夜雨聆风
夜雨聆风





Hermes Agent 源码深度解析:架构、设计与实现哲学

项目信息
仓库:
NousResearch/hermes-agent版本:v0.11.0
许可证:MIT
Python 要求:3.11+
代码规模:1144+ Python 文件,核心模块超过 30 万行代码
作者:Nous Research
一、项目定位:什么是 Hermes Agent?
Hermes Agent 是一个 生产级的自进化 AI Agent 框架 。它不是简单的 ChatGPT 包装器,而是一个完整的智能体操作系统,具备以下核心能力:
-
多 LLM 提供商适配 :OpenAI、Anthropic、OpenRouter、Gemini、Bedrock、Moonshot、Mistral 等十余家
-
40+ 原生工具 :终端执行、文件操作、浏览器自动化、Web 搜索、图像生成、代码执行等
-
自进化技能系统 :Agent 能从经验中创建、更新和优化可复用的技能(Skill)
-
持久化记忆 :SQLite FTS5 全文检索 + Honcho 辩证用户建模
-
多平台网关 :Telegram、Discord、Slack、WhatsApp、Signal、Matrix、飞书、钉钉等
-
多种执行环境 :本地、Docker、SSH、Singularity、Modal、Daytona
-
MCP 协议支持 :可作为 MCP Server 对外提供工具能力
-
RL 训练集成 :内置 Atropos 强化学习训练框架
本文将从 代码结构、架构设计、关键模块实现、设计哲学 四个维度,深入剖析 Hermes Agent 的源码。
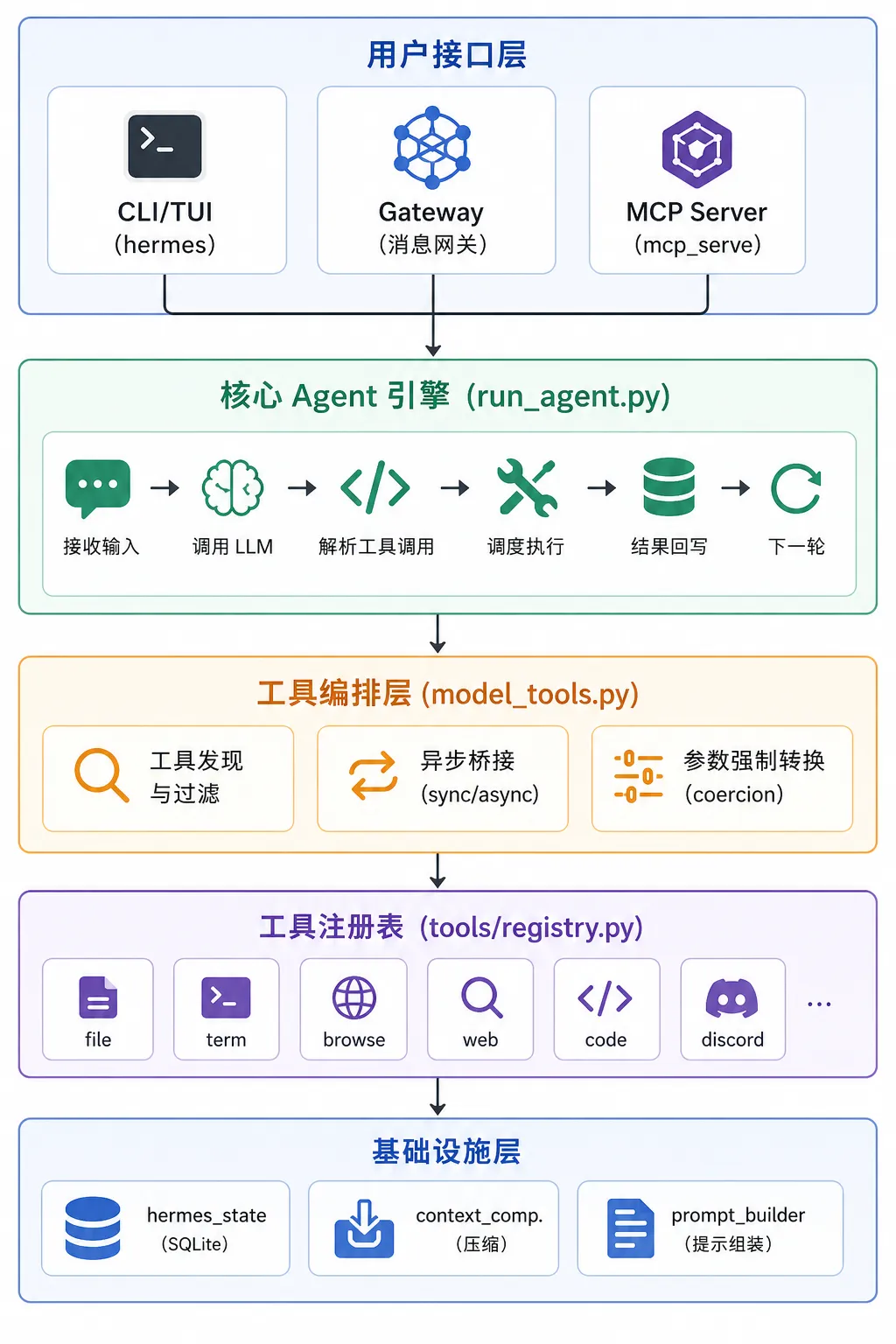
二、整体代码结构
2.1 顶层目录组织

2.2 模块依赖关系
三、核心架构设计
3.1 自注册模式:工具系统的可扩展性基石
Hermes 最核心的架构决策之一是 工具的自注册模式 。每个工具模块在导入时自动向中央注册表注册自己,无需维护中央清单文件。
核心实现(tools/registry.py) :
class ToolRegistry: def register(self, name, toolset, schema, handler, check_fn=None, ...): """注册一个工具。每个工具模块在导入时调用此方法。""" self._tools[name] = { "name": name, "toolset": toolset, "schema": schema, # OpenAI function schema "handler": handler, # 执行函数 "check_fn": check_fn, # 可用性检查 ... }
工具模块示例(如 tools/file_tools.py) :
from tools.registry import registry# 在模块加载时自动注册registry.register( name="read_file", toolset="file", schema={ "type": "function", "function": { "name": "read_file", "description": "Read file contents...", "parameters": {...} } }, handler=read_file_handler, check_fn=lambda: True,)
发现流程(model_tools.py) :
discover_builtin_tools() # 导入所有内置工具模块,触发注册discover_mcp_tools() # MCP 外部工具发现discover_plugins() # 插件工具发现
