 夜雨聆风
夜雨聆风





AI冲击下,企业架构若不遵循FAIR原则,所有数据资产将成无效冗余!

缘起:关于企业架构&AI的集体困惑
最近半年,在与业界同仁交流中,人工智能对企业架构的冲击成为最受关注的议题之一。
大家普遍存在一种焦虑:
AI来了,我们沿用多年的企业架构方法是否面临全面推翻?哪些环节亟待调整,哪些能力已发生本质变化?
要回答这个问题,首先需厘清人工智能的两大分支——机器学习(ML)与生成式AI(GenAI)——各自带来的影响。
这两者并非替代传统架构,而是为其注入新的智能维度。
ML主要通过对历史数据的分析、模式识别和预测,将传统架构从“规则驱动”升级为“数据智能驱动”,实现业务流程的自动化优化与精准决策;而GenAI则凭借其强大的内容生成、自然语言理解与创造性交互能力,正在重塑软件创新范式,催生“人机协同”的智能体应用,并推动计算架构从通用硬件向专用计算(如GPU、TPU)的根本性重构,以满足其海量、可预测的数学运算需求。
当前企业架构建模领域面临一个根本性挑战:
与业务流程管理(BPM)或软件工程等成熟领域相比,我们的方法论长期停留在理论框架与个案经验层面,缺乏基于大规模实证数据的模式总结与最佳实践提炼。
其核心瓶颈在于高质量、多样化、可公开获取的模型数据集的严重匮乏。正如学者洛佩斯所指出的,现有数据要么规模不足,要么未经系统化整理,致使数据驱动的架构分析与智能应用难以落地。
这种数据缺失在实践中衍生出一种令人担忧的“捷径心态”。
我常遇到企业提出这样的需求:
“我们不需要从零设计,能否直接参考或套用同行业领先企业的架构成果?”
我对此持明确反对态度。
这不仅是知识产权与商业伦理问题,更关键的是——架构的本质是适配而非复制。每一家企业的战略、组织、技术生态都是独特的。引入各种方法论,都必须经过系统性的上下文适配与再造。
近期业内关于华为体系能否直接移植到消费、零售、互联网等领域的讨论,恰恰印证了这一点:未经情境化改造的架构移植,往往水土不服。
另一方面,即使企业完成了一套看似完整的架构设计,若其成果仅停留在汇报文件、Visio图表或ArchiMate工具中,成为需要人工艰难维护的“静态标本”,那么在AI时代,其实际价值将变得十分尴尬,且谈论AI的冲击或许为时过早,因为架构本身的价值都尚未真正释放,甚至一些基础工作都没做完。
你可以用PPT跟高层汇报架构思路,有人说放弃PPT架构,除非有个前提,企业的整体架构已经落地为数字化呈现且高度完善,而且高层本身对技术理解的全面而透彻,这是非常理想化的状态,尤其是对于一个庞大的集团性组织。PPT也好什么也好,这是沟通的共同媒介。在此实现之前。PPT的高层管理汇报形式都极为必要。
当然,真正意义上的企业架构,必须让设计元素在运行环境中动起来:
流程(逐步走向自动化和AI自动化)须驱动系统,数据模型须融入所有平台,应用架构须落地为可部署可管理的服务,运维实现AIOPS….
为什么很多企业的所谓企业架构师在职时间都不长,很简单,因为高层一直看不到架构运转的载体…..
