OpenAI用1.3万条数据打败了自家千亿参数模型,靠的是什么
他最近在选模型,试了一圈之后跟我说了一句话,我觉得挺有代表性的:
“参数量越大的模型,用起来不一定越顺手。但我说不清楚为什么。”
直到后来我认真读了2022年OpenAI发布的一篇论文——InstructGPT。
他们用1.3万条人工精标数据,对一个13亿参数的小模型做了微调。然后让人类评估者盲测——结果这个小模型的输出,被显著更偏好于未经处理的1750亿参数GPT-3。
这件事让我意识到,”模型能力”和”模型好不好用”,其实是两件事。中间隔着的,是一套很多人没有系统了解过的训练流程。所以我想把这篇文章写清楚。
不是为了科普而科普——而是因为我越来越觉得,如果你在做AI相关的产品或决策,却没搞清楚预训练、SFT、RLHF分别在解决什么问题,你很可能在用错误的框架做判断。比如迷信参数量。比如以为”换个更大的模型”就能解决问题。比如不知道为什么同样是AI助手,有的敢说、有的缩手缩脚。
这篇文章,我想把这三个词背后的逻辑,用你不需要机器学习背景也能读懂的方式,完整讲一遍。
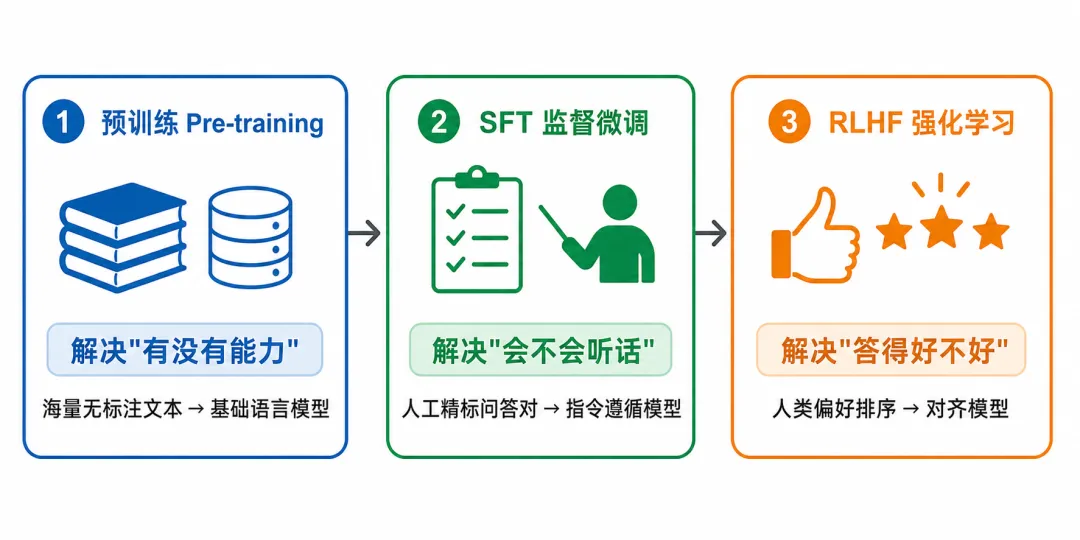
很多人接触大模型,会反复看到这三个词:预训练、SFT、RLHF。
它们不是并列的技术选项,而是一条流水线上的三道工序——缺了任何一道,模型要么没有能力,要么有能力但不听话,要么听话但答得不够好。
三者是递进依赖关系:后一阶段以前一阶段的输出为起点,顺序不能颠倒。
三个概念不是凭空出现的,每一个都是在解决前一个阶段遗留的问题。