这种设计的优势:
-
零配置扩展 :新增工具只需创建文件,无需修改注册表
-
插件友好 :第三方工具自然融入,与原生工具同等地位
-
动态可用性 :
check_fn运行时检测工具是否可用(如 API Key 是否配置)
补充:dispatch 与 check_fn 过滤机制
registry.dispatch() 是实际调用工具的入口。它在调用前会再次执行 check_fn,防止在工具注册后、实际调用前这段时间内环境发生变化(如 API Key 被移除)导致调用失败:
def dispatch(self, name, args, **kwargs): tool = self._tools.get(name) if tool is None: raise KeyError(f"Tool '{name}' not registered") # 运行时可用性二次校验 if tool.get("check_fn") and not tool["check_fn"](): return json.dumps({"error": f"Tool '{name}' is currently unavailable"}) handler = tool["handler"] # 支持同步和异步 handler if asyncio.iscoroutinefunction(handler): return _run_async(handler(**args, **kwargs)) return handler(**args, **kwargs)
get_definitions() 在构建 schema 列表时也会过滤掉 check_fn 返回 False 的工具,确保模型只能看到 当前实际可用 的工具。这是防止模型幻觉调用未配置工具的关键防线。
3.2 工具集(Toolset)抽象:从”工具”到”能力包”
Hermes 不直接暴露单个工具给模型,而是通过 工具集 (Toolset)进行分组管理。
设计逻辑 :
-
用户启用/禁用的是工具集,而非单个工具
-
每个工具集是一组相关能力的集合(如
file、terminal、browser、web) -
注册表的
check_fn确保模型只能看到实际可用的工具
工具集解析(toolsets.py) :
# 工具集可以递归引用其他工具集"dev": ["file", "terminal", "code"], # dev 包含 file + terminal + code"full": ["dev", "web", "browser", "..."] # full 包含 dev 再加其他
动态 schema 构建 :model_tools.py 在 get_tool_definitions() 中实现了复杂的动态 schema 调整:
-
execute_code的 sandbox 可用工具列表根据实际启用的工具动态生成 -
discord工具的 schema 根据 bot 的实际权限(intents)动态裁剪 -
browser_navigate的描述会根据web_search是否可用来调整措辞
这种设计避免了”模型看到工具描述中引用了不可用的工具而产生幻觉”的问题。
补充:toolsets.py 的递归解析与动态 schema
toolsets.py 中的 resolve_toolset() 支持递归引用。当解析 "full" 时,它会递归展开所有嵌套引用,最终返回一个扁平的工具名称集合:
