夜雨聆风
夜雨聆风





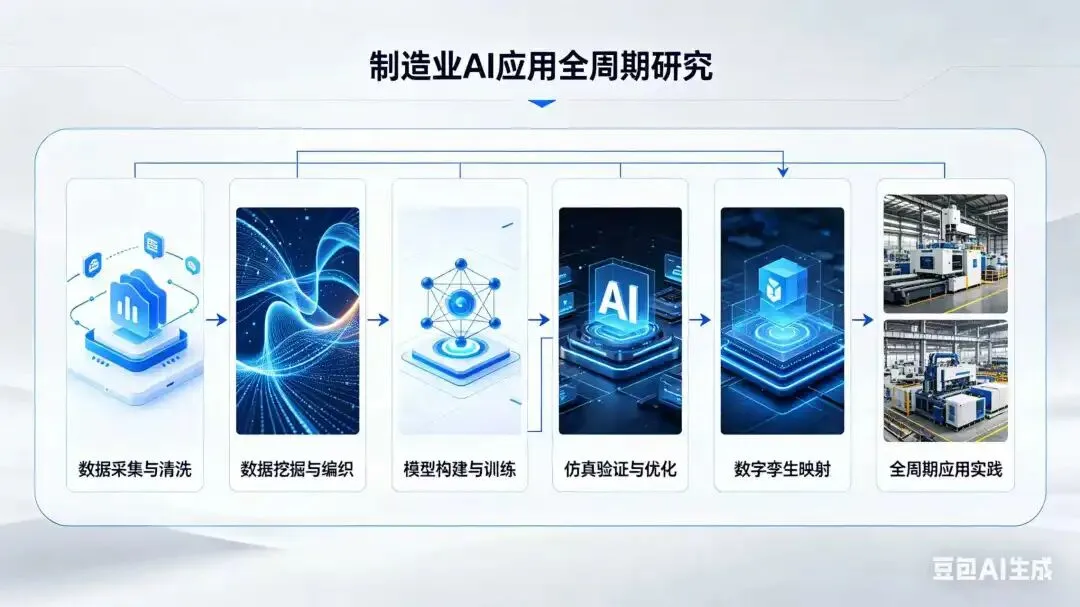
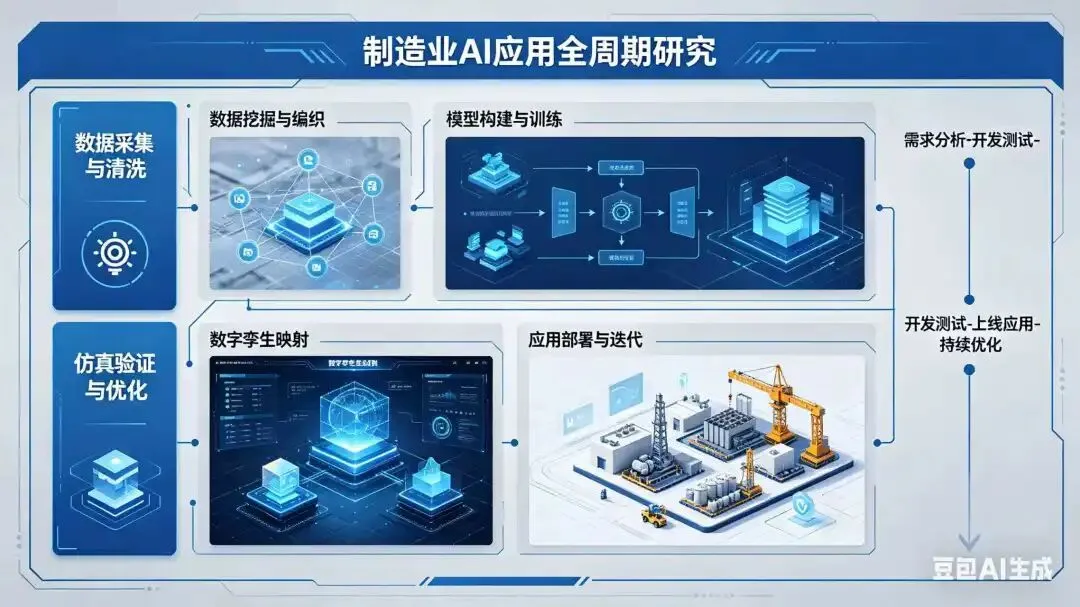
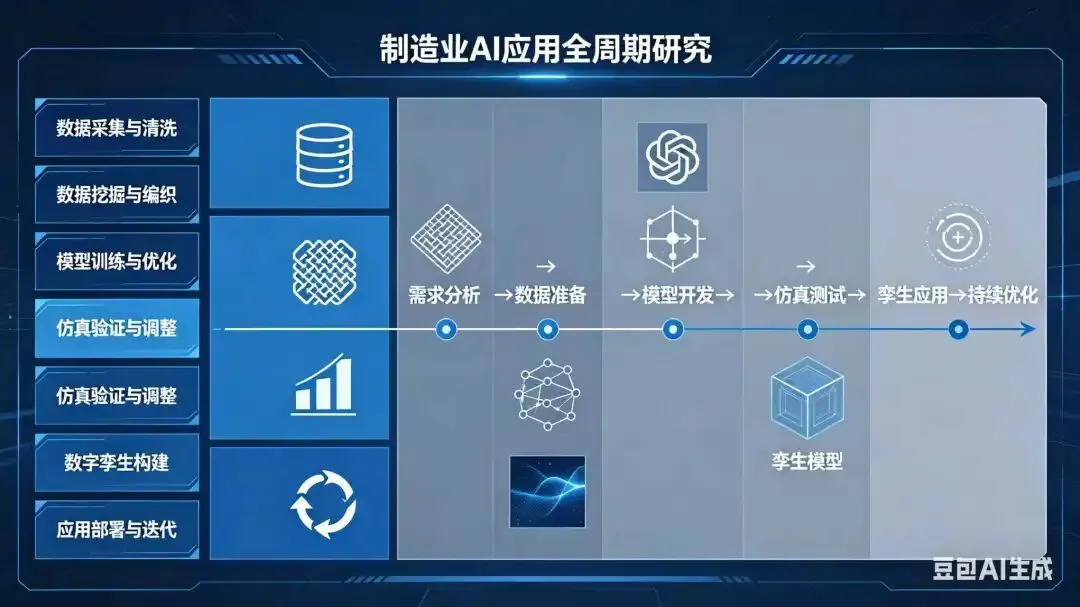
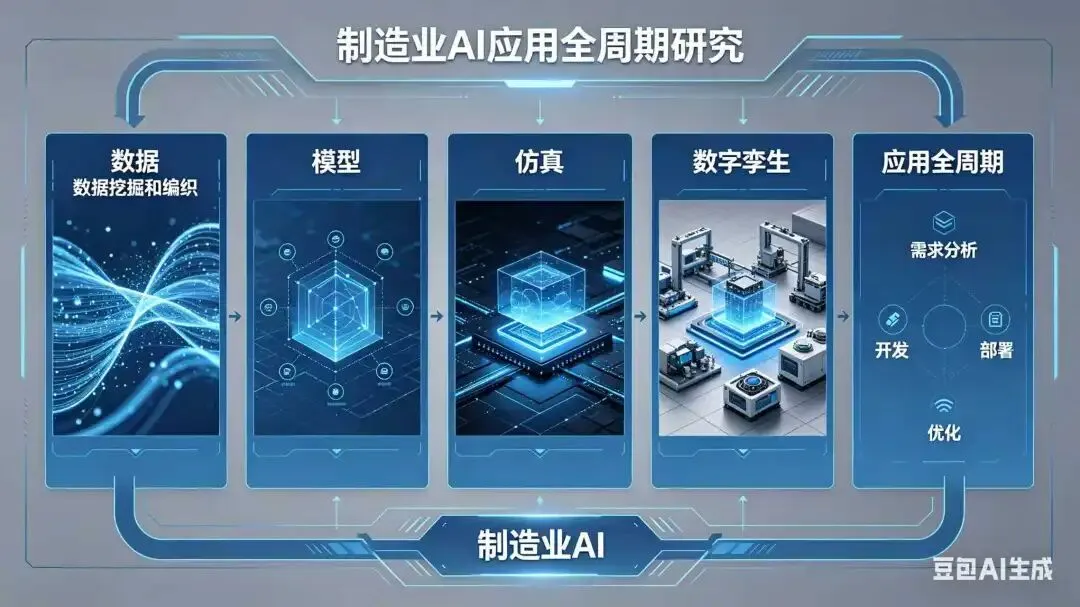
制造业AI、数据、数据挖掘和编织、模型、仿真、数字孪生、应用全周期研究
制造业AI、数据、数据挖掘和编织、模型、仿真、数字孪生、应用全周期研究
制造业正经历从“经验驱动”向“数据+模型+仿真+AI”融合驱动的深刻变革。在此背景下,数据挖掘(Data Mining)已不再是孤立的分析技术,而是嵌入于 “数据编织 → 模型构建 → 仿真验证 → 数字孪生 → 应用落地 → 反馈进化” 全生命周期的核心引擎。以下从 全周期视角,系统阐述制造业中 AI、数据、数据挖掘、数据编织、模型、仿真、数字孪生 的协同逻辑与实施路径。
