 夜雨聆风
夜雨聆风





LKDock 全版本功能说明(v1.0/2.0/3.0)
开发者:罗柯生信
范围:LKDock v1.0 / v2.0 / v3.0
内容:对接引擎、PPI 引擎、口袋预测、功能、算法、项目来源
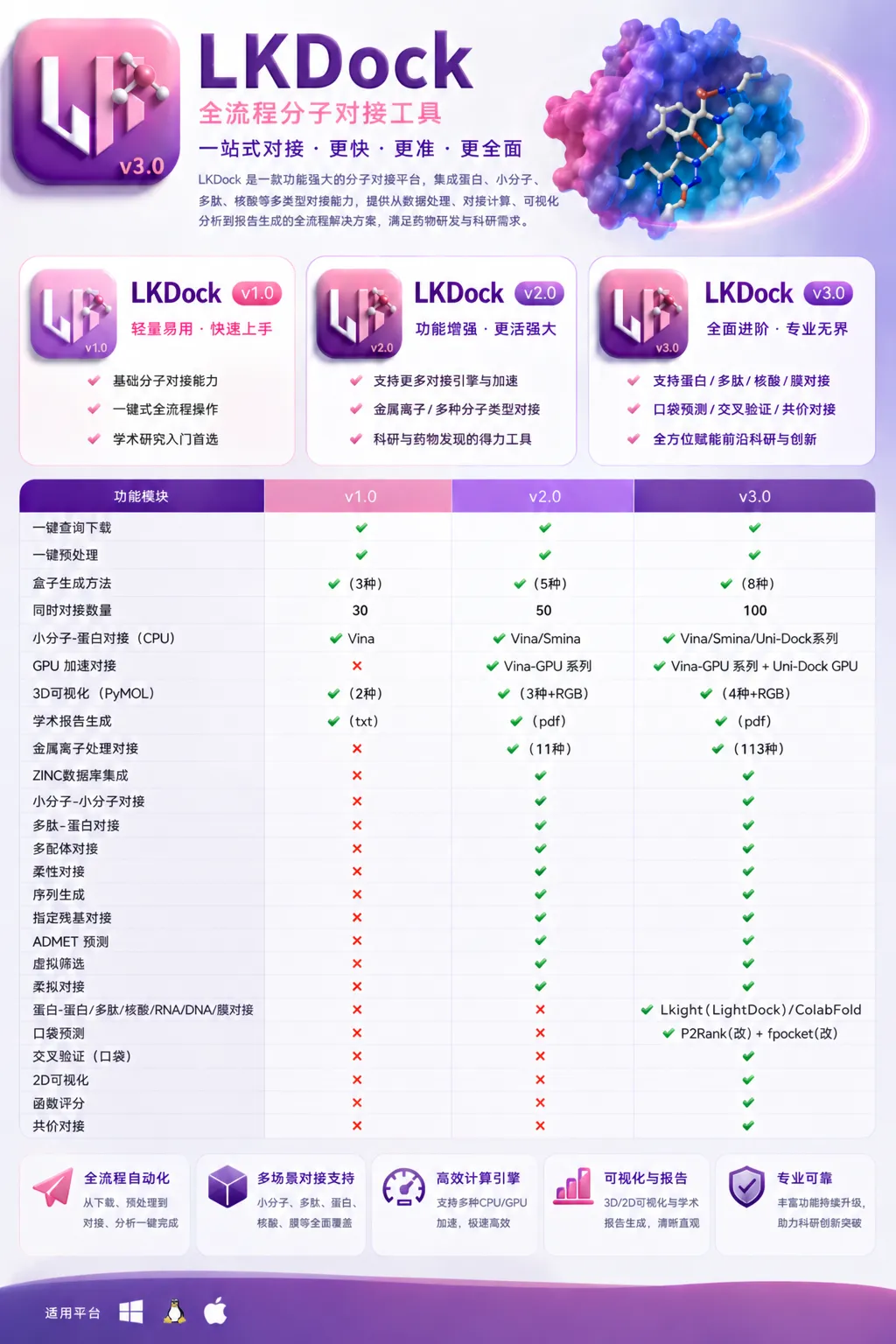
一、版本功能总览
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
二、Python 依赖对比
2.1 环境基础
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
2.2 软件依赖
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
三、小分子对接引擎
3.1 AutoDock Vina
|
|
|
|---|---|
|
|
|
|
|
vina127);v1.1.2(经典版) |
|
|
|
|
|
|
|
|
|
|
|
|
功能:小分子-蛋白刚性/半柔性对接 – 基于梯度优化的构象搜索 – 多构象输出(num_modes) – 支持 exhaustiveness 调节搜索强度
算法:全局搜索:迭代局部搜索(Iterated Local Search),结合随机扰动与局部优化 – 局部优化:BFGS(Broyden–Fletcher–Goldfarb–Shanno)拟牛顿法 – 评分函数:基于知识的经验势函数,包含立体效应(Gauss + Repulsion)、氢键、疏水作用、可旋转键惩罚 – 输出:结合自由能 ΔG (kcal/mol)
3.2 Smina
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能:全部 Vina 功能 + 可自定义评分函数权重 – 支持 58 种评分项(Gauss、电静力、AutoDock4 去溶剂化等) – 柔性侧链对接 – 改进的金属离子处理 – 非 PDBQT 配体文件直接读取(自动计算部分电荷)
算法:继承 Vina 的 ILS + BFGS 框架 – 扩展评分函数:支持加权线性组合自定义评分项 – 可用于重新打分(rescoring)和约束对接
3.3 Vina-GPU 系列
3.3.1 Vina-GPU
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能: 基于 OpenCL 的 GPU 加速 AutoDock Vina – 支持 NVIDIA / AMD / Intel GPU – 单配体对接加速
算法:将 Vina 的蒙特卡洛+局部优化并行化到 GPU – OpenCL 内核实现梯度计算和评分函数
3.3.2 Vina-GPU+
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能: Vina-GPU 的增强版,进一步加速 – 支持单受体-多配体批量对接 – 优化 OpenCL 内核
3.3.3 Vina-GPU 2.0 / 2.1
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能:集成 Vina-GPU+、QuickVina2-GPU、QuickVina-W-GPU 三种方法 – 进一步优化精度和速度的平衡
算法:双层并行:搜索步骤级并行 + 配体级并行 – 优化的 OpenCL Kernel(Kernel1_Opt.bin/ Kernel2_Opt.bin)
3.4 QuickVina 系列(GPU)
3.4.1 QuickVina2-GPU
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能:在 Vina 基础上引入”首次成功停止”策略,减少冗余搜索 – GPU 加速版支持 OpenCL 并行
算法: QuickVina2 核心:允许局部搜索在找到足够好的构象后提前终止 – 搜索空间分解 + 并行蒙特卡洛 – 保持 Vina 评分函数精度,速度提升约 20.49 倍(CPU 版 vs Vina)
3.4.2 QuickVina-W-GPU
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能:蛋白-配体盲对接(无需指定结合位点) – 进程间时空整合策略(Inter-Process Spatio-Temporal Integration)
算法:将搜索空间划分为多个重叠子空间 – 各子空间并行搜索后整合 – GPU 版进一步在每个子空间内并行化
3.5 Uni-Dock
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能:AutoDock Vina 的 GPU 加速版,V100 GPU 上可达 >2000 倍加速 – CPU 全局搜索:macOS/Linux/Windows 均可无 GPU 运行完整单配体对接 – GPU 批量虚拟筛选:--gpu_batch支持大规模配体库筛选 – 支持 vina、vinardo、ad4三种评分函数 – 配体索引文件模式(--ligand_index) – 兼容 Vina 命令行格式,可低成本替换
算法继承 Vina 评分函数和 ILS+BFGS 搜索框架 – CUDA 并行化:将多配体的蒙特卡洛搜索映射到 GPU 线程块 – 批量模式下在单次 GPU 调用中同时处理数百个配体。
3.6 UniDock-Pro
