 夜雨聆风
夜雨聆风





AI学习小结:readwise + Obsidian + LLM”构建生长型个人知识库实用指南
每天,我们都会遇到值得保存的内容:一篇深度文章、一段书摘、一份PDF 报告、一个播客观点。点下“收藏”“高亮”“稍后读”的瞬间,我们会产生一种轻微的安心感,好像知识已经进入了自己的系统。但真正需要写作、研究或表达时,却常常想不起那句话在哪里,更说不清它和当前问题有什么关系。
这就是传统收藏和传统笔记的失效点:它们解决了保存问题,却没有解决生长问题;它们制造了信息库存,却没有形成思考结构。
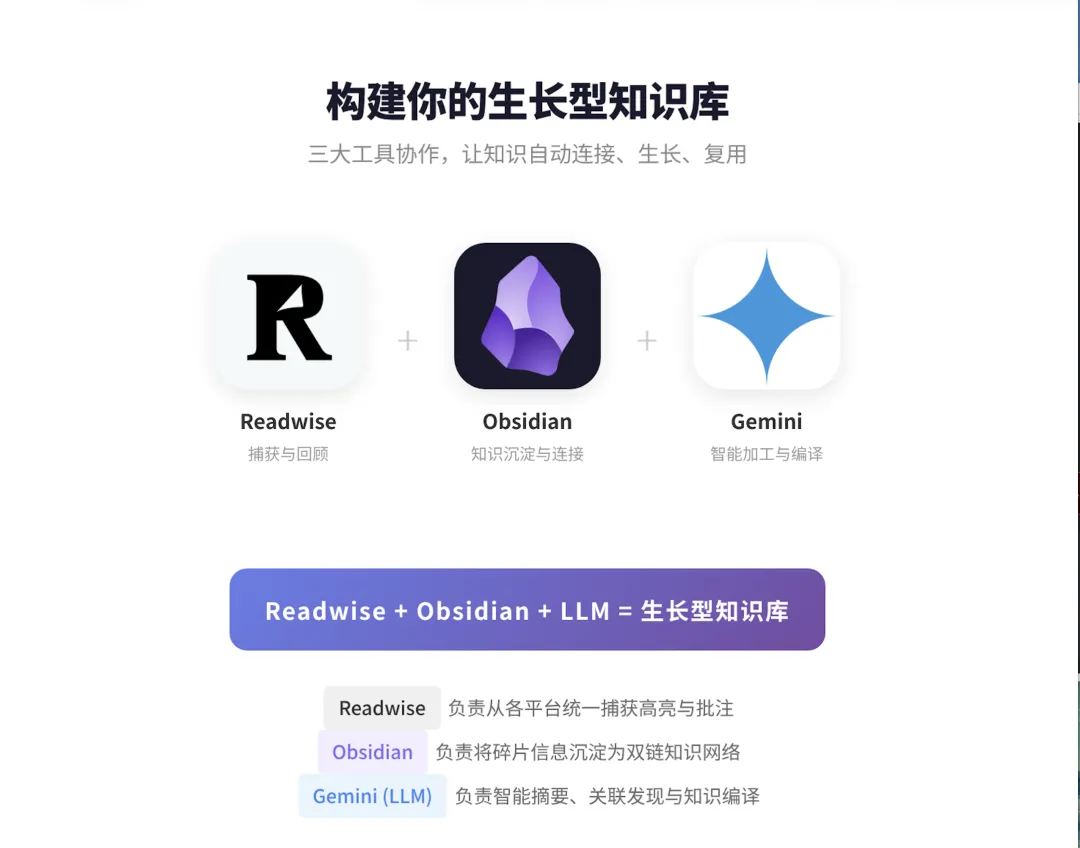
本文讨论的不是某个软件的炫技玩法,而是一套更稳定的知识工作流:如何用Readwise + Obsidian + LLM,把日常阅读中的碎片信息,逐步转化为可以长期复用、持续演化的个人知识网络。这几个应用组合在一起,旨在基于工作流,构建一条专属于自已的知识、信息、数据的河流,持续流入,通过沉淀,加工,转化为知识体系的一个部分,源源不断,持续进化。
一、为什么传统收藏/笔记方式失效了?
