 夜雨聆风
夜雨聆风





99% 代码由 AI 写:让 AI 当陪审团审 AI
一份来自前 Meta LLaMA 团队成员的工程实录:把”模型评估”和”QA”合并成同一个闭环

封面
0|引子
2026 年 3 月,CreaoAI 联合创始人 Peter Pang(@intuitiveml,前 Meta GenAI / LLaMA 团队、前 Apple)写过一句话:他们公司 99% 的产线代码是 AI 写的。
这不是噱头。他们已经把整个工作流推倒重来,让 agent 站在中间,每天往生产环境上线 3 到 8 次。
2026 年 4 月 28 日,他又发了一篇长文《The Self-Healing Agent Harness》。这一次他要回答一个被其它创始人反复追问的问题:
那谁来测试它?
答案不是”招更多 QA”。他们没有 QA 团队,没有 staging 环境给人去点,也没人坐在那里读 agent 的对话记录、给回复打分。
他们做了另一件事:让 AI 自己当陪审团,自己抓 bug,自己写 PR,自己验证修复,自己决定一次发布能不能放量。这套系统叫 Self-Healing Agent Harness。
这篇文章拆它的内部结构。
1|为什么”评估”和”QA”必须合二为一
在传统 SaaS 公司里,这是两条井水不犯河水的线。
模型评估问的是:模型在线上回答得好不好?这件事归 ML 或数据科学团队,他们的产物是 dashboard。
QA 问的是:产品在生产里能不能用?这件事归工程团队,他们的产物是 ticket、修复和发布。
但对一个 AI agent 平台来说,这两个问题其实是同一个问题。一条糟糕的 agent 回复,既是一个要画到指标图上的数字,也是一个要进 ticket 系统去 triage 的 bug。
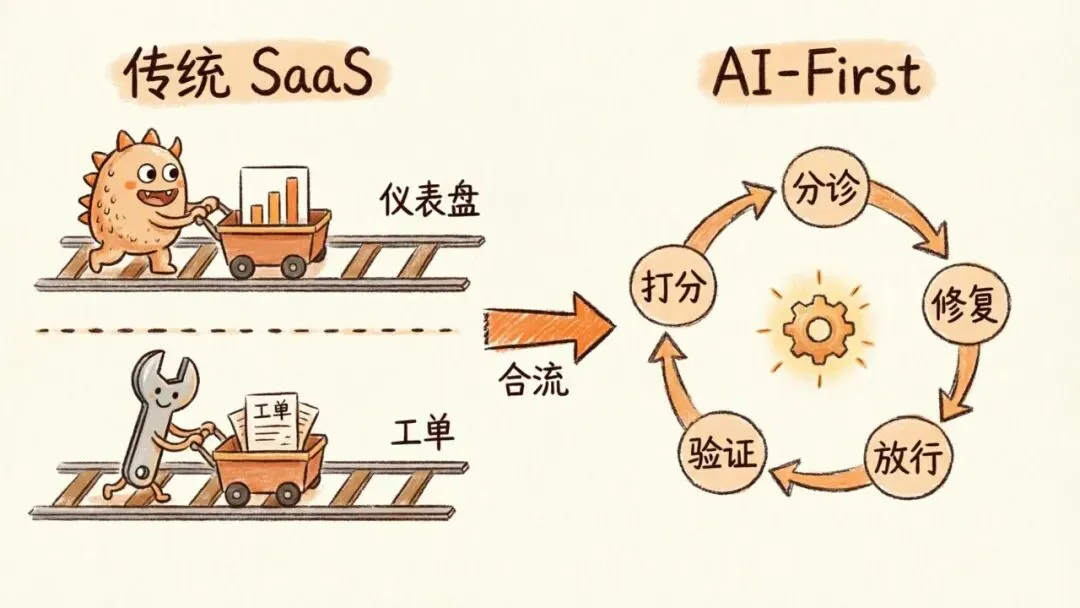
评估与 QA 合流
更麻烦的是,它的根因可能藏在 6 个完全不同的地方:
- 模型推理崩了或者直接幻觉
- 集成接口抛了 500、token 过期、payload 变形,agent 把这些坏数据原样吐了出来
- 基础设施抽风,比如 Cloudflare 超时、Postgres 副本延迟、ECS 任务跑一半 OOM
- 某个工具的 schema 在上游悄悄变了,agent 传参不再匹配
- Prompt 通路出问题,system prompt 被截断、RAG 取错 chunk、记忆没加载
- 一次部署回归悄悄拉低了某个小组件的表现
但对用户来说,这些看上去都是同一件事:一句烂回复。对打分器来说,它们也长得一样:某个 messageId 上的低分。
Pang 在文里写到一个核心命题:当 AI 把”写代码”这件事从月压缩到小时,下游每个环节都会变成新的瓶颈。如果”评估”和”QA”还各干各的,那就是双倍瓶颈。
合并之后的闭环,他们叫 Agent Harness。它跑一个自愈循环,串起三个组件:
- Grader:替代人工评审和离线 benchmark