当前,AI正在跨越炒作期,逐步嵌入从需求分析到系统运维的工程全链路。对于企业架构而言,真正的机遇不在于利用AI生成漂亮的架构图(即“文本转图”),而在于构建能够深度理解UML、BPMN、ArchiMate等建模语言语义,并能基于业务逻辑进行推理、校验与优化的智能辅助系统。这样的系统将成为架构师的“智能协作者”,协助完成模型补全、影响分析、模式推荐、合规检查等高频且复杂的工作。
企业架构建模将逐步告别高度依赖个人经验、耗时费力的“手工作坊”模式,走向人机协同、数据驱动、持续演进的新范式。
架构师的角色将从绘图员与文档撰写者,转向为智能治理的驾驭者。
而实现这一转型的基石,正是始于今天我们对待架构数据的态度,与其急于求成地“复制”,不如扎实地积累与锤炼自身的情境化架构资产,为迎接智能化的企业架构时代储备真正的数据燃料。
第一篇:AI时代企业架构建模升级
1.1 数据稀缺与模型幻觉
当前,阻碍AI在企业架构建模领域规模化应用的首要障碍,并非算法本身,而是持续出现的数据孤岛与高质量数据的结构性短缺。
财务、人力资源、营销、供应链等关键业务领域的数据往往在互不相连的孤岛中运行,缺乏共同的分类与共享标准。
其直接后果是,每一项AI举措都变成了一个旷日持久(6至12个月)的数据清理项目,团队将大量精力耗费在寻找和整理数据上,而非产生有意义的业务洞察。
这种数据困境在工业场景中尤为突出。
2025年,许多企业期待的大模型规模化智能并未实现,反而被迫退回“一事一议”的定制化开发老路。
例如,某汽车厂商训练AI识别零件缺陷,却发现公开数据集中全是标准件,自家产线的特殊型号数据根本无处可寻;金融机构为农村用户做信贷风控,模型在实验室表现优异,却因训练数据缺乏“养猪户雨季收入波动”等真实场景特征而频频误判。
数据不是AI的燃料,而是它的空气,一旦短缺或者错了,再先进的模型产出也只能是缺氧环境下的幻觉表述。
在企业架构建模的特定语境下,数据稀缺表现为缺乏大量、多样、标注良好的EA模型实例。而且建模本身属于企业资产。这使得该领域难以像BPM领域那样,基于海量案例归纳出可复用的模式、最佳实践与设计指南。
1.2 历史性机遇:AI作为“语义优先”的工程协作者
尽管挑战严峻,但技术演进同时打开了前所未有的机遇窗口。
2026年的前沿实践表明,AI在企业架构建模中的角色,正从简单的绘图工具,升级为具备深度工程智慧的“协作者”。
首先,是语义驱动的精准建模。
