 夜雨聆风
夜雨聆风





ClawGym:面向 OpenClaw 的智能体数据合成、训练与评测一体化框架
作者 | 白飞、宋华彤、孙爽、成岱璇
机构 | 中国人民大学
论文信息

论文链接:https://arxiv.org/abs/2604.26904
相关数据、代码资源将发布于 https://github.com/ClawGym
引言
Personal agent 正在从“回答问题”走向“完成任务”。在类似OpenClaw的环境中,agent 不只是生成文本,而是需要直接面对用户工作区:读取文件、运行脚本、整理表格、修改文档、生成报告,并留下可以被检查的最终产物。
这类任务的关键不再是 agent 是否“说完成了”,而是文件是否被正确创建或修改、表格计算是否准确、脚本是否能运行、输出格式是否满足要求,以及多个文件之间的约束是否一致。这往往会带来一个核心问题:如何系统性地构建能在工作区中可靠执行任务的 Claw Agent?
为此,我们提出 ClawGym,一个集大规模数据合成、模型训练与可靠评测于一体的系统框架,打通了 Claw Agent 从任务构建、能力学习到性能诊断的完整链路。具体而言,ClawGym 包含三个核心组成部分:
-
ClawGym-SynData:首个面向 Claw agents 的大规模合成数据集,包含 13.5K 个可执行任务,结合用户画像驱动的任务意图与技能驱动的可执行操作,规模化生成多样且可验证的训练数据。
-
ClawGym-Agents:基于 OpenClaw 黑盒执行收集高质量轨迹,并通过监督微调训练得到一系列能力更强的 Claw agents,同时探索了带有沙盒并行机制的轻量级强化学习流程。
-
ClawGym-Bench:包含 200 个任务、覆盖六类场景的可靠评测基准,通过难度感知筛选和人类-大模型协同审查保证质量,用于诊断不同规模 Claw agents 的任务执行能力差异。
ClawGym-SynData
ClawGym-SynData 是整个框架的数据基础,也是首个面向 Claw agents 的大规模合成数据集,包含 13.5K 个可执行任务。
其构建流程包括四个环节:任务生成、资源准备、验证设计和质量评估。
在任务生成阶段,ClawGym 采用两条互补路线:
-
persona-driven top-down synthesis :从用户画像、场景类别和原子操作出发,生成贴近真实需求的任务;
-
skill-grounded bottom-up synthesis :从 OpenClaw skills 出发,通过技能标注、过滤和组合,构造更接近实际可执行能力边界的任务。
前者提供用户意图和场景多样性,后者提供工具与操作 grounding,二者结合使任务既真实又可执行。