- Engineering Pipeline:替代人工 triage、迭代规划、回归测试
- Bridge:替代 staging 环境和发布审批
下面分开讲。
2|Component 1:Grader —— 三家厂商组成的陪审团
打分这件事,最难的不是”判断这段代码能不能编译”,而是”判断 agent 的这段回复在逻辑上到底好不好”。
这件事过去是人在做。现在,他们用一个异步打分 endpoint 接住了它。每一次 assistant 出完话,立刻对外发一个 POST,带上 messageId、threadId、以及最终承担回复的模型(fallback 之后的那一个)。打分整条链路在主请求之外跑,不给用户加一毫秒延迟。
这是整个 harness 的眼睛。下游所有组件都依赖这双眼睛足够准。
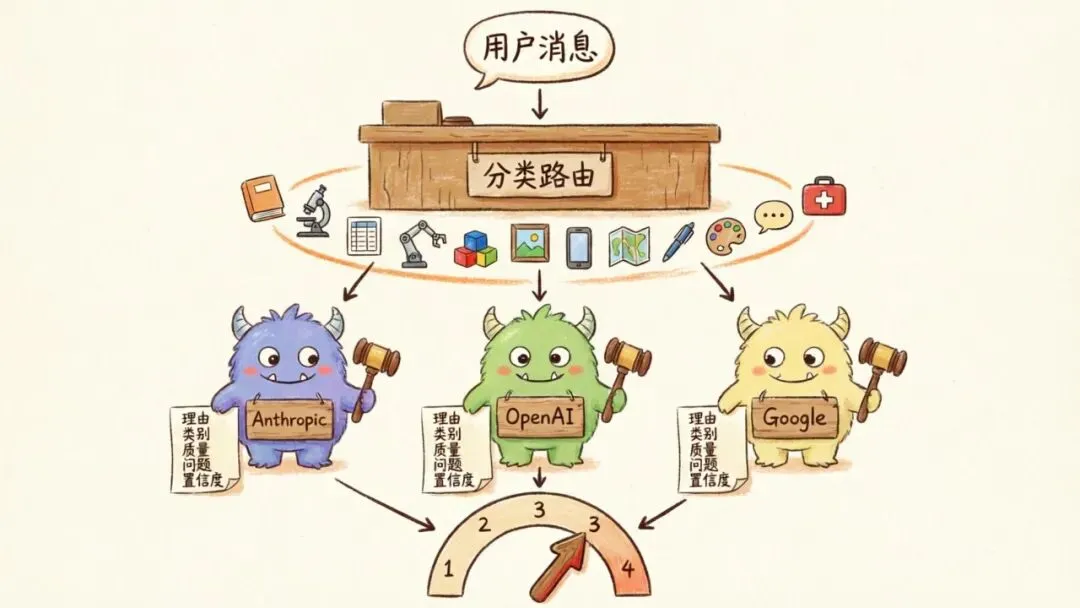
Grader 三家陪审团
分层采样:按模型,不是按流量
他们的主力模型是 Sonnet 4.6,承担了平台上约 24 倍于其他模型的流量。如果走”统一抽 X%”的扁平采样,少数模型永远跑不出统计显著性。
所以他们的采样策略是:
- Sonnet 4.6 抽 10%(流量大头,少抽一点也够看趋势)
- 其他所有模型抽 100%(Opus、GPT、Gemini 等少数派或实验中的模型)
这是少数模型能在数小时之内、而不是数周之内拿到足够样本去 gate 一次灰度的关键。
Job 0:先分类再打分
在三位判官看到 transcript 之前,先有一个轻量分类器(Job 0)把这次交互打上类别标签。他们把所有产品场景归成 12 个领域:编码、研究、数据分析、任务自动化、agent building、artifact building、传统应用构建、规划、写作、创意工作、对话、错误恢复。
为什么先分类?因为”一段好的代码答复”和”一段好的研究答复”应该看不同的红线。判官拿到的 rubric 是按类别裁过的。
三家厂商,三种人格
正式打分时,他们并行跑三个判官,分别属于三个不同的模型家族:Anthropic / OpenAI / Google。三个判官走不同的人格 prompt,通过自家的 AI Gateway 并发调用。任意一家慢了或者挂了不会拖死流程,只是这一行的法定人数(quorum)会少一票。
为什么必须跨家?因为模型给自己写的回复打分会偏高 —— 他们实测下来,Sonnet 给 Sonnet 打分会比真实分数偏高 ~0.3。光靠一家的判官无法消除这种自偏好。但当 OpenAI 和 Google 在不同人格下也都说”这个不行”,自偏好就被洗掉了。
每个判官必须用 schema 锁定的工具调用 submit_evaluation 返回 5 个字段:
- reasoning —— 2 到 3 句话的步骤化理由
- category —— 这次评判的领域
- quality —— excellent / good / acceptable / poor
