 夜雨聆风
夜雨聆风





AI/ML GPU 丛集中的光纤 shuffling技术
01
引言
人工智能与机器学习工作负载的快速增长,对资料中心基础设施提出了新的要求。现代 AI/ML GPU 丛集需要极高的互连频宽、可扩展性和布线密度。当这些系统扩展到数千个平行运作的 GPU 时,光互连基础设施必须支援日益复杂的拓扑结构,同时将实体布线复杂度降至最低。光纤fiber shuffling技术已成为管理这些挑战的关键工具,在维持高效能与讯号完整性的同时,提供简化网络架构的解决方案[1]。
02
光纤混洗技术原理
光纤混洗,也称为光纤网格化(fiber meshing),是在高密度网络环境中组织光纤连接的基本方法。混洗的核心概念是系统性地重组和重新路由光纤,从给定的实体光纤资源中创建更多的逻辑连接。混洗不需要在每个网络界面卡和每个交换机埠之间建立专用的点对点连接,而是利用光互连元件将资料讯号重新分配到多个输出路径。这种架构方法在脊叶(spine-and-leaf)网络拓扑中特别有价值,因为在没有智慧光纤管理策略的情况下,互连的复杂性会迅速变得难以控制。
混洗背后的基本原理是将光纤连接组织成离散通道,可以有效地在输入埠和输出埠之间映射。透过被动光学元件路由讯号,网络架构师可以扁平化传统的阶层式网络结构,在分散式运算资源之间实现更直接的通讯路径。这种扁平化效果减少了资料传输所需的网络跳数,在改善延迟特性的同时简化了实体布线基础设施。
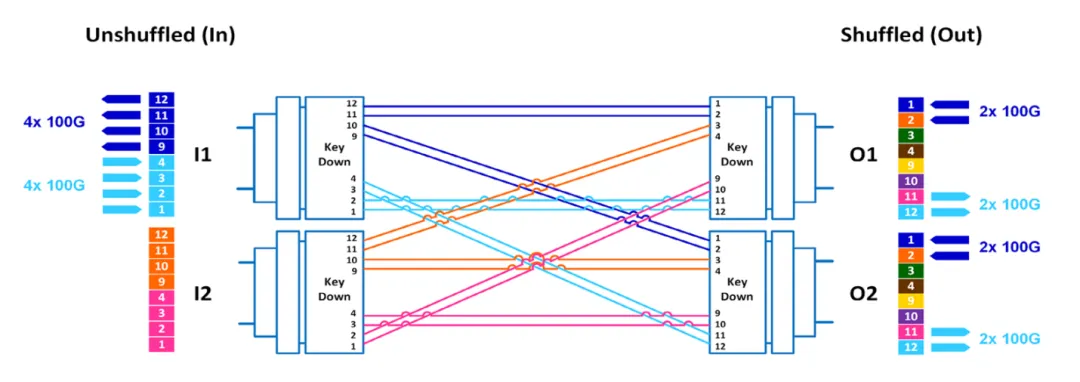
图1:2×2 shuffling配置显示如何将四条 100G 资料通道以 2 通道为单位、200G 的速率从 400G 收发器重新分配,将一个 MPO-8/12 连接器的两对光纤分散到两个输出连接器。
03
常见混洗配置方式
最广泛部署的shuffling配置是 2×2 混洗方法,在频宽优化和实施简易性之间提供了良好平衡。在此架构中,来自单一 MPO-8 或 MPO-12 连接器的两对光纤被重新分配到两个独立的输出连接器。此配置使具有 100G 通道的高速 400G 收发器能够同时建立到多个交换机的连接,每个输出承载 200G 的总频宽。与 4×4 配置相比,2×2 shuffling提供双倍的单连接频宽,对于需要优先考虑单个交换机埠最大吞吐量的应用特别有吸引力。简单明了的光纤路由模式将安装错误的可能性降至最低,同时保持高效的布线管理特性。
