 夜雨聆风
夜雨聆风





OpenClaw 进阶配置:extraPaths 与 sessionMemory 完整避坑指南
前两天有个朋友问我,他在用 OpenClaw 搭一个长期对话的智能体,但发现一个问题:
它默认只能”记住”两个文件 —— MEMORY.md 和 memory/*.md。
那他放在团队 Wiki 里的资料、上周在另一个会话里聊过的细节,怎么办?
答案藏在配置文件里两个看起来人畜无害的小开关上,叫 extraPaths 和 sessionMemory。
但”人畜无害”,只是它们没被打开的时候。

先看几个不大不小的数字
打开它们之前,有几个数据值得心里有数:
-
默认检索范围:只有 2 个路径 -
索引切片:每段约 400 tokens ,相邻 chunk 重叠 80 个 token -
文件监控防抖:约 1.5 秒– multimodal 启用:必须同时满足 3 个条件 -
已知 GitHub issue:至少 4 个 仍在挂着 -
多 agent 共享同一份文档时:可能产生 N × M 份 重复 embedding(这个我们后面再说)
OK,先收着,进入正题。
默认只读 2 个文件,你的团队 Wiki 它一个字也看不到
OpenClaw 的记忆系统结构其实挺优雅。
短期记忆放 memory/*.md,每天写日记、记台账。
长期记忆放 MEMORY.md,由系统通过梦境(Dreaming)筛选后晋升进来,沉淀真正稳定的事实和偏好。
听起来很完整。但默认情况下,它就只索引这两个路径下的内容。
也就是说,你电脑里其他笔记、Notion 导出的 Markdown、团队共享的 Wiki,OpenClaw 全都视而不见。
要让它”看见”这些东西,得手动告诉它:”喂,这边还有几个目录也算。”
这就是 extraPaths 这个配置项的事。
extraPaths:与其说它是开关,不如说是个”喂料口”
很多人第一次看 extraPaths,以为它是另一套独立的检索机制,专门处理外部文件。
其实并不是。
它只是”额外纳入索引的路径”。真正检索时,仍然走 memory_search 同一套管线,跟默认的 MEMORY.md 一视同仁。
可以这么理解:
extraPaths 目录/文件
↓
递归扫描所有 .md
↓
切成 chunks(约 400 tokens,相邻 80 重叠)
↓
写入 per-agent SQLite 索引
↓
查询时与默认记忆混在一起检索
所以它影响的是检索的”范围”,不是检索的”方法”。
配置写起来也很朴素:
{
"agents": {
"defaults": {
"memorySearch": {
"extraPaths": ["../team-docs", "/srv/shared-notes"]
}
}
}
}
支持的写法有四种:相对目录、绝对目录、glob 模式(如 ~/notes/**/*.md),以及具体某一个文件。
听起来很直白对吧?是直白。但坑也就藏在这种”看起来直白”的地方。
你以为是一个开关,其实有四个坑
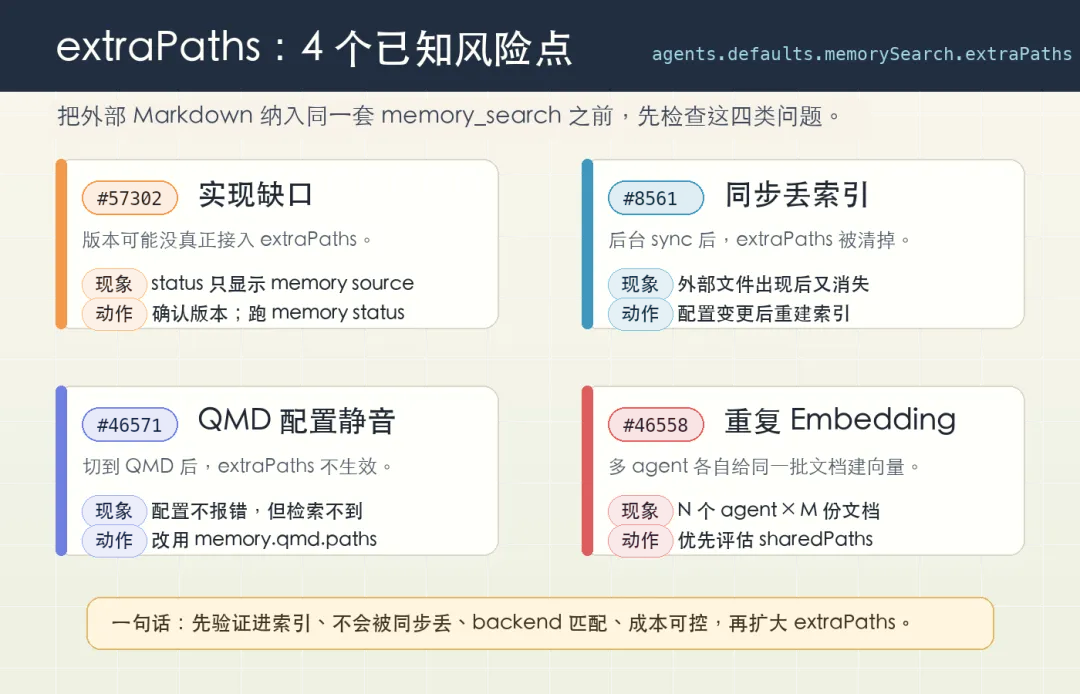
GitHub 上跟 extraPaths 相关的 issue,目前至少有 4 个 还挂着,每一个都很值得提前知道。
第一个, #57302 :在某些版本里 extraPaths 文档说支持,但代码里其实没真正实现。openclaw memory status 跑出来只显示一个 “memory” source,连你配的额外路径根本不显示。
第二个, #8561 :你手动跑一次 openclaw memory index 索引是有的,但后台 sync 跑一次又把这些 extraPaths 文件全 drop 掉。每次配置变更后得手动重建索引。
第三个, #46571 :如果你切到了 QMD backend(一个增强的本地检索引擎),memorySearch.extraPaths 直接被忽略。要改用 memory.qmd.paths 配置。
