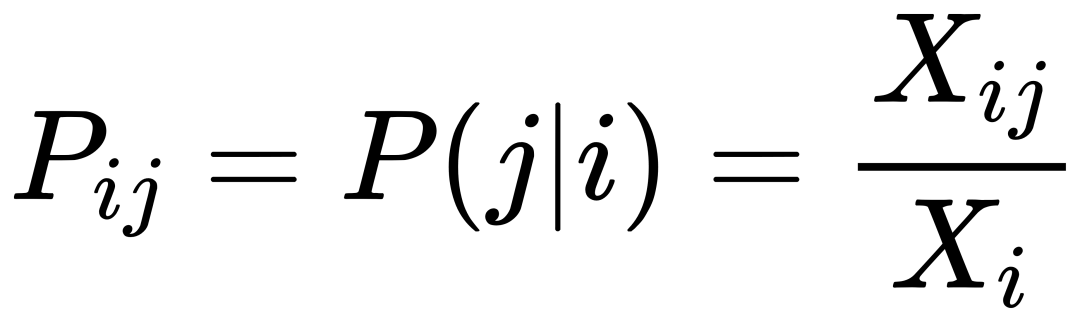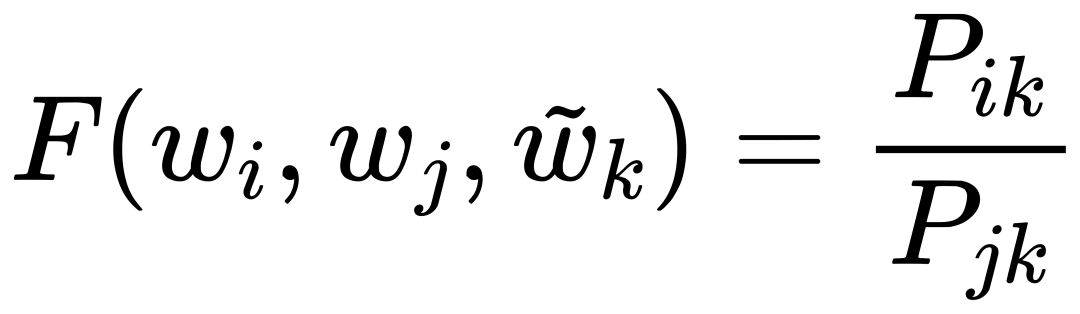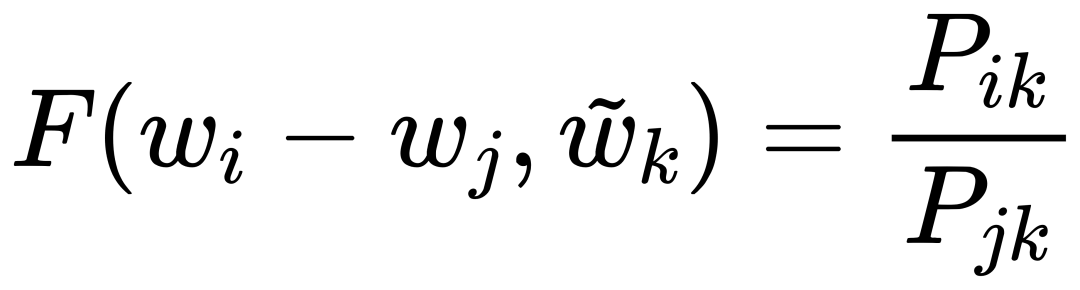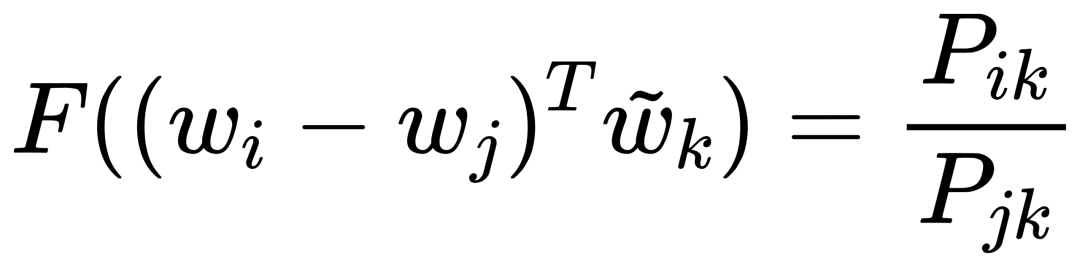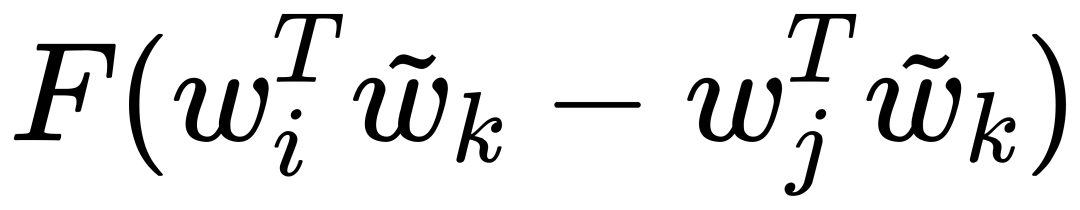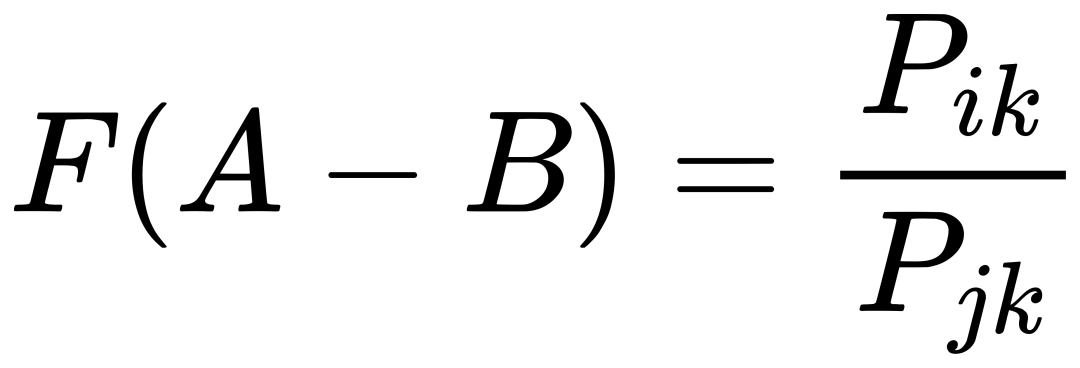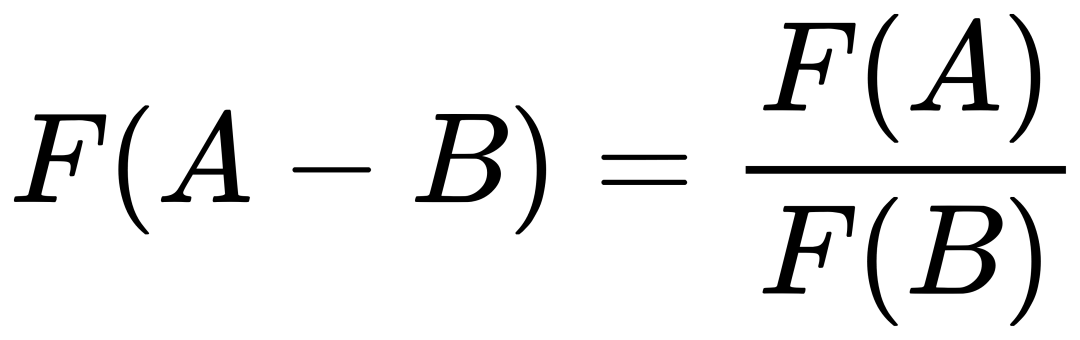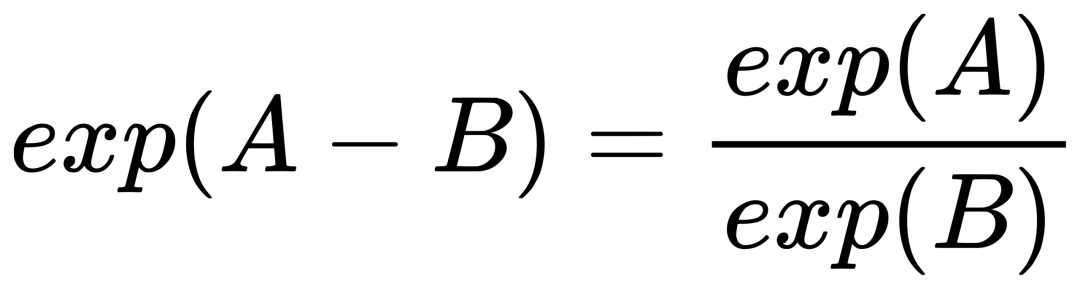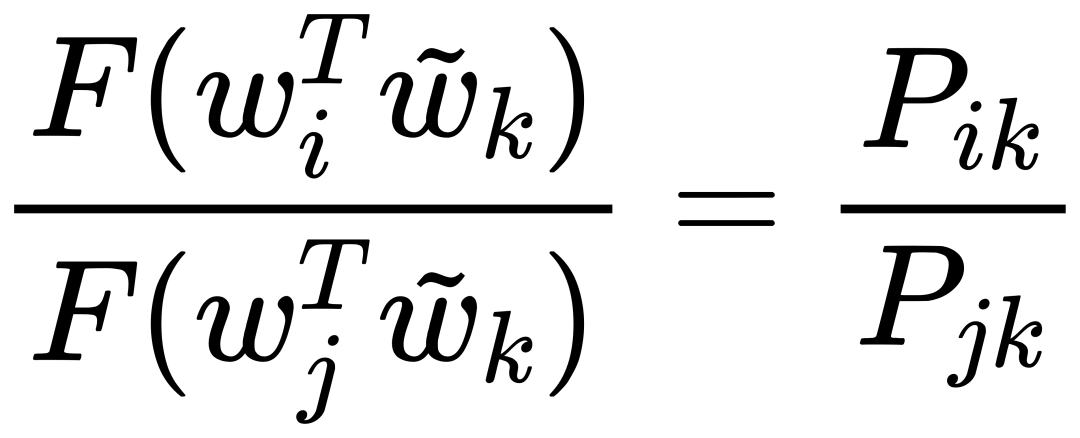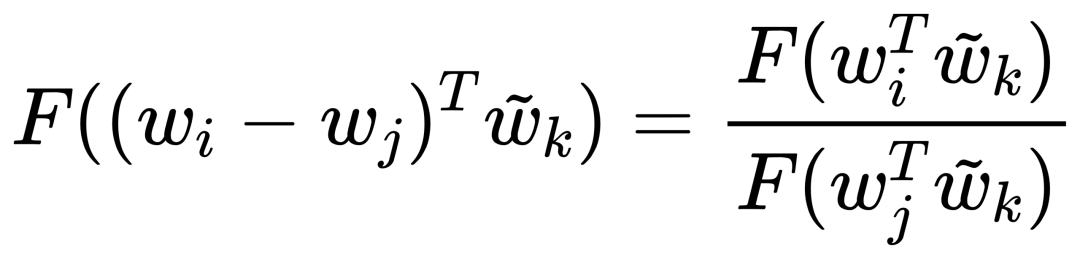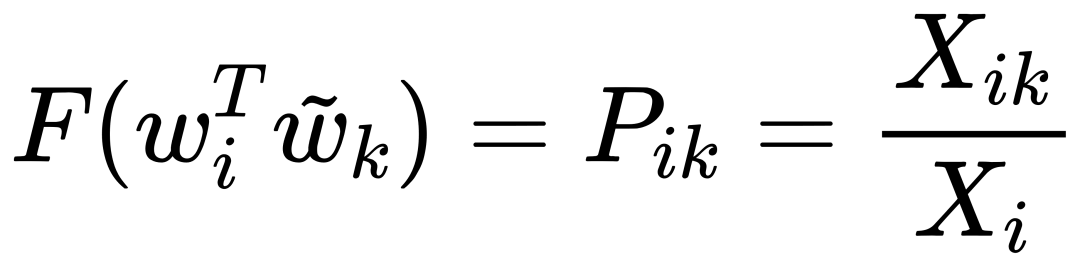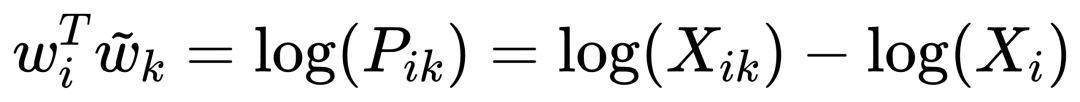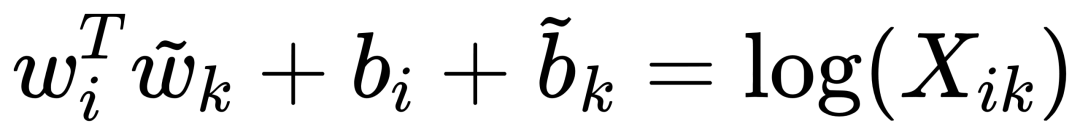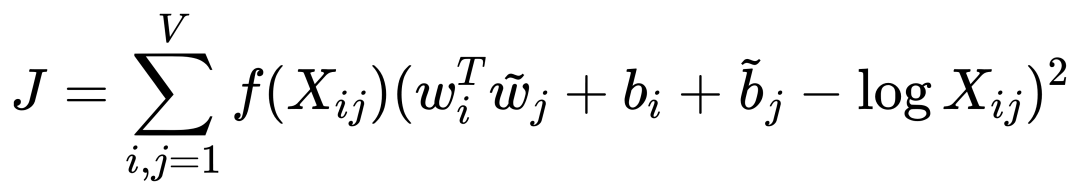GloVe 对于 Word2Vec 和 LSA 的改进
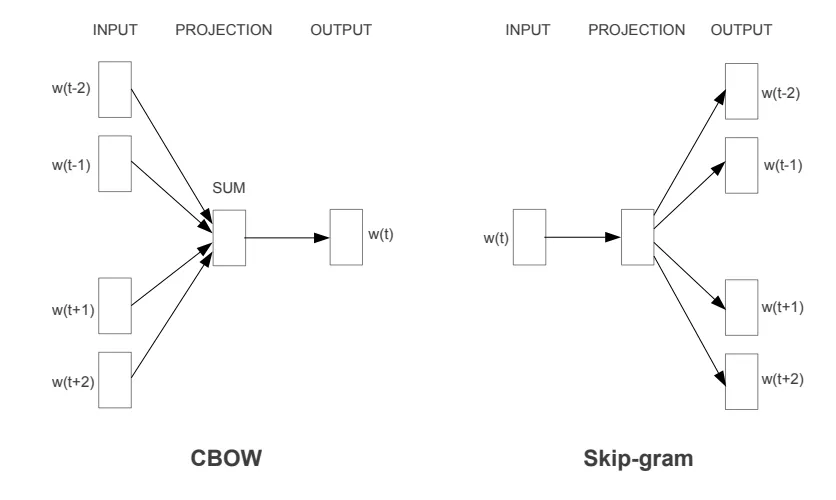
上一篇内容介绍完了 LSA 方法,一个十分简单的全局的 “词-文档” 出现频率统计矩阵,跟矩阵分解算法 SVD 结合来计算词向量的算法。还有在上一周介绍过的 Word2Vec,一个基于局部上下文窗口来计算词向量的算法,其中又分为两种,Skip-gram,根据中心词预测邻居,CBOW,根据邻居预测中心词,但本质都只是看局部分部,只不过 Skip-gram 是 “举一反三”,CBOW 是 “完形填空”。 而 GloVe(Global Vector)方法则试图将两者的优点结合在一起,论文引言中就提到:
虽然像 LSA 这样的方法能高效地利用统计信息 ,但它们在词汇类比任务 上的表现相对较差,这表明其向量空间结构是次优的 。
像 skip-gram 这样的方法可能在类比任务上表现更好,但它们对语料库统计信息的利用很差,因为它们是在独立的局部上下文窗口 上进行训练的,而不是在全局共现计数上进行训练。
GloVe 的原始论文是仅仅在 Word2Vec 发表一年之后的 2014 年发表的《 GloVe: Global Vectors for Word Representation 》。作者不仅详细说明了推导过程,也完全开源了代码跟权重,项目地址目前仍然在: https://nlp.stanford.edu/projects/glove/ 。
概念明确
全局 VS 局部
在开始介绍 GloVe 方法之前,先说明一下前面提到的一对概念,“ 全局 ” 跟 “ 局部窗口 ” 。
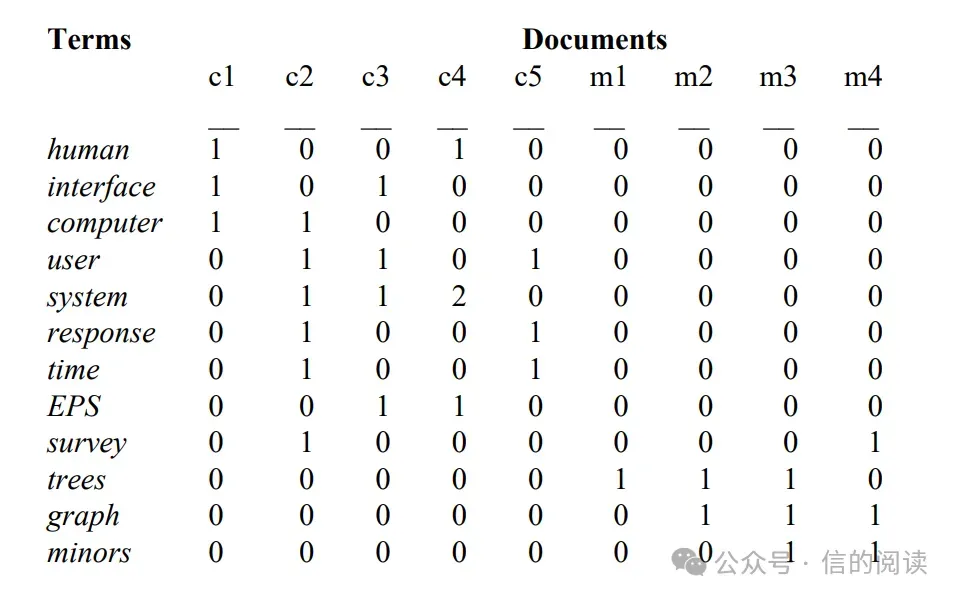
GloVe 提到 LSA 利用了全局信息,这里所指的全局信息是 LSA 基于整个文档数据建立的这个表:
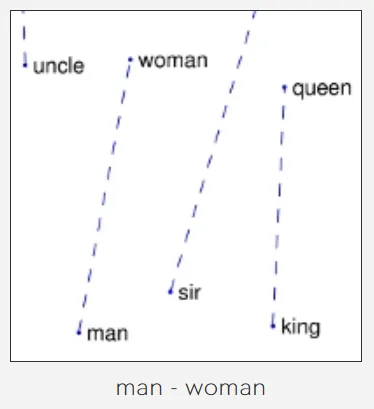
而在 Word2Vec 的训练过程中,每个文字在训练中只关注这个文字在给定上下文窗口的限度内跟其他文字的共现。也就是说 LSA 这种有全局视野的方法能够直接得到某两个内容之间的共现情况,而 Word2Vec 是以一种 “盲人摸象” 的方式一点点摸索两个内容之间的关联,Word2Vec 在遍历过全部文档内容后,其实也建立了全局感知 。 