夜雨聆风
夜雨聆风





AI对存储的影响:趋势、挑战与 SSD技术演进 | SNIA-SDC Storage 2026(Kioxia)

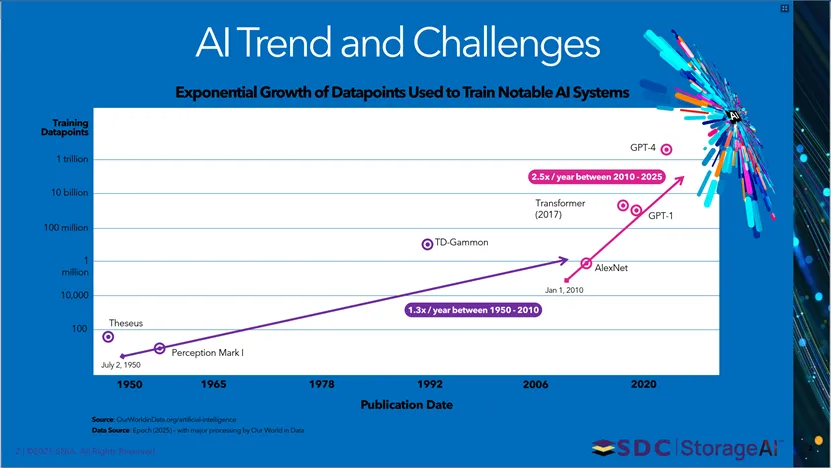
本页核心展示AI训练数据点的指数级增长趋势。1950-2010年AI系统训练数据点年增速为1.3倍,2010-2025年增速提升至2.5倍/年;从1950年Perception Mark I的100个数据点,逐步增长到TD-Gammon的百万级、AlexNet的万级、Transformer(2017)的1亿级、GPT-1的10亿级,直至GPT-4达到1万亿个训练数据点,直观体现AI训练数据规模的飞速扩张。
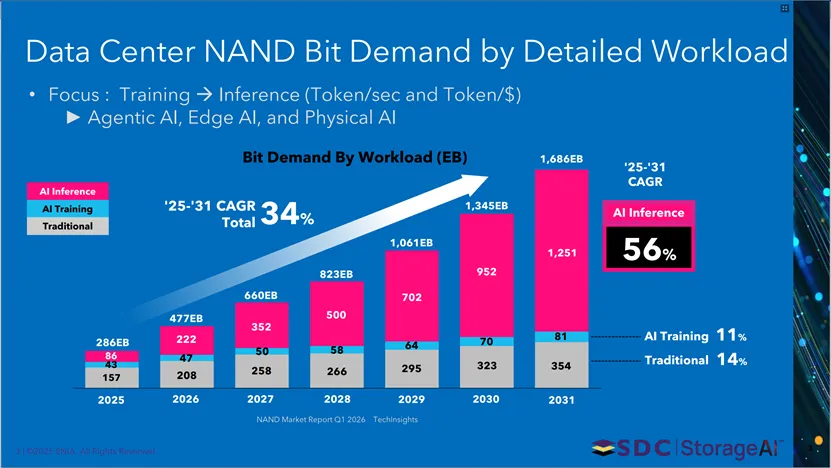
本页呈现2025-2031年数据中心NAND闪存比特需求按工作负载的分布与增长情况。总NAND比特需求中AI推理占比56%、AI训练占11%、传统负载占14%;2025-2031年AI推理比特需求复合年增长率(CAGR)为34%,AI训练与传统负载也保持相应增长,同时明确AI存储焦点从训练转向推理(关注Token/秒、Token/美元),并延伸至智能体AI、边缘AI与物理AI领域。
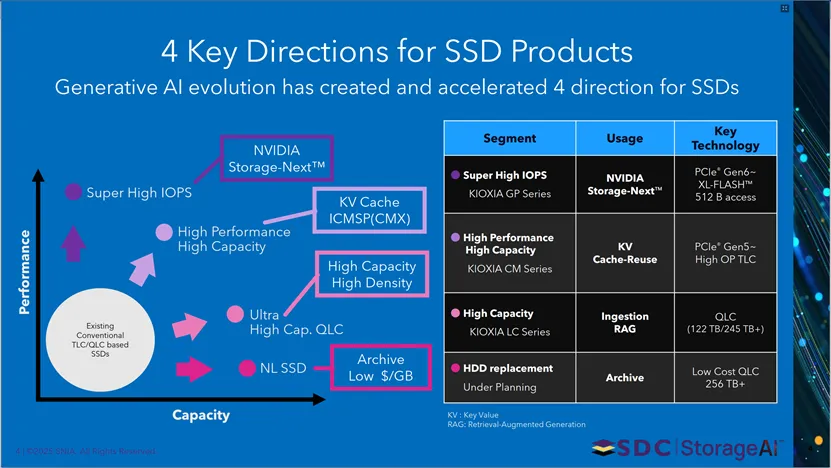
生成式AI发展推动SSD产品走向四大方向,并搭配铠侠SSD系列方案说明。四大方向分别为超高IOPS、高性能高容量、高容量、低成本归档;同时列出铠侠对应SSD系列:GP系列适配NVIDIA Storage-Next,采用PCIe Gen6~与XL-FLASH 512B访问;CM系列面向KV缓存复用,基于PCIe Gen5~高OP TLC;LC系列用于数据摄取与RAG,采用QLC(122TB/245TB+);规划中替代HDD的方案面向归档,采用低成本QLC(256TB+)
本页介绍NVIDIA Storage-Next技术,核心是通过NVMe SSD扩展GPU内存。该技术解决HBM高带宽内存扩展受限、成本高昂的问题,可支持10-100倍更大数据集;支持GPU发起I/O(软件栈为NVIDIA SCADA),采用细粒度I/O大小(512字节),可实现单GPU约200M IOPS的超高IOPS性能,基于NVMe/PCIe接口实现。