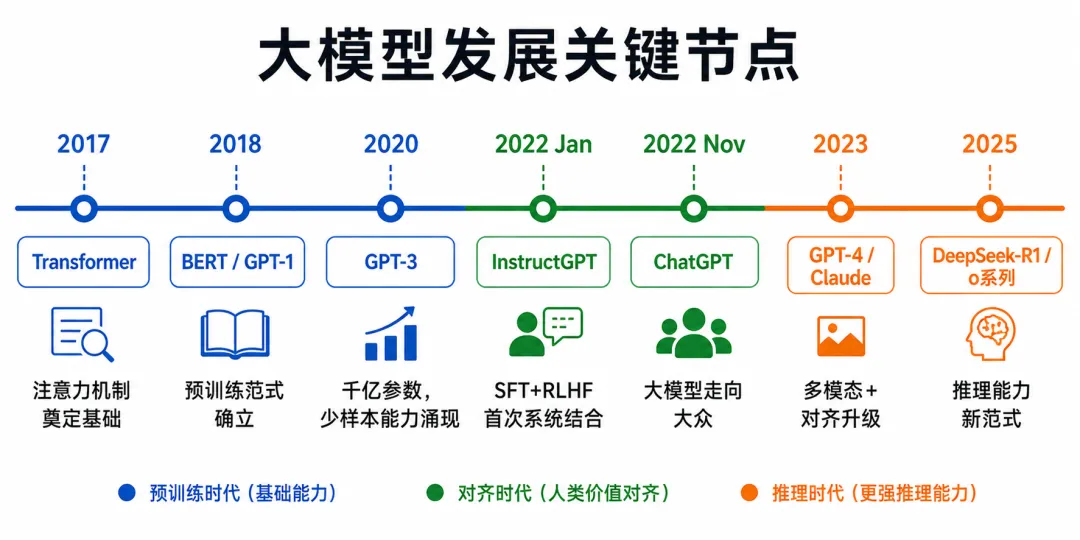
解决了”模型能不能在海量数据上高效训练”的工程问题,为预训练范式奠定基础。
2022年,InstructGPT发布(OpenAI)。
第一次系统性地将SFT和RLHF结合,解决了”模型有能力但不听话、不安全”的问题。ChatGPT正是这条路线的产物。
这两个节点之间,是BERT、GPT-1/2/3等预训练模型的积累期——模型越来越能干,但越来越难用,推动了SFT和RLHF的出现。
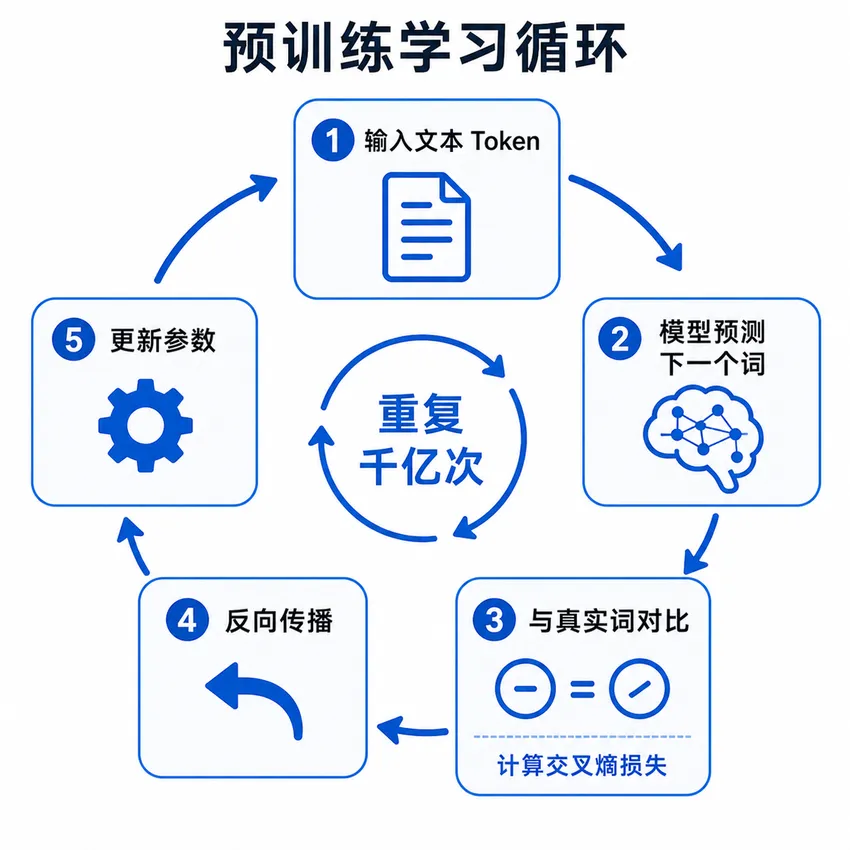
预训练 = 在海量无标注文本上,让模型通过反复预测语言结构,自主习得语言能力。
不告诉模型什么是对的,只给它看海量文字,让它反复猜”下一个词是什么”——猜了几千亿次之后,语言的规律、事实、逻辑,都被压进了参数里。
“今天天气很好“中,”好”既是预测目标,也是文本本身提供的答案——不需要任何人工标注。这就是自监督学习的核心逻辑:通过预设的变换规则从数据中自动构造训练任务,文本自身即包含监督信号。
输入文本 → 基于上下文预测下一个词 → 与真实词对比计算误差 → 反向传播更新参数 → 循环
模型不是在”记忆”文本,而是在将语言规律压缩进参数空间。支撑这个过程的核心架构是Transformer——它允许模型在处理每个词时,同时参考序列中所有其他词的信息,使得长距离语义关联的捕捉和大规模并行训练都成为可能。