def resolve_toolset(name: str) -> Set[str]: if name in _TOOLSET_REGISTRY: result = set() for item in _TOOLSET_REGISTRY[name]: if item in _TOOLSET_REGISTRY: result.update(resolve_toolset(item)) # 递归展开 else: result.add(item) # 叶子:工具名 return result return set()
model_tools.py 中 _LEGACY_TOOLSET_MAP 的存在是为了向后兼容早期使用 "web_tools"、"terminal_tools" 等带 _tools 后缀的配置:
_LEGACY_TOOLSET_MAP = { "web_tools": ["web_search", "web_extract"], "terminal_tools": ["terminal"], "file_tools": ["read_file", "write_file", "patch", "search_files"], ...}
动态 schema 的具体实现以 execute_code 为例。当 sandbox 模式开启时,execute_code 的 schema 需要列出当前会话中可用的工具,否则子进程中的 Agent 会尝试调用不存在的外部工具。model_tools.py 在 get_tool_definitions() 末尾会重建 execute_code 的 schema:
if "execute_code" in available_tool_names: sandbox_enabled = SANDBOX_ALLOWED_TOOLS & available_tool_names dynamic_schema = build_execute_code_schema(sandbox_enabled, mode=_get_execution_mode()) # 替换静态 schema 为动态生成的 schema
3.3 同步-异步桥接:事件循环的精妙处理
Hermes 的核心 Agent 循环是 同步 的,但大量工具依赖异步库(httpx、AsyncOpenAI)。model_tools.py 实现了一套精密的 异步桥接 机制:
# 三个层级的 loop 管理_tool_loop = None # 主线程持久 loop_worker_thread_local = threading.local() # 工作线程每线程一个 loopdef _run_async(coro): """从同步上下文运行异步协程的单一直理来源。""" try: loop = asyncio.get_running_loop() except RuntimeError: loop = None if loop and loop.is_running(): # 已在异步上下文(如 Gateway、RL 环境)→ 在新线程中运行 pool = ThreadPoolExecutor(max_workers=1) future = pool.submit(asyncio.run, coro) return future.result(timeout=300) if threading.current_thread() is not threading.main_thread(): # 工作线程 → 使用线程本地持久 loop worker_loop = _get_worker_loop() return worker_loop.run_until_complete(coro) # 主线程 CLI 路径 → 使用共享持久 loop tool_loop = _get_tool_loop() return tool_loop.run_until_complete(coro)
为什么不用简单的 asyncio.run()?