所以论文中的用词也很准确,论文中说这种方式对于全局统计信息的利用很差 ,而不是完全没有。 还有一点,LSA 构建的是 “词-文档” 之间的全局信息,而 Word2Vec 构建的是 “词-词” 之间的局部窗口信息,所有两种方法之间的区别还是很多的。 论文中还提到一个词叫 “ 词汇类比任务( analogy task ) ”,其实这个就是那个最经典的 king – queen = man – women 的任务。这一类任务可以检测算法是不是把某些语义成功映射到了某个空间方向上,在 GloVe 项目中,作者提供了一些非常好的案例: 比如这张图就是 man – woman 会跟其他哪几个词相减是相同方向,其中我们看到了 king – queen,另外两个没显示全,但是我们大概能猜出一个可能是 aunt(阿姨) – uncle(叔叔),一个能是 madam(女士) – sir(先生)。也就是说上面这张图中,这个竖直方向上可能代表了男女性别的含义。 我们看到有 strong(强) – stronger(更强),clear(清晰) – clearer(更清晰),soft(软) – softer(更软),所以类似的,在这张图中这个斜着 45 度左右的方向代表英文中 “er”,也就是 “更加” 如何的含义。 接下来我们就介绍一下 GloVe 是怎么得到这些向量的。
Global Vectors for Word Representation(GloVe)
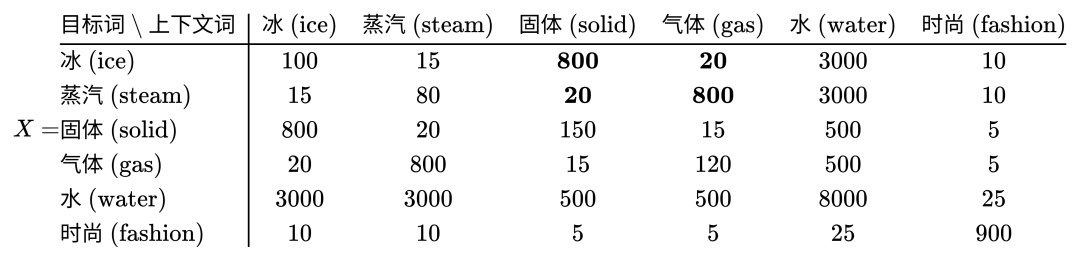
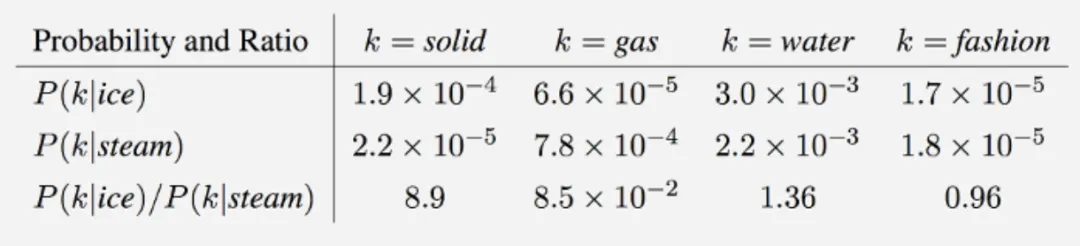