一、整体框架:制造业智能应用全周期闭环
A[数据源(OT/IT/IoT)] –> B[数据编织(Data Fabric)]
B –> C[数据挖掘(模式发现)]
C –> D[模型构建(AI/机理)]
D –> E[仿真验证(Digital Twin)]
E –> F[应用部署(控制/决策)]
F –> G[反馈学习(MLOps)]
G –> B
核心理念:数据是源(燃)料,挖掘是探针,模型是大脑,仿真是试验场,孪生是镜像,应用是出口,反馈是进化力。
二、各阶段深度解析
1. 数据层:多源融合 + 数据编织(Data Fabric)
挑战:OT数据(毫秒级时序)、IT数据(结构化事务)、非结构化数据(图纸、日志、语义)割裂;老旧系统协议封闭(Modbus、Profibus),难以接入(新老系统融合难,老系统如何升级迭代到新系统问题)。
解法:数据编织架构
虚拟化集成:不移动数据,通过语义层统一访问(如Starburst、Denodo);边缘预处理:在车间侧完成数据清洗、压缩、特征提取;主数据对齐:统一物料、设备、工序编码,构建企业级本体(Ontology);数据血缘追踪:记录从传感器到报表的全链路。输出:逻辑统一、物理分布、按需服务的数据湖仓。
2. 挖掘层:从数据中发现隐藏价值(Data Mining)
制造业典型挖掘任务:
任务类型 方法 应用场景
关联规则挖掘 Apriori, FP-Growth “当原料A硫含量>0.5% 且 温度<300℃ → 产品B收率↓”
聚类分析 K-Means, DBSCAN 设备运行模式分类(高效/低效/异常)
异常检测 Isolation Forest, AutoEncoder 实时识别DCS参数突变、能耗异常
序列模式挖掘 PrefixSpan 故障前兆序列识别(振动↑ → 温度↑ → 停机)
因果推断 DoWhy, PC算法 区分“相关”与“因果”(如压力升高是因还是果?)