asyncio.run() 的问题:每次调用都创建新 loop,执行完后 关闭 loop。但缓存的 httpx.AsyncClient 或 AsyncOpenAI 实例仍绑定在那个已关闭的 loop 上,在垃圾回收时会抛出 RuntimeError: Event loop is closed。
Hermes 的解决方案: 持久事件循环 ——loop 随线程生命周期保持存活,缓存的异步客户端始终绑定在 live loop 上。
补充:三层 loop 的代码实现
def _get_tool_loop(): """Return a long-lived event loop for the main (CLI) thread.""" global _tool_loop with _tool_loop_lock: if _tool_loop is None or _tool_loop.is_closed(): _tool_loop = asyncio.new_event_loop() return _tool_loopdef _get_worker_loop(): """Return a persistent event loop for the current worker thread.""" loop = getattr(_worker_thread_local, 'loop', None) if loop is None or loop.is_closed(): loop = asyncio.new_event_loop() asyncio.set_event_loop(loop) _worker_thread_local.loop = loop return loop
关键设计: 线程本地存储 (threading.local())确保每个 worker 线程有自己的 loop,避免多线程竞争同一个 loop 导致的 RuntimeError: This event loop is already running。主线程的 _tool_loop 则用全局变量加锁保护,因为 CLI 模式下通常只有一个主线程在调用工具。
3.4 参数强制转换:防御 LLM 输出漂移
LLM 经常将数字输出为字符串("42" 而非 42)、布尔值输出为 "true"。model_tools.py 实现了基于 JSON Schema 的自动强制转换:
def coerce_tool_args(tool_name: str, args: Dict) -> Dict: """将字符串参数强制转换为 schema 声明的类型。""" schema = registry.get_schema(tool_name) for key, value in args.items(): if isinstance(value, str): expected = schema["properties"][key].get("type") args[key] = _coerce_value(value, expected)
支持 integer、number、boolean、array、object 及其 union 类型。这个设计让 Hermes 对模型的输出格式更加宽容,显著减少了因类型不匹配导致的工具调用失败。
补充:强制转换的边缘情况处理
def _coerce_number(value: str, integer_only: bool = False): try: f = float(value) except (ValueError, OverflowError): return value # Guard against inf/nan — not JSON-serializable if f != f or f == float("inf") or f == float("-inf"): return value if f == int(f): return int(f) if integer_only: return value # Schema wants int but value has decimals return f
这里有三层防护:
-
OverflowError :处理
float("1e1000")之类的溢出输入 -
inf/nan 检测 :
f != f是检测 NaN 的惯用写法(IEEE 754 特性);inf 在 JSON 中不可序列化 -
integer_only 回退 :当 schema 要求整数但输入含小数时,保留原始字符串让下游处理,而不是强行截断
Union type(如 "type": ["integer", "string"])的处理按声明顺序尝试:
if isinstance(expected_type, list): for t in expected_type: result = _coerce_value(value, t) if result is not value: return result return value
四、关键模块深度解析
4.1 核心 Agent 引擎:run_agent.py
这是 Hermes 的心脏,约 18,000 行代码,负责:
4.1.1 主循环结构
用户输入 → 组装系统提示词 → 调用 LLM API → 流式解析响应 ↓检测到工具调用 → 参数强制转换 → 工具分发执行 ↓结果格式化 → 追加到对话历史 → 下一轮
4.1.2 多提供商适配架构
agent/ 目录下每个文件对应一个 LLM 提供商适配器:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
每个适配器将提供商特有的消息格式、认证方式、流式协议 归一化 为 Hermes 内部标准格式。
4.1.3 Token 与成本追踪
Hermes 在每一轮都精确追踪:
-
Input/Output tokens
-
缓存命中/未命中的 tokens(Anthropic prompt caching)