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能(在 Uni-Dock 基础上新增):相似度引导对接:--reference_ligand+ --similarity_searching– 混合模式:--hybrid_mode(相似度搜索 + 自由对接结合) – 详细能量分解:输出分子间能量、内部能量、扭转自由能 – GPU 批量虚拟筛选 – macOS CPU 模式支持打分(--score_only)和局部优化(--local_only)
算法:继承 Uni-Dock 核心(Vina 评分 + CUDA 并行) – 新增相似度引导:参考配体的形状/药效团约束注入搜索过程 – 混合模式在无偏搜索和有偏搜索之间自适应切换。
3.6.1 LK-UniDock(源码补丁与跨平台二进制发行)
✅ LKDock v3.0 的 Uni-Dock / UniDock-Pro 源码同步与可执行文件发布项目
GitHub:LK-Studio1128/LK-UniDock
Release:LK-Studio1128/LK-UniDock/releases/tag/v1.0.0
定位与目标
LK-UniDock 不是新的对接算法,而是围绕 Uni-Dock v1.1.3 与 UniDock-Pro v0.0.1 建立的 LKDock 专用源码补丁、跨平台构建与预编译发行工程。其目标是解决上游项目在实际 GUI 分发与终端用户使用中的三个关键问题:
-
Windows GPU 二进制缺失:上游 Uni-Dock / UniDock-Pro 不提供可直接运行的 Windows GPU 版;LK-UniDock 提供 Uni-Dock-GPU.exe与UniDock-Pro-GPU.exe。 -
运行库依赖复杂:传统 Windows 构建容易依赖 CUDA Runtime、Boost DLL、MSVC CRT、VC++ Redistributable 等大量外部组件;LK-UniDock 使用可移植编译方案,将 Boost、MSVC CRT、CUDA Runtime 静态嵌入,分发时仅需 exe + vcomp140.dll。 -
MSVC + CUDA 编译兼容性问题:上游源码在 Windows CUDA 编译时会因 Boost filesystem 进入 CUDA translation unit 而报错;LK-UniDock 通过 __CUDACC__守卫、头文件拆分与 CMake 选项修复该问题。
仓库结构
LK-UniDock/
├── Uni-Dock-main/ # 已补丁化的 Uni-Dock v1.1.3 源码
├── UniDock-Pro-main/ # 已补丁化的 UniDock-Pro v0.0.1 源码
└── UniDock/ # 预编译二进制发行目录
├── UniDock-macos-arm64/
├── UniDock-linux86/
└── UniDock-win64/
平台二进制发布包
|
|
|
|
|
|---|---|---|---|
|
|
UniDock-macos-arm64.tar.gz |
Uni-Dock
UniDock-Pro |
|
|
|
UniDock-linux86.tar.gz |
Uni-Dock-GPU
UniDock-Pro-GPU、split |
|
|
|
UniDock-win64.zip |
Uni-Dock-GPU.exe
UniDock-Pro-GPU.exe、vcomp140.dll |
|
Windows GPU 可移植版特性
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
cudart64_*.dll |
|
|
FETCH_BOOST=ON
|
|
|
|
BUILD_PORTABLE=ON
/MT静态嵌入 |
|
|
|
vcomp140.dll(随包分发) |
|
|
|
|
|
|
|
|
|
支持的 GPU 架构
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
相对上游源码的关键补丁
|
|
|
|
|---|---|---|
|
|
src/lib/common.h |
__CUDACC__
std::string替代 boost::filesystem::path,避免 MSVC + CUDA 编译错误 |
|
|
src/lib/file.h |
|
|
|
src/lib/cache.h
ad4cache.h |
.cpp,减少 CUDA 编译单元依赖污染 |
|
|
CMakeLists.txt |
|
FORCE_CPU_ONLY |
CMakeLists.txt |
|
BUILD_PORTABLE |
CMakeLists.txt |
|
FETCH_BOOST |
CMakeLists.txt |
|
|
|
CMakeLists.txt
build_mac.sh |
libomp,避免 Apple Clang OpenMP 缺失 |
|
|
CMakeLists.txt |
|
/utf-8
|
CMakeLists.txt |
|
predict_peak_memory
|
|
|
对 LKDock 的意义
-
降低用户部署门槛:Windows 用户无需安装 CUDA Toolkit、Boost、Visual Studio 或 VC++ Redist,仅需 NVIDIA 驱动。 -
增强 v3.0 GPU 批量筛选能力:配合 LKDock 中的 Uni-Dock GPU 批调度逻辑,可通过 --ligand_index复用受体网格与 CUDA context 初始化成本,避免”每个配体启动一次引擎”造成的性能浪费。 -