传统收藏有一个隐含假设:只要把信息保存下来,未来就能用上。但在真实场景里,信息不会因为被保存就自动变成知识。知识产生的关键不是“存储”,而是理解、重述、连接与调用。
很多人的笔记系统更像仓库:内容不断搬进去,却很少被重新整理;标签越来越多,但真正检索时并不可靠;文件夹层级越来越复杂,却无法回答一个具体问题。更麻烦的是,当信息来源从书籍扩展到网页、RSS、PDF、播客、视频和社交媒体后,入口越来越分散,格式越来越混乱,注意力也被切得越来越碎。
|
常见做法 |
表面收益 |
深层问题 |
|
把文章放进收藏夹 |
保存速度快 |
很少复读,也难以调用 |
|
大段复制到笔记软件 |
信息看似完整 |
没有经过自己的理解 |
|
用文件夹分类 |
结构清楚 |
一个知识点只能放在一个位置 |
|
临时让LLM 总结 |
即时效率高 |
如果不沉淀,答案很快消失 |
所以,真正的问题不是“你有没有笔记软件”,而是你有没有一条从输入到输出的知识生产链路。
二、什么是“生长型”知识库?
所谓生长型知识库,不是把所有资料放在一起,也不是追求一个永远完美的分类系统。它更像一片持续演化的知识生态:新信息进入后,会被拆解成知识种子;知识种子会被加工成原子化节点;节点之间通过概念、问题、场景和项目不断连接;最后,这些连接会在写作、研究、表达和决策中被调用。
生长型知识库的本质,是让笔记从“信息容器”升级为“思考基础设施”。
传统笔记更关注“我记录了什么”,生长型知识库更关注“这条记录能否在未来参与思考”。前者的单位是文章、书籍、文件夹;后者的单位是观点、问题、模型、案例和可复用结构。前者追求保存完整,后者追求连接有效。
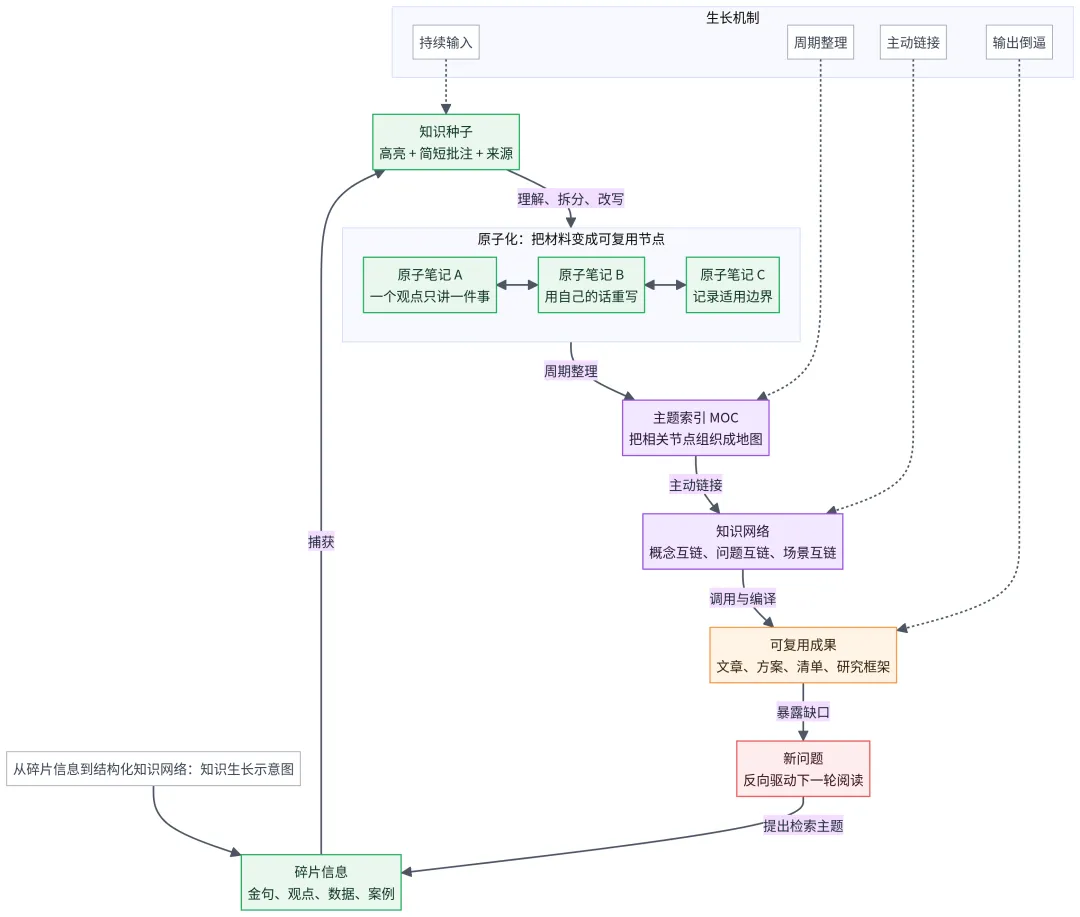
一个会生长的知识库,通常具备四个特征:稳定输入、渐进加工、主动链接和输出检验。它允许知识分阶段成熟,而不是要求每次阅读都立刻产出完美笔记。
三、三大组件:各自负责什么?
