 夜雨聆风
夜雨聆风





OpenClaw 技术全景:架构思路、运行机制与实现原理
模型本身很强,真正难的是怎么把它接到现实世界里。
你总不能要求一个 AI 助手只活在浏览器聊天框里。如果它真的要帮你做事,它就得能:
-
接消息 -
管会话 -
跑工具 -
调子代理 -
处理多平台接入 -
维护状态和权限
而 OpenClaw 这个项目最有意思的地方就在于,它不是单纯再造一个聊天 UI,也不是只做一个模型 SDK。
它做的是一层更底层的东西:
把 AI agent 变成一个可以跨平台、跨渠道、持续运行的个人网关。
这篇文章不讲热闹,只讲它背后的技术思路。

一、先用一句话讲清楚:OpenClaw 到底是什么?
根据 OpenClaw 官方文档,截至 2026 年 4 月 23 日,OpenClaw 的定位是:
一个 self-hosted gateway,用来把 Discord、Slack、Telegram、WhatsApp、iMessage、WebChat 等不同聊天入口接到 AI agents 上。
官方首页的表述非常直接:
-
Any OS -
Any Platform -
Send a message, get an agent response from your pocket
这说明它的核心目标不是“做一个模型”,而是“做一个运行面”。
换句话说,OpenClaw 想解决的是:
同一个 agent,如何在多个现实入口里持续工作。

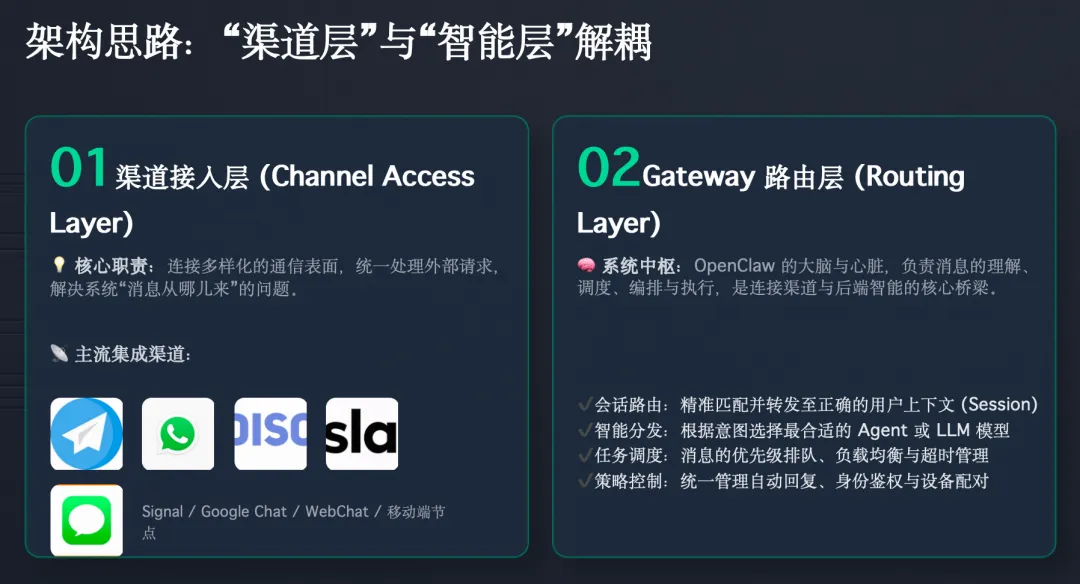
二、OpenClaw 的架构思路,本质上是“渠道层”和“智能层”解耦
如果把它拆开看,OpenClaw 的核心设计很清楚:
第一层:渠道接入层
这一层负责连接不同通信表面,比如:
-
Telegram -
WhatsApp -
Discord -
Slack -
Signal -
iMessage -
Google Chat -
WebChat -
移动端节点
这部分解决的是“消息从哪儿来”的问题。
第二层:Gateway 路由层
这是 OpenClaw 的核心。
所有来自不同渠道的消息,都会先进入 Gateway,再由 Gateway 决定:
-
路由到哪个 session -
用哪个 agent -
是否要排队 -
是否允许自动回复 -
是否需要配对 / 权限校验
这层决定的是“消息怎么被系统理解和编排”。
第三层:Agent Runtime
官方文档明确写到,OpenClaw 的嵌入式 agent runtime 建立在 Pi agent core 之上,而会话管理、发现机制、工具接线、渠道投递这些属于 OpenClaw 自己的边界层。
也就是说,它不是把所有东西都揉成一团,而是做了明确分层:
-
agent 核心负责思考与调用工具 -
OpenClaw 负责环境接入与运行时编排
这个边界切得非常工程化。
因为真正可扩展的系统,往往都不是“一个超大脑”,而是“核心能力 + 环境壳层”的组合。