GloVe 这篇论文中我最喜欢的部分无疑是作者使用几个最简单的直观理解跟统计学符号,在几步之内就推导出了整个算法的核心目标。所以接下来我想把这部分讲清楚所有人就都可以理解这个方法是在做什么了。但是这里还是要引入一些符号跟公式,但是这里的推导我认为真的很精彩,所以我会尽量能让所有人都可以读懂。 我们使用符号 X 代表共现矩阵,Xij 就是矩阵的第 i 行,第 j 列。含义就是在所有的文档中,词 j 在 词 i 的上下文中出现的次数,我们这里就用论文中的案例举例说明: 我们的矩阵 X 其实就是一个统计两个词在上下文一起出现的统计矩阵。比如这里的词有 6 个,冰,蒸汽,固定,气体,水,时尚 。 对角线表示的的是行跟列是一个词,代表这个词在自己的上下文里又出现的次数。比如 “冰 ” 跟 “冰 ” 一起出现过 100 词。 而不是对角线的地方代表不同词一起出现的次数,比如 “ 蒸汽 ” 那一行,“ 气体 ” 那一列,就代表在所有文档中,“蒸汽 ” 跟 “ 气体 ” 一起出现过 800 次。 而且你可能注意到,我们这里的矩阵是对称的,也就是说如果 A 跟 B 一起出现过 100 次,那么统计下来 B 跟 A 也是一起出现过 100 次。这在直觉上是对的,但是这取决于我们怎么定义上下文窗口,如果我们定义的上下文窗口是基于目标词左右 N 个词之内,那么这个矩阵就是绝对对称的。但是如果我们对于窗口的定义比如说这个词前面 N 个词,后面 M 个词,M 不等于 N 的话,那么这个矩阵就大概率不是对称的了,但是为了方便我们就用最简单两边相同的窗口方式。 再定义一个符号 Pij ,代表词 j 出现在词 i 上下文的概率。注意这里不同的地方是 “ 概率 ” ,不再是上面 Xij 简单的统计次数,也就是说我们需要统计 i 跟 j 一起出现的次数 Xij ,除以 i 一共出现的次数 Xi ,这个 Xi 在上面的矩阵中是没有的,需要单独统计。