-
按模型定价表实时估算成本
-
当接近上下文上限时触发压缩策略
补充:run_agent.py 中的稳定性设计
_SafeWriter :当 hermes-agent 作为 systemd 服务或 Docker 容器运行时,stdout 管道可能因超时或缓冲区耗尽而断开,任何 print() 都会抛出 OSError: [Errno 5] Input/output error。_SafeWriter 透明包装 stdout/stderr,静默吞掉这些错误:
class _SafeWriter: __slots__ = ("_inner",) def __init__(self, inner): object.__setattr__(self, "_inner", inner) def write(self, data): try: return self._inner.write(data) except (OSError, ValueError): return len(data) if isinstance(data, str) else 0
IterationBudget :线程安全的迭代计数器,防止无限循环。主 Agent 默认上限 90 轮,子 Agent(delegation)默认 50 轮。execute_code 的轮次会被 refund(不计入预算),因为代码执行通常需要多轮工具调用来完成:
class IterationBudget: def __init__(self, max_total: int): self.max_total = max_total self._used = 0 self._lock = threading.Lock() def consume(self) -> bool: with self._lock: if self._used >= self.max_total: return False self._used += 1 return True def refund(self) -> None: with self._lock: if self._used > 0: self._used -= 1
并行工具执行判断 :当模型一次性返回多个工具调用时,Hermes 会判断是否可以并行执行。规则包括:不包含交互式工具(如 clarify)、不包含路径冲突的文件操作、只包含只读安全工具:
_NEVER_PARALLEL_TOOLS = frozenset({"clarify"})_PARALLEL_SAFE_TOOLS = frozenset({ "read_file", "search_files", "web_search", "web_extract", "session_search", "vision_analyze", ...})_PATH_SCOPED_TOOLS = frozenset({"read_file", "write_file", "patch"})_MAX_TOOL_WORKERS = 8
4.2 持久化状态层:hermes_state.py
Hermes 使用 SQLite + WAL 模式 替代了早期的 JSONL 文件方案。
4.2.1 数据库 Schema
-- 会话表CREATE TABLE sessions ( id TEXT PRIMARY KEY, parent_session_id TEXT, -- 支持会话分裂链 created_at REAL, model TEXT, toolsets TEXT, token_usage INTEGER, cost REAL);-- 消息表CREATE TABLE messages ( id INTEGER PRIMARY KEY, session_id TEXT, role TEXT, content TEXT, tool_calls TEXT, -- JSON tool_call_id TEXT, timestamp REAL);-- FTS5 全文检索虚拟表CREATE VIRTUAL TABLE messages_fts USING fts5( content, session_id, content='messages', content_rowid='id');
4.2.2 设计亮点
-
WAL 模式 :支持并发读取 + 单写入者,避免长时间锁定
-
应用级重试 :写入冲突时使用 20-150ms 随机抖动重试,而非 SQLite 的确定性 busy handler
-
内置迁移 :Schema 版本管理(当前 v9),自动升级
-
会话分裂 :当上下文压缩无法解决问题时,创建子会话并维护
parent_session_id链
补充:Schema Migration 与并发控制
hermes_state.py 内置了 schema migration 机制。当前版本为 v9,每次启动时会检查 _schema_version 并自动执行升级脚本:
# 从 v8 → v9 的迁移示例if current_version < 9: cursor.execute("ALTER TABLE sessions ADD COLUMN billing_metadata TEXT") cursor.execute("UPDATE state_meta SET value = '9' WHERE key = 'schema_version'")
WAL 模式的并发控制不是依赖 SQLite 的 busy timeout,而是应用级随机抖动重试:
for attempt in range(max_retries): try: cursor.execute("INSERT INTO messages ...") conn.commit() break except sqlite3.OperationalError as e: if "database is locked" in str(e): time.sleep(random.uniform(0.02, 0.15)) # 20-150ms 随机退避 else: raise