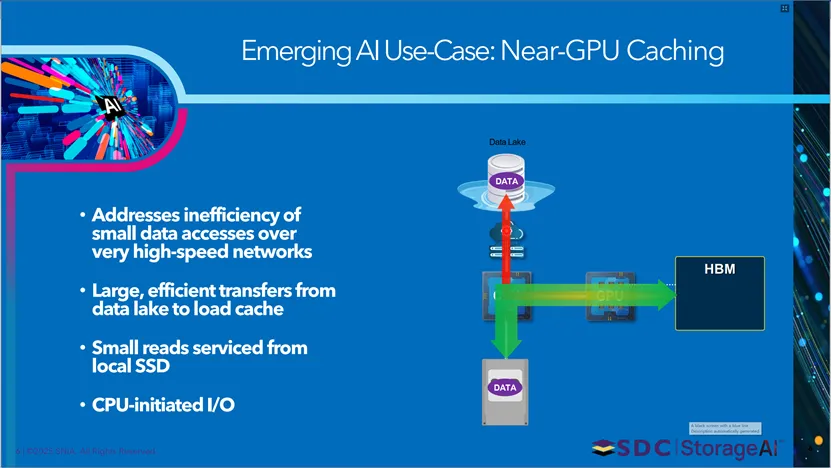
本页讲解新兴AI用例——近GPU缓存。该方案解决高速网络中小数据访问效率低的问题,数据湖以大体积高效传输方式将数据加载至缓存,小规模读取请求直接由本地SSD服务,由CPU发起I/O操作,优化AI场景下数据访问的效率与延迟。
本页介绍NVIDIA ICMS(推理上下文内存存储平台),由BlueField-4赋能,面向亿级规模推理与智能体AI。该平台为长上下文处理的AI系统提供快速长短时记忆,扩展AI智能体长期记忆,支持集群级上下文高带宽共享,提升Token/秒与能效;核心能力包括Rubin集群级KV缓存、5倍于传统存储的能效、硬件加速KV缓存部署等,2026年下半年推出,铠侠正与NVIDIA明确适配SSD需求,将采用PCIe Gen5/Gen6 TLC NVMe SSD。

本页列出AI场景下SSD的六大高层核心需求:512B随机读取优化、更高的耐用性、高队列深度、液冷支持、多发起者访问、更大容量。

本页聚焦SSD 512B随机读取优化的技术要点。需优化新的ECC布局,无需绑定IU大小;满足高并发要求,举例说明:若读取延迟45μ秒,实现25M IOPS需重叠1125个并行I/O;若读取延迟25μ秒,需重叠625个并行I/O。