提升源码可维护性:将跨平台构建脚本、许可证、CI、补丁说明集中在 GitHub 项目中,便于后续版本追踪与社区复现。 -
保持算法一致性:核心搜索算法与评分函数不改动,结果仍与 Uni-Dock / UniDock-Pro 同源;LK-UniDock 主要解决工程可用性、平台兼容性和发行可靠性。
3.7 小分子引擎对比总表
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| LK-UniDock |
|
|
|
|
|
|
|
| LKina |
|
|
|
|
|
|
|
3.7.1小分子对接引擎——评分函数对比
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
--custom_scoring |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
vinardo
ad4 |
|
|
|
|
|
vinardo
ad4 |
|
|
|
|
|
|
|
|
评分函数说明: – Vina 评分函数:5 项加权线性组合——两个 Gauss 项(引力)、一个 Repulsion 项(排斥)、一个 Hydrophobic 项(疏水)、一个 HBond 项(氢键),最终加可旋转键惩罚 – Vinardo 评分函数(Uni-Dock):去除 Gauss2,简化项数,权重重新拟合,对某些体系更鲁棒 – AD4 评分函数(Uni-Dock/LKina):使用 AutoDock4 格点映射(affinity maps),兼容 AD4 工作流;LKina 将 AD4 扩展为内联 AG4 金属格点与响应式共价约束 – Smina 自定义评分:通过 --custom_scoring <weights_file>指定 58 项中任意子集的权重文件
3.7.2 Vina 1.2.7 评分项权重(–help_advanced 输出)
|
|
|
|
|---|---|---|
weight_gauss1 |
|
|
weight_gauss2 |
|
|
weight_repulsion |
|
|
weight_hydrophobic |
|
|
weight_hydrogen |
|
|
weight_rot |
|
|
weight_vinardo_gauss1 |
|
|
weight_vinardo_repulsion |
|
|
weight_vinardo_hydrophobic |
|
|
weight_vinardo_hydrogen |
|
|
weight_vinardo_rot |
|
|
weight_ad4_vdw |
|
|
weight_ad4_hb |
|
|
weight_ad4_elec |
|
|
weight_ad4_dsolv |
|
|
weight_ad4_rot |
|
|
weight_glue |
|
|
3.7.3全部可用评分项(smina –print_terms 输出,共 27 项)
|
|
|
|
|
|---|---|---|---|
|
|
electrostatic |
|
|
|
|
ad4_solvation |
|
|
|
|
gauss |
|
|
|
|
repulsion |
|
|
|
|
hydrophobic |
|
|
|
|
non_hydrophobic |
|
|
|
|
vdw |
|
|
|
|
non_dir_h_bond_lj |
|
|
|
|
non_dir_anti_h_bond_quadratic |
|
|
|
|
non_dir_h_bond |
|
|
|
|
acceptor_acceptor_quadratic |
|
|
|
|
donor_donor_quadratic |
|
|
|
|
atom_type_gaussian |
|
|
|
|
atom_type_linear |
|
|
|
|
atom_type_quadratic |
|
|
|
|
atom_type_inverse_power |
|
|
|
|
atom_type_lennard_jones |
|
|
|
|
num_tors_add |
|
|
|
|
num_tors_sqr |
|
|
|
|
num_tors_sqrt |
|
|
|
|
num_tors_div |
|
|
|
|
num_tors_div_simple |
|
|
|
|
ligand_length |
|
|
|
|
num_ligands |
|
|
|
|
num_heavy_atoms_div |
|
|
|
|
num_heavy_atoms |
|
|
|
|
num_hydrophobic_atoms |
|
|
|
|
constant_term |
|
|
3.7.4小分子对接引擎——运行速度对比(官方基准数据)
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
说明:以上数据为各引擎官方论文/README 中报告的典型基准值,实际运行时间因受体大小、配体柔性、exhaustiveness 设置和硬件而异。Vina-GPU 系列的加速比基于 OpenCL(跨厂商),Uni-Dock 的加速比基于 CUDA(仅 NVIDIA)。
3.7.5小分子对接引擎——搜索算法对比
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