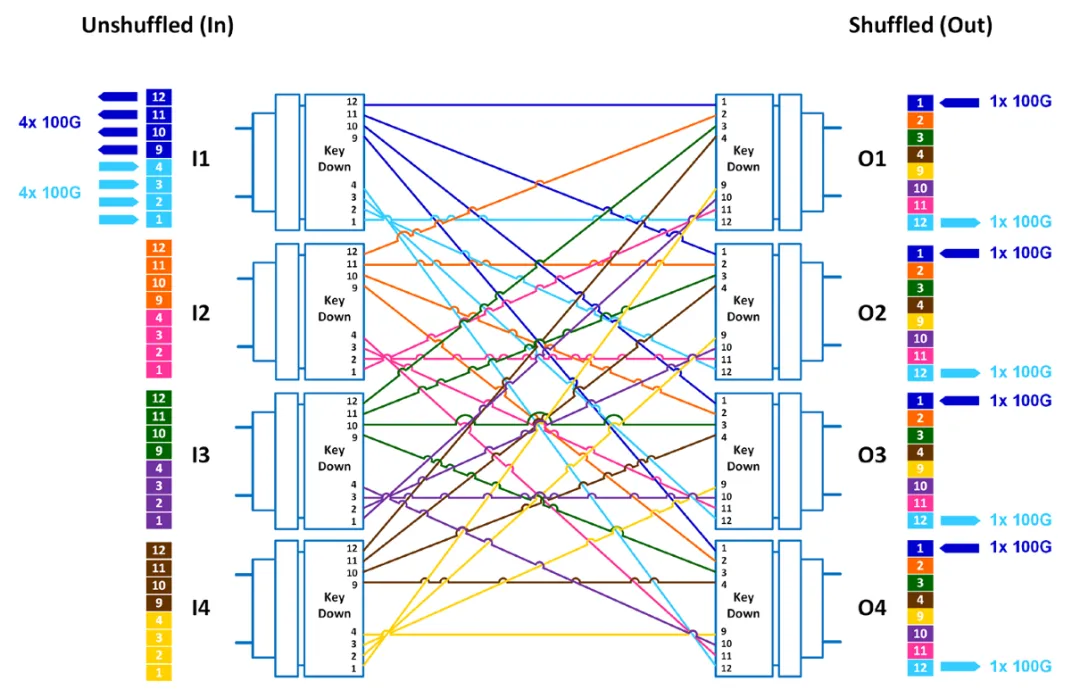
图2:4×4 混洗配置从 400G 收发器分配四条 100G 资料通道,将一个 MPO-8/12 连接器的光纤对分散到四个不同的输出连接器,以实现最大的埠分配。
4×4 混洗配置扩展了分配概念,将来自单一输入连接器的光纤对分散到四个独立的输出连接器。此方法使 400G 收发器能够同时建立到四个不同交换机埠的连接,每个连接承载 100G 频宽。虽然与 2×2 shuffling相比,单个连接频宽有所降低,但 4×4 方法最大化了网络连接选项,在需要将流量负载分散到多个网络路径时特别有价值。此配置在中大型资料中心中得到广泛应用,其中连接多样性和容错能力是首要考虑因素。
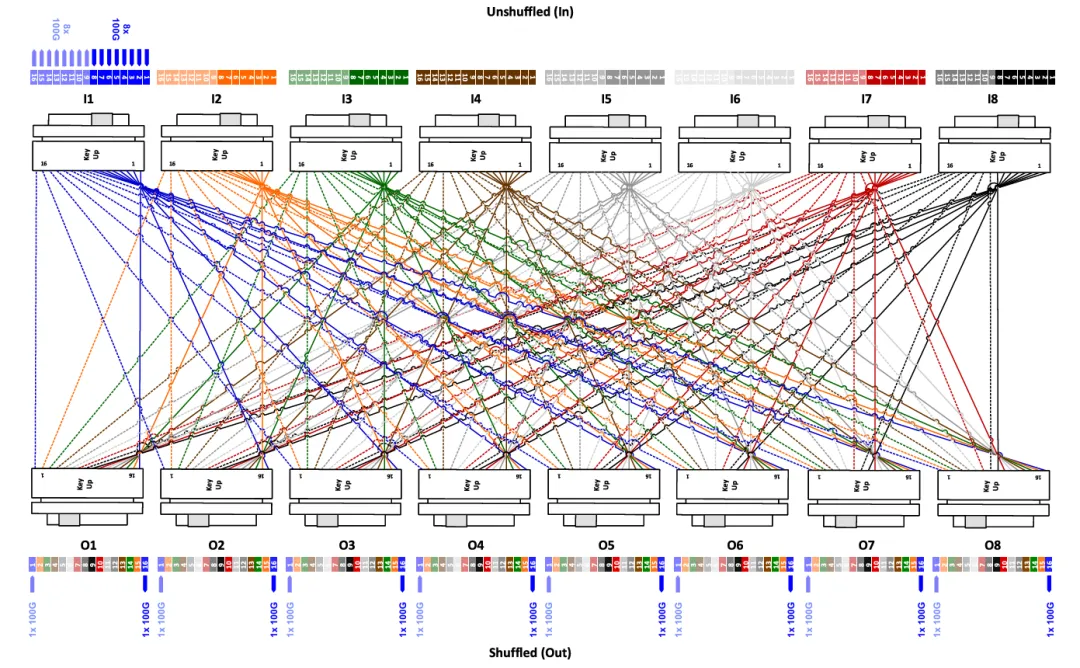
图3:8×8 shuffling配置显示从 800G 收发器分配八条 100G 资料通道,将单一 MPO-16 连接器的光纤对分散到八个不同的 MPO-16 输出连接器。
对于超高频宽应用,8×8 混洗配置提供最大程度的分配。此架构将来自单一 MPO-16 连接器的光纤对路由到八个独立的 MPO-16 输出连接器,使 800G 收发器能够建立跨越八个不同交换机埠的连接。每个输出连接承载 100G 频宽,为大规模交换 fabric 的流量分配提供卓越的灵活性。8×8 配置代表当前最高密度 AI/ML 丛集的技术水平,其中数百个 GPU 节点必须维持与分散式储存和运算资源的低延迟、高频宽连接。除了这些标准配置外,还可以设计客制化shuffling模式来满足特定的网络拓扑要求和效能目标。
04
实施方法: shuffle box与多光纤Shuffling Assembly
网络架构师可以透过两种主要硬件方法实现shuffling功能:被动shuffle box和多光纤shuffling assembly。shuffle box是封闭式模块化系统,设计用于在受控外壳环境中管理复杂的光纤互连。这些解决方案在需要集中式光纤管理的高密度部署中表现出色。Shuffle box提供广泛的客制化选项,包括 1 到 6 个机架单元(rack unit)的外壳尺寸,根据要求还可提供特殊尺寸。模块化架构支援可滑动的被动模块和固定外壳,根据安装要求可配置仅前端存取或前后双向存取模式。

