 夜雨聆风
夜雨聆风





YC 放出一套「AI-native 公司」组织方法论,直接把公司当操作系统来设计!中层管理变成了 markdown
【导读】Y Combinator 刚刚放出一段 Startup School 视频,YC 合伙人 Diana Hu 用 10 分钟讲了一整套 AI-native 公司的组织设计方法论——公司要变成「可查询的」、中层管理要让 AI 吞掉、未来拼的是 token 投入强度而非人头数。视频上线不到一天,近2 万人围观,评论区已经吵起来了。
YC 这次讲的,跟「加个 Copilot」完全是两回事
4 月 24 日,YC 官方账号在 X 上发了一条帖子,核心句非常直白:
“AI isn’t just making teams more productive. It’s changing how companies should be built.”
「AI 不只是让团队更高效,它正在改变公司应该如何被构建。」
随后 YC 追了一条跟帖,挂上了 YouTube 链接,把整件事从一句观点升级成一段完整视频论述。

▲ YC 官方主帖,直接抛出核心命题,近 200 赞、2 万次浏览
▲ YC 追加”Tune in”跟帖,挂出 Diana Hu 主讲的 Startup School 视频
视频全长 10 分 27 秒,章节标题已经很说明问题了——「AI 作为公司的操作系统」「开放循环 vs 封闭循环公司」「让公司完全可查询」「1000 倍工程师的崛起」「为什么中层管理会消失」「初创公司将赢得这一转变」。
每一个章节名都像一记重锤。
「AI 应该是公司运行的操作系统」——Diana Hu 一上来就把定调拉满
Diana Hu 开场就把 framing 立住了。她说,过去大家谈 AI,常常是”让工程师更高效””给旧流程加个 copilot””多上几个自动化 feature”。但这会错过真正的转变。
她的原话:
“AI should not be a tool your company just uses. It should be the operating system your company runs on.”
「AI 不应该只是公司拿来用的工具,它应该是公司运行其上的操作系统。」
这句话的关键在于组织边界被改写了——AI 变成所有 workflow、decision、process 共同经过的一层 intelligence layer。公司的设计目标,从「哪些岗位用 AI」变成「哪些信息、动作、判断必须先变得对 AI 可读、可调、可反馈」。
换句话说,YC 开始把 AI 创业从产品命题,升级成了组织命题。
闭环公司 vs 开环公司:你的决策有没有在「学习」?
视频第二个很猛的概念是 open loop / closed loop。
传统公司很多时候是 open loop——做了决策、执行了动作,但没有系统性地测量结果、把结果重新喂回系统、再修正流程。信息碎片化,靠人手动解释,反馈链条长。
Diana Hu 说,AI-native 公司应该是closed loop——重要流程都变成智能闭环,信息被捕捉、反馈、再训练下一轮动作。
这套逻辑天然连接到今天最常见的 agent 工作流:
-
销售线索收集 → 归因 → 成交/流失 → 反哺到下一轮 lead scoring -
客服对话 → 问题分类 → 工单流转 → 满意度 → 再反哺知识库与 SOP -
工程交付 → ticket / commit / bug / 用户反馈 → 下轮 sprint 规划
每一个环节产生的数据,都在喂下一个环节的智能。整家公司像一个持续在跑的学习系统。
「可查询公司」:未来公司跑得快不快,取决于上下文容器的质量
Diana Hu 说得很具体:如果你想把公司做成闭环,就必须让整个组织变得 queryable——对 AI 可查询、可理解、可回放。
她的原话:
“The whole organization should be legible to AI. Every important action should produce an artifact that the intelligence at the center of the company can learn from and use to self-improve.”