比如我们看到 “冰” 和 “蒸汽” 一起出现了 15 次,如果 “ 冰 ” 在文档中一共出现了 100 次的话,那么 P(蒸汽 | 冰) 就是 15%。 基本的几个符号有了共识之后,可以进入思考 GloVe 解决问题的思路了。 这里我们假设有两个词 i 跟 j ,论文中假设说明我们对于热力学概念很感兴趣,那么我们就假设 i 是 ice(冰),j 是 steam(蒸汽) ,我想为啥这俩词跟热力学有关我应该不用多说明了,反正也不重要,就是随便两个词。 此时我们想探究的问题是,这两个词 “冰” 跟 “蒸汽” 语义上到底有什么区别呢?回忆我们是怎么定义一个词的语义的,就是看它周围的词,这意思想我们已经提及过多次了,那么我们随便找一个在他俩周围都出现过的词 k ,比如 k 是 “solid(固体)” 。 我们现在所有的信息就是前面那个统计的表格,所以我们不妨使用一下,假设根据统计我们可以计算出来 P(固体 | 冰) 跟 P(固体 | 蒸汽) ,也就是这两个词分别跟 “固体” 的共现概率。前面我们提到了,我们想知道这两个词在语义上有什么 “区别”,也就是说我们不能单独的看这两个概率,而是要对比这两个概率的区别,那么对比区别就有两种方法,一是把两个概率相减,二是把两个概率相除,谁更好呢? 这里我们虚构两组概率来对比,目标对比词是 “冰” 跟 “蒸汽”,邻居词是 “固体” 跟 “水”:
P(固体| 冰) = 0.001
P(固体 | 蒸汽) = 0.00001
P(水 | 冰) = 0.40
P(水 | 蒸汽) = 0.30
由于我们数据的分布问题,“固体” 整体出现的次数很少,所以有关固体的概率整体偏小。而 “水” 在我们文档中出现次数很多,有关它的概率也整体偏大。 如果我们使用概率对比想看到这个区别的话,如果我们使用减法:
固体: 0.001 – 0.00001 = 0.00099
水: 0.40 – 0.30 = 0.10
如果只看这个减法的结果,我们会认为,“水” 这个词对于区分 “冰” 跟 “蒸汽” 的能力远远大于 “固体” 这个词对于区分 “冰” 跟 “蒸汽” 的能力,因为 0.1 >> 0.00099。但这明显是不对的。 我们作为人类,能够从语义上感知到,“固体” 这个词跟 “冰” 更相关,而跟 “蒸汽” 没那么相关,而 “水” 跟两者都相关,所以能区分 “冰” 跟 “蒸汽” 含义的,分明是 “固体” 而不是 “水”。
固体: 0.001 / 0.00001 = 100
水: 0.40 / 0.30 = 1.33
这样的结果就符合预期了,“ 固体 ” 区分 “冰” 跟 “蒸汽” 的能力几乎是 “水” 的 100/1.33 = 75 倍 。这里的原因很明显,除法能够消除在数据分布上不均衡的问题从而消除语义之外的干扰。
第一:词向量学习的适当起点应该是共现概率的对比,而不是概率本身
第二:对比应该使出比率(除法),而不是差值(减法)
因为我们的最终目标是得到每个词的词向量,假设对于词 i 的向量是 wi ,词 j 的向量是 wj ,而这个中间词 k 的向量是 wk 。 所以对于两个目标对比词 wi, wj , 跟这个中间词 wk ,我们可以得到 wi 跟 wj 的语义区别可以由下面关系表达: 等式右边是我们上面推论的共现概率比率,而等式左边的 F 是我们希望能找到的某个方程或者模型 F ,它能计算词向量之间的某些关系,从而使得这个计算结果符合我们在数据中观察到的这个概率比率。 