 夜雨聆风
夜雨聆风





从临时提示词到可复用AI工作流:Claude Code Skills技能实践
1. 引言
搭建一次可用的工作流并不难,难的是让工作流能够稳定复用。
每次通过提示词调用 ChatGPT 或 Claude 固然高效,但输出结果参差不齐、难以复现。依托 Python 全量开发或固化工作流虽能提升稳定性,却往往牺牲了大语言模型在探索性场景下的灵活优势。
Claude Code 技能恰好能够弥补这一短板。它既保留自然语言的灵活特性,又可通过SKILL.md文件与配套脚本建立标准化规范,保障工作流输出稳定统一。
该方案尤其适用于场景重复、细节微调的任务:依赖自然语言指令开展工作,且完全硬编码开发会徒增冗余复杂度。
2. 应用场景:虚拟用户调研
本次案例聚焦大模型人设访谈场景——借助大语言模型模拟真实用户对话,开展定性市场调研。
用户调研具备极高商业价值,但调研成本高昂。委托专业机构开展一次定性调研,费用动辄数万美元。
因此越来越多团队开始使用大语言模型替代真人调研。 常见操作如向大模型下达指令:「你扮演一名25岁、关注护肤的女性」,随后围绕新产品概念收集用户反馈。这种方式高效免费、随时可用。
但落地到实际项目中,该模式会暴露出诸多问题,也是纯临时提示词模式的核心短板。
3. 临时提示词模式的核心弊端
让大模型扮演指定人设并回答问题并不困难,真正的难题在于:如何在多个人设、多轮会话、多个项目中,保证整套调研流程可复用、可复现。

作者配图
在人设访谈工作流中,这类问题会快速凸显:共享对话上下文会让后续回答受前文内容干扰、输出内容逐渐同质化、调研人设样本无法复用至后续测试与追问环节。
由此可见,单纯优化提示词无法从根源解决问题。核心症结不在于话术表述,而在于工作流缺少结构化设计:缺少固定的人设定义标准、缺乏差异化设计、没有独立的访谈隔离环境。
4. 从零散提示词到可复用技能
关键突破不在于优化提示词文案,而是将脆弱的多步骤提示词流程,改造为可复用的 Claude Code 技能。
无需每次手动重复配置调研样本、生成人设、编写追问指令,现在仅需一条命令,即可一键启动完整工作流:
/persona generate 10 Gen Z skincare shoppers in the US
从使用者视角来看操作极简,但这条指令背后,技能会以标准化流程完成调研样本规划、人设生成、内容校验与结果整理,全程稳定可复现。
5. 指令背后的运行逻辑
单条指令触发的是一套完整工作流,而非单次简单提问。
在底层逻辑中,技能主要完成两项核心工作:标准化定义调研样本结构、可控化批量生成用户人设。所有虚拟访谈均在独立隔离环境中运行,生成结果可长期复用,支持二次测试与深度追问。
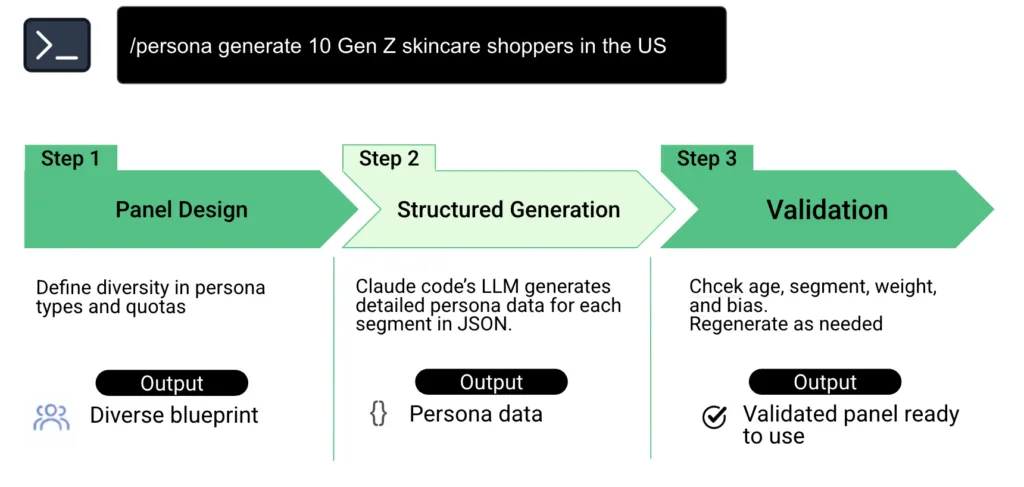
作者配图
5a. 将人设定义为结构化数据对象
核心优化之一:摒弃碎片化的对话式人设描述,改用结构化数据对象定义用户人设。这一改造大幅提升工作流稳定性与数据可分析性。
传统简陋的人设设定方式如下:
你是一名22岁、关注护肤的大学生。
你如何看待「屏障修护霜」这款产品概念?