图4:Shuffle box硬件展示外部外壳和内部被动模块,提供集中式光纤管理和路由能力。
多光纤shuffling assembly 代表基于预配置布线系统的替代实施方案,直接将混洗功能整合到布线系统中。这些 assembly 在网络界面之间的光纤路由方面提供卓越的灵活性,混洗映射永久编码在布线结构本身中。透过在工厂预先组织光纤连接,多光纤 assembly 与现场组装解决方案相比,大幅缩短安装时间并降低复杂性。两种方法都支援在单模和多模光纤基础设施中部署,与结构化布线系统和点对点布线架构兼容。

图5:多光纤shuffling assembly 展示两种配置 – MMC-16 至 MPO-8/12 APC 和 MPO-8/12 APC 至 MPO-8/12 APC 连接器类型,展示实现混洗功能的预配置布线方法。
05
效能特性与权衡
Shuffle box和多光纤 assembly 都提供相当的光学效能,在单模和多模变体中,对接连接的插入损耗规格最大值为 0.35 dB。单模实施提供最小 65 dB 的回波损耗效能,而多模配置则提供最小 45 dB 的回波损耗。这些光学参数确保混洗元件维持高速光链路无误传输所必需的讯号完整性。两种方法之间的主要效能差异在于连接器数量:与多光纤 assembly 相比,混洗盒引入额外一对连接器,导致通道插入损耗略高。必须根据模块化混洗盒架构为成长中的网络提供的灵活性和可扩展性优势来评估此权衡。
从部署角度来看,多光纤shuffling assembly 在安装后提供优异的灵活性,因为预配置结构限制了对变化网络需求的适应能力。相比之下,混洗盒提供出色的可扩展性特性,使网络营运商能够在不大规模重新布建实体基础设施的情况下新增或修改连接。对于初始部署,安装效率有利于多光纤 assembly,因为预组织的光纤结构减少了连接时间并将跳接错误的可能性降至最低。但是,两种方法都需要仔细标记和纪录,以防止在移动、新增和变更期间发生误接,并且在复杂网络环境中诊断连接问题时都可能面临故障排除挑战。