参数量和数据量不只是量的堆叠,超过一定规模后,某些小模型几乎不具备的能力(多步推理、代码生成)会开始显著出现——研究者称之为”涌现能力”。
但需要注意:这一现象的成因存在争议。有研究表明,当改变评测指标的设计时,”突然出现”的能力可能呈现为平滑的连续提升,而非质变。对从业者的实践意义是:不能将”堆规模”视为获得特定能力的可靠路径,评测方法的设计同样关键。
价值: 预训练一次,可以作为多个垂直领域模型的起点,这是基础模型(Foundation Model)范式的核心经济逻辑。
-
预训练语料需覆盖目标领域——冷门语言、高密度专业知识(如放射科报告、细分法律条款)往往覆盖不足,直接SFT效果会打折
-
“只需一次”是相对表述——知识时效性要求高的场景,仍需持续预训练或增量训练
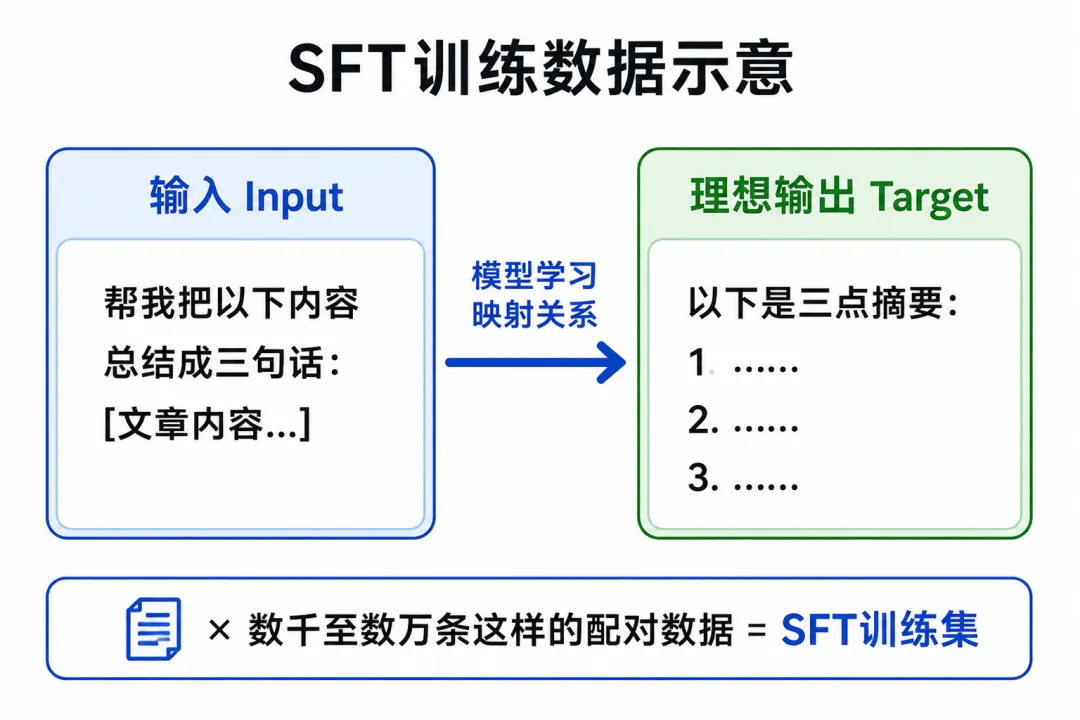
预训练结束后,你得到的是一个基础语言模型。 它能做什么?给它一段文字开头,它会继续续写。仅此而已。这就引出了SFT存在的必要性。
四、SFT(监督微调)——从”续写机器”到”指令助手”
SFT = 用人工精标的”指令→理想回答”样本对,让模型学会按预期方式响应用户指令。
解决的是”能不能完成任务、会不会好好回答”的问题。
预训练之后模型”什么都懂但不听话”。SFT是给它看大量示范——遇到这类问题,应该这样回答——让它学会把能力以正确的形式输出来。
模型在大量这样的配对样本上训练,学会了:遇到特定类型的指令,以什么结构、什么边界来输出内容。
技术上,SFT与预训练的目标函数形式一致(最小化交叉熵损失),但条件变了——从”预测任意下一词”变为”在指令约束下预测期望输出”。