领先的工具平台(如Visual Paradigm)其核心竞争力在于“语义优先”的建模范式。
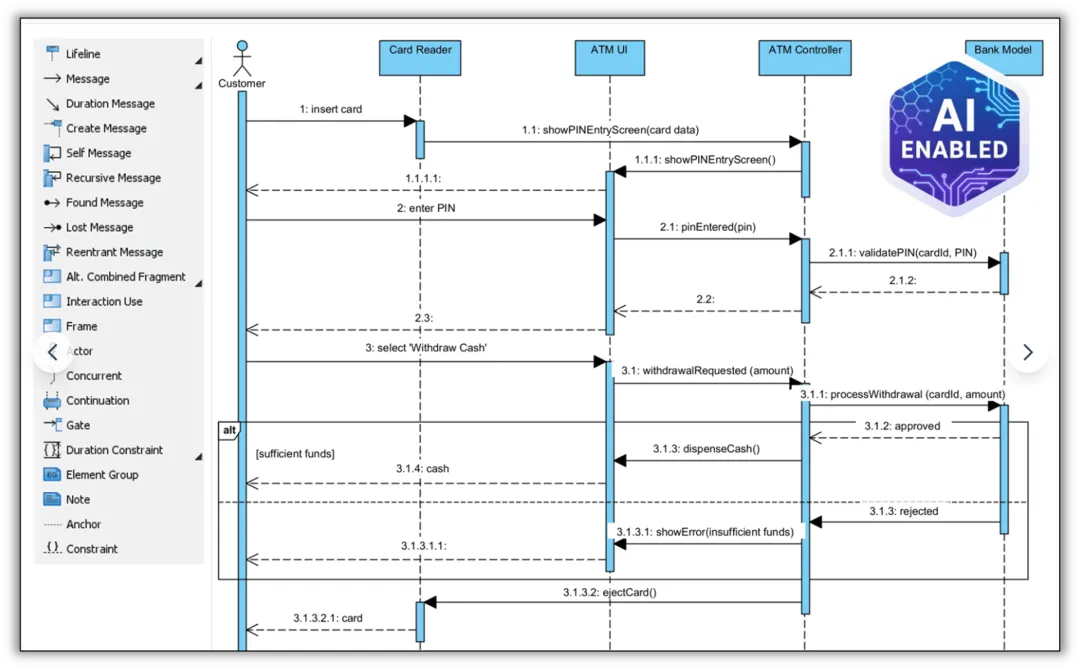
其AI系统经过深度训练,能理解并遵循ArchiMate、UML等标准的正式语义规则。例如,它能准确区分类图中的“聚合”与“组成”关系,避免系统耦合问题;能处理复杂的多重性约束(如“支付成功后才允许发货”);能确保序列图中的片段、激活、生命线等元素符合实际业务流程。
这种对建模语义的深层理解,确保了生成内容在工程上是可验证、可扩展、可追溯的,超越了通用大语言模型仅能“绘制草图”的局限。
其次,是实时对话式建模与敏捷迭代。
传统“一次生成、无法修改”的静态流程被彻底摒弃,代之以基于自然语言的动态对话式工作流。
企业架构师可以通过AI Chatbot,用自然语言指令实现模型的持续演化,例如:“为支付失败场景增加异常处理分支”、“将用户角色从‘顾客’更改为‘已认证客户’”。系统不仅能执行指令,还会自动触发图示的重新布局与优化,确保输出始终符合专业标准。这极大地降低了建模门槛,提升了敏捷响应业务变化的能力。
最后,是自动化的变更传播与一致性维护。
在大型企业架构项目中,“文档衰减”和信息断层是常见痛点。
新一代AI系统通过“全模型联动机制”实现了跨视图的实时变更同步。
例如,在时序图中修改一个服务名,相关类图、部署视图中的对应元素会自动更新。这种“单一数据源”机制,确保了从高层战略到底层设计的一致性,构建了真正可追溯、抗衰变的架构资产。
第二篇:遵守与破局
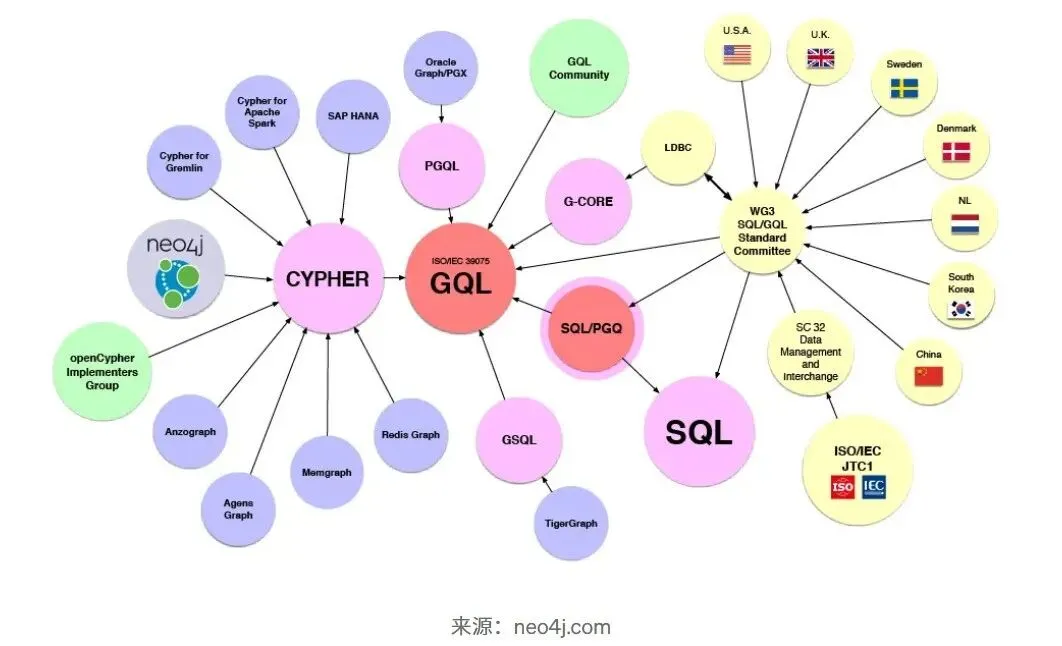
面对数据稀缺的核心挑战,全球研究与实践社区达成了一个关键共识:
必须遵循FAIR原则来构建和管理企业架构数据资产。
FAIR代表可发现性(Findable)、可访问性(Accessible)、互操作性(Interoperable)和可重用性(Reusable)。
一个符合FAIR原则的EA模型数据集(如 EA ModelSet)是解锁AI潜能、推动实证研究的基石。

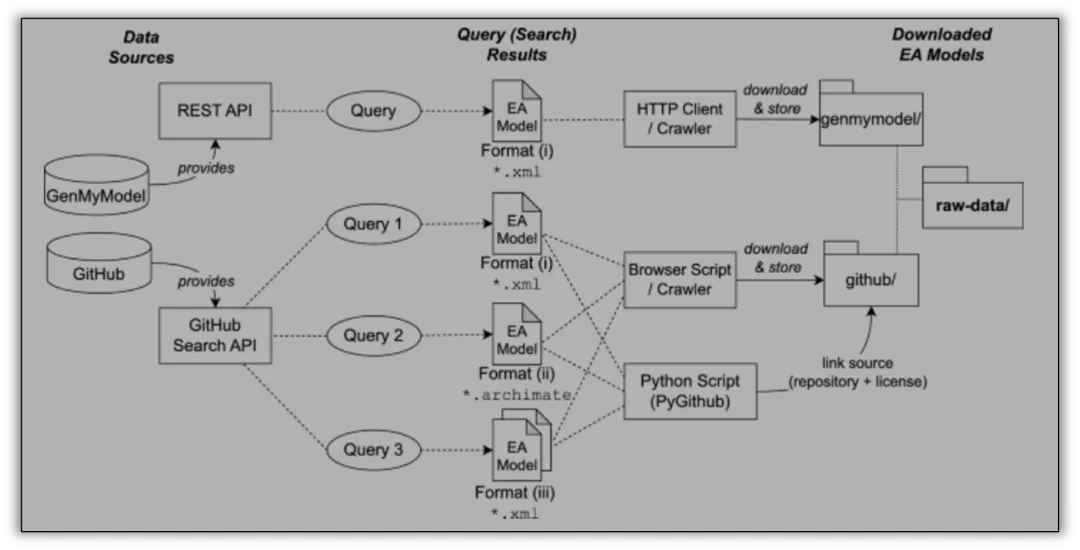
第一阶段:多元化数据源的识别与接入
“Data Sources”(数据源)模块,是整个数据生态的起点。
高质量的数据集并非凭空产生,而是需要从现实世界中既有的、分布式的资源中汇聚而来。
两个主要数据源:
GenMyModel:这是一个在线的协作建模平台,用户可以在其上创建、分享各种UML、BPMN、ArchiMate等格式的模型。通过其提供的REST API,可以以程序化的方式,按照特定条件(如模型类型、标签、公开状态)批量查询和获取模型数据。这代表了对结构化、标准化平台数据的利用。
GitHub:作为全球最大的开源代码托管平台,GitHub上同样存储着大量由个人开发者、研究团队或企业项目公开的架构模型文件(如XML、.archimate文件等)。通过GitHub Search API,可以基于关键词、文件扩展名、项目描述等进行搜索,从而发现散落在无数代码仓库中的宝贵模型资源。这代表了对开源社区与分布式存储数据的挖掘。
这两个数据源的并列设计极具代表性,它揭示了构建数据集的两条主要路径:
一是从专业的、集中的建模工具或社区获取;
二是从更广泛的、非结构化的互联网开源生态中爬取。
这种组合确保了数据来源的多样性,避免了单一来源可能带来的偏见或局限性。
第二阶段:定向查询与结果筛选
“Query (Search) Results”(查询结果)模块,是连接数据源与最终采集结果的桥梁。它强调了数据获取不是盲目的全量下载,而是基于明确意图的精准检索。
针对GenMyModel,通过设计一个或多个“Query”来获取特定格式(如*.xml)的EA模型。这里的查询逻辑可能包括模型类型、元数据标签、创建时间等过滤条件。
针对GitHub,这一过程更为复杂和关键。
“Query 1”、“Query 2”、“Query 3”,对应搜索不同文件格式(如*.xml, *.archive, *.archimate)的模型。这在实际操作中至关重要,因为不同工具生成的ArchiMate模型可能使用不同的文件扩展名。
为了构建一个全面的数据集,必须设计周密的搜索策略,覆盖所有可能的主流及变体格式,以确保不遗漏潜在的有效数据。
此阶段的核心在于将数据需求(我们需要什么样的模型)转化为各个数据源API能够理解和执行的查询指令,从而从浩瀚的数据海洋中定位到目标资源。
第三阶段:自动化下载、存储与溯源
“Downloaded EA Models”(已下载的EA模型)模块,展示了将查询结果转化为本地化、可管理资产的具体执行与存储方案。这里采用了多种适配不同数据源和技术特点的采集工具,体现了高度的工程实用性:
对于GenMyModel:使用通用的HTTP Client / Crawler。由于REST API通常返回结构化的JSON响应和直接的文件下载链接,利用一个配置好的HTTP客户端或轻量级爬虫,即可自动化地遍历查询结果列表,下载每个模型文件(如XML文件),并将其存储到本地指定的目录结构下(如genmymodel/文件夹)。