「整个组织都应该对 AI 可读。每个重要动作都应该产出一个 artifact,让公司核心的智能层可以从中学习、自我改进。」
具体怎么做?她给的不是空话:
-
会议尽量被 AI notetaker 记录 -
减少碎片化 DM 和 email -
在各个沟通渠道里嵌入 agent -
搭自定义 dashboard,把 revenue、sales、engineering、hiring、ops 等关键数据打通 - 每个重要动作都产出 artifact,便于系统学习
这套说法的潜台词很强:未来公司跑得快不快,取决于你有没有先把公司做成一个高质量上下文容器。
软件工厂来了:人写规范,AI 生产实现
视频中段,Diana Hu 把研发组织往前推了一步。她说,高速公司正在进入一种新的产品构建范式——software factories。
人类负责写 spec、定义测试、判断是否成功;agent 负责生成实现、写代码、循环迭代直到测试通过。
她甚至给出了一个很激进的说法:有些公司已经把 repo 做到「几乎没有手写代码,只有 spec 和 test harness」。并点了 StrongDM AI team 这个例子。
这里有两个传播点:
1.软件开发的主语在变:从「人写代码,AI 辅助」走向「人写规范,AI 生产实现」。 2.1000x engineer 的叙事开始从夸张口号,变成 YC 官方愿意公开讲的组织范式。
当然要注意:视频中「把工程 sprint 时间砍半、产出接近 10 倍」是 Diana Hu 的主张和她所见样本,目前还无法作为行业均值来引用。
「中层管理没有消失,它变成了 markdown」
这期视频最容易引爆讨论的一句,应该跟中层管理有关。
Diana Hu 的意思是:旧世界里之所以需要 middle managers 和 coordinators,是因为信息要靠人手动上下传递。而在 queryable、artifact-rich、legible-to-AI 的公司里,这部分「human routing」会显著减少。
她说得很直接:
“You should have almost no human middleware.”
「公司里应该几乎没有『人肉中间层』。」
推文底下,Chen Avnery 的跟帖直接把这句话翻译成了从业者的版本:
“‘Queryable company’ framing is right. Our 12 agents share context through plain text files – constraint docs, rolling context, shared intel. No middleware, no management layer. Agent reads a file, does its job, writes back. Middle management didn’t disappear. It became markdown.”
「12 个 agent 通过纯文本文件共享上下文——约束文档、滚动上下文、共享情报。没有中间层,没有管理层。agent 读文件,干活,写回去。中层管理没有消失,它变成了 markdown。」
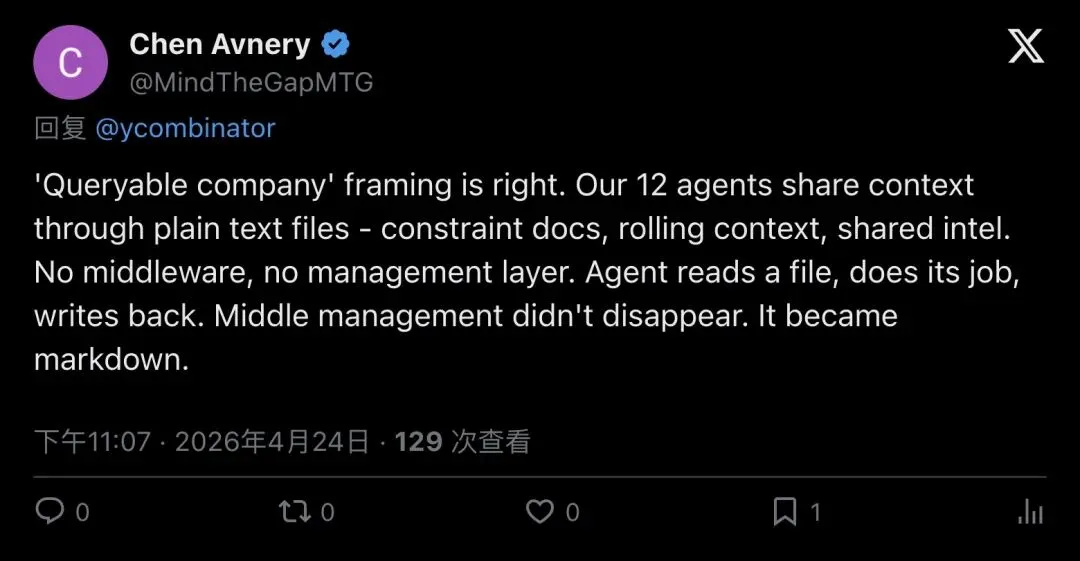
▲ Chen Avnery:「中层管理没有消失,它变成了 markdown」
这句话极具网感。它把 YC 的抽象概念变成了一个极具画面感的落地表达——管理没有凭空蒸发,而是被文档、约束文件、共享上下文、agent 协作流程重写了。
Token maxing:未来最强的公司,拼的是 token 投入强度
视频后段还有一个很适合出圈的提法:
“Maximizing token usage, not headcount, will be the critical shift. The best companies will be the ones that are token maxing.”