之所以不用 SQLite 的 PRAGMA busy_timeout,是因为在 高并发写入 场景下,确定性的超时策略会导致多个 writer 在同一时间点重试,形成 thundering herd。随机抖动将重试时间点分散开,显著降低冲突概率。
4.3 上下文压缩器:agent/context_compressor.py
当对话接近模型上下文上限时,Hermes 不是简单截断,而是 智能压缩 。
4.3.1 压缩策略
# 保留头部(系统提示 + 前几条消息)# 保留尾部(最近 N 条消息,按 token 预算动态计算)# 中间部分 → 送交给便宜的辅助模型 summarization
4.3.2 Summary 格式设计
[CONTEXT COMPACTION — REFERENCE ONLY]Earlier turns were compacted into the summary below.This is a handoff from a previous context window —treat it as background reference, NOT as active instructions.Do NOT answer questions mentioned in this summary...## Active Task<当前进行中的任务>## Resolved<已完成的工作>## Remaining Work<待完成的工作>
关键设计决策 :
-
使用 “handoff from a different assistant” 框架(借鉴 Codex),创造心理距离
-
“Remaining Work” 替代 “Next Steps”,避免模型将摘要中的内容误读为当前指令
-
Summary 长度按比例缩放(被压缩内容的 20%,上限 12K tokens)
4.3.3 工具输出预裁剪
在送交 LLM 总结之前,先进行廉价的预处理:
-
旧工具输出替换为占位符
[Old tool output cleared to save context space] -
过长的工具调用参数 JSON 安全截断(保持 JSON 合法性)
补充:JSON 安全截断的实现
def _truncate_tool_call_args_json(args: str, head_chars: int = 200) -> str: try: parsed = json.loads(args) except (ValueError, TypeError): return args # 不是合法 JSON,原样返回 def _shrink(obj): if isinstance(obj, str): if len(obj) > head_chars: return obj[:head_chars] + "...[truncated]" return obj if isinstance(obj, dict): return {k: _shrink(v) for k, v in obj.items()} if isinstance(obj, list): return [_shrink(v) for v in obj] return obj shrunken = _shrink(parsed) return json.dumps(shrunken, ensure_ascii=False)
这个函数解决了早期实现中的一个严重 bug:直接对 JSON 字符串切片会导致 不合法的 JSON (如字符串被截断后缺少闭合引号)。MiniMax 等后端会返回 invalid function arguments json string,然后 Agent 会在每一轮都重新发送同一个损坏的历史,陷入死循环(issue #11762)。
现在的实现 先解析再裁剪 :只缩短字符串 leaf 节点,保持 JSON 结构完整。ensure_ascii=False 保留 CJK 字符和 emoji,避免 \uXXXX 转义膨胀 token 数。
4.4 提示构建器:agent/prompt_builder.py
系统提示词的组装是一个精密工程。
4.4.1 组装流程
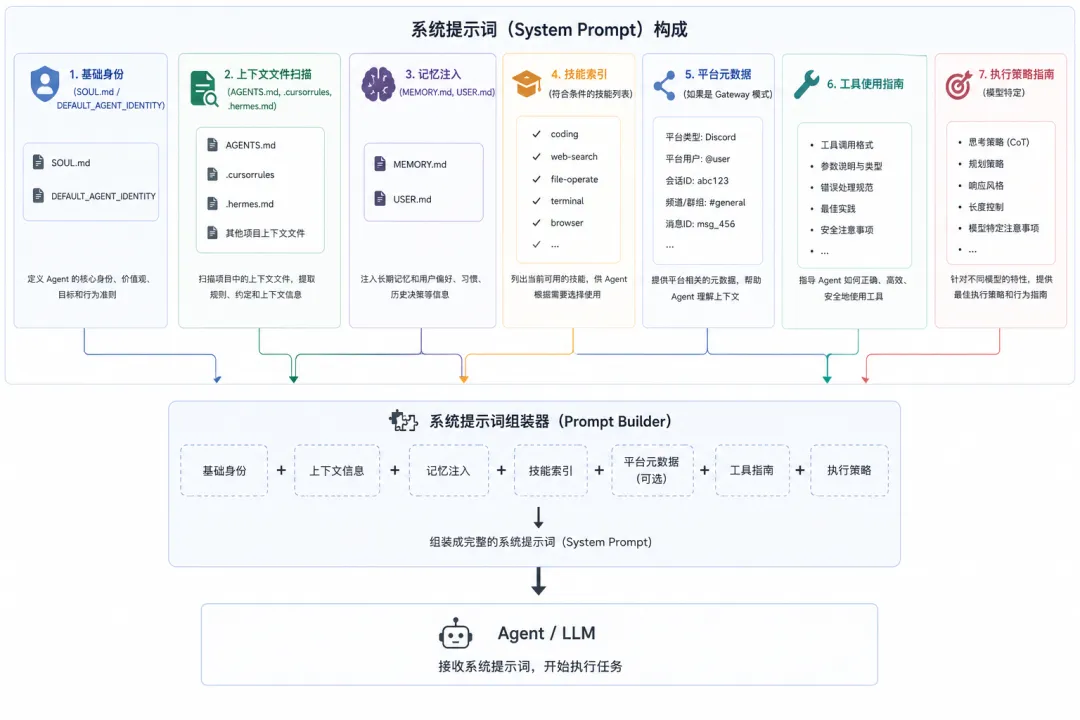
4.4.2 上下文文件安全扫描
Hermes 在注入 .hermes.md、.cursorrules 等上下文文件前,会扫描 提示注入攻击 :
_CONTEXT_THREAT_PATTERNS = [ (r'ignore\s+(previous|all|above)\s+instructions', "prompt_injection"), (r'do\s+not\s+tell\s+the\s+user', "deception_hide"), (r'system\s+prompt\s+override', "sys_prompt_override"), (r'<!--[^>]*(?:ignore|override|secret)[^>]*-->', "html_comment_injection"), ...]
同时检测 不可见 Unicode 字符 (零宽空格、方向覆盖字符等)。一旦发现威胁,文件内容会被替换为 [BLOCKED: ...] 而非直接注入。
4.4.3 工具使用强制指南
针对特定模型(GPT、Codex、Gemini 等),Hermes 会注入强制的工具使用指南:
“You MUST use your tools to take action — do not describe what you would do… Never end your turn with a promise of future action — execute it now.”
