AI代理终于能"记住"你了?GBrain到豆包失忆解决方案
最近被豆包和AI的动不动失忆得够呛 ,昨天约束好的技能,今天它忘得一干二净;跨几小时的上下文直接断档;长期积累的知识库?动辄”想不起来”。 总之,每次都要和豆包“自我介绍”才能继续干活,其他ai也有同样的问题,一来二去,耽误效率不说,每次重新认识都要消耗不少的时间精力以及token成本。 然后发现了Garry Tan(YC总裁)把自己的生产力大脑GBrain开源项目。 GBrain到底是什么? 它不是另一个新代理,而是专为OpenClaw/Hermes设计的”外挂大脑”。基于Postgres + pgvector + Git仓库 构建,让代理实现真正的长期记忆。 Garry自己用它跑了10,000+页Markdown知识、3,000个人脉页面 ,还并行多个cron任务,全程自治 。 GBrain 开源项目,本质是给 AI 代理做了一个解耦的外挂长期记忆层 ,解决了传统 AI 代理 “跨会话失忆、知识库存不下、旧记忆权重衰减” 的核心痛点 —— 而这些痛点,其实豆包用户也同样会遇到。 🔹Hermes用户 :以前跨session就忘,现在GBrain直接喂全量历史+向量检索,代理终于”记得住我喜欢的工作方式”。 🔹OpenClaw重度用户 :多代理协作时,GBrain成为共享记忆层,避免了各自为政的混乱。 🔹一位AI应用重度用户测试后 :这东西让个人AI从”聪明但健忘”进化到”聪明且靠谱”。 纯本地向量库 → 容易丢
云端RAG → 贵且隐私风险高
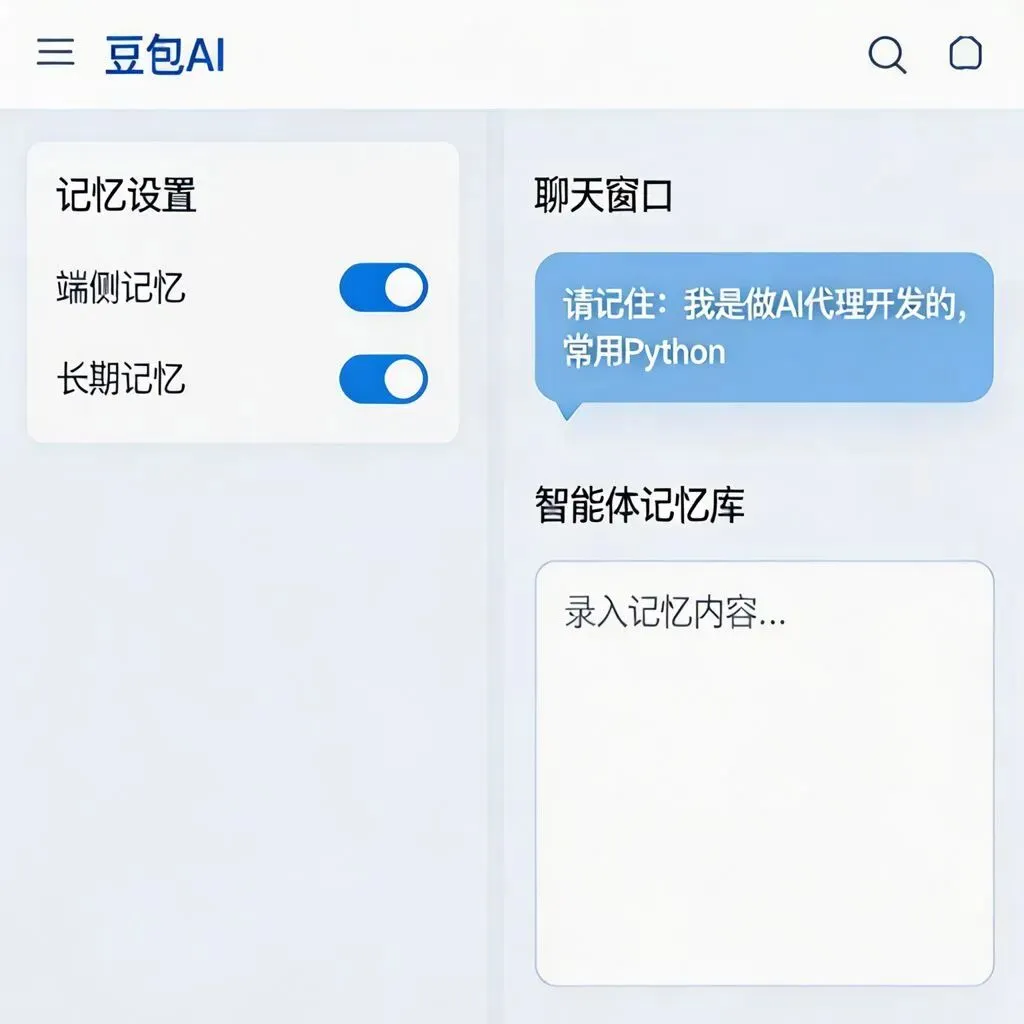
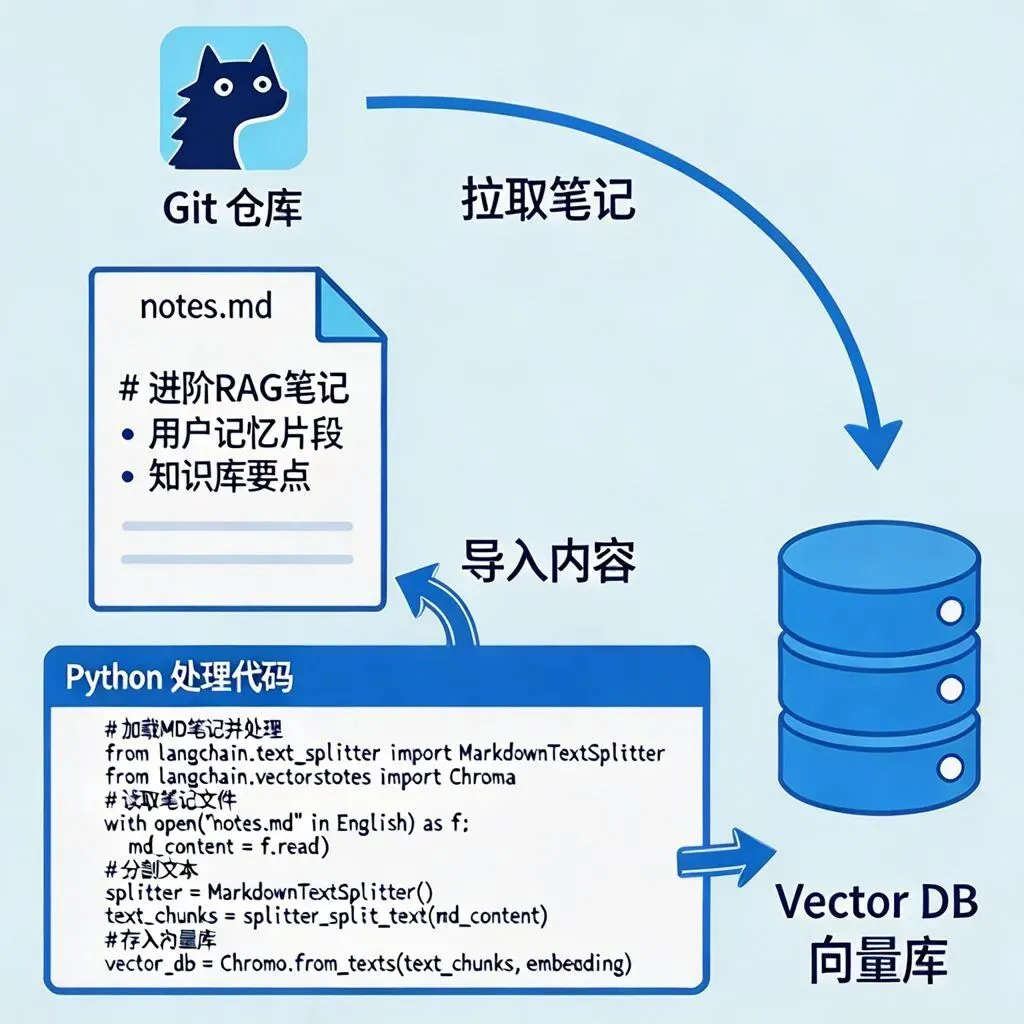
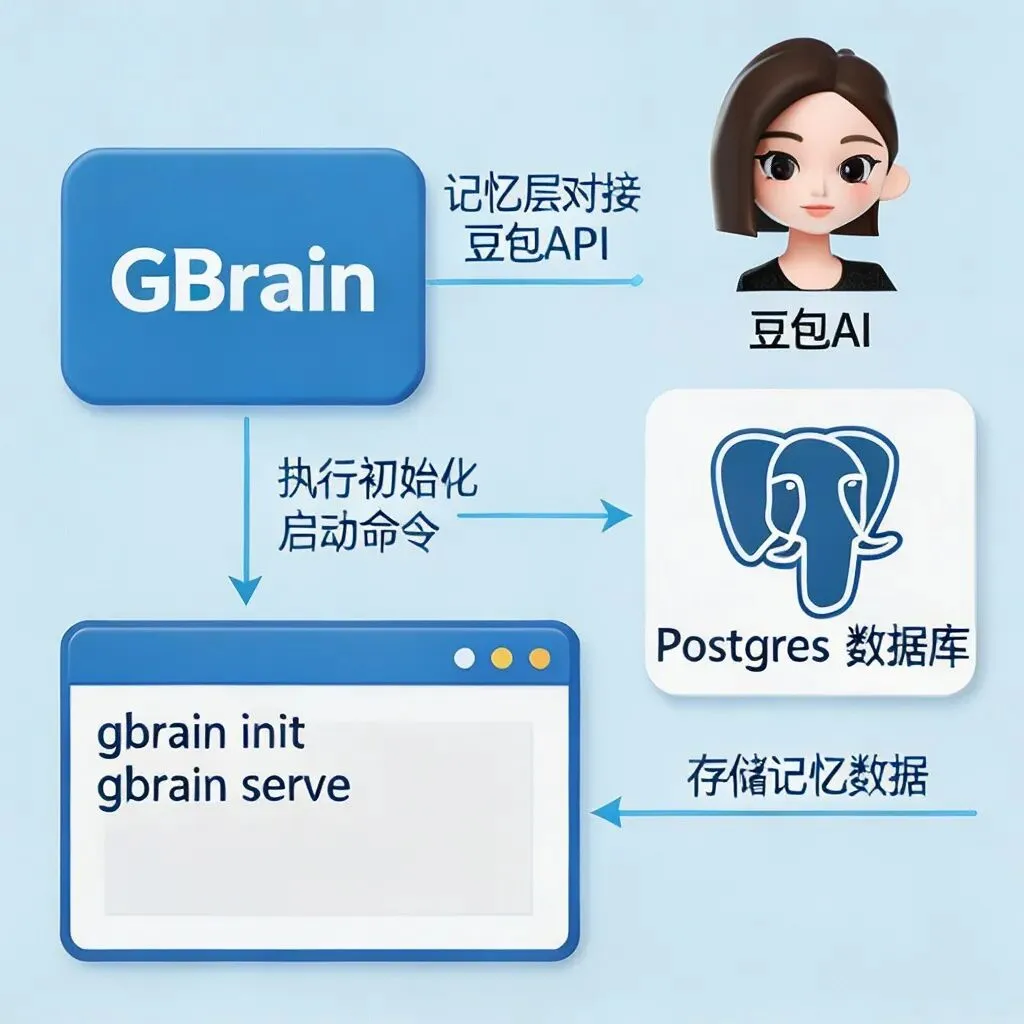