对于GitHub:采用了两种互补的方法:
1-Python Script (PyGithub):利用PyGithub这类成熟的官方库封装,可以高效、合规地调用GitHub API进行搜索和内容获取。这种方法不仅可以下载模型文件本身,还能同时抓取并记录关键的溯源信息,如文件所在的仓库地址、项目许可证类型等,并将其与模型文件一同存储。这一点对于遵循FAIR原则(尤其是“可重用性”)至关重要,因为清晰的溯源信息是评估数据合法性和适用性的基础。
2-Browser Script / Crawler:对于某些复杂或需要交互的页面,或者作为API访问的补充,可能会使用基于浏览器自动化(如Selenium)的脚本或爬虫来模拟用户行为,导航并下载文件。
所有下载的模型文件被系统地组织在raw-data/根目录下,并按来源(genmymodel/, github/)进行子目录分类。这种清晰的存储结构为后续的数据预处理、质量检查和统一格式转换提供了便利。
2.1 数据基础设施重构:从孤岛到网格
破局的第一步,是从基础设施层面重构数据供给范式。
企业普遍存在的“无统一标准、无集中治理、无动态更新”的“三无”状态必须被终结。
IBM的研究指出,将数据重新定位到中心数据湖的旧模式成本高昂、速度缓慢,正被更现代的数据网格(Data Mesh)和数据结构(Data Fabric)架构所取代。这些模式提供了一个虚拟化层,允许在数据原位进行访问和处理,支持“将AI引向数据”,而非“将数据移向AI”。
数据标准化与集中治理是基础。
香港医管局的案例提供了典范:
通过三十年持续投入,建立跨院区数据中台,将分散在127家医院的近60亿条诊疗记录进行标准化清洗,统一了疾病编码、检查指标等规范。
这一基于“一套系统架构、一套标准”的顶层设计,最终使AI辅助诊断模型的准确率大幅提升。
对企业而言,这意味着必须建立元数据管理体系、数据质量评估框架(完整性、一致性、时效性)以及跨域共享协议(如利用联邦学习实现“数据可用不可见”)。
图技术成为连接与理解的关键。
传统的关系型数据库模型固化,难以演进,加剧了数据蔓延和孤岛。
图数据库(如Neo4j)因其能自然表征世界的网络、层次和旅程关系,正变得不可或缺。通过在现有系统之上构建基于图的连接层,企业可以实现渐进式现代化,逐步形成企业知识图谱,为AI提供理解业务语义所必需的清晰性,从根本上减少“幻觉”。