06
在现代 AI/ML 基础设施中的应用
Shuffling技术在 AI/ML GPU 丛集中的应用解决了现代高效能运算基础设施最具挑战性的方面之一:在数百或数千个 GPU 加速器之间建立高效的全对全连接,同时保持可管理的布线复杂度。在典型的大规模 AI 训练丛集中,每个 GPU 节点都需要与多个网络交换机建立高频宽连接,以支援需要在整个 GPU 集合中频繁同步梯度更新的分散式训练算法。如果没有shuffling,建立这些连接将需要大量的个别光纤布线,创建出如此复杂的布线系统,以至于安装、维护和故障排除几乎变得不可能。
透过在网络阶层的策略性位置实施shuffling,架构师可以在维持所需连接矩阵的同时,大幅减少实体布线数量。常见的部署模式是利用Shuffle box或多光纤 assembly 将 GPU 服务器机架与脊交换机基础设施互连,使每个 GPU 节点能够使用最少数量的光纤连接将流量分配到多个网络路径。此方法在 NVIDIA NVL72 机架配置和类似的高密度 GPU 部署中特别有效,其中机架空间和布线路由通道的实体限制对实际可容纳的个别布线数量造成严格限制。混洗基础设施使这些系统能够扩展到数千个 GPU,同时保持布线系统的组织性、可维护性,并在基础设施的多年运作生命周期内保持可维护状态。
07
连接器类型与光学规格
Shuffle box和多光纤shuffling assembly 支援多种连接器类型配置。最常见的选项包括 8 光纤 MPO APC 至 8 光纤 MPO APC,可提供单模和多模光纤版本;8 光纤 MPO PC 至 8 光纤 MPO PC,仅提供多模光纤版本;16 光纤 MPO APC 至 16 光纤 MPO APC,可提供单模和多模光纤版本。对于需要更高密度互连的应用,还提供 MMC-16 至 8 光纤 MPO APC 和 MMC-24 至 8 光纤 MPO APC 配置,均为单模光纤版本。根据特定项目需求,还可提供其他连接器类型。
单模连接器的插入损耗最大值为 0.35 dB(对接状态),回波损耗最小值为 65 dB(对接状态)。多模连接器同样具有最大 0.35 dB 的插入损耗(对接状态),回波损耗最小值为 45 dB(对接状态)。这些光学参数确保在整个讯号路径上维持足够的讯号质量,即使在经过多个连接点后也能保持可靠的资料传输。对于需要超低损耗的长距离或高速应用,单模配置提供更优异的回波损耗效能,有助于减少讯号反射对系统效能的影响。