为了让任务真正落到环境中,ClawGym 还为每个任务自动生成轻量级 mock workspace,包括 Markdown、JSON、CSV、YAML、配置文件、日志和原始记录等。这些资源围绕任务要求构造,提供执行和验证所需的字段、数值、约束和参考内容,使任务能够被真实执行、稳定复现并自动评估。
在验证设计上,ClawGym 采用 code-based verification + rubric-based verification 的混合机制。前者检查文件、schema、数值计算、过滤规则和输入输出一致性,后者评估报告清晰度、摘要忠实性、表达专业性和内容完整性。这样的设计既强调工作区产物的客观正确性,也覆盖了对内容质量与用户偏好的要求。
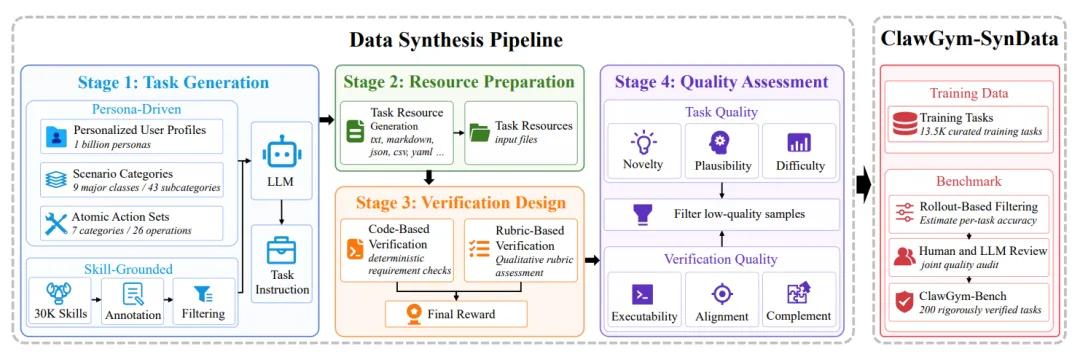
图1:ClawGym-SynData的合成pipeline
ClawGym-Agents
ClawGym-Agents 是框架中的模型训练部分。基于 ClawGym-SynData,我们通过 OpenClaw black-box rollout 收集真实交互轨迹,而不是重新实现一个简化 agent loop。
这样做是因为 OpenClaw 本身是高度封装的真实系统,内部上下文管理、工具调用和执行流程并不完全暴露。直接在 OpenClaw 中执行任务,可以更真实地保留 agent 在实际系统中的行为模式。
轨迹收集后,我们进行聚合、清洗和筛选:将分散的请求和响应恢复为完整多轮轨迹,去除 heartbeat、cron 等与任务无关的系统提示,并根据 verifier score 保留高质量轨迹。
最终筛选出的轨迹平均包含 13.00 轮交互、18.67K tokens、15.82 次工具调用和 3.25 种工具类型。这说明训练数据不是短回复,而是包含规划、文件检查、工具执行和反馈调整的多轮 agentic supervision。
随后,我们对 Qwen3 系列模型进行 multi-turn SFT,得到 ClawGym-4B、ClawGym-8B 和 ClawGym-30B-A3B。训练时对环境反馈进行 loss masking,使模型学习自身生成的推理、决策和工具调用,而不是模仿工具返回结果。
此外,ClawGym 还探索了 sandbox-parallel RL。每个任务在独立 sandbox 中运行,并直接使用 code verifier 提供 outcome reward。实验显示,无论从原始 Qwen3-4B-2507-Instruct 出发,还是从经过 SFT 的 ClawGym-30B-A3B 出发,RL 都能带来进一步提升。
ClawGym-Bench