- issues —— 9 项问题分类中的若干项(incomplete、hallucination、toolmisuse、missedcontext 等)
- confidence —— 0 到 1 的浮点数
但即便三家都同意,他们也不全信。他们仍然把一小撮判决回采给真人做周期性校准。如果判官共识和人工评审之间出现稳定偏差,他们会把这当作 rubric 里的 bug,而不是”可以容忍的误差”。
取均值,不投票
quality 那 4 档被映射成 1–4 的连续分,跨判官取平均而不是投票。这一改让一个本来钝得不行的 4 档量表变成了一个连续的指标 —— 3.33 比 2.66 是肉眼可见的差距,趋势能在更小的样本上显现出来,比”3 比 2 多数票通过”敏感得多。
每条判决的原始数据他们都会保留:sonnetquality、gptquality、geminiquality、judgecount,便于事后审计。哪天某一家判官开始系统性偏移,他们可以重新加权。
一句话定位
Grader 不是用来排行模型的。它是产品级的 bug 探测器。Pang 在文里特地强调过:如果两位判官在同一个 messageId 上都打了 poor,他们学到的不是”哪家模型更强”,而是”我们自己 pipeline 的某一环坏了,去修”。
3|Component 2:Engineering Pipeline —— 从分数到 PR 的 6 个 Job
学术界已经有不少论文证明”自动 bug 修复”是可行的。但论文不在生产环境跑。如果 AI 在 benchmark 上幻觉一个修复,你拿到的是一个差分;如果 AI 在你的活体代码库上幻觉一个修复,你拿到的是一次故障。
Engineering Pipeline 接 Grader 的输出。一个低分就是一份 bug 报告,6 个 Job 把这份报告推到一份已经被验证为有效的修复。
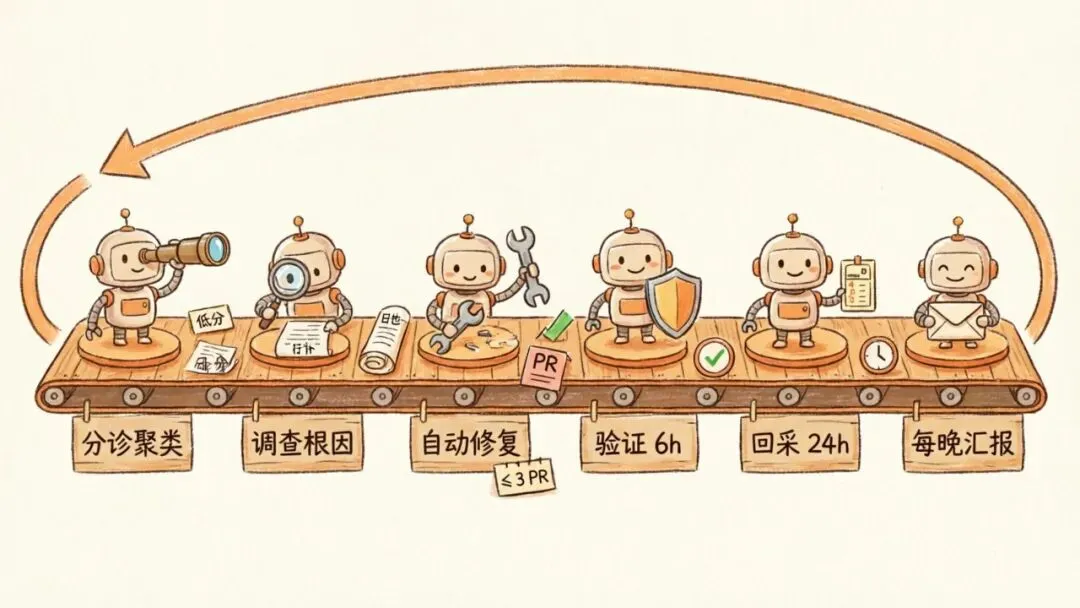
6-Job 流水线
Job 1:Detect & Triage
一个 agent 拉起所有被打成 poor 的判决,做聚类,再用一个 9 维严重度引擎给每一簇打分:用户影响、传播速度、持续时长、告警相关性、资源压力、延迟、4xx 比例、爆炸半径、业务关键性。超过紧急度阈值的进入下一步,剩下的进趋势日志。
Job 2:Investigate
挑出 top 3 簇,agent 走 monorepo 里的 stack trace、拉 CloudWatch 日志、查最近的部署、查 DB replica。最后给出一个根因,并把一份完整证据包附在 ticket 上路由给真人。
注意这一步不是替真人做决定,而是把真人需要做的”翻日志、串证据”先包圆。
Job 3:Auto-Fix
只对高置信、高紧急的问题动手:开新分支、写补丁、跑校验、起一份 draft PR。
护栏比野心更重要:
- 每次最多 3 个 PR。Reviewer 是有上限的,bot 一旦把人淹了,整个流程就废了。