2.2 模型架构演进:“通专融合”的混合智能
面对长尾场景数据稀缺的难题,单一的模型策略已不适用。
未来主流范式是“大模型+小模型”的混合架构,即用通用大模型的泛化能力覆盖广度,用垂直领域小模型的精准适配解决深度。
例如,在金融风控场景,可以采用混合架构:

这种架构能将特定场景的数据需求降低70%,同时大幅压缩模型迭代周期。
中关村科金的实践也显示,通用模型处理标准化问答,垂直模型专攻专业决策,整体响应速度可提升4倍。
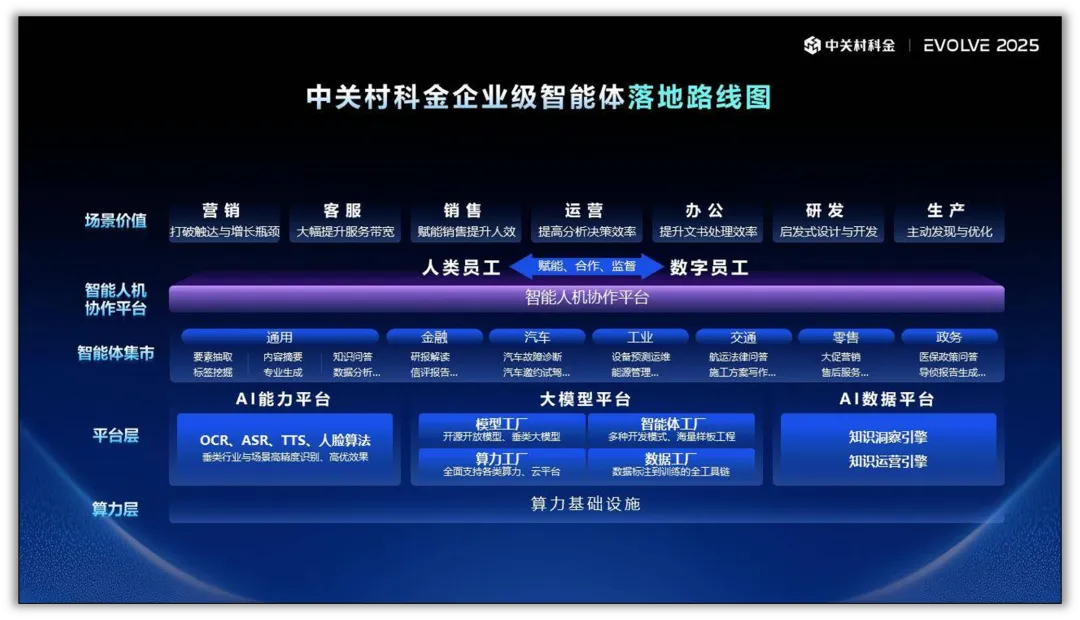
这种“通专融合”体系的关键在于建立高效的“语义网关”或交互协议(如MCP、A2A),实现不同模型、智能体之间的上下文交换与协调行动。这正推动着运营模式的变革:过去需要多个团队协作的流程,现在可以由网络、存储、编排等领域的智能体直接通信并协同决策。
2.3 组织与文化转型:从数据管理员到价值驱动者
技术的落地最终依赖于组织与人的转变。
IBM的研究发现,92%的首席数据官(CDO)认同其成功取决于对业务成果的关注,但只有29%的人相信自己有明确的方法来衡量数据驱动的商业价值。
这种差距正是AI智能体被期望填补的。
文化上,必须培养全员数据素养。
数据民主化成为关键,80%的CDO认为这有助于组织更快前进。这意味着要投资于直观的工具,使非技术业务人员也能与数据简单交互,并培养一种基于数据和事实进行决策的文化。
治理上,需建立平衡速度与安全的联盟。
CDO与首席信息安全官(CISO)的紧密联盟至关重要,以应对数据主权、隐私保护等核心风险。同时,要推动团队开发和使用“数据产品”——即为特定业务目的(如“客户360视图”)设计的、可重用、可安全共享的数据资产包。
人才上,应对快速变化的技能需求。
2025年,高达82%的CDO正在招聘去年还不存在的、与生成式AI相关的数据角色。吸引和留住顶尖数据人才,并持续更新团队技能,是最大的挑战之一。
第三篇:AI赋能的企业架构建模实施路径
基于上述破局之道,结合2025-2026年的行业最佳实践,我们可以勾勒出一幅AI赋能企业架构建模的清晰实施蓝图。
3.1 从重咨询到轻咨询、快交付
传统的企业架构转型往往伴随长周期、高成本的咨询项目。
新的范式强调“业务建模驱动”,以轻量级、敏捷精益的方式打通“战略→业务→技术→运营”全链路。