ClawGym-Bench 是框架中的评测部分,由 200 个经过严格筛选的任务组成,用于评估 Claw Agent 在工作区任务中的执行能力。
相比训练数据,ClawGym-Bench 对任务质量和评测可靠性提出了更高要求。首先,它通过难度感知筛选,保留强模型能够完成、小模型不易完成,并且能够区分模型能力差异的任务。其次,每个候选任务都会经过“人类-大模型协同审查”:由前沿大模型对任务指令、输入资源和验证器进行诊断式检查,再由人类审查者完成最终确认。此外,ClawGym-Bench 还要求任务具备可验证的可解性,确保每个任务至少存在一条可以获得满分的完成路径。
在任务覆盖范围上,ClawGym-Bench 包含六类典型工作区场景:生产力与协作、系统与自动化、分析与推理、内容与领域支持、规划与知识管理、软件开发。这些类别覆盖办公协作、系统自动化、数据分析、内容生成、知识整理和代码开发等常见任务类型。
评测结果进一步表明,ClawGym-Bench 具有良好的稳定性,能够支持对不同 Claw Agent 进行可靠的能力比较,并揭示不同规模模型在工作区任务执行中的能力差距。
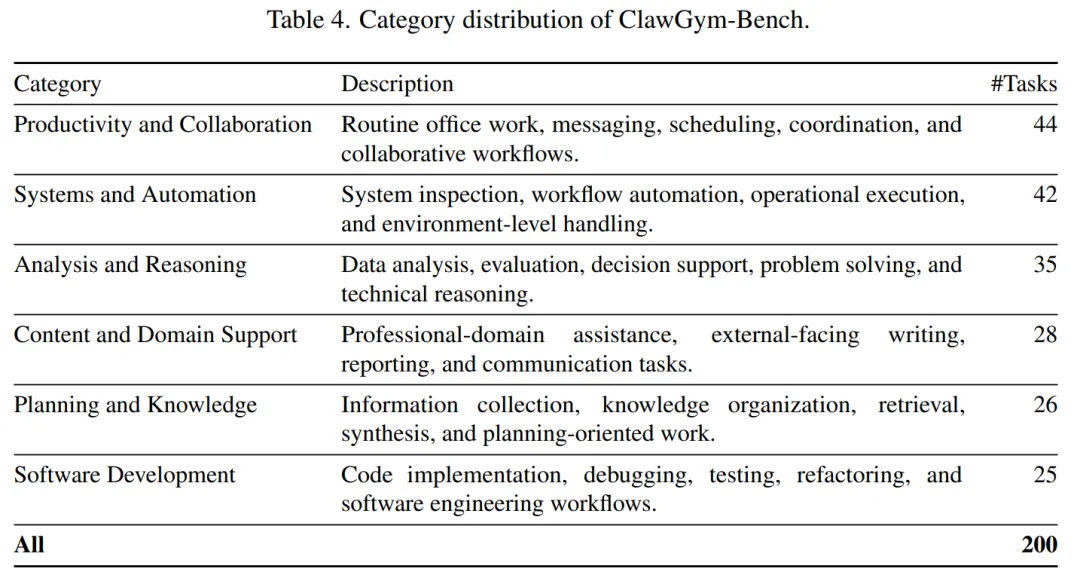
主要结果
数据有效性:ClawGym-SynData 显著提升模型表现
实验结果表明,ClawGym-SynData 能够稳定提升不同规模开源模型在 Claw-style 任务中的表现。经过训练后,ClawGym-4B、ClawGym-8B 和 ClawGym-30B-A3B 在 ClawGym-Bench 上分别达到 47.73、50.24 和 56.82,均超过对应的 Qwen 基座模型。值得注意的是,ClawGym-30B-A3B 还超过了规模更大的 Qwen3-235B-A23B,说明高质量的 agent 交互数据能够在一定程度上弥补模型规模不足。
基准区分度:不同模型呈现清晰能力差异
ClawGym-Bench 展现出良好的区分能力。不同模型的平均得分从 Qwen3-8B 的 35.02 到 Claude-4.7-Opus 的 77.81,形成清晰的能力梯度。同时,不同模型在不同任务类别上各有优势:Claude-4.7-Opus 整体平均分最高,GPT-5.4 在生产力与协作类任务上表现更好,Gemini-3-Flash 则在软件开发类任务上领先。这说明 ClawGym-Bench 不只提供总体分数,也能揭示模型在具体能力维度上的差异。
泛化能力:从合成任务迁移到外部基准
更重要的是,ClawGym-Agents 只使用 ClawGym-SynData 训练,却能在外部评测基准 PinchBench 上取得显著提升。其中,ClawGym-30B-A3B 在 PinchBench 上达到 86.00,表现具有很强竞争力。这说明模型并不是简单记住合成任务模式,而是学到了可迁移的工作区执行能力。