本页继续阐述512B随机读取优化的并发逻辑。以读取延迟45μ秒为基准,要实现每40纳秒完成一次I/O的效率,必须通过大量并行I/O重叠执行,满足超高IOPS下的并发读取需求。

本页说明AI场景下SSD耐用性提升的需求。AI工作负载特性与传统场景截然不同,推动pSLC、pMLC闪存技术应用;过度配置(OP)是提升耐用性的方案之一,需区分缓存与长期存储场景,耐用性要求从3 DWPD提升至100 DWPD。

本页讲解SSD高队列深度的重要性。高队列深度会影响I/O调度效率,可能引发队头阻塞问题,同时直接关系到整体I/O延迟表现,是AI高并发场景下SSD的关键指标。

本页分析SSD液冷方案的核心关注点。液冷主要解决高功率散热问题,提升数据中心能效,同时面临散热设计标准化的行业挑战。

本页阐述SSD多发起者访问的技术要点。支持多发起者直接访问文件系统数据,实现LBA范围租约管理、租约与发起者映射、快速路径执行;同时需应对碎片化、数据保护等技术难题。

本页说明SSD大容量化的背景与挑战。AI数据持续增长驱动大容量需求,同时需考虑pSLC、pMLC产品型号精简与库存管理问题,平衡容量与供应链效率。

本页介绍铠侠适配NVIDIA Storage-Next的超高IOPS GP系列SSD规划。基于XL-FLASH技术,当前模拟器可实现100+M IOPS,支持GPU发起I/O(搭配NVIDIA SCADA);2026年底推出PCIe 6.0、第二代XL-FLASH的评估样片,实现512B随机读取10M IOPS且功耗低于25W;2027年推出PCIe 7.0、第三代XL-FLASH产品,实现约100M 512B随机读取IOPS。