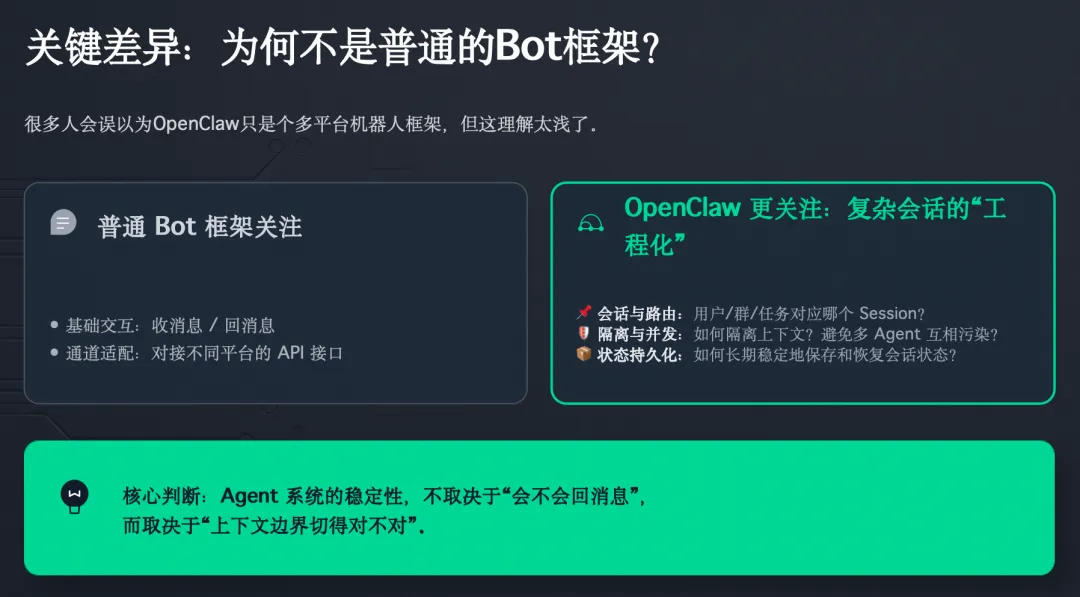
三、它为什么不是普通 Bot 框架?关键在“会话”而不是“消息”
很多人第一次看 OpenClaw,会误以为它只是个多平台机器人框架。
这理解太浅了。
Bot 框架通常关注的是:
-
收消息 -
回消息 -
对接平台 API
而 OpenClaw 明显更关注:
-
一个用户 / 一个群 / 一个任务,对应哪个 session -
session 如何隔离 -
session 的状态如何长期保存 -
多个 agent run 如何避免互相污染
官方 session 文档里写得很明确:
-
私聊默认共享 session -
群聊按 group 隔离 -
room / channel 按 room 隔离 -
cron job 每次新 session -
webhook 按 hook 隔离
这背后体现的是一种很关键的产品判断:
Agent 系统真正稳定与否,不取决于“会不会回消息”,而取决于“上下文边界切得对不对”。
为什么这很重要?
因为一旦你把不同来源的消息错误混在同一个上下文里,agent 的行为很快就会不稳定,严重时甚至会造成隐私和权限问题。
所以 OpenClaw 在 session routing 上花这么多力气,不是锦上添花,而是底层稳定性的前提。

