 夜雨聆风
夜雨聆风





OpenAI 给 Agent 加了一个续命键"/goal":AI 终于能一直干到做完了?
Codex CLI 新增 /goal,背后不是一个命令,而是 Agent 从”短任务工具”走向”长期执行系统”的信号。
你让 AI 改一个复杂项目,它很快能写计划、改几处代码、跑几个命令。但真正麻烦的是:它经常半路忘目标,遇到报错就绕路,跑完一个测试就以为任务完成,最后还要你一遍遍接力。
这个问题困扰了整个行业很久。Agent 真正难的不是”会不会写代码”,而是能不能围绕一个目标,持续执行、持续验证、持续修复,直到任务真的完成。
OpenAI 刚刚在 Codex CLI 0.128.0 里加了一个 /goal 命令。表面看只是多了一条斜杠指令,但如果你读完它的实现细节,会发现这其实是一个信号:Agent 产品形态正在从”一次性对话工具”变成”持续执行系统”。
01发生了什么:不只是多了一个命令
OpenAI 在 Codex CLI 0.128.0 的 changelog 里写得很明确:
Added persisted /goal workflows with app-server APIs, model tools, runtime continuation, and TUI controls for create, pause, resume, and clear.
这句话里有四个关键词:
persisted——目标可以被持久化保存,不只是当前一轮对话里的临时上下文。你关掉终端再打开,目标还在。
runtime continuation——运行时可以围绕目标继续推进。不是每次都要从头开始,而是接着上次的进度往下走。
pause / resume / clear——目标的生命周期可以被控制。你可以暂停、恢复、或者清除一个目标重新来。
model tools + app-server APIs——这不是纯 prompt 技巧,而是产品和系统层的能力。模型层面有专门的工具支持,应用层有 API 接口。
对比一下以前的工作方式:
以前是你不断给 AI 派活——”帮我改这个””帮我测那个””帮我修这个报错”。每一轮都是独立的,AI 不记得你最终要干什么。
现在是你给它一个目标——比如”把这个模块重构到测试全部通过、文档更新、没有明显回归为止”。然后它围绕这个目标持续推进。
以前是任务驱动,现在是目标驱动。
这个差别看起来微小,实际上是 Agent 从”工具”变成”执行者”的关键一步。
02目标驱动 vs 任务驱动:差别在哪?
普通 prompt 是任务驱动:
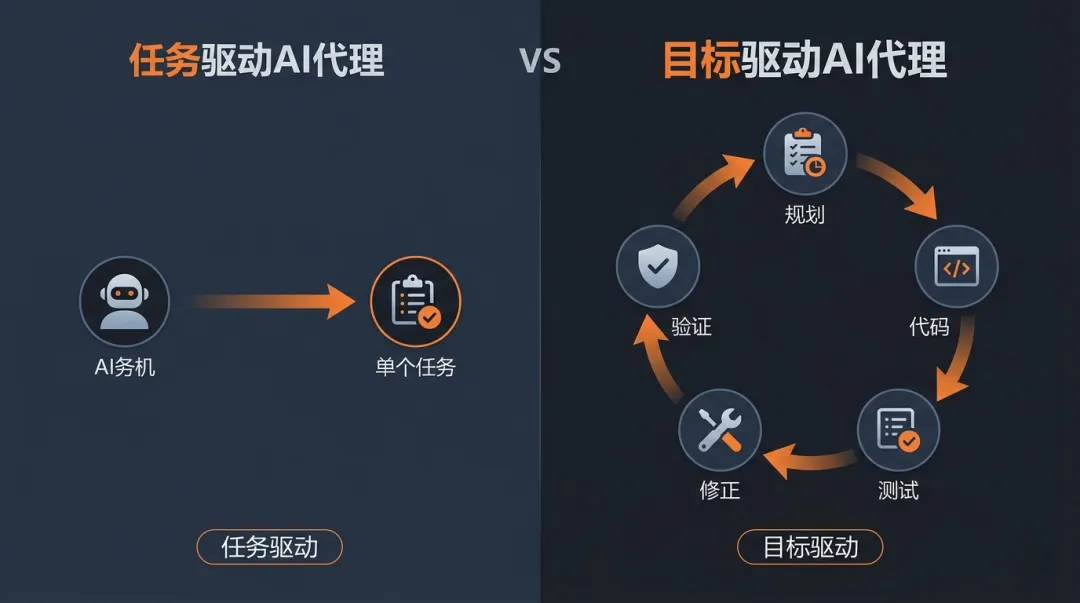
任务驱动与目标驱动对比图,左边是一条条指令,右边是一个持续推进的目标循环
每个指令关注的是”做一步”。做完就结束,不管整体目标有没有达成。
/goal 更像目标驱动:
差异在于:任务驱动关注”做一步”,目标驱动关注”做到什么状态才算结束”。
用更直白的话说:以前 AI 的终点是”我回复完了”,现在 /goal 让它的终点变成”目标达成了”。
这不是一个语义游戏。它意味着 Agent 的执行逻辑会发生根本变化——从”完成当前指令”变成”持续检查目标是否达成,没达成就继续干”。
03为什么这对长任务很关键?