- 触碰
.env、.github/、IAM policies 的 diff 自动关闭,不上 review。 - 类型错误直接拦截。
- 测试失败直接拦截。
文章里有一句很克制的话:他们不试图在 Auto-Fix 这一步去修深层架构债,他们只想把”显眼的小 bug”快速吃掉,把人类的注意力还给真正需要思考的事情。
Job 4:Verify
对所有进入 In Review 状态的 ticket,系统去查过去 6 小时的 CloudWatch。零次复现就关单,把 telemetry 证据贴进 comment。还在出错就更新错误计数,回到循环里。
这一步的意义是:把”回归测试”从一件人工动作,变成一道客观的时间窗口验证。
Job 5:Re-grade
关单之后并不算结束。Grader 在接下来的 24 小时内对该簇做 100% 采样。一旦发生回归,自动重开 ticket 并 revert 修复。
也就是说,”修复有没有真的修好”这件事,仍然由打分器闭环兜底。
Job 6:Report
每晚一份 digest 落到 Linear 和团队频道:检测到多少簇、上线了多少 PR、回滚了多少 PR、各类别分数变化、各模型排行。dashboard 不是目的,它只是闭环跑过之后留下的痕迹。
4|Component 3:Bridge —— AI 把守的灰度发布
前两个组件兜的是已经上线的 bug。第三个组件兜的是即将上线的 bug。
自愈流水线对小创口处理得不错。但当你换掉一个底层模型、改写一段核心 system prompt、给某个 agent 大幅扩权工具访问,行为风险会陡然拉高。这种时候你不能直接推全量然后祈祷。
Bridge 是 Grader 和 Engineering Pipeline 见面的地方。Grader 的分数被当作发布闸门之一(实际上还有别的闸门,但 Pang 在文里只展开了这一项)。没有 staging 环境,没有人在 PR 里写”看着行”。

灰度阶梯 Bridge
灰度阶梯
当一个重大 agent 变更合入主干,他们会把约 10% 的真实流量切给新版本,让它和当前生产基线同时跑。Grader 实时给两者打分,做对照。
晋升阶梯是自动的:
- 失败:判官面板的均值跌幅 ≥ 0.15、p < 0.05、最小 200 次交互窗口;或者他们的确定性 bug 探测器在这 10% 队列里发现新错误簇暴增 —— 任意一条命中,pipeline 直接中止 rollout、把流量切回稳定版本、开一张 Linear ticket,把这一批回归样本附上去。这张 ticket 进 Component 2 的 Job 1 入口。闭环成立。
- 持平或更优:cohort 按 5% → 20% → 50% → 100% 阶梯放量,每一档都用同一套统计检验在新窗口上重测一次。
模型在真实用户流量上证明自己的安全性,而爆炸半径被 cohort 大小卡死。
5|从生产里打磨出来的三条硬经验