--cpu N) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键差异总结: 1. Vina/Smina:纯 CPU,适合小规模精确对接 2. Vina-GPU 系列:OpenCL 加速,支持 NVIDIA/AMD/Intel GPU,适合中等规模筛选 3. QVina 系列:在 Vina 搜索策略上做了智能优化(提前停止/空间分解),速度显著提升 4. Uni-Dock / LK-UniDock:CUDA 深度优化,仅支持 NVIDIA GPU,批量筛选性能最强(>2000x 加速),LK-UniDock 重点解决跨平台源码补丁与预编译发行 5. LKina:面向金属配位与共价对接,继承 Vina 搜索框架并扩展 AD4/AG4、金属伪原子和 reactive 约束
3.8 LKina(金属 + 共价对接引擎)
✅ LKDock v3.0 的金属配位与共价对接核心引擎(AD4 路径)
GitHub:LK-Studio1128/LKina
Release v1.0.0:LK-Studio1128/LKina/releases/tag/v1.0.0
|
|
|
|---|---|
| 全称 |
|
| 二进制名 | LKina
LKina.exe(Windows) |
| 版本 |
|
| 语言 |
|
| 预编译二进制 |
|
| 许可证 |
|
| 上游基线 |
|
| 开发者 |
|
| 论文 | LKINA.md
|
| 本地二进制路径 |
byi/LKina/build/mac/release/LKina;Linux:byi/LKina/build/linux/release/LKina;Windows/MSYS2:build/linux/release/LKina.exe或 Release assets 解压后使用 |
核心能力(相对 Vina 1.2.7 的扩展)
-
113 AD4 原子类型 + 4 伪原子(TZ / SQ / MH / JT),覆盖 80+ 金属/类金属 -
内联 AG4 格点生成:无需外部 autogrid4可执行文件 -
BVS 氧化态自动推断:Fe / Cu / Mn / Co / V / Mo / Ni 的 +2 / +3 / +4 / +6 自动识别 -
Jahn-Teller 变形模式:Cu²⁺(d⁹)、Mn³⁺(d⁴)拉长八面体 -
半显式水桥候选位点:配位不饱和处的 M–O(water) 几何后处理评分 -
响应式共价对接 P1–P4:距离约束 + 角度约束 + 帧原子扭转 + 混合 vdW 缩放 -
C3 两阶段策略:Phase-1 无约束 MC 预采样 → Phase-2 带约束 L-BFGS 精化 -
6 种反应预设: cys_michael/cys_sn2/ser_covalent/lys_targeting/boronic_acid/tyr_covalent -
Metal Bias(O5):向受体金属中心注入软 Gaussian 吸引子,适合金属靶点快速筛选 -
金属作为配体:reverse metal-donor pair potentials(参考 MetalDock standard_set) -
完全向后兼容:对不含金属、不触发共价的标准受体,行为与 Vina 1.2.7 一致
典型 CLI
# 1. 标准 Vina 评分(与上游等价)
LKina --receptor rec.pdbqt --ligand lig.pdbqt \
--center_x 0 --center_y 0 --center_z 0 \
--size_x 20 --size_y 20 --size_z 20 --out out.pdbqt
# 2. 内联 AD4 + 自动金属识别(Zn 金属酶)
LKina --scoring ad4 --generate_maps \
--receptor carbonic_anhydrase.pdbqt --ligand inhibitor.pdbqt \
--center_x 14.68 --center_y 32.38 --center_z 10.64 \
--size_x 25 --size_y 25 --size_z 25 --out out.pdbqt
# 3. Cys 迈克尔加成共价对接
LKina --scoring ad4 --generate_maps \
--receptor egfr.pdbqt --ligand afatinib.pdbqt \
--center_x 18.2 --center_y 54.1 --center_z 25.7 \
--size_x 20 --size_y 20 --size_z 20 \
--reactive_preset cys_michael \
--reactive_rec_atom A:797:SG --reactive_lig_atom index:12 \
--reactive_frame_atom A:797:CB --reactive_two_step --out out.pdbqt
许可证结构
|
|
|
|
|---|---|---|
LICENSE |
|
|
LICENSE.Apache-2.0 |
|
|
COPYING |
|
|
NOTICE |
|
|
-
Apache-2.0 ↔ GPL-3.0 兼容性:FSF 官方确认。 -
AutoGrid4 either version 2 of the License, or (at your option) any later version条款允许升级到 GPL-3.0。 -
每个扩展源文件均带独立许可证头 + SPDX 标签 GPL-3.0-or-later。
四、蛋白-蛋白对接(PPI)引擎
PPI 功能仅在 LKDock v3.0 中引入。
4.1 LightDock(Python)