OpenAI 之前在一篇关于 Codex Agent Loop 的文章里,详细解释过长时间任务的核心机制。他们明确强调:长时间任务的关键不是”一个超长 prompt”,而是一个完整的执行循环:
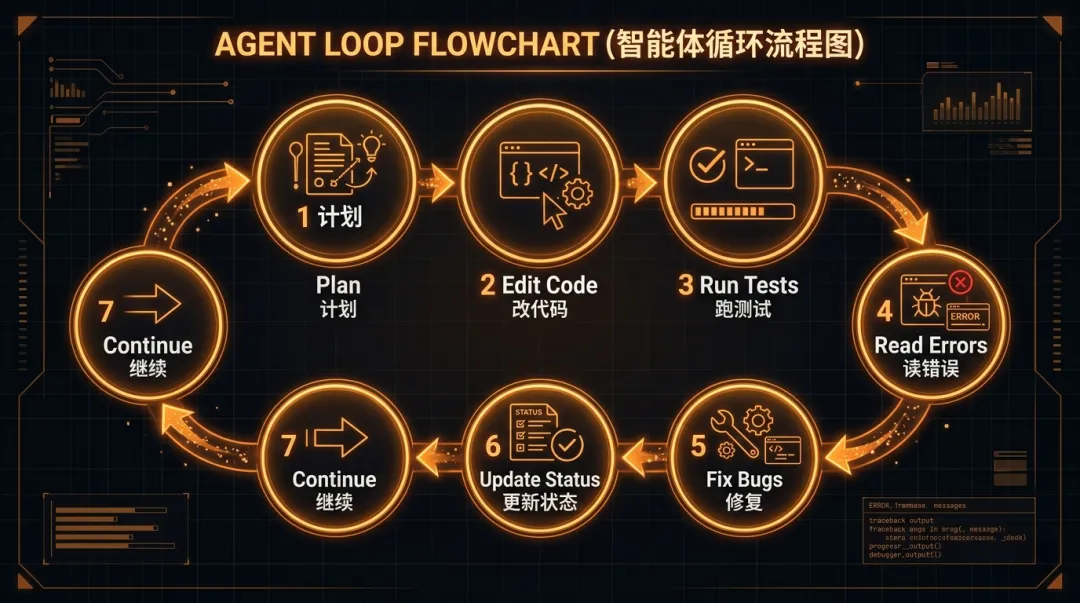
Agent Loop 七步循环流程图:计划、改代码、跑测试、读错误、修复、更新状态、继续
这个循环不断重复,直到所有条件满足。
OpenAI 的 Harness Engineering 实验更直接地验证了这一点:一个三人工程师小组用 Codex Agent 从零构建了一个软件产品,五个月交付上线,代码量约一百万行——没有一行是人写的。
这不是”AI 辅助编程”,而是人类定义目标和验收标准,Agent 自主完成全部编码、测试和提交。
长任务不是靠模型”记性好”硬撑,而是靠外部状态、工具反馈和持续验证组成闭环。
/goal 的作用就是把这个闭环正式产品化了。以前你得靠各种技巧——比如写 AGENTS.md、配置自动批准、手动接力——才能让 Agent 跑得久一点。现在 /goal 把”目标持久化”和”运行时续跑”做成了系统级能力。
举个例子:你让 Agent 实现一个完整的认证系统。
以前的方式是:你先写一个长 prompt,Agent 改几处代码,跑一下测试,然后停下来告诉你”完成了”。你一看,发现它漏了注册流程、没处理边界条件、测试覆盖不够。于是你再发一轮指令,它再改一点,又停下来。如此反复。
有了 /goal,你可以定义目标为”认证系统完整实现,包括登录、注册、登出、会话管理、错误处理,所有测试通过,文档更新”。然后 Agent 会自己推进:改代码、跑测试、看报错、修 bug、继续改,直到所有条件满足。
04这会带来什么变化?
