 夜雨聆风
夜雨聆风





【综述】 智能体AI如何重塑软件开发生命周期:从代码补全到人类监督下的委托执行
导读
2021年,GitHub Copilot的发布让全球软件工程师首次在日常工作中接触到生成式AI工具。当时,这款工具的本质是一个“超级自动补全”:开发者编写代码,模型给出建议,人类决定接受或拒绝。五年之后的今天,游戏规则已然改写。当前最前沿的智能体系统——包括Anthropic的Claude Code、OpenAI的Codex CLI、Google的Jules、Cognition的Devin,以及开源项目OpenHands和SWE-agent——已不再仅仅是补全代码,而是在执行真正的工程工作:阅读整个仓库、跨多个文件制定计划、执行Shell命令、运行测试、观察失败、修正方案,并提交最终变更。
本文作者Happy Bhati系统梳理了这一从“代码补全”到“智能体化编程”的转变,提出了一个六层参考架构来组织智能体软件工程系统的设计空间,并整合了来自性能基准(SWE-bench Verified从1.96%飙升至78.4%)、生产力研究(13.6%-55.8%的时间节约)以及劳动力市场影响(Anthropic 2026年调查显示49%的职位中AI被用于至少四分之一的任务)的多维实证证据。这篇文章的核心价值在于,它明确指出软件工程的核心研究对象已从“代码生成”转向“人类监督下的委托执行”,并为这个领域识别了五个亟待解决的开放问题。对于关心软件开发未来走向的研究者、从业者与技术管理者而言,这是一份不可多得的全景式综述。

摘要
大型语言模型(LLMs)具备多步推理、工具使用和长程规划能力,引发了软件工程的质变。早期代码补全工具(如GitHub Copilot)在单行或单函数粒度上运作,而现代智能体系统(如Claude Code、OpenAI Codex CLI、Google Jules、Devin、OpenHands、SWE-agent、MetaGPT、ChatDev以及DeepMind的AlphaEvolve)则在仓库、功能或算法粒度上运作。本文整合了来自Anthropic、OpenAI、Google DeepMind、Microsoft Research、Princeton、Stanford以及更广泛学术社区的工作,以刻画这一转变。论文提出了智能体软件工程的六层参考架构,对比了传统的软件开发生命周期(SDLC)与新兴的智能体SDLC(A-SDLC),并整合了关于性能(SWE-bench Verified基准从2023年10月的1.96%跃升至2026年4月的78.4%)、生产力(受控研究中13.6%-55.8%的时间节约)以及劳动力市场影响(Anthropic 2026年调查显示49%的职位中AI被用于至少四分之一的任务)的实证证据。作者论证说,核心研究对象已从代码生成转向人类监督下的委托执行。论文识别的五大开放问题——评估、治理、技术债务、技能再分配和注意力经济学——将决定智能体化转型是否对该学科产生净正面影响。
引言:论文要解决什么问题
论文要解决的核心问题是什么?简而言之:当智能体AI系统具备多步推理、工具使用和长程规划能力时,它们将如何彻底改变软件工程的实践方式?从2017年Transformer架构问世,到2021年GitHub Copilot首次将生成式AI带入主流开发者的日常工作流,再到今天智能体系统能够在真实仓库中自主解决实际GitHub Issue,这一演变速度之快、影响之深,已经超出了传统软件工程方法论所能应对的范畴。
作者将这一变迁刻画为一场“认知契约”的重新谈判。在Copilot时代,人类的角色是工程师,模型只是具备判断力的自动补全工具。然而到了2026年,像Claude Code这样的系统已经能够独立完成从仓库阅读、跨文件计划、Shell命令执行到测试运行与方案迭代的全套流程。在Anthropic内部,大多数代码已由Claude Code生成;在Princeton的SWE-bench Verified基准上,最先进系统的性能从2023年10月的1.96%跃升至2026年春季的约78.4%。
因此,这篇论文需要回答的核心追问包括:这种质的转变给软件开发周期带来了哪些结构性变化?新的架构范式是怎样的?当前有哪些实证证据可以量化这种转变的生产力和劳动力市场影响?以及,为了确保这一转型对软件工程学科产生净正面影响,我们必须优先解决哪些开放问题?
