https://doi.org/10.1021/acscentsci.6c00643本文发表于 ACS Central Science,为开放获取文章,采用 CC-BY 4.0 许可协议,作者为 Eva Amsen。文章核心围绕 AI 药物研发面临的核心数据缺口问题,系统阐述了制药行业打破数据孤岛的两大核心路径 ——联邦学习与规模化公开数据集生成,同时分析了行业实践的成果、现存挑战与未来发展方向。
一、研究背景与核心行业痛点
AlphaFold 等 AI 工具实现蛋白质结构精准预测后,机器学习在药物研发中的应用成为行业核心发展趋势。但仅靠蛋白质结构数据,无法完成候选药物的筛选与优化;药物研发还需明确药物与靶点蛋白、人体全系统的相互作用机制,而这正是当前 AI 药物研发的核心瓶颈。牛津大学结构生物学家 Frank von Delft 指出,目前药物 – 靶点相互作用的可用数据量极度匮乏,而所有机器学习模型的性能,都完全依赖训练数据的规模与质量。行业数据缺口主要来自两方面:一是部分 AI 模型所需的关键数据,从未被行业系统记录;二是大量有效数据被封锁在各制药企业的专有数据库中,形成严重的数据孤岛。为推动机器学习在药物研发中的落地应用,全球制药企业开始开展同业深度合作,并与公共科研联盟联动,共同填补药物研发的 AI 训练数据缺口。
二、AI 药物研发对高质量训练数据的迫切需求
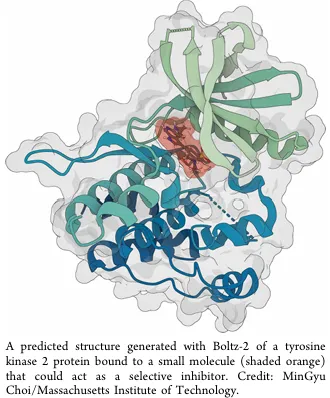
在药物研发早期阶段,计算建模可帮助科研人员筛选出具备潜力、可进入临床前开发的分子,而机器学习技术能大幅提速并拓展这一流程,核心应用场景包括:药物吸收、分布、代谢、排泄与毒理(ADMET)特性预测,以及基于结合亲和力与 3D 结构的药物 – 蛋白相互作用图谱绘制。上述所有 AI 工具的性能,都高度依赖训练数据的规模、质量与多样性。以 AlphaFold 为例,其强大的蛋白质结构预测能力,源于蛋白质数据库(PDB)中约 25 万个、历经数十年积累的蛋白质结构数据训练。但药物研发所需的 AI 工具,对数据的复杂度要求远高于单纯的蛋白质结构。哥伦比亚大学系统生物学助理教授、开源工具 OpenFold 开发团队负责人 Mohammed AlQuraishi 指出,目前行业内蛋白质与小分子结合的结构数据极为稀缺。其团队开发的最新版本 OpenFold3,已实现蛋白质 – 小分子复合物的建模功能。药物研发领域对药物 – 蛋白相互作用数据的巨大需求,也体现在开源模型 Boltz-2 的广泛应用上。该模型由麻省理工学院 Regina Barzilay 教授团队开发,可预测蛋白质与其他分子相互作用的结构及结合亲和力,累计下载量已超 120 万次,核心用户群体为药物研发从业人员。图中为 Boltz-2 生成的酪氨酸激酶 2 蛋白与小分子结合的预测结构,该小分子以橙色阴影标注,具备成为选择性抑制剂的潜力。更充足的训练数据,可显著提升 AlphaFold、OpenFold3、Boltz-2 等工具的药物 – 蛋白相互作用预测精度,ADMET 特性预测模型同样高度依赖相关药物数据。但这类核心研发数据,大多并未像 PDB 数据一样向全行业公开,而是分散封锁在各制药企业的专有数据库中。Barzilay 教授提出,作为 AI 工具的核心使用方,制药企业通过资助数据生成或开放自有数据,最终能实现全行业的合作共赢。
三、基于现有数据的联邦学习解决方案
针对训练数据短缺与数据保密的核心矛盾,制药行业提出的核心解决方案之一是联邦学习。该模式可让参与方在不泄露自有核心数据的前提下,联合完成 AI 模型训练:各参与机构在本地私有数据上训练算法副本,仅共享数据带来的算法更新参数,而非原始数据本身,从根源上平衡了数据保密与联合训练的需求。
FAITE(联邦 AI 治疗工程)计划该项目聚焦抗体等免疫治疗用生物药的研发。参与方安进公司研发副总裁 Marti Head 指出,生物药数据往往在不同实验条件、不同检测方法与格式下生成,存在严重的碎片化问题,直接限制了模型在不同项目、不同机构间的泛化能力。目前该计划已由 5 家制药企业启动试点,验证联邦学习能否实现企业基于集体生物药数据,安全合规地完成 AI 工具训练。
(二)行业先驱实践与现存挑战
