稳定 |
无降级机制 |
Resilience4j 熔断 + 兜底回复 |
|
重复问题浪费钱 |
无缓存 |
Redis 语义缓存 |
|
问题不可见 |
无监控 |
Micrometer + Prometheus |
────────────────────────────────────────────────────────────
九、总结
AI 接口不是普通 REST 接口,它的延迟高、限制多、不稳定三个特点决定了你必须在工程层面做好防护。
核心原则记住三条:
-
超时问题:调大超时 + 改流式,体验从 0 到满分 -
限流问题:客户端主动限速 + 指数退避,从被动挨打到主动掌控 -
架构问题:队列 + 熔断 + 缓存,构建真正的生产级 AI 应用
把今天的代码复制进去,你的 AI 应用就能扛住真实的生产流量了。
────────────────────────────────────────────────────────────
如果你觉得有用,欢迎点赞收藏
附:配套技术图解
令牌桶限流原理
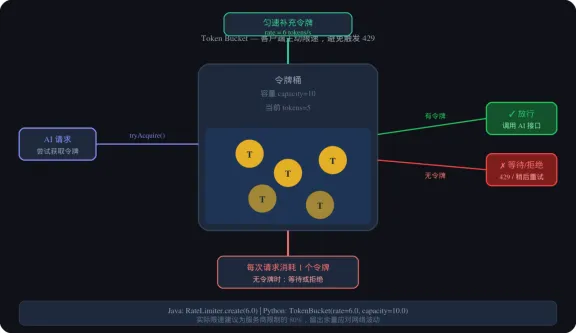 图2:令牌桶限流工作原理
图2:令牌桶限流工作原理
指数退避重试时序
图3:指数退避重试时序图
熔断器状态机
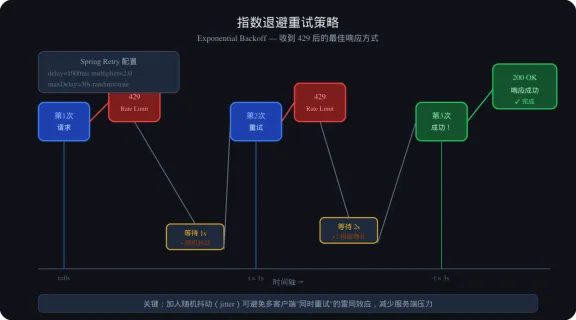 图4:Resilience4j 熔断器三态转换
图4:Resilience4j 熔断器三态转换