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能:蛋白-蛋白、蛋白-肽、蛋白-DNA 对接 – 多种评分函数(DFIRE, DFIRE2, CPyDock, PISA, FastDFIRE 等) – 支持 ANM(各向异性网络模型)柔性对接 – 约束对接(残基限制) – 多核并行(MPI / multiprocessing) – Swarm 分布式搜索
算法:GSO(萤火虫群优化,Glowworm Swarm Optimization):全局搜索 – 搜索空间:在受体表面生成多个 swarm,每个 swarm 包含多个 glowworm – 每个 glowworm 携带一个 6D 刚体变换(3 平移 + 3 旋转用四元数表示) – ANM 模式下额外加入主链柔性自由度 – 局部优化通过评分函数梯度引导。
4.2 LKlight
✅ LKDock v3.0 当前首选 PPI 引擎(取代原
lightdock-rust)
GitHub:LK-Studio1128/LKlight
Release:LK-Studio1128/LKlight/releases/tag/v1.0.0
|
|
|
|---|---|
| 全称 |
|
| 二进制名 | LKlight |
| 版本 |
|
| 语言 |
|
| 预编译二进制 |
|
| 许可证 |
|
| 上游基线 | lightdock-rust
|
| 开发者 |
|
| 论文 | PAPER.md
|
| 本地二进制路径 | byi/LKlight/target/release/LKlight
|
主要功能
-
12 类评分函数、13 个命令行方法名:dfire / fastdfire / dfire2 / dna / mj3h / pydock / cpydock / vdw / sd / pisa / sipper / tobi / ddna -
ANM 柔性对接:各向异性网络模型,受体/配体分别支持多个模式向量 -
对接类型:蛋白-蛋白、蛋白-肽、蛋白-DNA/RNA、抗体-抗原、跨膜蛋白 -
约束对接:支持 restraints_file指定活性/被动残基限制 -
单文件自包含二进制:无需 Python 环境或外部参数文件 -
跨平台:macOS arm64 / Linux x86-64 / Windows x86-64
修复的上游 Bug(相对 lightdock-rust)
|
|
|
|
|
|---|---|---|---|
|
|
|
|
const数组 |
|
|
|
|
nmodes.len()/(3*n_modes),加边界保护 |
|
|
|
|
|
|
|
|
assert_eq!(atom_count, anm_atoms)
|
|
多层次性能优化
|
|
|
|
|
|---|---|---|---|
|
|
|
|
rayon::par_iter()
|
|
|
|
|
|
|
|
sqrt_vdw_charges
|
|
sqrt()调用 |
|
|
|
|
|
|
|
BufWriter
|
|
write!()改为缓冲写,减少 syscall |
|
|
|
|
[f64;3]
Vec<f64> |
|
|
|
|
pos_scratch/rot_scratch
|
|
|
|
|
movement_phase()
rayon::par_iter_mut() |
评分函数完整列表(vs lightdock-rust)
|
|
|
|
|
|
|---|---|---|---|---|
dfire |
|
|
|
|
fastdfire |
|
|
|
|
dfire2 |
|
|
|
|
dna |
|
|
|
|
mj3h |
|
|
|
|
pydock |
|
|
|
|
cpydock |
|
|
|
|
vdw |
|
|
|
|
sd |
|
|
|
|
pisa |
|
|
|
|
sipper |
|
|
|
|
tobi |
|
|
|
|
ddna |
|
|
|
|
| 合计 | 12 类评分函数 / 13 个命令行方法名 | 7 种(含映射) |
基准测试数据(macOS arm64, Apple Silicon)
条件:swarm_0,200 glowworms,100 steps,n = 3 次均值
|
|
|
|
LKlight v1.0 |
|
|
|---|---|---|---|---|---|
|
|
|
|
290 ms | 3.0× | 26.5× |
|
|
|
|
33 ms | 25.5× |
|
|
|
|
|
44 ms | 19.2× | 163× |
|
|
|
|
46 ms | 16.5× | 307× |
LKDock v3.0 集成配置
CONFIG["ppi"]["engine"] = "lklight"
CONFIG["ppi"]["lklight_exe"] = "..."
CONFIG["ppi"]["lklight_concurrency"] = 0
-
GUI 引擎下拉框: ["lklight", "alphafold"],默认lklight -
评分函数下拉框:auto / fastdfire / dfire / dfire2 / cpydock / dna / ddna / pisa / vdw / sipper / tobi / mj3h -
内存预算: _ppi_engine_mem_profile()返回("lklight", 0.2 GB/任务) -
历史展示名兼容:保存的 "lightdock"引擎字符串加载时自动规范化为"lklight"
4.3 ColabFold / AlphaFold2