我们知道每个词的 w 本质上就是一个某个维度大小的向量,我们也知道我们想要构建 king – queen 的类似的向量关系,而且这个向量空间也允许我们做这样的操作,因为向量空间支持线性操作 ,所以最自然的方法就是我们把 F 中 wi 跟 wj 的关系定义为减法,上面的公式就变成: 接下来我们注意到,式子左边都是向量操作,即使向量加减之后仍然是向量 ,而式子右边是一个数字 ,那么我们如何自然的把向量变成一个数字呢?当然 F 可以是一个复杂的神经网络把输入向量映射成一个数字,但是神经网络的非线性本质会混淆我们试图捕获的向量间的线性关系 ,所以最自然的方式是使用向量之间的点积: 如果我们把 F 里面的第一个式子 wiwk 看成 A ,第二个式子 wjwk 看成 B ,那公式就是: 接下来的变化就有点像魔术,需要一点数学的直觉了。现在方程的 左边是一个函数里面装着减法 ,右边是两个数字做除法 。这怎么能扯上关系呢?我们要不然试试让 wiwk 就是 Pik , wjwk 就是 Pjk ,那么我们就能得到: 关于这一步我想说明的是,这里没有严格的数学推导,更多的是一种符合数学直觉的模型构造,因为我们的目标就是在试图构造一个模型,本身就没有正确答案,所以只要内在逻辑自洽,我们可以让符合条件的两个数字之间对齐,这本身就是模型建构的过程。 这里我们又可以根据数学关系上看出 F 可以使用指数函数 exp ,因为指数函数就符合这个关系: 得到了上面的关系之后我也就是说我们可以使用下面的关系: 其中右边分子分母的 F 都 可以写成类似下面这样的概率计算展开: 所以把 F 替换成 exp, 两边同时再使用 log 后 , 我们可以得到: 此时回忆,我们前面提到,我们如果定义合适的话,两个词的互相出现统计是完全对称的。观察上面的式子我们发现要不是式子右侧的 log(Xi) ,我们可以完全等价交换 i 跟 k ,因为整个式子中只有 log(Xi) 是不依赖于 k 的。