OpenAI在InstructGPT论文中披露:约1.3万条精标数据对175B参数的GPT-3进行SFT,人类评估中结果显著优于未经SFT的GPT-3。
|
|
|
|
|
|
|
|
医疗、法律等专用模型(注意:通用能力可能同步下降)
|
|
|
|
一个容易被忽视的事实: 标注员的判断直接定义了”什么是好的回答”。他们的背景、标准、理解偏差,会被模型学习并放大。谁在标注、按什么标准标注,是一个在技术文档里不显眼、但在产品影响上不可忽视的变量。
SFT告诉模型”怎么回答”,但无法告诉它”哪个回答更好”。
标注数据只能覆盖有限场景,无法穷举所有指令类型。更关键的是,SFT的目标是最小化与标注答案的差距,而非最大化真实有用性——模型倾向于模仿标注风格,可能在某些场景输出”听起来对但实际错误”的内容。
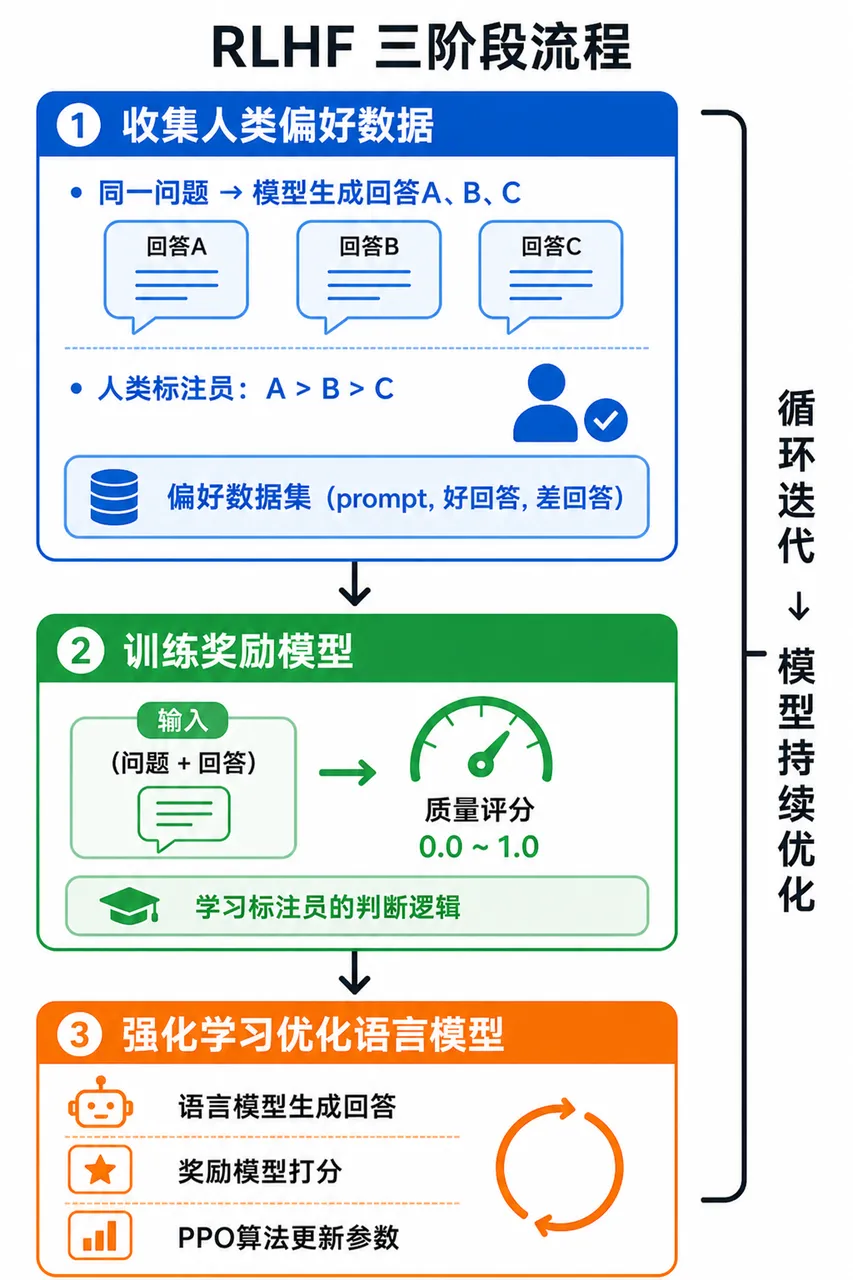
RLHF = 用人类对多个模型输出的偏好排序,训练一个”评分模型”,再用强化学习驱动语言模型持续优化输出质量。
解决的是”回答得好不好、安不安全、符不符合用户期待”的问题。
不只是给模型看”标准答案”,而是让人类比较多个回答,告诉模型:A比B好、B比C更安全——然后用这些判断训练出一个”自动评分官”,再用它持续引导模型改进。
同一问题让模型生成多个回答,人类标注员进行两两比较(”A比B更有帮助”)。
收集的是相对偏好而非绝对评分——人类在判断”哪个更好”时,比给出绝对分数更稳定、更一致。