这套工作流之所以有效,是因为三个工具承担了不同层级的任务。Readwise 负责捕获,Obsidian 负责沉淀与连接,LLM 负责理解增强与编译辅助。它们不是彼此替代,而是形成接力。
|
组件 |
核心角色 |
主要价值 |
|
Readwise |
信息捕获与高亮同步 |
把多来源摘录统一带入知识库 |
|
Obsidian |
双链笔记与知识网络 |
让笔记之间形成语义连接 |
|
LLM |
智能辅助与知识编译 |
帮助摘要、追问、改写、发现关联 |
Readwise的价值在于让“捕获”尽量无摩擦。其官方文档说明,Readwise 的Obsidian 插件可以把新高亮同步到Obsidian;如果是同一本书或同一篇文章中的新高亮,内容会追加到已有页面底部,并且不会覆盖用户在Obsidian 中已经做过的编辑。1
Obsidian的价值在于链接。Obsidian 官方帮助文档提到,通过内部链接可以把笔记连接起来,从而创建知识网络。2图谱视图则用节点和连线展示笔记关系,帮助使用者观察某个主题在知识库中的连接状态。3但图谱不是目的,真正重要的是:当你写下一条笔记时,会自然追问“它应该连接到哪里”。
LLM的价值在于降低知识加工的阻力。它可以帮助你把长文压缩成要点,把多条笔记整理成框架,把模糊想法改写成更清晰的问题。但要注意,LLM 不是知识库本身。它更像一位临时研究助理,真正决定知识质量的,仍然是你提出的问题、选择的材料和最后的判断。
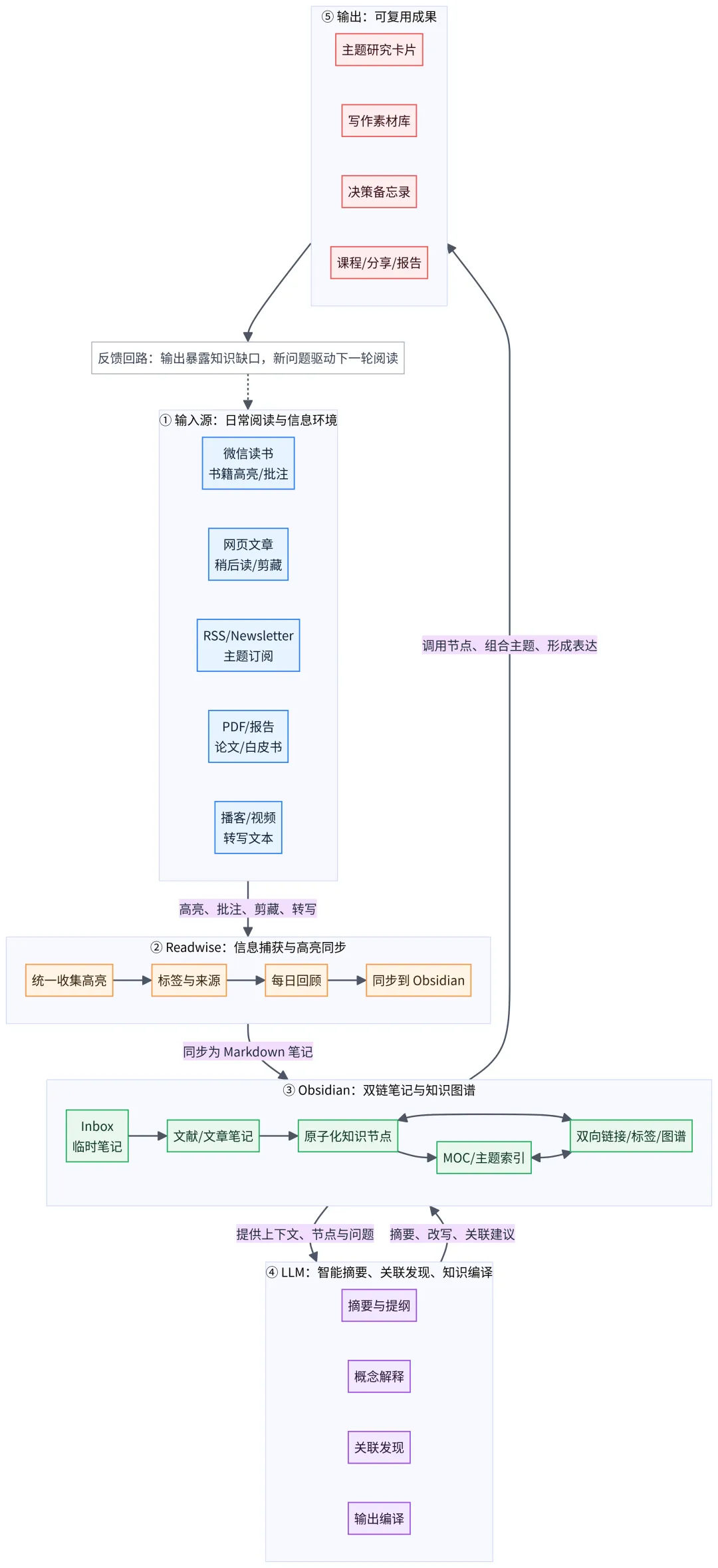