但是也恰恰由于它是独立于 k 的,我们不妨假设他是有关于 i 的一个偏置常数 bi ,为了对称性,我们也给 k 增加一个偏置常数 bk ,则可以得到: 这种增加偏置常数的操作是模型构建中常用的技巧,它不会影响模型的训练,因为如果我们不需要它那么模型会学习到这个常数为 0。 到了这里我们就完全构建了我们假设的向量 wi, wk ,跟共现概率 Xik 之间的线性关系,如果将他们移动到等式一侧就是我们的损失函数了。但是这里有一点小问题需要解决,因为很多词之间可能完全不会一起出现,这会导致 Xik 是 0 ,那么 log(0) 是发散到无穷大的,这会破坏我们模型的收敛,解决方法是我们可以人为的给那些 Xik 为 0 的位置设置 0 权重,使得他们不参与最终的计算。这样做的额外好处是,我们还可以给那些一起出现次数过多的 Xik 增加一个限制性的权重,比如一起出现次数多于 1000 就不再增加了,于是我们人工设置这样一个权重矩阵 f(Xij) ,得到最终的损失函数 J : 观察这个损失函数,所以我们最终得到的模型非常简单,我们只需要一个 基础的 embedding 层,是每个单词的 w 向量,然后查询每两个词之间的共现频率的 log 值,最小化这两个值之间的差异就好了。最后我们看一看真实计算出来的 GloVe 模型在上面 “冰”,“蒸汽” 案例的统计结果,其中比率越大(远高于1),或者越小(接近0)都是能够有效区分含义的词: 项目也给出来了最终所有词汇的向量可视化图,其中横坐标是所有单词,纵坐标是对应单词的向量: 而由于能画出这样一张图,也恰恰暴漏了 GloVe,Word2Vec,LSA 这些算法最致命的问题,每个单词只有固定的词向量 ,而这在现实中是不正确的,这也是我们下一周要讨论的话题。
 夜雨聆风
夜雨聆风