针对这些问题,论文做出了四项贡献:第一,系统综述了来自主要工业实验室和学术团体的智能体编程相关主线工作;第二,提出了六层参考架构来组织智能体软件工程系统的设计空间;第三,对比了传统SDLC与新兴的智能体SDLC;第四,整合了关于性能和劳动力市场效应的实证证据,并识别了五个构成领域近期研究议程的开放问题。
方法:核心思路与技术路线
作为一篇综述论文,本文的方法主要体现在其系统性的文献整合与架构设计上,而非提出一个具体的新技术方案。核心思路可以分解为两条主线:一是“从代码补全到智能体的演变”这一历史视角的梳理,二是“六层参考架构”这一结构化视角的构建。
在“从代码补全到智能体”这条线索上,作者回顾了关键节点的技术突破。最早的基于LMs的编程工具在HumanEval和MBPP等单函数合成基准上进行评估,这些基准很快饱和(到2024年,前沿模型在HumanEval上的pass@1已超过90%)。单函数评估的饱和促使Princeton的Jimenez等人于2023年10月引入SWE-bench,一个包含2294个GitHub Issue的基准,来自12个成熟的Python仓库。原始报告显示,没有任何系统能解决超过2%的问题。转折点出现在SWE-agent(NeurIPS 2024)的提出:通过设计一个定制的智能体-计算机接口,即使在使用相同底层模型的情况下,分辨率也提升到了12.5%。这一洞察——即智能体的接口设计与模型能力同样重要——从此塑造了整个领域的发展方向。
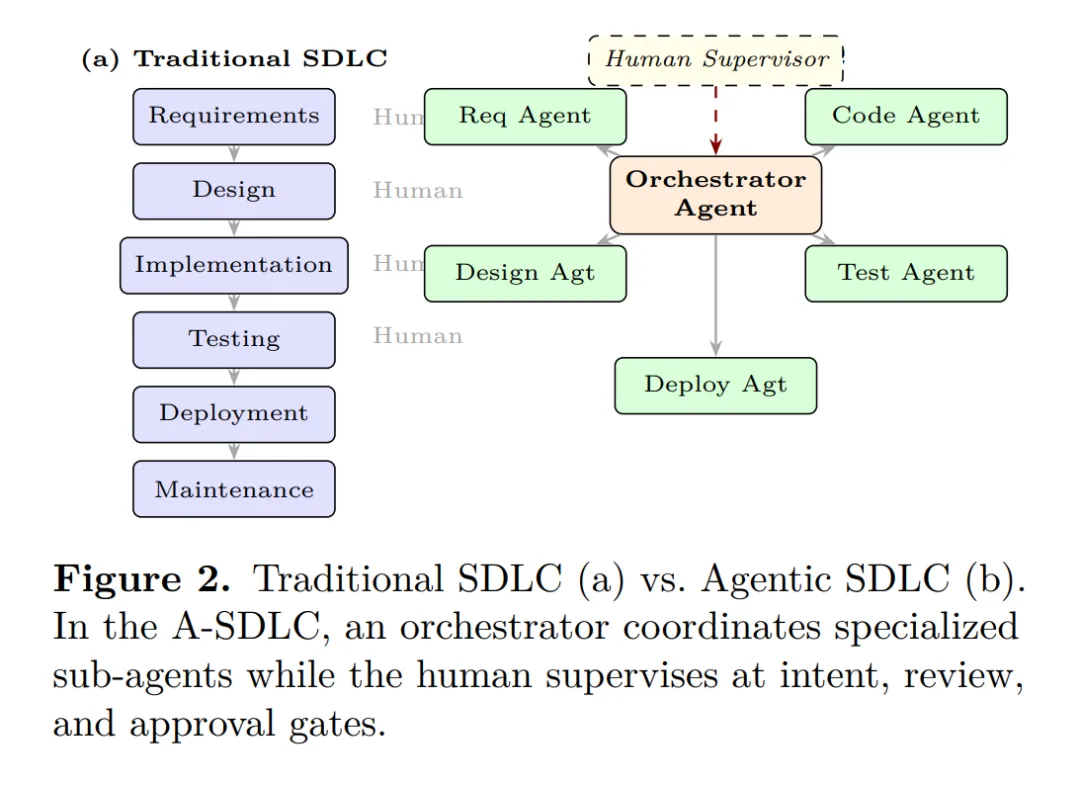
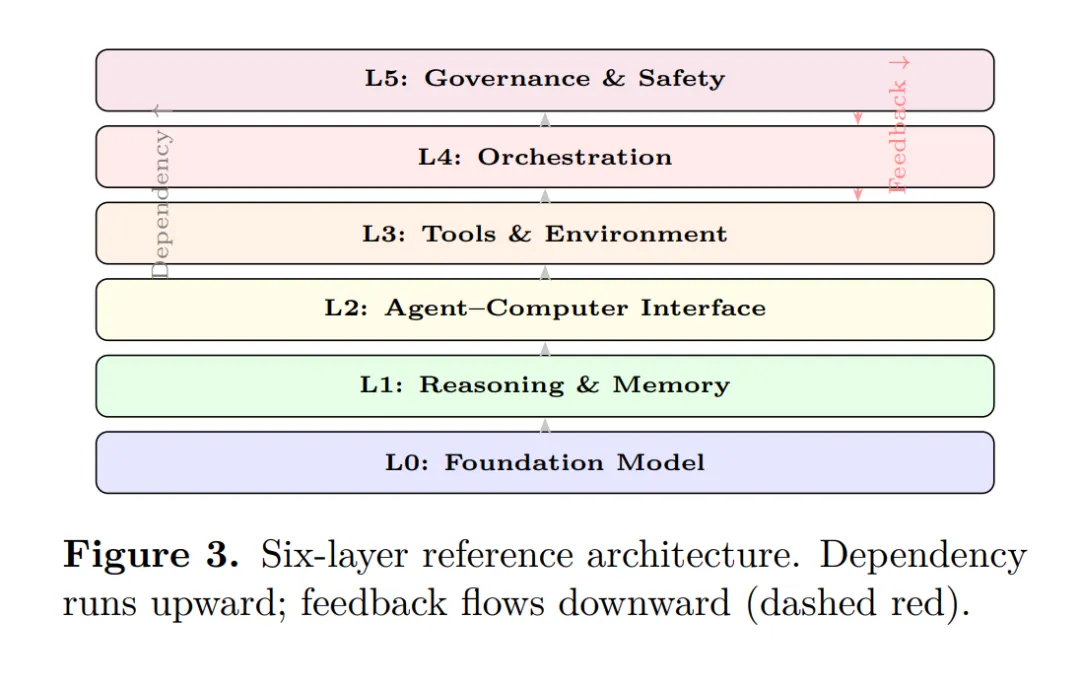
在六层参考架构方面,虽然论文正文节选未提供该架构的详细逐层描述,但从摘要和后续讨论中可以推断,该架构用于组织智能体软件工程系统的设计空间。每一层处理系统的不同抽象级别,从底层的模型能力到顶层的治理与监控。与之配套的,论文对比了传统软件开发周期(SDLC)与新兴的智能体SDLC(A-SDLC)。传统的SDLC遵循从需求、设计、编码、测试到部署和维护的线性或迭代过程,其中人类在每个阶段处于核心地位。而A-SDLC的核心特征是“委托执行”:人类设定目标和审核结果,智能体系统负责执行多步骤的工程工作。这种转变意味着软件工程的核心研究对象已经从“如何生成代码”变成了“如何设计委托机制并保持人类的监督控制”。