其核心框架通常包括五大模型(能力、业务、流程、产品、数据)、四大视角(流程、产品、数据、能力实现)和三层架构(业务架构→应用架构→技术架构),并引入体验模型来补齐用户旅程视角。
实施方法论遵循的逻辑:
首先统一高层认知,明确价值;
然后量体裁衣,选择T型拓展、领域先行等适合的实施方式;
最后建立由PMO、工具平台和复合型团队构成的保障体系。
目标是让“业务人员做选择题,不做填空题”,将建模周期从周/月级缩短至天/小时级。
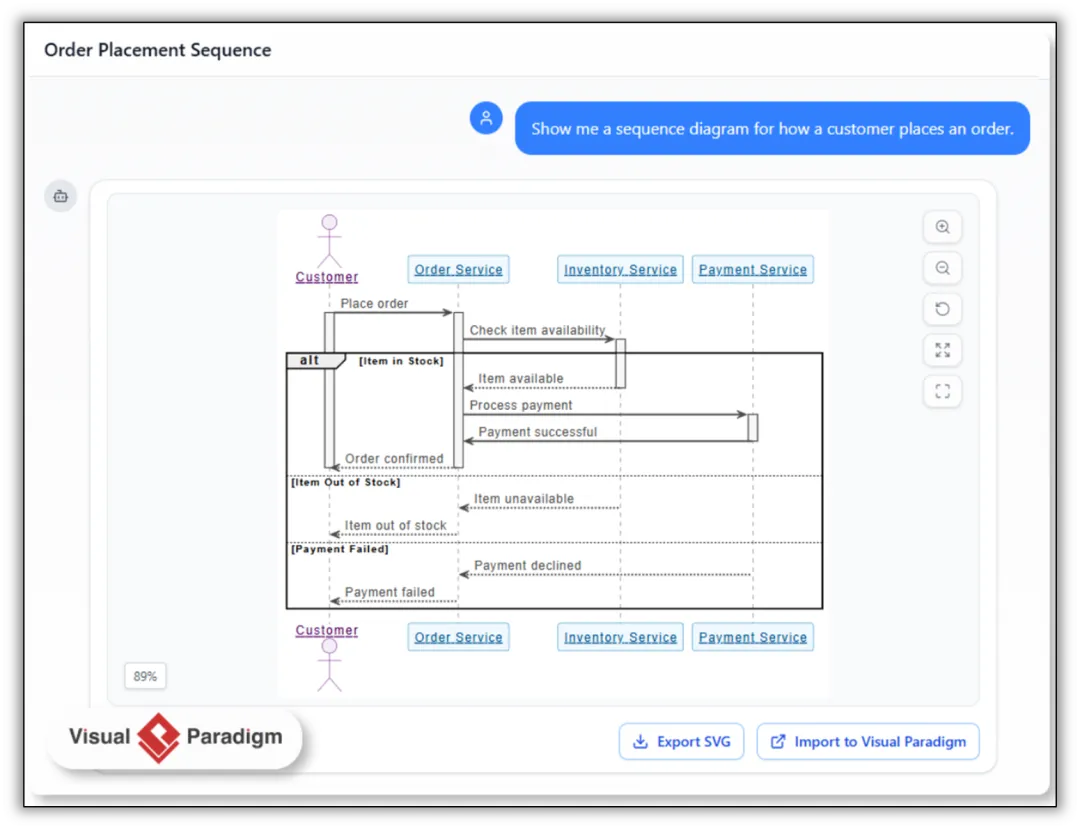
3.2 工具平台智能化:Hyper-Agent与一体化工作流
工具平台的进化是落地的关键。
领先的平台正集成Hyper-Agent智能体,实现业务建模自动化与人机协同。其技术架构通常分层构建:从L0通用大模型,到L2/3针对金融、制造等领域的垂直精调模型,并结合知识图谱、流程引擎、组件库等形成“六边形模型”能力。这些智能体能够一键生成流程、产品、数据模型,自动生成微服务框架和前端原型,并进行实时仿真验证。

更先进的工作流支持“AI生成→无缝导入专业编辑器”的闭环。
AI生成的图表作为“种子”,可立即在专业环境中进行深度开发,如添加语义标签、执行矩阵分析、进行系统仿真等。
平台支持云端协同,团队可在浏览器端进行头脑风暴,关键模型则同步至桌面客户端进行复杂设计,完美适配远程协作与敏捷团队。
3.3 聚焦战略清晰度:ArchiMate 3.2的七个关键动作
在企业架构建模语言层面,ArchiMate® 3.2标准的普及带来了表达清晰度的革命。它通过对动机层、战略层、实施迁移层的系统性优化,
将架构图从“盒子与箭头”转变为支撑战略决策的叙事工具。
架构师可通过七个关键动作迅速提升价值:
1 选择结构化视角:根据受众(高管或技术团队)选择匹配的视角,而非将所有内容堆砌于一图。
2 使用动机元素:清晰表达“为什么做”,用驱动因素、目标、成果等元素将技术文档升级为战略工具。
3 从流程思维转向能力思维:聚焦稳定、高管关注的企业能力,而非易变的流程细节。
4 使用实施与迁移元素:用平台、差距、工作包等元素构建真正可执行、可追溯的路线图。
5 建模“动机→战略→能力”链路:清晰展示战略对齐,解释“为什么重要”。
6 通过跨层视图融入利益相关者:使模型成为战略对话与协商的工具。
7 建立视觉纪律:采用分层配色、清晰命名、减少交叉连线等规范,提升对非技术受众的说服力。
第四篇:企业接下来怎么办?