第四个最有意思, #46558 :
如果你在 agents.defaults.memorySearch 里配了 extraPaths,那么你有几个 agent,每个 agent 就会独立把这堆文件 embedding 一遍。
也就是 N 个 agent × M 份文档 = N × M 份 重复的向量。
API 计费的话,钱就是这么烧出去的。
修复方案是用 sharedPaths(PR #46542 引入),让多 agent 共享同一份索引。但这条路径在文档里讲得比较隐蔽,不专门挖一下的人很容易跳进同一个坑。
切到 QMD backend?这个开关直接静音
刚才提到了 QMD,多说两句。
OpenClaw 的检索引擎是可以换的:
-
默认是 builtin(轻量、内置) -
增强版是 QMD(更强但更重,需要单独装)
切到 QMD 之后,memorySearch.extraPaths 不会报错,但完全失效。它不会告诉你”嘿你这个配置我不认识”,只是默默不工作。
正确做法是改用 memory.qmd.paths:
{
"memory": {
"backend": "qmd",
"qmd": {
"paths": [
{ "name": "docs", "path": "~/notes", "pattern": "**/*.md" }
]
}
}
}
QMD 把这些路径当 collection 管理,根据你设置的 searchMode(search / vsearch / query)选择不同的检索方式。
总之记住一句话:同一个路径配置,在两个 backend 下走的不是同一条流水线。
sessionMemory:那行小字漏了,你白配半天
讲完 extraPaths,再来看另一个开关 sessionMemory。
这个比前一个更隐蔽。它属于 experimental 节点下的实验性参数,作用是:
让记忆检索从”只查笔记”扩展到”笔记 + 完整聊天历史”。
什么意思?
默认情况下,OpenClaw 检索时只看你写下来的笔记文件。如果你之前在某次会话里口头说过一些内容、但没人主动落盘成 memory,那它就搜不到。
打开 sessionMemory,它就能把所有历史 session 的聊天记录也纳入进来。
听起来很爽。配置看起来也很简单:
{
"experimental": { "sessionMemory": true }
}
但这里有个特别容易漏掉的点。
光配 sessionMemory: true 是不够的,还得加一行 sources: ["memory", "sessions"],否则一点效果都没有。
完整版长这样:
{
"agents": {
"defaults": {
"memorySearch": {
"experimental": { "sessionMemory": true },
"sources": ["memory", "sessions"]
}
}
}
}
两个字段缺一不可。文档里这一行小字写得相当含蓄,很多人配完以为生效了,跑半天结果发现完全没用上。
想打开 sessionMemory?先想清楚代价
实验性 + 数据量大 + 拖慢检索 —— 这三个属性叠在一起,意味着 sessionMemory 不是”能开就开”的开关。
它适合:
-
用户经常说”还记得我们之前聊的……”的场景 -
项目跨会话周期长、短期记忆没及时升格的场景 -
调研类工作,需要回查历史讨论原文的场景
但代价也明确:
-
历史 session 通常体量很大,检索会显著变慢 -
实验性功能,稳定性不如核心检索链路 -
数据越多,向量索引越重,机器吃力
如果决定打开,建议同步做这几件事:
-
关掉 multimodal(数据量再叠加一层易超时) -
把 query.hybrid.candidateMultiplier从默认 4 下调到 2 或 3 -
用 openclaw memory status --deep监控索引大小和耗时
话说回来,memory_search 到底是谁在调?