「关键变化将是最大化 token 使用,而非最大化人头数。最好的公司会是那些在拼 token 投入的公司。」
翻成更直白的话就是:未来最强的公司,未必是人最多的那个,而是更敢把 API/token 预算当作「生产力投资」,用算力替代本该扩张的组织人数。
这很像是在重新定义创业公司的成本结构——以前拼 headcount,现在拼上下文质量、agent 覆盖率、模型调用密度、闭环反馈速度。
Scott Motte 在跟帖里直接提炼出了三个最适合传播的概念词:

▲ Scott Motte 提炼三个关键词:Queryable company、Human middleware、Human routing
这三个词非常适合被剪成短视频切片、公众号小标题、朋友圈钩子。
为什么 YC 说初创公司反而更占便宜?
Diana Hu 在视频最后明确强调,早期创始人有巨大优势。因为他们没有 legacy systems、没有既有组织架构、也没有成千上万人需要再培训。他们可以从 Day 1 就按 AI-native 逻辑来设计系统、工作流和文化。
而大公司相反——要边维护已有产品边改组织,改一个流程就可能打断已运行机制。最多先靠 skunkworks team 旁路试验。
这意味着 YC 在给「为什么小公司还能赢大公司」这个问题,提供一套 AI 时代的新论证。
但评论区已经吵起来了
YouTube 评论区不全是叫好。
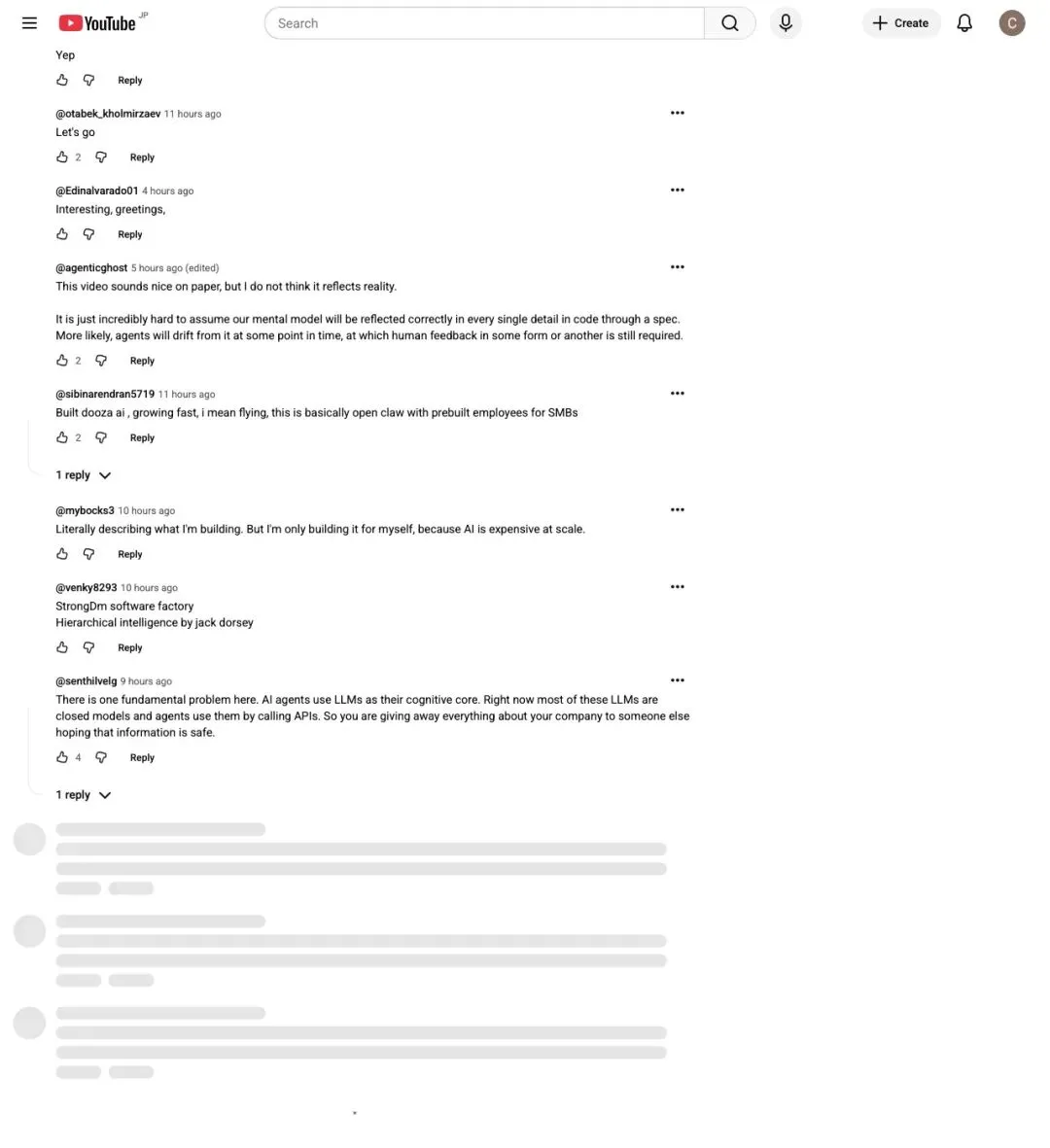
▲ YouTube 评论区:既有认同,也有质疑
最典型的反对意见来自 @agenticghost:
“This video sounds nice on paper, but I do not think it reflects reality. It is just incredibly hard to assume our mental model will be reflected correctly in every single detail in code through a spec.”