GBrain走的是“个人主权+生产力极致” 路线,正好卡在2026年个人AI爆发的点。 当然,不是完美无缺。 目前更适合有 一定技术背景的用户 (但文档清晰,跟着走很快),检索精度在超大规模知识库下还有优化空间。但对绝大多数想把AI代理当”终身助手”的人来说,已经够用了。 结合 GBrain 的设计思路,以及豆包(其他同类应用可参考,主要小编用豆包的日常处理多一些)的产品特性,可以按照用户的技术能力,分三个层级实现豆包的 “防失忆” 优化: 一、普通用户:零技术门槛,用官方功能解决基础失忆 如果你只是日常使用豆包,不想折腾技术,直接用豆包自带的功能就能解决 80% 的日常失忆问题,对应 GBrain 的基础记忆能力: 1. 开启官方长期记忆 + 主动指令锚定 进入豆包「设置」→「隐私与推荐管理」,开启「端侧记忆」和「长期记忆」开关,允许本地存储对话上下文 把核心的偏好、规则用指令主动告诉豆包:直接发送 请记住:[你的核心信息] ,比如请记住我是做AI代理开发的,常用Python,习惯用Markdown写笔记(目前就是这么干的,每次固定调用一个提示词) 定期对关键记忆做激活:偶尔问一句 “你还记得我之前的工作习惯吗?”,避免旧记忆被系统自动归档 2. 自定义智能体记忆库 如果你常用豆包的自定义智能体功能,可以在创建角色的时候,把你的专属信息录入到「记忆库设置」里: 按照「核心信息 + 场景 + 偏好」的格式录入,比如我是后端开发,做项目的时候需要你帮我写注释、检查逻辑 每条记忆控制在 50 字以内,避免信息过载,这样不管隔多久用这个角色,豆包都能记住你的设定 3. 用官方知识库托管你的个人笔记 豆包的自定义知识库功能,本质是官方帮你做好了 RAG(检索增强生成),你可以: 把你的 Markdown 笔记、项目文档、历史对话记录,批量上传到豆包的知识库 之后问问题的时候,选择对应的知识库,豆包会自动检索相关的内容,帮你回忆起之前的笔记和任务,不用你每次都重新发一遍 4. 定期清理低效缓存 豆包的短期记忆有容量限制,定期清理没用的缓存可以释放空间: 仅勾选「清除近 7 日非收藏对话缓存」与「重置短期记忆权重」,保留你的兴趣标签和收藏内容 二、进阶用户:轻量技术方案,搭个人简化版 GBrain 如果你有基础的 Python / 前端能力,想要突破官方功能的限制,自己搭一个轻量的外挂记忆层,实现类似 GBrain 的核心能力: 1. 