聊到这有个挺关键的细节,是很多人配完 extraPaths / sessionMemory 之后没意识到的。
OpenClaw 的记忆检索 —— 也就是那个叫 memory_search 的工具调用 —— 它 不是 runtime 自动跑的 。
不是说你配了 extraPaths,每次对话 OpenClaw 就在背后悄咪咪查一遍。
真正的逻辑是这样:当你启用了 memory-core 这类记忆插件,Agent 的工具列表里会多出来两个工具 —— memory_search 和 memory_get。然后由 Agent(也就是主模型)在回答你的问题时, 自己判断 “我现在需不需要查一下记忆”,需要就调,不需要就不调。
换句话说:
能不能查到,看你怎么配;要不要查,看模型怎么想。
什么时候模型会主动去调?常见的几种语义:
-
“之前我们说过什么?” -
“按我的偏好来” -
“继续上次那个方案” -
“我之前让你记住过什么?”
也就是说,问题里得有那么点”暗示”,模型才会自觉去翻记忆。
如果你只是说”帮我写个 Python 脚本”,模型大概率就直接写了,不会去查你之前的记忆 —— 哪怕你的记忆里恰好有相关偏好。
用户明确指令也是同一条路 。比如你说”查一下记忆里关于 extraPaths 的内容”,技术上仍然是 Agent 听懂了你的话之后 主动调用memory_search,并不是 runtime 强制触发。区别只是”模型听懂的概率会高很多”。
理解这个机制,就能解释一些常见的困惑:
-
配了 extraPaths,但聊天时模型好像没用上? → 大概率是模型没判断出来要查 -
总觉得”召回率低”? → 一半是检索本身的问题,另一半是模型压根没去触发
那有没有办法让它每轮都查一下?
有,那就是 Active Memory 插件 —— 它就是那个 替你按按钮的人 。
但代价是什么?我们下一节正好聊到。
实测彩蛋:你 Active Memory 还开着吗?
这个坑我自己踩过,单独拎出来说一下。
如果你在打开 extraPaths 或 sessionMemory 之后,发现每次响应都慢得离谱、明显比之前卡,先别急着怪检索本身 —— 大概率是 Active Memory 插件在背后拖后腿。
原因藏在一个不起眼的配置里:active-memory.config.model。
如果你没单独配它,按 OpenClaw 的规则,它会 默认继承你当前会话用的主模型 。问题在于,你聊天用的主模型通常是性能挺重的那一档,但 Active Memory 干的活其实是”轻量记忆判断” —— 这俩根本不是一个量级的需求。
更要命的是,Active Memory 单次响应的链路长得吓人:
启动子 agent
↓
调主模型做记忆判断
↓
工具调用(多半还得搜一轮 memory)
↓
总结输出
每一步都在用一个”杀鸡用牛刀”的模型跑。再叠上 extraPaths 扩出来的索引规模,或者 sessionMemory 多出来的会话历史,链路一下子就被拉长。
我自己的实测体感是:同样一句问候,开 Active Memory 和不开,响应时间能差出 好几倍 。
所以一个挺实用的建议是:
想充分用上
extraPaths或sessionMemory,最好先把 Active Memory 插件关一下,或者单独给它配一个轻量模型。
如果离不开 Active Memory,就务必给它单独指定一个便宜的小模型(比如某个 7B 级别的本地模型),别让它跟主对话共用同一个”重型选手”。