此类人设描述模糊笼统,随着问题增多,角色人设容易逐渐跑偏。取而代之,我们通过 JSON 结构化文件定义完整人设:
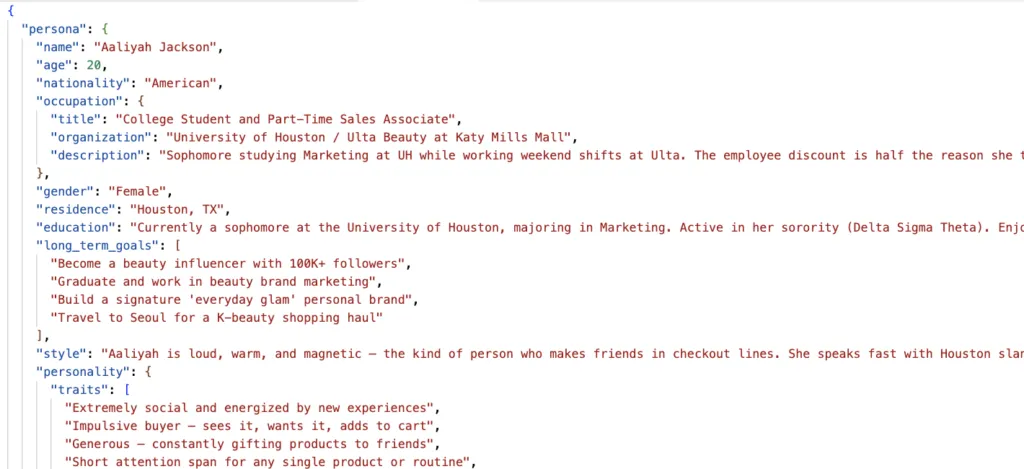
作者配图
结构化格式能够锁定用户核心属性,避免多轮问答中人设跑偏。同时所有人设以 JSON 文件独立存储,可直接复用至下一轮产品概念测试或深度调研。
5b. 前置规划样本多样性并完成合规校验
第二项核心优化:在大模型生成人设之前,提前规划并锁定调研样本的差异化配比。
若直接让大模型一次性批量生成10个人设,无法有效控制样本结构:年龄区间过度集中、用户观念趋同,最终所有人设仅有细微差异,调研失去参考价值。
因此我在 Claude Code 技能中增加前置设计:先规划整体用户观念分层,再基于分层规则生成对应人设,最后自动校验样本分布合理性。
以Z世代护肤人群调研为例,提前划分人群类型:护肤刚需爱好者、护肤理性质疑者、预算敏感型消费者、潮流跟风人群、问题肌肤刚需人群。
分层规则确定后,技能自动生成人设,并校验各类人群的数量分布是否均衡。
访谈环节还有一项关键设计:每个人设独立隔离运行。彻底避免回答互相干扰,保证不同用户样本的观点差异,提升调研真实性。
6. 为何选择 Claude Code 技能,而非纯提示词或 Python 库
本次方案设计参考了微软研究院推出的多智能体模拟 Python 库 TinyTroupe,其核心理念便是以对象化形式管理多智能体人设。我借鉴了这一设计思路,但在日常落地中发现,直接引入 Python 库会增加额外使用成本,因此将整套工作流重构为 Claude Code 技能。
相较于纯提示词与传统开发库,Claude Code 技能完美平衡灵活性与规范性,是该类场景的最优解。
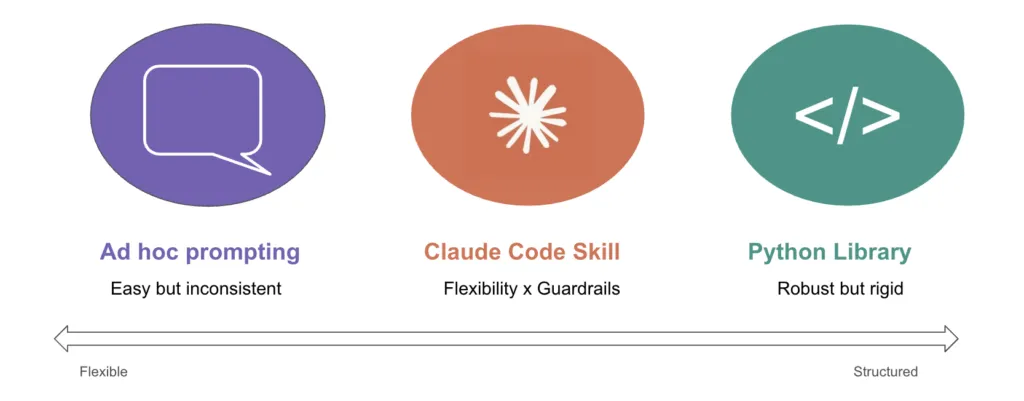
作者配图
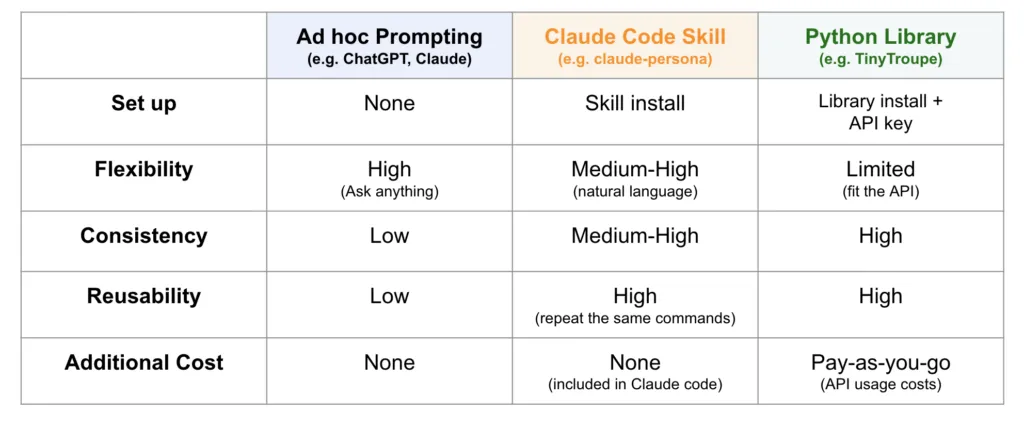
作者配图
综合对比来看,Claude Code 技能的核心优势主要体现在以下几点:
无额外计费成本。TinyTroupe 等调用大模型的 Python 库,需要单独配置 OpenAI、Claude 等平台的 API 密钥,持续产生调用费用。在方案探索测试阶段,持续的额外开销会严重影响使用体验。而 Claude Code 技能依托现有订阅服务运行,扩充人设样本数量不会产生额外费用。
自然语言式参数输入。使用 Python 库开发时,必须严格匹配函数入参格式,示例如下:
factory.generate_person(context="A hospital in São Paulo", prompt="Create a Brazilian doctor who loves pets")`