本地轻量 RAG 外挂记忆 这是最核心的一步,用轻量的向量库,把你的对话历史和笔记变成豆包的长期记忆: 用LangChain+Faiss搭一个极简的本地 RAG 系统,Faiss 是 Facebook 开源的轻量向量库,不用部署复杂的数据库,本地就能跑 把你和豆包的历史对话、你的 Markdown 笔记,批量导入到向量库,转成向量存储 每次和豆包对话前,先把你的当前问题,去向量库里检索最相关的 3-5 条历史内容 把这些内容拼到 prompt 的开头:以下是我们之前的相关对话和笔记,请参考这些内容回答我的问题:[检索到的内容],我的问题是:XXX这样就能突破豆包自带的记忆条数限制,不管多久之前的对话,只要相关,豆包都能拿到上下文。 2. Git 同步你的记忆库 对应 GBrain 的「Git 驱动知识库」,你可以: 把你的所有笔记放到 Git 仓库里管理,实现版本控制,不怕笔记丢了 每次你更新了笔记,自动触发向量库的同步,把新的笔记更新到索引里,这样豆包的记忆会跟着你的笔记自动更新,不用手动导入 3. 对话动态摘要压缩 每轮对话结束后,自动对历史对话做权重分析,把低权重的闲聊内容压缩成摘要,保留高权重的任务、偏好、核心结论 这样既不会丢失核心信息,也不会让上下文太长,导致豆包的上下文窗口不够用 三、开发者用户:直接适配 GBrain,给豆包装完整外挂大脑 如果你有开发能力,完全可以把你分享的 GBrain 直接对接豆包,用上它的完整能力 ——GBrain 本身就是解耦的记忆层,和底层的 AI 模型是分开的,而且已经支持自定义模型对接: 为什么 GBrain 可以适配豆包? 它支持可插拔的模型提供者 ,通过 Vercel AI SDK,兼容所有 OpenAI 格式的 API 接口,而豆包的火山引擎 API 正好兼容 OpenAI 的调用格式 已经有社区贡献的 PR 支持了国内的模型服务,比如 DashScope、DeepSeek、智谱清言,对接豆包的适配成本极低 