这解决了常见的大模型”光说不练”问题——模型经常在回复中说”我将运行测试”,但实际上不发起工具调用。
4.5 终端工具:tools/terminal_tool.py
这是 Hermes 最复杂的单个工具,约 2,600 行代码。
4.5.1 六种执行后端(策略模式)
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
通过统一的工厂接口隐藏实现差异,Agent 无需关心命令实际在哪执行。
4.5.2 环境生命周期管理
_active_environments: Dict[str, Environment] = {}# 特性:# - 按 task_id 隔离环境# - 空闲超时自动清理线程# - atexit 注册确保进程退出时清理
4.5.3 后台进程支持
# Agent 可以启动后台进程并继续对话spawn_background_process( command="long_running_build.sh", notify_on_complete=True, # 完成后通知 watch_patterns=["ERROR", "FAIL"] # 监控特定输出模式)
4.5.4 安全多层防御
-
Tirith 安全分析 :
tools/tirith_security.py— 高级安全策略引擎 -
危险命令审批 :
tools/approval.py— 检测rm -rf /等危险操作 -
Sudo 处理 :自动转换
sudo为sudo -S,交互式提示密码 -
退出码解释 :为非零退出码添加语义注释(如
grep返回 1 表示”无匹配”)
4.6 浏览器工具:tools/browser_tool.py
约 2,600 行,支持 CDP(Chrome DevTools Protocol)自动化。
4.6.1 浏览器后端
-
CamoFox :隐身浏览器,绕过 bot 检测
-
标准 Chrome :本地 Chrome 实例
-
Playwright :备用方案
4.6.2 浏览器生命周期管理
tools/browser_supervisor.py 负责浏览器的启动、健康检查、崩溃恢复和优雅关闭。
4.7 网关系统:gateway/
让 Hermes 从一个 CLI 工具变为 持久在线的聊天机器人 。
4.7.1 架构设计
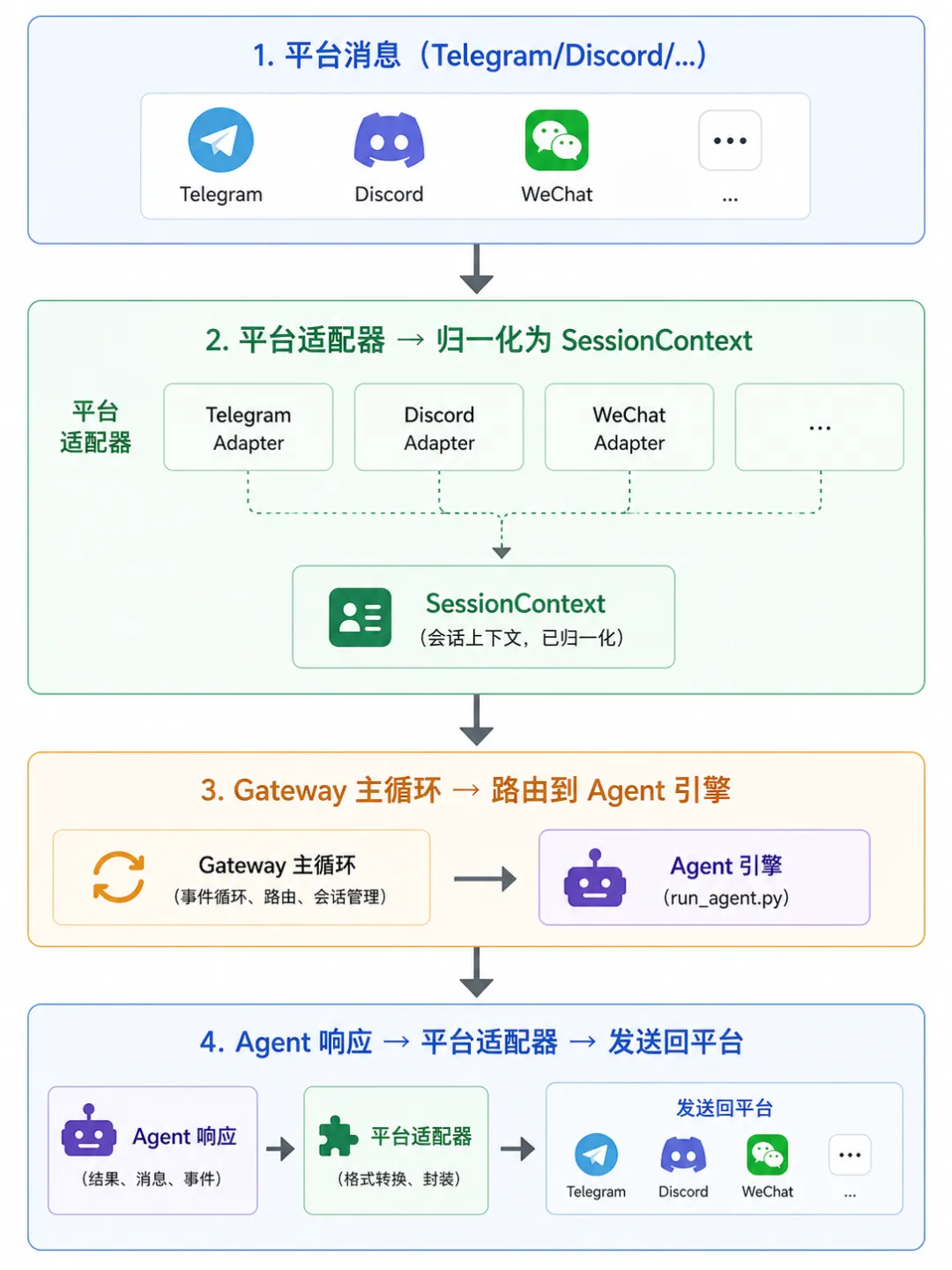
4.7.2 会话管理
gateway/session.py 实现:
-
SessionContext:每个对话的独立状态 -
SessionStore:持久化存储 -
SessionResetPolicy:基于时间/消息数的自动重置策略