08
客制化选项与配置灵活性
Shuffle box提供广泛的客制化可能性以满足特定部署需求。外壳尺寸可从 1 到 6 个机架单元选择,并可根据要求提供特殊尺寸。每个机架单元的密度可根据连接器类型和所需配置进行客制化。存取方式可以配置为仅前端存取,或前后双向存取,以适应不同的机架安装环境。在模块化设计方面,可提供具有可滑动功能的被动模块或固定外壳。非模块化选项则提供带埠的单一固定外壳。
多光纤shuffling assembly 的客制化选项包括布线长度调整、直线或交错分支配置,以及特殊标签和连接器颜色编码。这些客制化功能使网络设计师能够根据特定的机架布局、布线路径和标识要求来优化 assembly 配置。适当的标签和颜色编码在复杂的高密度环境中特别重要,可以大幅降低安装错误的风险并简化未来的维护作业。
09
适用于不同规模资料中心的混洗技术选择
选择适当的shuffling技术取决于资料中心的规模和特定设计需求。对于小型和中型资料中心,通常适合使用 EDGE 4×4 网格模块或 4×4 shuffling assembly。这些解决方案提供充足的连接分配能力,同时保持相对简单的实施复杂度。安装和配置过程相对直接,使得这些选项对于资源有限的环境特别有吸引力。
对于中大型资料中心,选项包括Shuffle box (2×2、4×4、8×8)、EDGE 4×4 网格模块或shuffling assembly(2×2、4×4、8×8),根据特定的设计需求和基础设施要求进行选择。在这些环境中,决策过程必须考虑多个因素,包括预期的网络成长、所需的连接密度、可用的机架空间、维护存取要求以及长期可扩展性目标。Shuffle box通常为需要频繁重新配置或预期大幅成长的环境提供最大的灵活性,而多光纤 assembly 则在拓扑相对稳定的部署中提供更简化的安装体验。
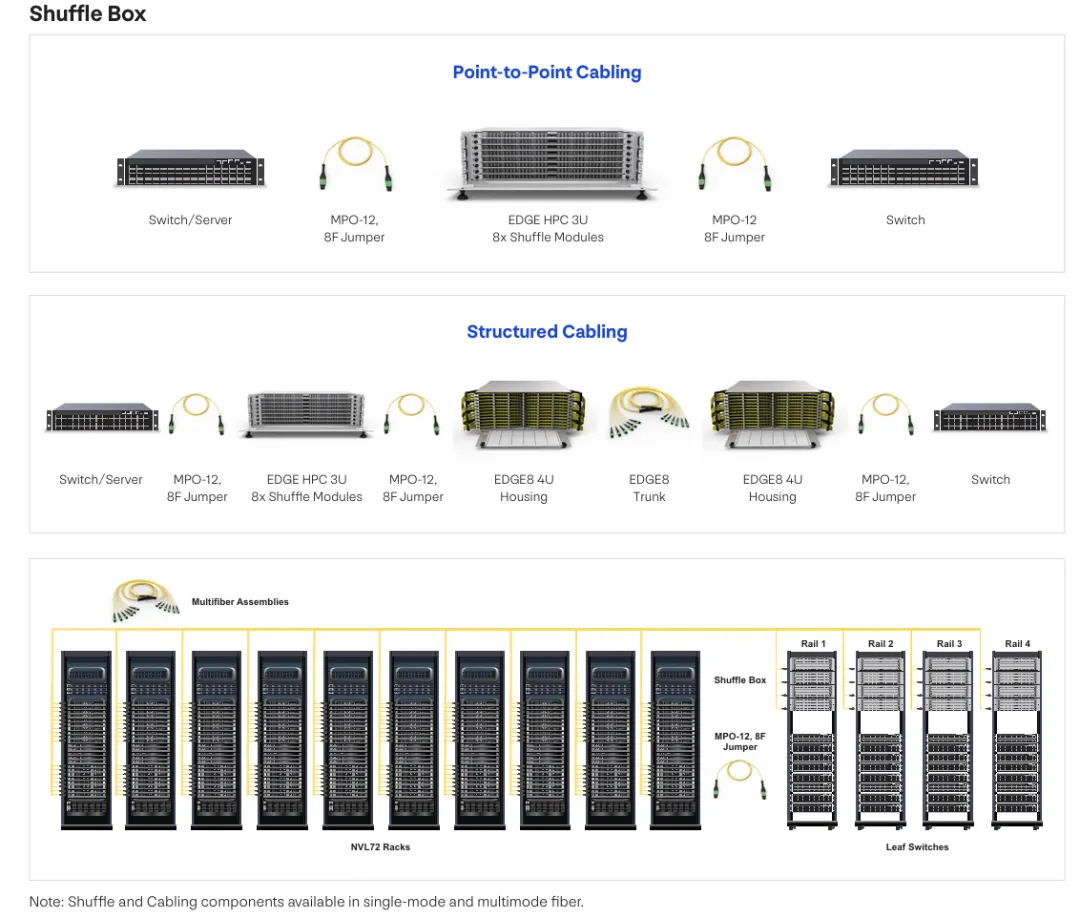
图6:展示Shuffle box在点对点布线和结构化布线场景中的部署,以及多光纤 assembly 在 NVL72 机架与叶交换机互连中的应用。