未来,企业架构建模工作将不再依赖于个体的经验与静态的文档,必然会演进为一个由高标准、高质量数据资产驱动,并由人工智能深度赋能的价值创造系统。
1 企业架构的实践质量,根本上取决于其所依赖的数据基础的质量和规范程度。
2 一个遵循“可发现、可访问、可互操作、可重用”的FAIR原则的、开放的模型数据集,将成为核心基础设施。
尤其对于肩负着国之重器使命的央国企而言,这种转变的紧迫性与战略意义尤为突出。
我们必须清晰认识到:
企业架构的本质,是将高层的战略愿景与宏大的业务规划,转化为一系列可执行、可度量、可治理的具体技术蓝图的系统过程。
它连接着战略管理与项目管理,是确保大型复杂组织运行稳定、创新有序、投资有效的“转换器”。
而确保这个“转换器”高效、精准、与时俱进运转的基石,正是标准化、高质量、可共享的架构数据资产。
因此,
第一,我们必须旗帜鲜明地将数据资产的战略地位提升到与业务资产、财务资产同等重要的高度。
管理者需要推动并投资于建立覆盖全集团、贯穿战略到执行的数据治理体系。
这不仅需要“结构”(成立企业级数据治理委员会等组织与标准体系),更需要“管理系统”(覆盖数据全生命周期的管理流程)和“人员”(具备数据管理与架构能力的专业团队)。
投资有效的企业级数据治理是为了降低未来的隐性成本(如数据孤岛造成的重复投资、数据质量问题引发的决策失误、数据标准不一造成的系统集成难题),并放大数据作为一种战略资产的乘数效应。
第二,我们必须深刻理解并采纳“语义优先”的架构标准化,以从根本上提升数字资产的互操作性与长期价值。
打破数据孤岛与信息烟囱的关键,并非仅仅在于技术上的物理联通,而在于语义上的统一理解。
需要建立“企业范围的通用数据定义”,开发“概念数据模型”,以达成对核心业务实体(如“客户”、“设备”、“订单”)的统一语义共识。
这正是在为未来的数据共享与人工智能应用铺设轨道。
当AI需要理解业务、辅助决策时,一个标准化的、语义清晰的“概念数据模型”是其理解和推理的通用“词典”。
没有这个基础,再强大的AI也只能是“盲人摸象”,无法形成跨领域、跨部门的全局洞察。
第三,我们应当审慎而前瞻地规划和建设面向复杂管理场景的综合性人工智能赋能体系。
在架构工作中引入AI,不是要完全替代架构师的创造性思维和专业判断,而是要将其定位为一个强大的“协同智能体”。
一方面,它可以承担重复性、高强度的信息处理与模式发现工作,
例如在海量的历史项目文档中自动提炼业务流程模式、识别架构决策的共性风险。
另一方面,它可以在标准架构元素的组合与设计上,基于对高质量历史案例(即开放的EA模型集)的学习,提供智能建议与合规性检查,从而提升架构设计的效率与规范性,确保设计决策符合组织级的战略原则。
最终,这意味着我们要推动组织从传统的“文档驱动、项目驱动”的运作模式,向“数据驱动、模型驱动”的现代化治理模式转变。
一个健康的、能持续产生价值的企业架构实践,其核心产出应是一个可动态维护的、可查询的、可组合的、与业务运营实时对齐的“活”的架构模型库。
这个模型库本身,就是企业的“数字孪生”,是战略推演、投资评估、风险防控、系统集成的共同事实依据。
通过建立一个“业务需求→架构模型→技术方案→投资决策→价值验证”的闭环价值链,我们能够让企业的数字化投资更加精准,决策链条更加敏捷,组织结构更加敏捷,从而在快速变化的市场与技术环境中,构建起制度化的、而非偶然性的、可持续的核心竞争优势。
总而言之,对于企业管理者而言,拥抱企业架构建模的智能化未来,是一项关乎组织长远韧性、创新效率与战略执行力的根本性决策。其路径是明确的:以治理决心夯实数据基础,以标准化构建语义共识,以智能辅助提升决策效能,最终打造一个能自我学习、持续优化、并与国家战略与市场脉搏同频共振的现代化数字企业。