特色:结合领域知识:约束挖掘空间(如仅分析工艺窗口内数据);实时流挖掘:Flink + MLlib 实现秒级模式发现。输出:可解释的业务规则、预警信号、优化线索。
3. 模型层:机理与数据融合建模
建模范式演进:
范式 代表技术 适用场景
纯机理模型 Aspen Plus, ANSYS 已知物理规律明确(如流体力学)
纯数据驱动 XGBoost, Transformer 黑盒系统、高维非线性(如视觉质检)
混合建模 物理信息神经网络(PINN)
知识图谱+GNN 复杂制造(如反应器建模、设备RUL预测)
关键能力:小样本学习:利用仿真数据预训练;可解释性:SHAP/LIME + 因果图,满足工业审计要求;在线更新:支持边缘端增量学习。输出:高可信、可部署、可进化的智能模型。
4. 仿真层:安全验证与策略预演
作用:验证AI策略安全性(如“升温10℃是否超压?”);生成稀缺场景数据(如故障、极端工况);支持强化学习训练(RL Agent在仿真中试错)。
技术栈:多物理场仿真:COMSOL, ANSYS(高保真但慢);降阶模型(ROM):用AI加速仿真(如POD+DNN);离散事件仿真:AnyLogic, Simio(用于产线调度)。输出:虚拟验证报告、合成数据集、优化策略。
5. 数字孪生层:虚实映射与持续同步
制造业数字孪生 = 数据 + 模型 + 仿真 + 可视化
层级 内容 技术
几何孪生 3D设备/产线模型 Unity, NVIDIA Omniverse
行为孪生 动态响应(温度、振动) IoT + 实时模型
机理孪生 物理规律嵌入 PINN, 机理方程
决策孪生 优化建议生成 RL + 优化求解器
核心能力:实时同步:物理世界状态 → 孪生体更新(延迟<1s);“What-If”推演:调整参数,预演结果;根因追溯:点击异常点,自动回溯至源头。输出:可交互、可推演、可决策的虚拟工厂。
6. 应用层:闭环执行与价值实现
典型应用场景:
场景 技术组合 价值
智能排产 数据挖掘(瓶颈识别) + 仿真(方案评估) + 数字孪生(可视化) OEE↑15%,交付准时率↑20%
预测性维护 异常检测 + RUL模型 + 数字孪生(设备健康看板) 非计划停机↓40%
实时成本优化 数据编织(打通MES/ERP) + 成本挖掘(动因分析) + 控制指令下发 单位成本↓8%
质量根因分析 关联规则 + 知识图谱 + LLM解释 质量问题定位时间从8h→10min
部署模式:边缘智能:控制类应用(<100ms延迟);云边协同:分析类应用(私有云训练,边缘推理)。
7. 反馈层:持续学习与进化(MLOps for Industry)
闭环机制:数据反馈:应用结果(如控制效果)回流至数据湖;模型监控:检测数据漂移、性能衰减;自动重训练:触发条件(如准确率<90%)→ 启动训练流水线;人工校验:工程师修正AI建议 → 生成高质量标注数据。目标:模型越用越聪明,系统越用越可靠。
三、全周期落地关键成功要素
维度 要求
业务对齐 从高价值场景出发(如降本、提质、增效)
架构弹性 Data Fabric + 微服务,支持渐进式建设
组织协同 OT(工艺/设备)+ IT(数据/AI)+ 业务(生产/财务)铁三角
安全合规 控制指令独立通道,满足IEC 62443、等保要求
持续运营 建立工业MLOps,避免“模型上线即死亡”
四、典型案例:某高端装备企业全周期实践
1.数据编织:接入PLM(BOM)、MES(工单)、DCS(传感器),统一设备编码;
2.数据挖掘:发现“主轴转速波动 >5% 且 冷却液流量 <阈值 → 加工面粗糙度超标”;
3.模型构建:训练GNN预测表面质量,嵌入热变形机理;
4.仿真验证:在数字孪生中测试补偿策略(调整进给速度);
5.应用部署:边缘控制器实时调参,良率提升12%;
6.反馈学习:每日自动收集新数据,周级模型更新。
成效:年减少废品损失¥2800万,新产品调试周期缩短30%。
五、总结:制造业智能系统的“生命体”隐喻数据编织 = 神经系统(感知与传输),数据挖掘 = 潜意识(发现模式),模型 = 大脑皮层(推理决策),仿真 = 想象力(预演未来),数字孪生 = 镜像自我(自我认知),应用 = 肢体行动(执行反馈),MLOps = 新陈代谢(持续进化)。终极目标:打造一个 “自主感知、自主认知、自主决策、自主优化” 的智能制造生命体,在不确定环境中,实现 韧性、敏捷、高效、绿色 的新质生产力。这正是制造业数字化转型的最高境界——从“自动化机器”走向“智能化有机体”。