10
部署架构:点对点与结构化布线
Shuffling技术可以在点对点布线和结构化布线架构中实施。在点对点布线配置中, Shuffle box直接安装在服务器与交换机之间,使用 MPO-12 8 光纤跳接线建立连接。这种方法提供最直接的讯号路径,将连接点数量降至最低,从而优化插入损耗效能。点对点配置特别适合需要最低延迟和最高讯号完整性的高效能运算环境。
结构化布线实施提供更大的灵活性和可管理性。在此架构中, Shuffle box连接到 EDGE8 4U 外壳系统,该系统作为集中式互连点。从Shuffle box到 EDGE8 外壳使用 MPO-12 8 光纤跳接线,而 EDGE8 trunk 布线则提供到最终交换机目的地的连接。这种分层方法简化了大规模部署中的布线管理,使网络营运商能够在集中位置进行更改,而无需接触个别服务器连接。
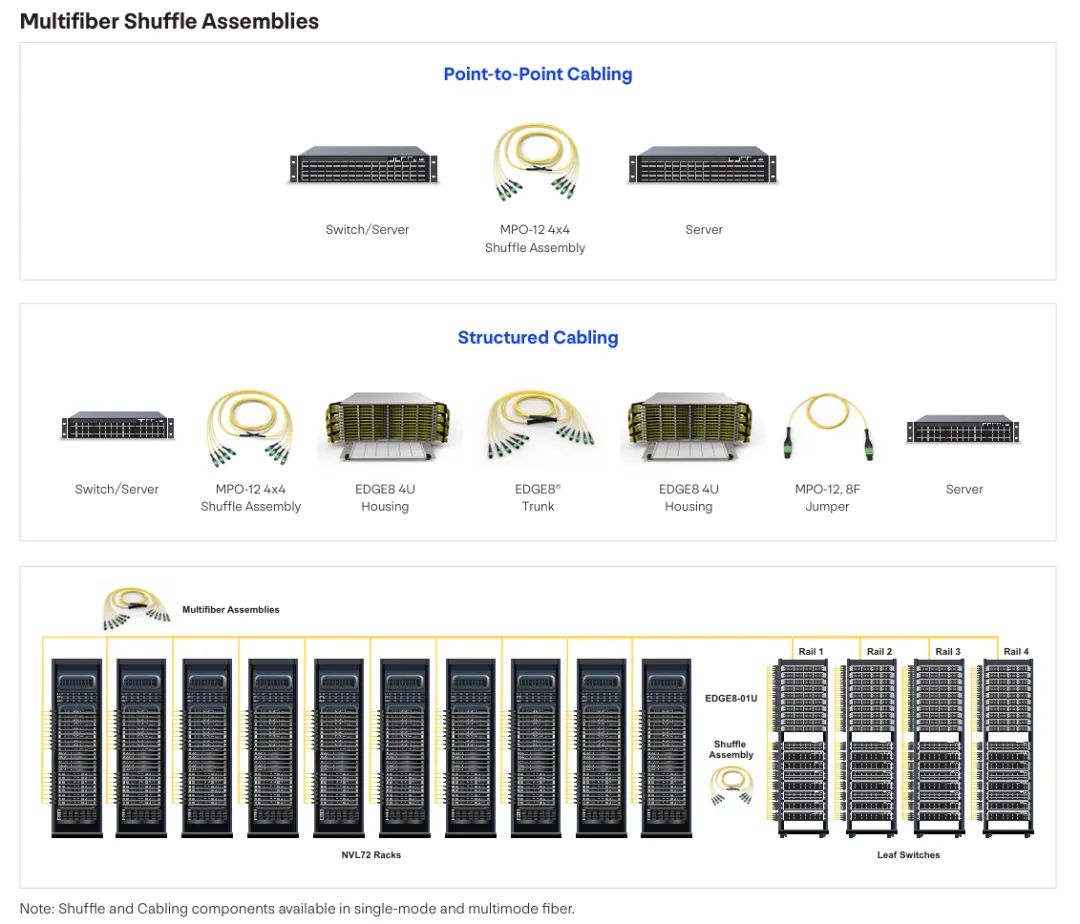
图7:多光纤 assembly 应用范例:展示在点对点布线和结构化布线场景中使用 MPO-12 4×4 shuffling assembly,以及在 NVL72 机架环境中的大规模部署。
多光纤shuffling assembly 同样支援点对点和结构化布线部署模式。在点对点配置中,MPO-12 4×4 shuffling assembly 直接连接服务器与交换机,提供简化的安装体验,无需额外的互连硬件。对于结构化布线实施, shuffling assembly 与 EDGE8 4U 外壳和 EDGE8 trunk 系统整合,在保持集中式管理优势的同时提供shuffling功能。选择点对点或结构化布线方法取决于资料中心的具体要求,包括规模、成长预期、维护流程和现有基础设施投资。
11
Shuffling技术在扩展性方面的影响
Shuffling技术对资料中心可扩展性的影响体现在简化新交换机和服务器的整合过程,允许在不增加布线复杂性的情况下轻松扩展。透过使用光互连元件,资料中心可以更容易地向外扩展。这是透过将光纤连接组织成离散通道来实现,减少了对多个单独连接的需求,并允许使用单一讯号从脊或叶交换机向中央光互连元件提供多个通道。此方法支援扁平化网络架构,促进可扩展性并确保基础设施的高效使用,同时维持高效能和讯号完整性。