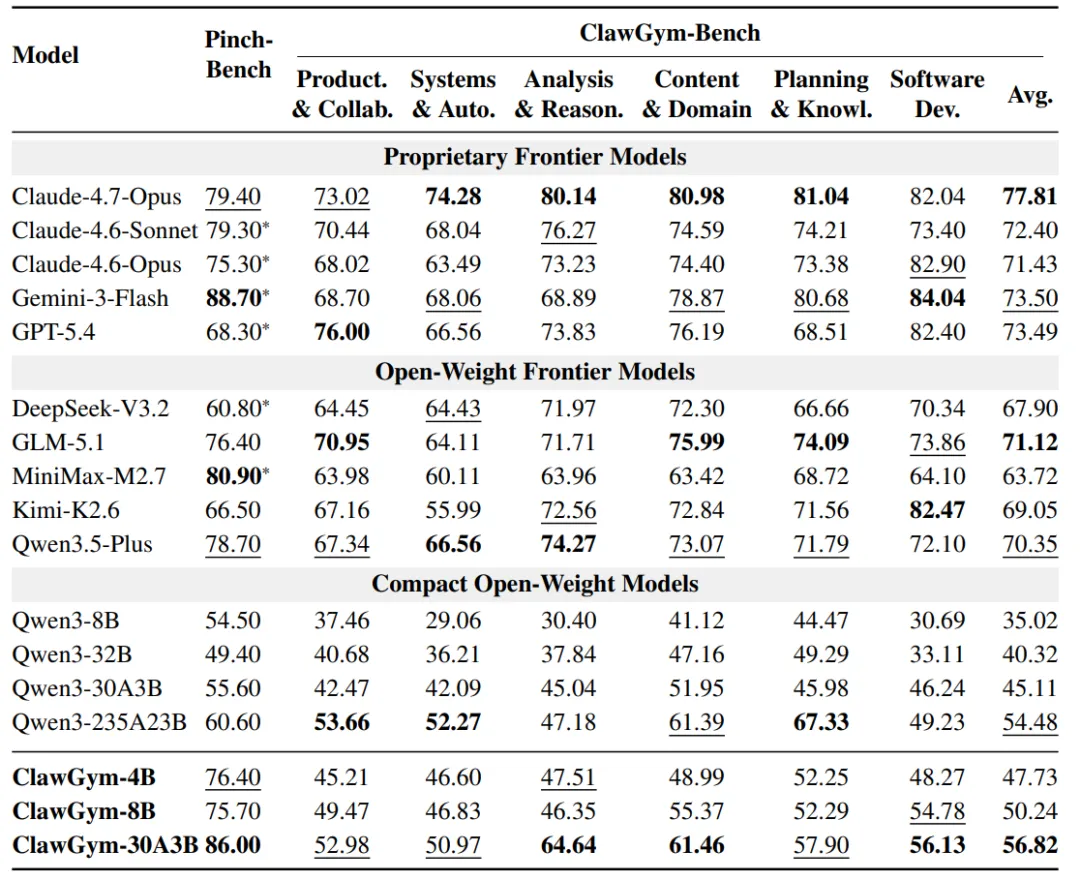
强化学习探索:验证器奖励继续提升模型能力
除监督微调外,我们还探索了面向 Claw-style 任务的强化学习训练。ClawGym 将每个任务放入独立沙盒中并行执行,并直接使用代码验证器提供结果奖励。从两条训练曲线可以看到,无论是从原始 Qwen3-4B-2507-Instruct 出发,还是从经过监督微调的 ClawGym-30B-A3B 出发,强化学习都能带来进一步提升。这说明,基于验证器的结果奖励可以为 Claw Agent 的持续优化提供有效信号。
需要强调的是,这部分目前仍在初步探索阶段。后续我们将继续改进任务采样策略、奖励设计、训练稳定性和 rollout 效率,进一步探索更适合工作区任务的强化学习范式。
Claw Agent 行为分析
常规 agent 往往围绕相对明确的网页、代码或问答任务展开,重点是选择合适工具并完成局部操作。而 Claw Agent 面对的是一个持续变化的用户工作区:已有文件、目录结构、脚本输出、中间状态和最终产物都会影响任务是否真正完成。
因此,Claw Agent 的关键能力不只是“会调用工具”,而是能否把工作区逐步更新到满足用户要求的最终状态。
这也带来三点核心差异:
-
从工具调用到工作流组织:Claw Agent 需要把文件探索、信息读取、脚本执行、结果检查和产物验证串联成完整流程,而不是完成孤立的工具调用。
-
从单步执行到长程恢复:Claw Agent 更容易遇到文件缺失、路径错误、命令失败等状态相关问题,因此需要根据环境反馈不断调整,而不是在错误累积后停止。
-
从生成答案到验证产物:Claw Agent 的输出不是一段文本,而是 CSV、JSON、报告、脚本等工作区产物;这些产物必须满足字段、公式、过滤规则和跨文件一致性等细粒度要求。

从这个案例可以看出:强模型能够把错误作为反馈继续推进任务,而弱模型则容易在连续错误中偏离目标。因此,Claw-style 任务考察的不是单一语言能力,也不是简单工具调用能力,而是 agent 在状态化工作区中持续执行、恢复错误并保证最终产物正确的能力。
总结与展望
ClawGym 的核心价值在于,它是首个系统连接 Claw Agent 数据构建、能力训练和可靠评测的完整框架:ClawGym-SynData 提供大规模、可执行、可验证的工作区任务,ClawGym-Agents 从 OpenClaw 黑盒执行轨迹中学习如何在环境中行动,ClawGym-Bench 则用于评估 agent 是否真正完成了工作区任务。