四、OpenClaw 的运行机制,核心是“事件进入后,先排队,再执行”
这是它非常值得讲的一点。
官方 Queue 文档在 2026 年 1 月 16 日更新后,把这部分机制写得非常清楚。
OpenClaw 对 inbound auto-reply runs 采用的是一个lane-aware FIFO queue。翻译一下,就是:
-
来的消息先进队列 -
队列按 lane 区分 -
每个 lane 有并发上限 -
同一个 session 会被序列化处理
为什么要这么做?
因为 agent run 不是普通 HTTP 请求。
它可能会:
-
调大模型 -
写 session 文件 -
持续 streaming -
调工具 -
拉子代理
如果同一个 session 同时来两条消息,让两次 run 直接并发,很容易发生冲突:
-
会话状态互相覆盖 -
CLI stdin 抢占 -
日志串线 -
上游模型限流
所以 OpenClaw 的做法很务实:
在 session 级别上,默认先保证“不要撞车”;在全局级别上,再按配置放开并发。
这是一种非常典型的工程折中。
它没有为了“看起来更实时”而无脑并发,而是优先保证 agent 运行的一致性。

五、它如何处理“正在回复时用户又发新消息”这种真实问题?
这正是很多 Agent 产品最难做细的地方。
OpenClaw 在 queue 模式里提供了多种策略:
-
steer -
followup -
collect -
steer-backlog -
interrupt
这套设计背后非常有意思。
它承认了一个现实:
用户不会等 agent 完美结束后才发下一句话。
所以系统必须有机制决定:
-
是立刻把新消息注入当前 run -
还是排到下一轮 -
还是合并多条消息后统一处理 -
还是中断旧 run,只保留最新输入
这意味着 OpenClaw 不是把 agent 当成“同步函数”,而是把它当成一个持续运行、可被打断、可被引导的交互进程。
这也是它比很多简单 Bot 系统更像“操作系统层中间件”的原因。

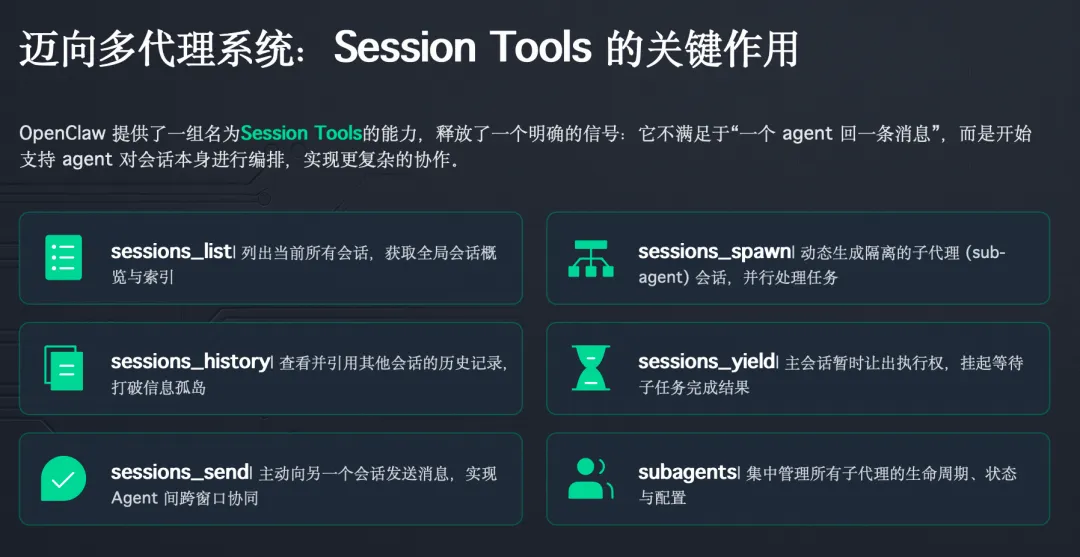
六、Session Tools 是它迈向多代理系统的关键
OpenClaw 还有一组很值得注意的能力,叫 Session Tools。
官方给出的工具包括:
-
sessions_list -
sessions_history -
sessions_send -
sessions_spawn -
sessions_yield -
subagents -
session_status
这些工具释放了一个非常明确的信号:
OpenClaw 不满足于“一个 agent 回一条消息”,而是开始支持 agent 对 session 本身做编排。
比如:
-
查别的会话历史 -
往另一个 session 发消息 -
生成隔离的 sub-agent session -
主会话先让出执行权,等待子任务结果
这时系统就从“聊天机器人”进化成了“会话操作平台”。
你可以把它理解成:
普通 Bot 只能回答问题。而 OpenClaw 这类架构,已经开始让 agent 具备了跨会话协调能力。
七、Skills 机制说明它不是只想做接入层
如果 OpenClaw 只是个消息网关,那它的技术价值会有限。
但官方 Agent Runtime 文档专门写了 Skills 的加载优先级:
-
<workspace>/skills -
<workspace>/.agents/skills -
~/.agents/skills -
~/.openclaw/skills -
bundled skills -
extraDirs
这意味着它并不满足于“把消息送进模型”。
它还在做另外一件更重要的事:
把能力模块化,让 agent 在不同工作区和不同层级里动态加载技能。
这件事的意义很大。
因为真正可维护的 agent 系统,不能所有能力都塞进一个超长 prompt。它必须像插件系统一样,按需发现、按需加载、分层覆盖。
从这个角度看,OpenClaw 的目标并不是某个单点功能,而是一个可以持续长出能力的运行平台。