而通过 Claude Code 技能,仅需自然语言描述需求即可:
/persona generate 10 Gen Z skincare shoppers in the US
简洁高效,无需适配代码语法。
SKILL.md 提供标准化约束。人设结构化规则、样本多样性设计流程、完整工作流规范,全部统一写入配置文件。无需反复修改提示词,无论输入何种自定义需求,技能都会遵循固定流程执行,保障标准化输出。
实际落地效果如下:仅需一句自然语言指令,即可批量生成调研样本:
/persona generate 10 Gen Z skincare shoppers in the US
系统自动生成10位差异化人设,并以结构化 JSON 文件保存,同步完成人群分布、年龄区间的自动校验。随后执行指令/persona ask 选择护肤产品时,你最大的困扰是什么?,即可在独立环境中完成全人设访谈,完整汇总所有用户的痛点与核心需求。完整演示案例(含产品概念测试、用户原始语录)已上传至 GitHub 演示目录。
7. Claude Code 技能的适用边界
Claude Code 技能并非万能工具,存在明确适用边界。
完全固定化、强确定性的业务流程,直接使用原生代码开发更合适;需要严格审计、合规监管的业务逻辑,不适合依托自然语言指令实现;一次性探索类问题,直接在对话窗口提问即可,无需额外搭建技能。
Claude Code 技能并非只能依赖自然语言,还可内嵌 Python 脚本。在本次人设调研技能中,我通过 Python 代码完成样本多样性校验、调研结果汇总统计。
灵活结合大模型的软性判断能力与代码的刚性逻辑能力,这是单纯提示词模板无法实现的核心优势。
通用选用原则:当工作流需要标准化约束,但全量硬编码开发过于繁琐冗余时,Claude Code 技能就是最优中间方案。
8. 总结
重复性 AI 工作存在一个最优中间形态:摒弃临时提示词的不稳定性,规避传统代码库的过度固化。
Claude Code 技能恰好填补这一空白,保留自然语言的灵活优势,同时依托SKILL.md配置文件与配套脚本建立规范约束。
本文以大模型人设访谈为实践案例,拆解整套工作流的核心设计思路:人设对象结构化定义、前置规划样本多样性。整体设计理念借鉴了微软 TinyTroupe 相关研究成果。
完整的SKILL.md配置文件、Python 源码与详细演示案例,已开源至 GitHub(claude-persona)。
核心要点总结
————————————————————-
希望这篇文章能为您带来一些帮助。如果有任何疑问或建议,请在评论区留言,我们将尽力回答!
让我们一起探索并推动前沿技术发展!🚀💻
祝好运!😊✍️