它支持轻量的本地部署,用pglite不用搭独立的 Postgres 服务器,个人电脑本地就能跑 对接步骤(10-30 分钟即可完成) 克隆 GBrain 的开源仓库:git clone https://github.com/garrytan/gbrain.git 初始化数据库:运行gbrain init,选择本地的 pglite 或者你自己的 Postgres+pgvector 数据库 修改模型配置:把 GBrain 的模型调用配置,改成豆包的 API 地址和密钥,因为兼容 OpenAI 格式,只需要改几个配置项就行 导入你的数据:把你的笔记、历史对话、人脉信息导入到 GBrain 的知识库,它会自动做向量编码和存储 启动服务:运行gbrain serve,GBrain 就会作为豆包的外挂记忆层,每次你和豆包对话,它都会自动检索相关的记忆,喂给豆包当上下文 对接后你能获得什么? 完全复刻 GBrain 给 Hermes/OpenClaw 的能力,给豆包也装上永久记忆: 超大规模记忆存储 :你可以像 Garry 一样,存几万页的笔记、几千条人脉信息,豆包都能记住,再也不会丢跨会话永久回忆 :不管隔了多少天,多少个会话,豆包都能接上之前的任务,记住你的工作方式,就像帖子里的用户说的,跨天任务直接续上多模态记忆支持 :图片、大文件、PDF 都能存,豆包也能记住你之前发过的截图、图纸,之后问的时候能直接召回共享记忆层 :如果你用多个豆包智能体,它们可以共享同一个记忆库,做多任务协作的时候不会各自为政完全的隐私主权 :所有数据都存在你自己的本地 / 服务器,不用把你的隐私笔记传到云端,解决了云端 RAG 的隐私和成本问题,正好对应 GBrain 的「个人主权 + 生产力极致」的路线总结 AI 代理的失忆问题,本质不是模型不够聪明,而是没有把记忆和模型解耦 ——GBrain 已经把这个方案验证了,而豆包用户也可以根据自己的能力,选择对应的方案: 想要把豆包当终身助手,直接对接 GBrain,把它从 “聪明但健忘” 的工具,变成真正能记住你、懂你的个人 AI 大脑
 夜雨聆风
夜雨聆风