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能: 蛋白质结构预测(单体/多聚体) – AlphaFold2-Multimer:直接预测蛋白复合物结构 – ColabFold 封装 AlphaFold2 + MMseqs2 快速序列比对 – 支持 model_type、num_models、num_recycle参数 – 可作为 PPI 对接的”结构生成器”
算法: Evoformer:多层注意力网络处理 MSA(多序列比对)和 pair representation – Structure Module:迭代细化 3D 坐标 – Recycling:多轮迭代提升预测质量 – Multimer 模式:扩展 pair representation 支持链间交互 – MMseqs2 替代 Jackhmmer 加速序列搜索
安装:ColabFold需要使用conda安装,先安装conda软件(Miniforge3/Miniconda3/Anconda等)
conda create -n colabfold -c conda-forge -c bioconda python=3.13 kalign2=2.04 hhsuite=3.3.0 mmseqs2=18.8cc5c
conda activate colabfold
# With CUDA GPU support
pip install colabfold[alphafold,openmm] jax[cuda] openmm[cuda12]
# CPU only
pip install colabfold[alphafold,openmm]
# For colabfold_search only (no structure prediction)
pip install colabfold
4.4 PPI 引擎对比总表
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| LKlight | 1.0.0 | GSO + rayon 并行 |
|
|
12 类/13 方法名 |
|
|
|
|
|
|
|
|
|
|
|
对比说明:
LKlight vs LightDock-Rust:算法同源,但 LKlight 修复上游 Rust 基线问题,补齐 VDW/SD/PISA/SIPPER/TOBI/DDNA 等能力,并通过 rayon 并行和热路径优化显著提速。
LKlight vs ColabFold:定位不同。LKlight 是传统基于物理/统计势的 PPI 对接;ColabFold 是深度学习结构预测。ColabFold 可生成初始复合物结构,LKlight 可做后续精细化对接。
互补使用:支持 ColabFold 生成复合物 → LKlight 精化 → 综合分析
4.4.1 搜索算法与搜索空间
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.4.2 评分函数详细对比
(1)LightDock v0.9.4 (Python) 支持的评分函数(lightdock3 --listscoring实际输出):
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
评分函数包括:fastdfire / dfire / dfire2 / pisa / mj3h / tobi / cpydock / pydock / vdw / dna / sipper / ddna。
ddna 用于 DNA-DNA 体系,需手动选择;sipper 和 ddna 在标准残基以外(如 CYX/HID)时可能报 KeyError,属设计限制。
(2)LightDock-Rust 支持的评分函数(历史基线,_RUST_SCORING_SUPPORTED源码定义 + data/目录验证):
|
|
|
|
|---|---|---|
dfire |
dfire |
|
fastdfire |
dfire |
|
dfire2 |
dfire2 |
|
dna |
dna |
|
mj3h |
mj3h |
MJ_potentials.dat) |
pydock |
pydock |
|
cpydock |
pydock |
|
(3)LKlight v1.0 支持的评分函数 / 命令行方法名:
|
|
|
|---|---|
dfire |
|
fastdfire |
dfire
|
dfire2 |
|
dna |
|
pydock |
|
cpydock |
|
sd |
|
vdw |
|
mj3h |
|
pisa |
|
sipper |
|
tobi |
|
ddna |
|
LKDock 评分自动选择逻辑(_ppi_get_scoring_function()): – protein-dna/ protein-rna→ dna– 其他所有类型(protein-protein / protein-peptide / membrane) → fastdfire
4.4.3 PPI 引擎运行速度对比(官方基准数据)
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
-c 8), 同上 |
|
|
|
|
|
|
|
|
|
|
|
|
290 ms/swarm | 3.0× vs Python / 26.5× vs Rust 上游 |
|
|
|
|
33 ms/swarm | 25.5× vs Python |
|
|
|
|
44 ms/swarm | 19.2× vs Python / 163× vs Rust 上游 |
|
|
|
|