八、它的安全思路也很现实:默认不信任外部消息
这是很多开源 Agent 项目最容易被忽略的一层。
OpenClaw 官方 README 明确强调:
它连接的是真实消息面,因此入站私信应被视为不可信输入。
默认策略里,Telegram / WhatsApp / Signal / iMessage / Discord / Slack 等渠道都支持 pairing 或 allowlist 这类控制机制。未知发信人先收到短配对码,批准后才真正放行。
这件事很关键。
因为一旦 agent 真开始接真实外部渠道,安全问题就不再是“prompt 会不会被注入”这么简单,而是:
-
谁能触发它 -
谁能拿到上下文 -
谁能共享 session -
谁能调用危险动作
OpenClaw 至少在系统设计层面承认了这个现实,而且给了默认保护。
这比很多“先跑起来再说”的玩具型 Agent 项目成熟得多。

九、OpenClaw 适合什么样的人?
如果你只是想本地玩玩单机 Agent,OpenClaw 不一定是最轻的方案。
但如果你有这些需求,它就会非常对路:
1. 你想把一个 agent 接到多个真实聊天入口
不是只在网页里聊,而是让它在 Telegram、Slack、WhatsApp、WebChat 等地方都能工作。
2. 你希望会话和渠道隔离是系统级能力
而不是每次自己手动处理上下文边界。
3. 你需要自托管和“自己的网关”
OpenClaw 的价值观很明确,就是自己掌控入口、运行环境和会话。
4. 你想搭一个可扩展的个人 AI 助手基础设施
不是 demo,而是长期可运行的 agent gateway。

十、最后
OpenClaw 最值得关注的,不是它支持多少平台,也不是它 UI 长什么样。
而是它把 Agent 从“单次调用的模型能力”推进成了:
一个有渠道接入、有会话路由、有执行队列、有技能系统、有安全边界的长期运行平台。
换句话说,它真正做的不是一个聊天机器人。
它做的是一层 Agent Runtime Gateway。
这层东西一旦成熟,未来很多“AI 助手”产品的竞争,拼的就不再只是模型本身,而是:
-
谁的渠道层更稳 -
谁的 session 边界更清晰 -
谁的运行队列更可靠 -
谁的技能系统更可扩展

从这个意义上说,OpenClaw 不是一个小众开源项目那么简单。
它更像是在提前回答一个问题:
当 Agent 真要进入现实世界时,它到底该跑在什么样的系统上?
如果你对 AI 知识、AI 落地工作方法感兴趣,欢迎关注。后续我会持续分享行业趋势、实战经验与可直接落地的方法,内容力求务实、易懂、可复用。
每天更新一点,帮你把复杂的 AI 世界看明白、跟上节奏、不掉队。