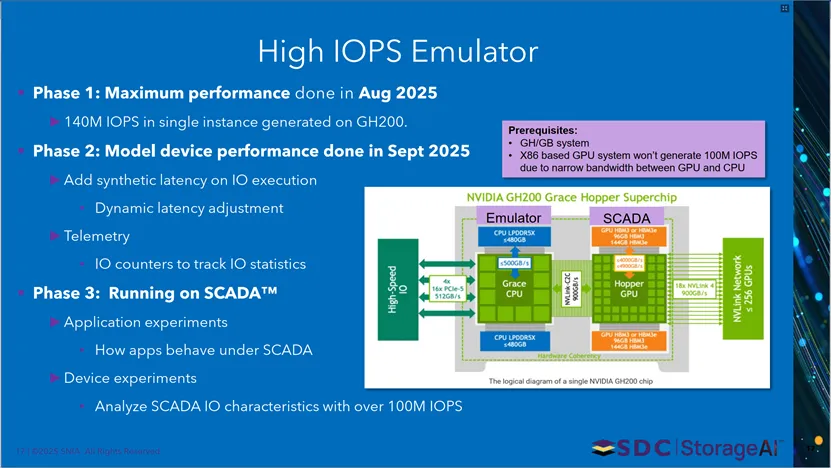
本页介绍铠侠超高IOPS模拟器的研发阶段与硬件基础。第一阶段2025年8月实现GH200单实例140M IOPS;第二阶段2025年9月添加合成延迟、动态延迟调整与遥测统计;第三阶段基于SCADA运行应用与设备实验;仅NVIDIA GH200超级芯片可支撑100M+IOPS,X86 GPU系统因GPU-CPU带宽不足无法实现。
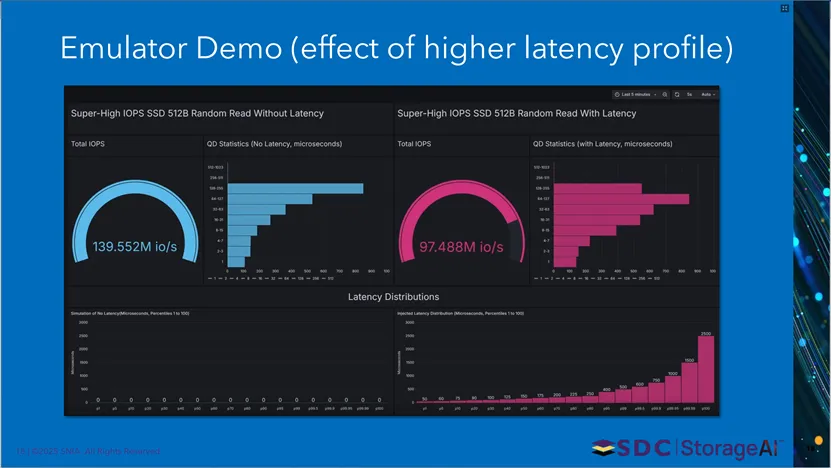
本页展示超高IOPS模拟器延迟测试效果。无延迟配置下实现139.552M IOPS,添加延迟后为97.488M IOPS,同时呈现不同队列深度下的IOPS分布与延迟分布情况,验证延迟对SSD性能的影响。
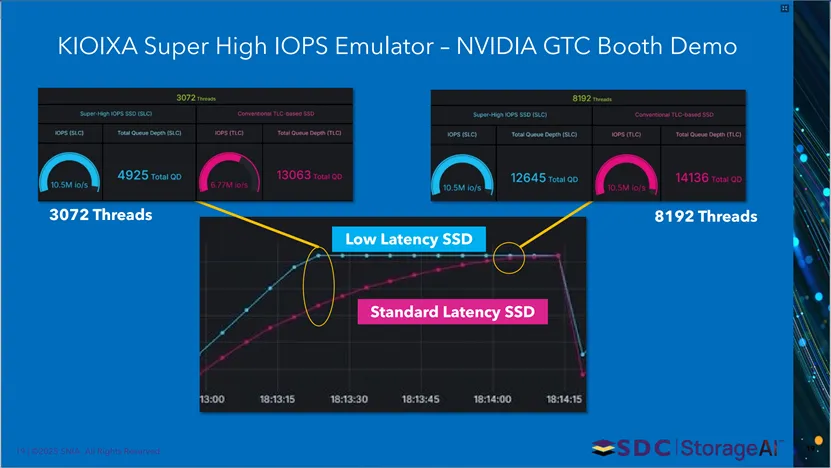
本页对比铠侠超高IOPS SLC SSD与传统TLC SSD的性能。3072线程下,SLC SSD达10.5M IOPS,队列深度远低于TLC SSD;8192线程下,二者IOPS持平,但SLC SSD队列深度仍更低,体现SLC架构在低队列深度下实现高IOPS的优势。
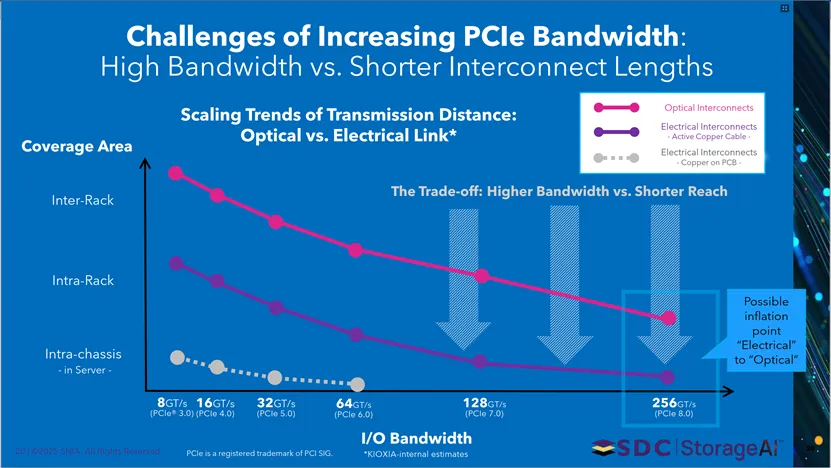
本页分析PCIe带宽提升的传输距离挑战。随着PCIe版本从3.0到8.0迭代,I/O带宽从8GT/s提升至256GT/s,但电气互连传输距离持续缩短,呈现高带宽与短传输距离的矛盾;未来互连趋势将从机箱内、机架内、机架间的电气连接,逐步向光互连演进。