在实际部署中,这种可扩展性优势转化为降低扩展成本和缩短实施时间。当向现有丛集新增新的 GPU 服务器机架时,混洗基础设施允许这些新资源利用现有的光互连点,而无需在整个资料中心重新布线。这种增量扩展能力对于需要随着业务需求演变而逐步增加运算容量的组织特别有价值。Shuffling架构还支援异构扩展,其中可以将不同世代或类型的 GPU 硬件整合到同一网络 fabric 中,只要遵守基本的连接器和频宽兼容性要求即可。
Shuffling元件在高密度 AI/ML 环境中的应用展示了光纤基础设施设计如何直接影响大规模运算系统的可行性。透过解决布线复杂性这一基本挑战, Shuffling技术使资料中心营运商能够部署和维护支援现代机器学习工作负载所需的大规模 GPU 丛集,同时保持可管理的营运成本和合理的实施时间表。
参考文献
[1] Corning Optical Communications, “Shuffling Solutions for AI/ML-GPU Clusters and Modern Data Centers: Enhancing Scalability and Reducing Complexity,” LAN-3440-AEN, March 2026.
END
NOTICE
点击左下角“阅读原文”马上申请
欢迎转载
转载请注明出处,请勿修改内容和删除作者信息!
关注我们
 |
 |
 |
关于我们:
深圳逍遥科技有限公司(Latitude Design Automation Inc.)是一家专注于半导体芯片设计自动化(EDA)的高科技软件公司。我们自主开发特色工艺芯片设计和仿真软件,提供成熟的设计解决方案如PIC Studio、MEMS Studio和Meta Studio,分别针对光电芯片、微机电系统、超透镜的设计与仿真。我们提供特色工艺的半导体芯片集成电路版图、IP和PDK工程服务,广泛服务于光通讯、光计算、光量子通信和微纳光子器件领域的头部客户。逍遥科技与国内外晶圆代工厂及硅光/MEMS中试线合作,推动特色工艺半导体产业链发展,致力于为客户提供前沿技术与服务。
http://www.latitudeda.com/
(点击上方名片关注我们,发现更多精彩内容)