变化一:从 Copilot 到 Coworker
过去 AI 更像副驾驶——你要一直握方向盘,它帮你打下手。
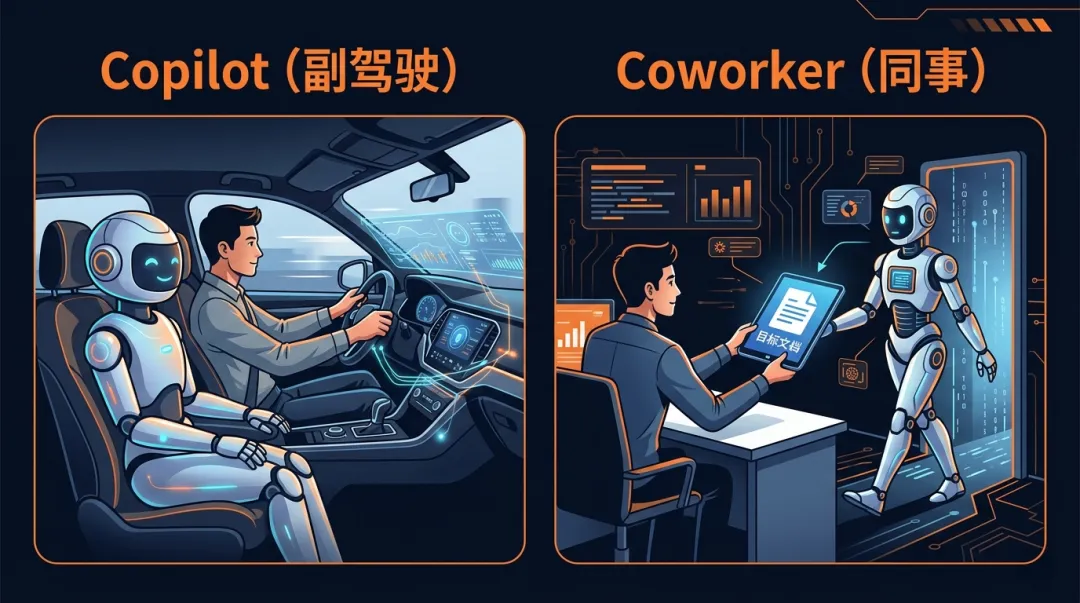
Copilot 与 Coworker 协作模式对比图,展示从实时操控到异步委派的变化
/goal 这类能力出现后,AI 更接近一个”可委派的同事”:你告诉它目标,它自己推进一段工作。你不需要每一步都盯着,只需要在关键节点审查结果。
这不是说 AI 已经能完全独立工作了。而是说,开发者和 AI 的协作模式正在从”实时操控”变成”异步委派”。
变化二:从 Prompt 工程到 workflow 工程
以前大家卷的是”怎么写一句神奇 prompt”。以后更重要的能力变成了:
Prompt 工程正在让位于 workflow 工程。
变化三:开发者开始管理 Agent,而不是操作 Agent
以前开发者像”打字员”——一条条喂指令,一步步等结果。
以后更像”项目负责人”——定义目标、设定边界、配置验收标准,然后审查结果。
这个转变对开发者的能力要求会发生变化。写好 prompt 依然重要,但更重要的是:你能不能把一个复杂任务拆成清晰的目标、约束和验收条件。
05但别误解:这不是 AI 全自动写完整个项目
这里必须泼一盆冷水。
/goal 不是万能的。它有几个重要的限制:
第一,它不是无限后台运行。 它仍然受 token 预算和运行时上下文的约束。当预算耗尽或上下文压缩时,目标可能会丢失细节。
GitHub 上已经有人反馈:在长时间运行中,active goal continuation prompt 和 audit requirements 在上下文压缩后可能丢失,导致 Agent 过早认为目标完成。
第二,它不是不需要人类审查。 Agent 的产出仍然需要人来验证。它可能写出能跑但不优雅的代码,可能通过测试但遗漏边界条件,可能完成表面目标但引入新问题。
第三,它不是所有任务都适合。 目标模糊的大型产品设计、缺少测试和验收标准的项目、涉及高风险权限和生产数据的任务——这些都不适合直接交给 Agent 用 /goal 跑。
真正危险的不是 Agent 做得慢,而是它”以为自己做完了”。
你必须为它定义清晰的完成标准,配置可靠的验证手段,然后认真审查结果。这不是”设置完就走开”的能力,而是”设置好目标和验收条件,让 Agent 去跑,然后你来审查”的能力。
06对开发团队的启发:给 Agent 准备”作战地图”
如果你打算在团队里用 /goal 这类能力,光写一个好的 goal prompt 是不够的。你需要为 Agent 准备一套”作战地图”:
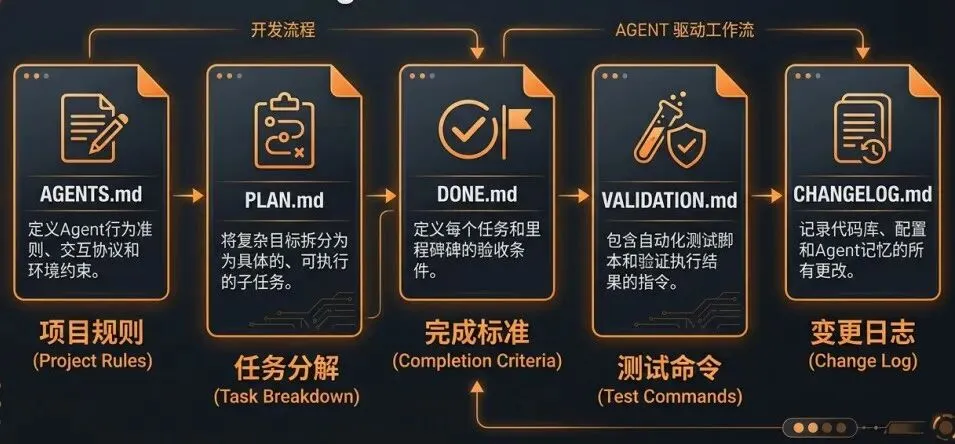
Agent 作战地图文件结构:AGENTS.md、PLAN.md、DONE.md、VALIDATION.md、CHANGELOG.md
AGENTS.md——项目规则、目录结构、编码规范、命名约定。让 Agent 知道你的项目长什么样。
PLAN.md——任务拆解和里程碑。把大目标拆成小步骤,每步都有明确的完成标志。
DONE.md——完成标准。什么状态算”做完了”?测试通过?Lint 通过?文档更新?类型检查通过?
VALIDATION.md——测试、构建、lint、验收命令。Agent 用什么命令来验证自己的产出。
CHANGELOG.md——每轮修改记录。方便你审查 Agent 做了什么,也方便 Agent 自己回溯。
小范围 worktree / branch——隔离 Agent 的修改,便于 review,也便于回滚。
不要只给 Agent 一个需求,要给它目标、边界、工具和验收标准。
这不是浪费时间。你花 10 分钟准备好这些文件,可能省下 Agent 跑偏后几小时的修正时间,更省下你审查一团乱码的时间。
07最适合 `/goal` 的场景
不是所有任务都适合用 /goal。根据目前的能力边界,以下场景最值得尝试:

适合与不适合使用 /goal 的场景对比
适合的场景:
不适合的场景:
核心判断:/goal 最适合那些”目标清晰、验收可自动化、需要持续执行”的任务。
08Agent 的下一个价值点:”更持久的执行”
/goal 不是一个普通命令。它是 Agent 产品形态的变化信号。
以前 AI 工具的竞争点是:谁回答得更好。现在开始变成:谁能围绕一个目标,持续执行更久、偏航更少、验证更扎实、交付更可信。
OpenAI 把 /goal 做成了系统级能力——有持久化、有 API、有生命周期管理、有 TUI 控制。这意味着他们判断:Agent 的下一个价值点不在”更聪明的回答”,而在”更持久的执行”。
但持久执行的前提是:你得先学会定义目标。模糊的目标 + 持久的执行 = 持续跑偏。清晰的目标 + 持久的执行 = 真正的交付。
09Agent 时代,开发者最该升级的能力
未来开发者不会因为会写 prompt 而领先。真正领先的人,是能把复杂工作拆成目标、约束、验收和反馈闭环的人。
AI 会越来越像执行者——它能改代码、跑测试、修 bug、写文档。但前提是:你得先学会像负责人一样定义目标。
不是更会提问的人赢了,而是更会定义完成标准的人赢了。