46 ms/swarm | 16.5× vs Python / 307× vs Rust 上游 |
|
|
|
|
|
|
|
|
|
|
|
|
|
说明:LightDock/LKlight 运行时间与 swarms 数、glowworms 数、steps 数成正比。LKlight 的表中数据为单 swarm benchmark;完整任务耗时还取决于 swarm 数、外层并行、后处理与 I/O。ColabFold 时间主要取决于序列长度和 MSA 搜索。
4.4.4 PPI 对接参数对比
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
12 类/13 方法名 |
|
|
|
|
|
|
af_random_seed) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
--membrane |
|
|
|
|
|
--cores |
|
lklight_concurrency/ rayon |
|
|
|
|
|
|
alphafold2_multimer_v3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
五、口袋预测工具
口袋预测功能仅在 LKDock v3.0 中引入。
5.1 P2Rank(改)
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能: 从蛋白 3D 结构预测配体结合口袋;基于溶剂可及表面点的机器学习分类;支持 RandomForest 模型(random_forest_v4,sklearn);支持启发式打分(heuristic_v5,无需 sklearn);交叉验证评估 – 输出口袋中心坐标、残基列表、可信度评分。
算法:表面点采样:在蛋白溶剂可及表面和内腔生成候选点;特征提取:每个点计算局部特征(原子密度、极性/非极性比例、B-factor、二级结构、深度、DFG 相邻性等);分类:RandomForest 对每个点打分(配体结合概率);聚类:对高分点进行空间聚类(半径 cluster_radius);排序:按聚类内得分总和排名输出 top-N 口袋 ;v4 新增特征:pocket_depth(RF特征#1)、dfg_adjacent、hinge_backbone_score、gatekeeper_small、nucleic_complex_filter; v4b 改进:分层交叉验证、内腔裂缝采样(project_interior_points())
5.2 fpocket(改)
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
功能: 基于几何方法的快速口袋检测 ;Voronoi 分割 + Alpha 球过滤;输出口袋 PDB/PQR/JSON/info 多种格式 ;持体积(蒙特卡洛)、凸包、SASA 计算
算法:Voronoi 镶嵌:对蛋白原子坐标进行 Delaunay 三角剖分 ;Alpha 球筛选:提取外接球半径在 [fpocket_min_alpha_radius, fpocket_max_alpha_radius]范围内的 Delaunay 四面体顶点;过滤:去除远离蛋白原子的球(fpocket_max_dist_to_protein),保留符合极性条件的球 ;聚类:对 alpha 球进行空间聚类(fpocket_min_cluster_size);口袋表征:计算每个聚类的体积、SASA、极性比例、平均 B-factor 等描述符;排序:综合打分后输出。
5.3 口袋预测对比总表
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
对比说明:
P2Rank(改) 依赖 scikit-learn,在有训练数据时精度更高(v4b top1_hit_rate_4Å = 0.5),但需要预训练 RF 模型
fpocket(改)纯几何方法,无需训练,速度快,适合快速筛查 ;两者均完全内嵌无外部二进制依赖 ;通过 对接配置中 backend参数切换
5.3.1特征/描述符对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.3.2性能/准确率对比
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.3.3口袋预测工具深度对比
-
P2Rank(改)完整流程:
1. 解析蛋白结构(PDB/MMCIF)→ 提取蛋白原子
2. 溶剂可及表面点采样 + 内腔裂缝采样(project_interior_points)
3. 每个候选点计算 ~20 维局部特征:
- atom_density_close(近距离原子密度)
- atom_density_mid(中距离原子密度)
- polar_ratio(极性原子比例)
- aromatic_ratio(芳香原子比例)
- bfactor_mean(平均 B-factor)
- secondary_structure_score(二级结构评分)
- pocket_depth(口袋深度,v4 新增,RF 特征 #1)
- dfg_adjacent(DFG 基序邻近度,v4 新增)
- hinge_backbone_score(铰链区骨架评分,v4 新增)
- gatekeeper_small(看门人残基小型化,v4 新增)
- nucleic_complex_filter(核酸复合物过滤,v4 新增)
- shell_3_0 / shell_5_0 / shell_8_0(不同半径壳层原子数)
- ...