「这段视频纸面上很美,但我不觉得它反映了现实。很难假设我们的心智模型能通过一份 spec 准确映射到代码的每一个细节。」
还有人直接戳信息安全:
“Right now most of these LLMs are closed models and agents use them by calling APIs. So you are giving away everything about your company to someone else hoping that information is safe.”
「现在大多数 LLM 都是闭源模型,agent 通过调 API 来使用它们。所以你其实是在把公司的一切都交给别人,指望那些信息是安全的。」
这两条质疑抓到了要害:agent drift(agent 能否长期稳定反映人的心智模型?)和闭源模型的信息安全风险。当你把公司的认知核心交给外部 LLM API,组织信息暴露给模型提供商,这会成为 AI-native 公司的一条硬约束。
所以 YC 到底在做什么?
退一步看,YC 这次输出的东西,远不只是一期 Startup School 视频。
结合推文的概念抛出 → 视频的系统论述 → 跟帖中新概念词的自发传播,它更像 YC 在提前定义下一波 AI 创业公司应该怎么介绍自己——闭环的、可查询的、软件工厂式的、token maxing 的组织系统。
这套表述非常适合在融资、招聘、品牌定位里被反复引用。
YC 开始给 AI-native 公司统一话术了。你准备好接住这套新组织学了吗?
▲ Diana Hu 主讲的 Startup School 视频,上线不到一天,近 2 万次播放,1K 赞
— END —