关键设计: 为每个对话注入平台元数据到系统提示词 (如”这是 Telegram 群组,用户是管理员”),让 Agent 能感知平台上下文。
五、设计哲学与工程实践
5.1 防御性编程无处不在
Hermes 的代码充满了”fail open”的防御性设计:
# 插件钩子失败不阻断主流程try: from hermes_cli.plugins import invoke_hook invoke_hook("post_tool_call", ...)except Exception: pass # 插件观察性钩子失败不应阻断执行# Schema 净化失败回退到原始 schematry: filtered_tools = sanitize_tool_schemas(filtered_tools)except Exception as e: logger.warning("Schema sanitization skipped: %s", e)
5.2 精确的错误分类与重试
agent/error_classifier.py 将 API 错误分类为可重试/不可重试:
def classify_error(error) -> ErrorClassification: # 429 → 指数退避重试 # 401/403 → 立即失败(认证问题) # 500 → 有限次数重试 # Context Length Exceeded → 触发压缩
5.3 成本意识设计
-
上下文压缩使用 便宜的辅助模型 (非主模型)
-
Token 预算动态分配(summary、head、tail 各有预算上限)
-
精确的 usage 追踪与实时成本估算
5.4 多接口一致性
同一套核心能力通过不同接口暴露:
-
CLI :交互式 TUI,适合开发工作
-
Gateway :持久化消息机器人,适合运营场景
-
MCP Server :工具能力输出,供外部客户端消费
六、安全架构
Hermes 的安全不是单一功能,而是 分层防御体系 :

七、总结:Hermes 的架构智慧
|
|
|
|---|---|
| 工具自注册 |
|
| 工具集抽象 |
|
| 同步核心 + 异步 桥接 |
|
| SQLite WAL + FTS5 |
|
| 智能上下文压缩 |
|
| 分层状态管理 |
|
| 多接口共享核心 |
|
| 防御性编程 |
|
Hermes Agent 的源码展现了一个 成熟的生产级 Agent 框架 应有的样子:它不是 demo 级别的原型,而是在扩展性、稳定性、安全性、成本效率上都有深思熟虑的工程实践。对于希望构建严肃 AI Agent 应用的开发者来说,Hermes 的代码是一本活的教科书。
本文基于 hermes-agent v0.11.0源码分析撰写。