4. RandomForest 分类器打分(random_forest_v4 模型)
或 heuristic_v5 启发式打分(无 sklearn 时的备选)
5. 空间聚类(cluster_radius=3.5Å, min_cluster_size=7)
6. 口袋重排序指标:
- 聚类内得分总和
- zscore_threshold 过滤(-0.3)
- prefer_deep_pocket 深口袋偏好
- extended_pocket_cutoff 扩展口袋截断
7. 输出 top-N 口袋:中心坐标、盒子大小、残基列表、可信度
8. 可选:structure_profile.json/csv, residue_level.json/csv, view_pockets.pml/.cxc
-
fpocket-(改)完整流程:
1. 解析蛋白结构(PDB/MMCIF)→ 提取蛋白原子
2. Delaunay 三角剖分(scipy.spatial.Delaunay)
3. 计算每个四面体的外接球(circumsphere)
4. Alpha 球筛选:
- 半径范围:[fpocket_min_alpha_radius, fpocket_max_alpha_radius](默认 3.4-6.2Å)
- 距蛋白原子距离:≤ fpocket_max_dist_to_protein
- 极性/非极性分类(基于顶点原子电负性)
5. 聚类(层次聚类,fpocket_clustering_method=single-linkage)
- fpocket_cluster_distance=2.4Å
- fpocket_min_cluster_size=15
6. 口袋构建(_fp_build_pockets):
- 残基分配(alpha 球近邻蛋白原子所属残基)
- MC 体积估算(fpocket_iterations_volume_mc=300)
- 凸包体积
- SASA 计算(极性/非极性分解)
- Alpha 球密度过滤(min_as_density=0.7)
7. 标准化 + 综合打分 + 排序
8. 输出:PDB/PQR/JSON/info 多种格式
5.3.4口袋预测配置参数完整对照
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.3.5 盒子生成功能对比
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
六、各版本引擎集成一览
v1.0 引擎目录结构
./vina # AutoDock Vina 可执行文件(内置)
v2.0 引擎目录结构(./engine/)
engine/
├── vina127 # Vina 1.2.7
├── vina_split127 # Vina Split 1.2.7
├── smina # Smina (conda 安装)
├── Vina-GPU/ # Vina-GPU 1.0
│ ├── Vina-GPU.exe
│ ├── Vina-GPU-K.exe
│ ├── Kernel2_Opt.bin
│ └── OpenCL/
├── Vina-GPU+/ # Vina-GPU+ (v2.0系列)
│ ├── Vina-GPU+.exe
│ └── OpenCL/
├── Vina-GPU2/ # Vina-GPU 2.2
│ ├── Vina-GPU-v2.2.exe
│ ├── Kernel1_Opt.bin
│ ├── Kernel2_Opt.bin
│ └── OpenCL/
├── QVina2-GPU/ # QuickVina2-GPU
│ ├── Qvina2_GPU.exe
│ ├── Kernel2_Opt.bin
│ └── OpenCL/
└── QVina-W-GPU/ # QuickVina-W-GPU
├── QVina-W-GPU.exe
├── Kernel2_Opt.bin
└── OpenCL/
v3.0 引擎目录结构(./engine/)
继承 v2.0 全部引擎,新增:
engine/
├── [v2.0 全部引擎...]
├── Uni-Dock _* # Uni-Dock 跨平台二进制
├── UniDock-Pro_* # UniDock-Pro 跨平台二进制
├── LK-UniDock/ # Uni-Dock / UniDock-Pro 补丁源码与预编译发行包
└── LKina # 金属 + 共价对接核心引擎
LKLight/ # PPI 引擎(独立目录)
LKlight / ColabFold / LKina系列引擎可按平台自行下载、源码编译或通过配置项指定路径。