实验:设置、指标与结果
作为一篇综述论文,本文的实验部分本质上是汇总和分析已发表的研究结果。论文整合了来自多个来源的实证证据,覆盖性能、生产力和劳动力市场影响三个维度。
性能指标:SWE-bench Verified基准
论文追踪了SWE-bench Verified基准上的前沿系统性能演变。SWE-bench是一个测试系统能否解决真实GitHub Issue的基准,要求系统导航真实代码库、定位相关文件、编写补丁问题并通过项目隐藏的测试套件。SWE-bench Verified是OpenAI与SWE-bench作者合作发布的489-task子集,筛选了那些更明确可解的Issue。
主要结果如下:
- 时间线演变
性能从2023年10月的1.96%(当时最佳系统)飙升至2026年4月的约78.4%(由Claude Opus 4.7达到)。中间里程碑包括:2024年中期约20%、2024年底约40%、2025年中期约60%左右。 - Agentic系统的影响
SWE-agent通过设计定制的智能体-计算机接口(ACI)将分辨率提升至12.5%,即使在未更换底层模型的情况下。这一发现证实了脚手架(scaffolding)设计与接口工程对系统性能的关键作用。
生产力指标
论文汇总了多个受控研究和观察性研究:
- GitHub Copilot受控实验
Microsoft Research的研究显示,使用Copilot的开发者完成HTTP服务器任务的速度比控制组快55.8%。 - 大规模用户分析
对934,533名Copilot用户的分析发现,建议接受率约为30%。基于这一数据,预测到2030年累计GDP影响可达1.5万亿美元。 - 更广泛的Agentic系统
论文提及其他研究中的生产力提升范围在13.6%到55.8%之间。
劳动力市场影响
- Anthropic 2026年调查
在Anthropic 2026年的经济指数调查中,49%的工作样本中AI被用于至少四分之一的任务。这意味着AI系统已不再仅仅是辅助工具,而是已经开始实质性改变劳动力市场的任务分配。 - AlphaEvolve的算法发现
Google DeepMind的AlphaEvolve采用进化循环方法,非直接用于解决GitHub Issue,而是用于算法发现。其成果包括: -
发现了新的4×4复杂矩阵乘法算法(使用48次标量乘法,优于Strassen的1969年结果) -
