 夜雨聆风
夜雨聆风





AI让我更累了:一个每天用AI工作的人的真实体感
我花了三个月设计了一套上下文管理系统——怎么压缩对话、怎么分层加载记忆、怎么在有限的窗口里塞进最多信息。然后Claude出了1M context版本,三个月的活,一个版本号吃掉了
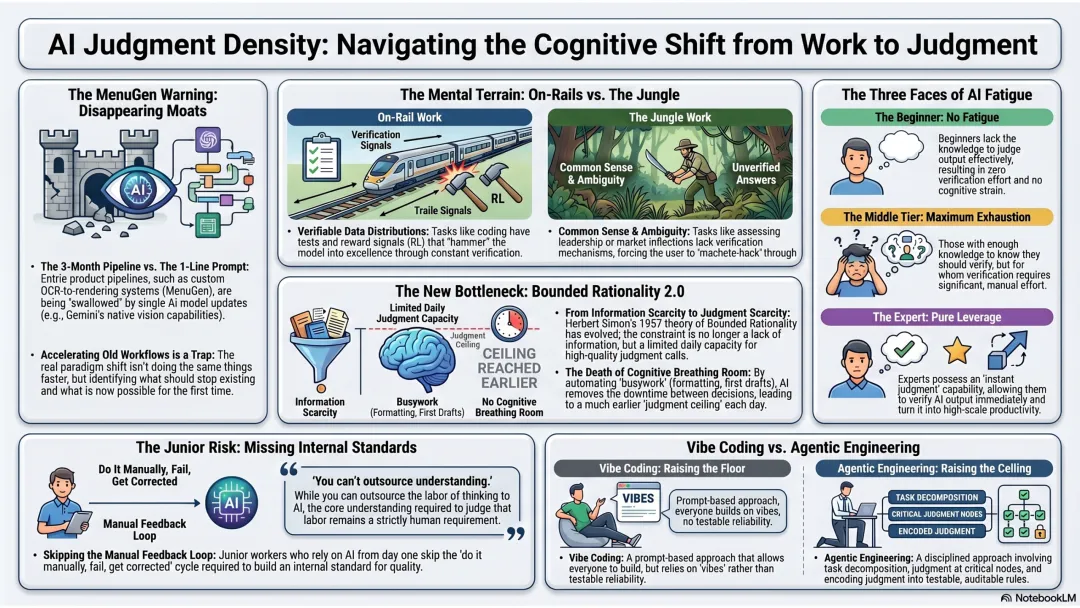
1. 这不是抱怨。当时那套系统确实解决了真实问题。但它构不成门槛。Karpathy在Sequoia Ascent 2026上讲了一个类似的故事:他做了一个叫MenuGen的App,完整的技术流水线——OCR识别菜单、图像生成配图、渲染输出。然后Gemini一句prompt把整件事干掉了。他的原话:「我的整个MenuGen是多余的,它不应该存在」
2. 每次范式转移里最容易掉进去的陷阱就是用新工具加速旧范式。PC出来的时候想的是打字比手写快,互联网出来的时候想的是查资料比去图书馆快。这些判断都没错,但都不是最重要的那个。最重要的判断是:什么东西原来根本做不了,现在第一次变得可能了
3. Karpathy说了一个我觉得密度很高的观点:模型的「蠢」不是bug,是商业决策的结果。为什么同一个模型能重构十万行代码库、能发现零日漏洞,但你问它50米外的洗车店应该走路还是开车,它告诉你走路?因为代码能跑测试、有清晰的reward signal,所以被反复训练到极致。常识判断没有这种验证机制,实验室也没有商业动力去覆盖——训练代码能力值钱,训练「50米该开车」不值钱。他的比喻很准:在数据分布里你在铁轨上飞驰,在数据分布外你在丛林里挥砍刀
4. 这对我每天的体感解释力很强。我自己会写代码,让AI帮我做编程、跑数据、处理结构化的问题——铁轨上的活,输出质量稳定,放心用。但涉及到需要行业经验的判断、需要读懂人的场景、需要在模糊信息里做决策——这些是丛林里的活。模型给你十个看起来合理的答案,每个都有理有据,但每个都经不起你多追问一句
5. 但这里有一个大多数人没讲的问题:AI让我变累了,不是更轻松了。以前做水活的时候——整理材料、排版文档、写初稿——这些活虽然无聊,但中间有喘气的间隙,脑子有放空的时候。现在这些全交给AI了,留下来的全是需要你拍板的判断。以前一天可能做十个判断,现在可能做四五十个。产出确实多了,但认知负荷不降反升。你的大脑像一台CPU,以前有idle time,现在跑满了
6. 我观察到人面对这个大致分三类。第一类,纯小白,什么都不懂,完全听AI的,反正也判断不了,不累。第二类,特别强的人,一秒钟知道对不对,AI在手里是纯杠杆,也不累。第三类,中间的人——知识够用,知道要判断,但判断起来费力。这是最累的一群
7. 为什么中间这类最累?Herbert Simon 1957年提出有限理性:人的决策不是最优化,是认知资源约束下的「够好就行」。AI没有消除这个约束,只是把它推到了更高的层级。以前瓶颈是信息不够,现在信息过剩,瓶颈变成了判断力本身。你一天能做多少个高质量判断,这个上限比以前更早被触达
8. 对更junior的人来说处境可能更难。传统成长路径是手动做一遍、犯错、被前辈纠正、慢慢积累pattern recognition。这个过程痛苦但有效——你从错误中建立起「什么是好的」的内在标准。但如果一上来就让AI做,你跳过了手动那步,也就跳过了整个反馈循环。等到AI犯了一个看起来很合理的错误,你分辨不出来,因为你从来没有自己做对过
9. Karpathy把这分成了Vibe Coding和Agentic Engineering。Vibe Coding提升下限,所有人都能用自然语言驱动开发。Agentic Engineering拉高上限——设计系统、分解任务、验收结果、在关键节点做判断。你管理的是一群能力极强但偶尔犯蠢的实习生
10. 他引了一句话:「你可以外包你的思考,但不能外包你的理解。」我自己的版本是:不能工程化的东西就是不靠谱的。所以我的应对不是更快地用AI,是把judgment编码成规则——让AI在规则内工作,让规则可测试、可审计、可迭代。这不是vibe coding,这是把判断变成工程
11. 这大概也是真正该想的事:别问AI让什么变快了,问它让什么不该存在了、什么第一次变得可能了。我那套context管理系统是前者,被一个版本更新吃掉了。但我这些年积累的领域判断是后者——你在一个行业扎了多少年、见过多少人、踩过多少坑,这些模型替代不了。那些靠包装模型缺陷生存的中间层,模型进步一代就消失一层。留下来的,是你对问题本身的理解——这个外包不了