上述项目均深度借鉴了 2019-2022 年开展的 MELLODDY 项目(药物发现机器学习账本编排)的实践经验。该项目由 10 家制药企业联合学术界、英伟达等科技公司共同完成,首次实现了制药企业在不泄露自有数据的前提下联合训练 AI 工具,验证了联邦学习在药物研发领域的技术可行性。但该项目也暴露了联邦学习的核心行业痛点:一是参与收益失衡,数据贡献量大的参与方收益有限,而数据贡献量小的参与方获得了更高的模型提升收益;二是数据兼容性问题,参与方必须提前统一数据标准,保障各合作方贡献数据的质量一致性与可重复性。此外,联邦学习无法突破现有数据的固有局限。当前药物研发流程中积累的数据,仅覆盖了与已知疾病相关的部分分子,而 AI 算法还需学习研究较少的分子信息,以及实验产生的阴性数据。阿斯利康计算化学家 Ola Engkvist 表示,数据多样性不足,是联邦学习面临的核心瓶颈。
四、面向全行业的规模化公开数据生成
针对现有数据的固有局限性,行业提出了另一核心解决路径:多家机构联合生成全新的标准化数据,并全部纳入公共领域,供全行业免费使用。Engkvist 提出,相较于搭建更复杂的联邦学习体系,联合生成公开数据,或许是解决 AI 药物研发数据缺口更高效的方案。
(一)核心落地项目
Ligand-AI 项目该项目由辉瑞公司与结构基因组学联盟(SGC)牵头,联合多家制药企业、高校、医院与科技公司共同推进,核心目标是生成数十亿小分子与蛋白质相互作用的相关数据,且所有数据均为 AI 工具训练定向生成。SGC 首席执行官 Aled Edwards 表示,项目生成的所有新数据均作为公共资源完全公开,任何 AI 工具开发者均可无限制使用,其定位与价值,与 PDB 数据库对蛋白质折叠预测工具的支撑作用一致。该项目还解决了大规模数据集的存储与使用痛点,搭建了专属数据库,无需开发者下载海量数据集即可完成工具测试,同时提供交互式环境,支持用户上传并运行自有 AI 模型。
Credit: Diamond Light Source. 图中为保存在液氮中的蛋白 – 小分子结合晶体,将被置于 Diamond Light Source 同步辐射光束线中开展检测;通过 X 射线晶体学解析的蛋白 – 配体结构,将被纳入 OpenBind 项目,用于 AI 工具训练。
(二)数据与模型的协同优化
公开数据集的核心价值,最终将通过 AI 模型的训练效果体现。AlQuraishi 指出,数据与建模之间存在紧密的耦合关系:建模结果明确了需要采集的数据类型与方向,新数据又能提升模型质量,进而推动下一轮数据采集与模型优化的正向循环。目前 OpenFold 已与 OpenBind 达成合作协议,将基于项目生成的新结构数据测试模型;同时数据完全向行业开放,其他 AI 工具也可无限制使用。
联邦学习与规模化公开数据生成两大路径,核心目标高度一致:优化药物研发 AI 工具,提升早期药物研发效率。这一共同目标也推动了开源工具开发者与联邦学习项目方的深度合作。例如,OpenFold 正与多家制药企业组成的 AI 结构生物学网络(联邦学习项目)合作,企业将在不泄露自有数据的前提下训练 OpenFold3,不仅为模型提供了更多训练数据,还补充了药物及类药化合物的高相关性行业数据。OpenBind 也计划与制药企业深度合作,依托企业的药物研发实操经验,反馈验证采集数据对研发工具的优化效果,而这也是判断 AI 工具实际行业价值的核心依据。文章同时明确了 AI 在药物研发中的价值边界:AI 工具可显著提升候选药物筛选的效率,但很难大幅加快药物研发的整体进程。Edwards 指出,一款药物从靶点发现到成功上市,平均需要 10-20 年,AI 最多只能将早期 1 年的研发周期缩短至 6 个月。但 AI 工具可大幅解放早期计算阶段研发人员的时间与精力,助力其产生更多创新的先导化合物开发思路,引导研发人员聚焦更具潜力的分子与研发方向,再通过实验完成验证。当前,数据生成与联邦学习领域的快速发展,体现了制药企业与公共科研机构对 AI 药物研发的高度期待,但行业仍处于起步阶段。目前尚无一款 AI 设计的药物成功上市,首批相关药物仍处于临床试验阶段。Engkvist 总结道,AI 在药物研发领域的应用是一场马拉松,而非短跑。
 夜雨聆风
夜雨聆风