四、完整工作流:从阅读到可复用知识节点
假设你读到一篇关于“深度工作与注意力管理”的文章,里面有几个观点让你很受启发。
第一步是在阅读现场捕获信息。不要急着复制全文,只高亮真正触动你的句子,并写下一两句即时批注。高亮是作者的语言,批注才是你与材料发生关系的起点。
第二步是通过Readwise 同步到Obsidian。同步后的内容可以先进入Readwise/Articles或Inbox/Highlights。此时不必过度整理,只要保证标题、来源、链接、日期和标签清楚。对多数人来说,知识库崩溃的原因不是整理太少,而是整理标准太高,导致系统无法持续运行。
第三步是在Obsidian 中做二次加工。打开同步笔记后,先用自己的话写一个简短摘要,再把真正有价值的观点拆成独立笔记。例如,原文说“注意力不是时间管理问题,而是环境设计问题”,你可以改写成:
当一个人反复无法进入深度工作状态时,问题未必是意志力不足,而可能是环境中的默认选项过于分散。注意力管理的关键,是减少低价值选择自动出现的机会。
这条笔记已经不再只是摘录,而是一个可复用判断。接下来,你可以把它链接到[[注意力管理]]、[[工作环境设计]]、[[默认选项]]、[[行为改变]]等主题。这样,它未来就不只属于原文章,而是进入了你的知识网络。
第四步是引入LLM 做辅助加工。你可以把文章摘要、自己的批注和几条原子笔记提供给LLM,让它回答三个问题:这组材料能归纳出哪些核心概念?它和我已有的哪些主题可能相关?如果我要写一篇文章,还缺少哪些论据和案例?