将20%的五十个开放数学问题向前推进 -
在Google的整个数据中心恢复0.7%的计算量 -
产生了训练Gemini的FlashAttention内核23%的加速
消融/分析
原文未明确说明消融实验或系统性分析的结果。
结论:贡献、局限与启发
核心贡献
论文的四项核心贡献已在前文详述,这里再提炼其最重要的判断:软件工程正处于一场不连续性之中。2021年人们还在追问语言模型能否合理补全一个函数,而到了2026年,前沿智能体系统已经能解决大约五分之四的真实GitHub Issue(来自成熟仓库),并且非微不足道比例的代码在主要AI实验室中是由这类系统编写的。
局限:五个开放问题
论文识别了决定智能体化转型是否对该学科产生净正面影响的五大开放问题:
- 评估问题
:如何设计超越SWE-bench的基准,以评估智能体系统的多步骤推理、工具使用、长程规划以及跨仓库协作等能力?评估框架需要从“是否通过测试”转向“是否正确决策”。 - 治理问题
:当智能体自主执行工程工作时,如何确保确定性(确定性回归控制)、可审计性(谁对失败负责)、安全性(防止恶意代码注入)和知识产权归属?现有的软件开发治理框架并未设计用于处理自主代理。 - 技术债务
:智能体生成的代码是否会比人类编写的代码引入更多的技术债务?已有研究(如Bauer et al. 2025)表明,AI辅助编程可能增加经验开发者的技术债务和运维负担。 - 技能再分配
:软件工程师所需的核心技能正在从“写代码”转向“定义需求、设计审核机制和治理框架”。这种技能再分配将如何影响培训、招聘和职业发展路径? - 注意力经济学
:当智能体能够生成大量代码变体时,人类的注意力将成为稀缺资源。如何确保人类监督者能有效地区分哪些任务需要人工干预、哪些可以放心委托?
启发
作者整体持“审慎乐观”的态度。智能体系统是真正的生产力工具,而非玩具。但错误的视角是“代码生成”,正确的视角是“人类监督下的委托执行”。长期赢家将是那些在委托执行所需的过程、治理和技能上最先投资的人。软件工程研究的议程,归根结底,是保持人类牢牢掌握主动权,同时让机器负责“打字”。
专知便捷查看,访问下面网址或点击最底端“阅读原文”
https://www.zhuanzhiai.com/vip/2124c02009a0e94de9584d51f1c4b653

点击“阅读原文”,查看下载本文