顺便说说 multimodal 那个”三条件 AND”
聊到这里顺便提一句一个挺有意思的细节。
extraPaths 默认只索引 .md 文件。但如果你想让它也吃图片和音频,OpenClaw 提供了一个 multimodal 能力。
但启用这个能力,必须同时满足三个条件:
-
multimodal.memorySearch开启 -
embedding 模型必须是 gemini-embedding-2-preview -
fallback必须为"none"
少一个都不行。
而且更妙的是 —— 这个能力只对 extraPaths 生效。
也就是说:你给智能体喂图片,得从额外路径喂;想直接贴在主笔记 MEMORY.md 里?它依然视而不见。
满足全部条件后才能识别的格式有:
-
图片: .jpg/.jpeg/.png/.webp/.gif/.heic/.heif -
音频: .mp3/.wav/.ogg/.opus/.m4a/.aac/.flac
至于 .pdf / .docx / .xlsx / .json……当前文档没有承诺支持。所以想索引这些格式的同学,先转成 Markdown 吧。
真要打开?先把这四步顺序走完
如果看到这你还想用,建议按下面这四步渐进启用,别一次全开。
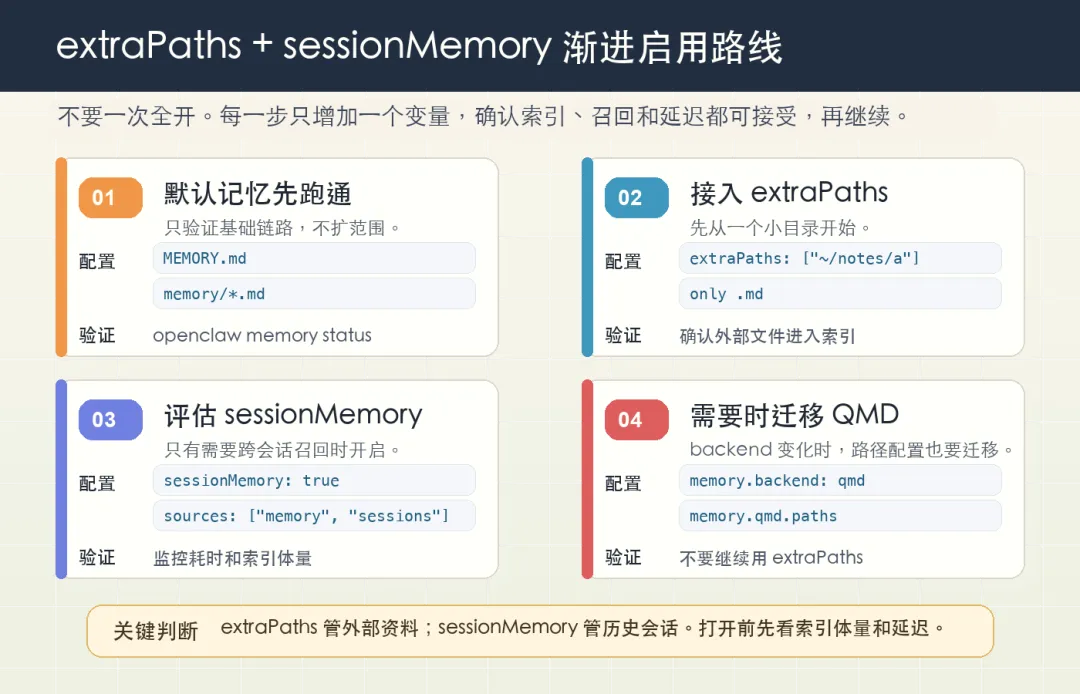
第一步:先按上一篇文章里的最小配置跑通。Ollama + qwen3-embedding:4b,hybrid 默认权重,extraPaths: [],sessionMemory: false。
确认基础检索能跑通,再往下走。
第二步:加 extraPaths。先指向一个小目录(比如 ~/notes 下的某个子目录),跑一下 openclaw memory status 确认真的纳入了索引、检索仍然快。
如果这步出事,多半是踩到了 #57302、#8561、#46571 这几个坑里的某一个 —— 翻一下 issue 描述,对症下药。
第三步:评估是否真的需要 sessionMemory。
如果你的智能体经常”差最后一里路”,比如明明聊过的内容但召回不到,再考虑打开。
打开时同步下调 candidateMultiplier、关掉 multimodal,避免几个重负载叠加。
第四步:考虑切到 QMD backend。
切的时候记得把 extraPaths 迁移到 memory.qmd.paths,否则两个开关会一起静音。
写在最后
extraPaths 和 sessionMemory 这两个配置,本质上解决的是同一个问题的两个侧面。
简单总结一下:
-
extraPaths解决的是「我的知识不止在 OpenClaw workspace 里」 -
sessionMemory解决的是「我以前在聊天里说过,但当时没主动记下来」
它俩看起来是两个独立的小开关,背后却是 OpenClaw 记忆系统在思考一个挺基础的问题:智能体的”记忆”到底应该到哪一层为止?
只到笔记?只到对话?还是把你电脑里所有可能相关的文档都吞下去?
这个边界往哪儿划,没有标准答案。
但有一点比较确定:打开它们之前能多读三分钟文档,大概率比打开之后再读节省两小时。
至少别让钱包和检索延迟,先你一步给出反馈。
参考链接
-
上一篇文章:OpenClaw 记忆系统:白天先记,晚上整理,回复前还能主动提醒