一个实用提示词可以这样写:
请基于以下笔记,提炼3 个核心观点,指出它们分别可以连接到哪些相邻主题,并提出5 个值得继续追问的问题。请不要扩写成文章,而是以知识库整理为目标,帮助我发现结构、边界和缺口。
第五步是形成主题索引。随着相关笔记增多,你可以建立一个注意力管理MOC。MOC 可以理解为某个主题下的知识地图,不必复杂,只要列出关键问题、核心概念、代表案例、反方观点和输出方向即可。
|
MOC 模块 |
可以放入的内容 |
作用 |
|
核心问题 |
为什么注意力越来越稀缺? |
定义研究范围 |
|
关键概念 |
深度工作、环境设计、默认选项 |
建立概念骨架 |
|
相关案例 |
个人工作流、团队会议、信息订阅 |
连接现实场景 |
|
输出方向 |
文章、清单、分享、研究框架 |
让知识进入应用 |
到这一步,一篇文章已经不再是一条孤立收藏,而是变成了可复用的知识节点,并且进入了更大的主题网络。
五、运行一段时间后的真实感受
这套系统真正跑起来以后,最明显的变化不是“笔记变多了”,而是思考过程变得更可见了。
过去读完一篇好文章,留下的常常只是“我好像懂了”。现在,你会更清楚地知道:我从这篇文章中拿走了哪几个观点?这些观点和我已有的哪些问题有关?它们未来可以用于什么场景?如果一个观点无法被改写、链接和调用,它可能只是短暂共鸣,而不是可沉淀的知识。
第二个变化是复利开始出现。单条笔记价值有限,但当几十条笔记围绕同一主题形成连接后,写作和研究会明显变顺。你不再从空白文档开始,而是从一组已经被理解、分类、链接过的节点开始。输出不再是临时“憋文章”,而是对已有思考的重新编译。
第三个变化是信息焦虑会下降。稳定的工作流会带来秩序感:看到好内容时先捕获,有时间再加工,遇到项目时再调用。你不必要求自己当场消化一切,因为系统允许知识逐步成熟。
第四是不再追求一个完美的系统。构建知识库的过程,就是一个边干边思考边迭代的过程。这些工具大部分支持充分“自定义”。因此,给自我创新提供了更多空间。另外,将学习融在工作流中是一个很好的体验,比如订阅一些英文的源,一边点亮一边通过LLM 解析,这个过程象我这样的英文菜鸟也在不知不觉中进步了。
六、一个可直接上手的最小配置
如果刚开始搭建,不建议一上来就设计复杂目录。可以先用一个最小系统跑两周。
|
模块 |
建议配置 |
使用原则 |
|
Readwise |
连接主要阅读来源,同步高亮 |
只捕获真正值得复看的内容 |
|
Obsidian |
Inbox、Sources、Notes、MOC、Outputs |
文件夹少一点,链接多一点 |
|
标签 |
#待整理、#概念、#案例、#问题 |
标签服务检索,不代替思考 |
|
LLM |
摘要、提问、关联、反驳、改写 |
辅助结构化,不替代判断 |
|
周期复盘 |
每周整理5—10 条笔记 |
小步快跑,比大整理更重要 |
最小工作流可以概括为一句话:读到好内容,先高亮;同步到Obsidian 后,改写成自己的原子笔记;用双链连接到相关主题;必要时让LLM 帮你提炼、追问和编译;最后通过输出检验它是否真的有用。
结尾:知识库不是目的,思考力的提升才是
个人知识库最容易让人上瘾的地方,是它看起来可以无限优化。你可以不断调整文件夹、模板、标签、插件和自动化脚本。但如果这些优化没有带来更清晰的问题意识、更稳定的输出能力和更深的判断力,它们就只是另一种形式的信息消费。
真正值得追求的,不是拥有一个漂亮的知识库,而是拥有一个能陪你长期思考的系统。Readwise 负责把阅读中的火花留下来,Obsidian 负责让火花彼此连接,LLM 负责帮助你看见结构和缺口。最后,真正让知识生长的,仍然是你一次次主动提问、改写、链接和输出。
愿你的每一条高亮,都不只是被保存,而是开始生长。从数据到知识到智慧,完成一次又一次的迭代与升华。(注:LLM可以样化接入,比如read是自带gpt的。而obsidian 可以根据需要对接不同LLM 的 API.)