文章末尾有一段很短但很重的总结。如果你也在往 AI-first 工程流程上迁,这三条值得抄下来。

三条硬经验
1. 评判产物,不评判路径。 他们早期惩罚过 agent 做”不必要的工具调用”。结果发现这并不持续 —— agent 经常会找到一些在人类看来奇怪、但效果非常好的非线性解。和近期的 agentic 研究结论一致:评判最终产物比微管理过程稳健得多。
2. 按模型采样,不按流量采样。 扁平采样会让主力模型显得是”唯一存在的模型”,少数派模型永远拿不到统计显著性,于是你永远不会去投资它们。
3. 没有 ticket 的分数 = 没人看的 dashboard。 打分器没有工程流水线接住就是空响铃。工程流水线没有打分器喂信号就是瞎子。要么两个都建,要么都别建。
6|AI-Assisted 与 AI-First 的真正分水岭
这篇文章真正咬人的一句在最后。
大多数公司还在把 Copilot 嫁接在原来的工作流上。他们跑标准的 CI/CD,跑标准的人工 QA。他们用小时写代码,用天测试代码。他们是 AI-assisted,不是 AI-first。
竞争优势会归于那些不再把”模型评估”和”QA”当成两件事的团队 —— 归于那些真的去把这两件事融成同一个 harness 的团队。
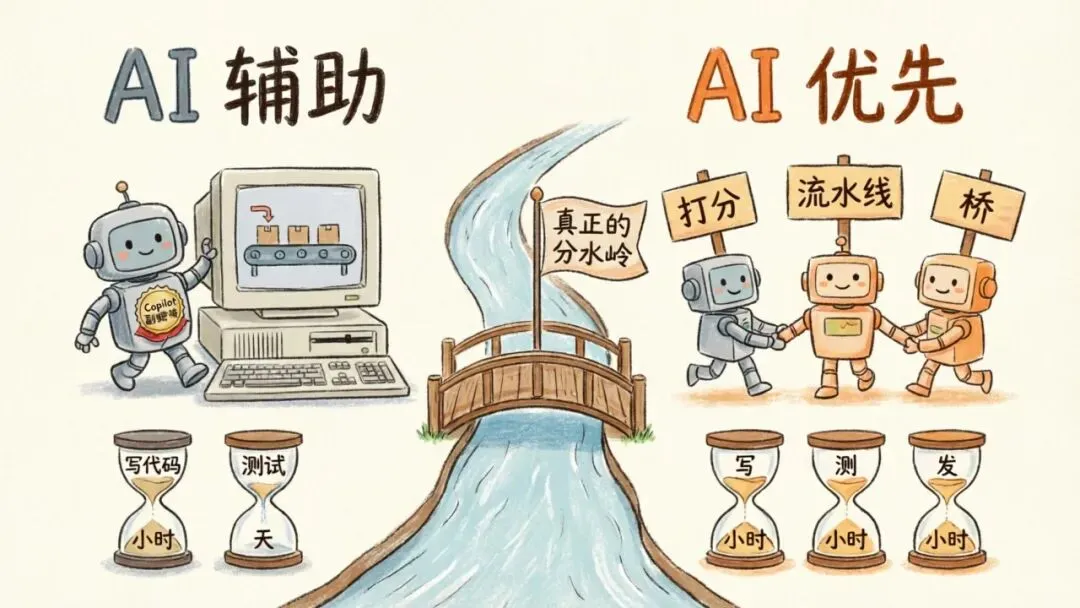
AI-assisted 与 AI-first 分水岭
Pang 是这么收尾的:
我们做一个 agent 平台。我们用 AI 陪审团测试它,我们按陪审团的判决发布它,我们让陪审团在出现回归时自己重开案子。
The harness tightens day by day.
—— harness 一天比一天勒得更紧。
后记:可以直接抄回去的几条工程动作
如果你只想从这篇文里带走可执行项,下面这些是密度最高的:
- 打分异步化:放在主请求之外,永不污染用户延迟
- 采样按模型而非按流量:主力 10%、其余 100%
- 打分前先分类:让 rubric 跟着场景走
- 跨家陪审团 + 连续分均值:自偏好被稀释,趋势更早可见
- Auto-Fix 加护栏:每次 ≤ 3 PR、敏感路径黑名单、类型错与测试失败硬拦
- 6 小时验证窗口 + 24 小时 re-grade:把”回归测试”变成确定性闸门
- 灰度由分数 gate:跌幅阈值 + 显著性 + 最小窗口三件套
参考来源
- The Self-Healing Agent Harness — Peter Pang (@intuitiveml):https://x.com/intuitiveml/status/2048912026018484317
- CreaoAI(作者所在公司的 agent 平台):https://creao.ai
——
本文由 Zero (https://github.com/V1ki/zero) 协助分析与撰写。原推文阅读、要点拆解、文章结构与配图方案均由 Zero 在用户偏好约束下自主完成,最终内容经人工审阅。