第二阶段:训练奖励模型(Reward Model)
训练目标:让奖励模型对”人类更偏好的回答”打出更高分。
奖励模型本质上是在学习人类标注员判断逻辑的压缩表征——它学的不是”客观正确”,而是”这批标注员认为什么是好的”。这是RLHF最重要的局限性来源。
语言模型生成回答 → 奖励模型打分 → 用PPO算法根据分数更新模型参数 → 循环迭代
为什么用PPO? 如果模型单纯追求最大化奖励分数,会找到奖励模型的漏洞,生成”评分高但没有实际价值”的内容——即奖励黑客(Reward Hacking)。PPO通过约束每次参数更新的幅度,防止模型偏离原有能力边界过远。
来源:InstructGPT论文(Ouyang et al., 2022)
|
|
|
|
1.3B InstructGPT vs 175B GPT-3
|
|
|
|
|
|
|
|
这对资源有限的团队是一个重要判断:更大不一定更好用,对齐方式和数据质量同样是关键变量。
|
|
|
|
|
|
|
|
Constitutional AI(用原则约束AI自我批评)
|
|
|
奖励模型集成(Ensemble)+ 对抗性红队测试;或绕过奖励模型直接用DPO
|
|
|
|
关于DPO: 2023年提出的直接偏好优化(Direct Preference Optimization)绕过了显式奖励模型训练,直接用偏好数据优化语言模型,在部分场景下效果与RLHF相当但成本更低,是目前开源社区广泛采用的替代路线。
预训练给模型能力,SFT给模型行为规范,RLHF给模型价值判断。
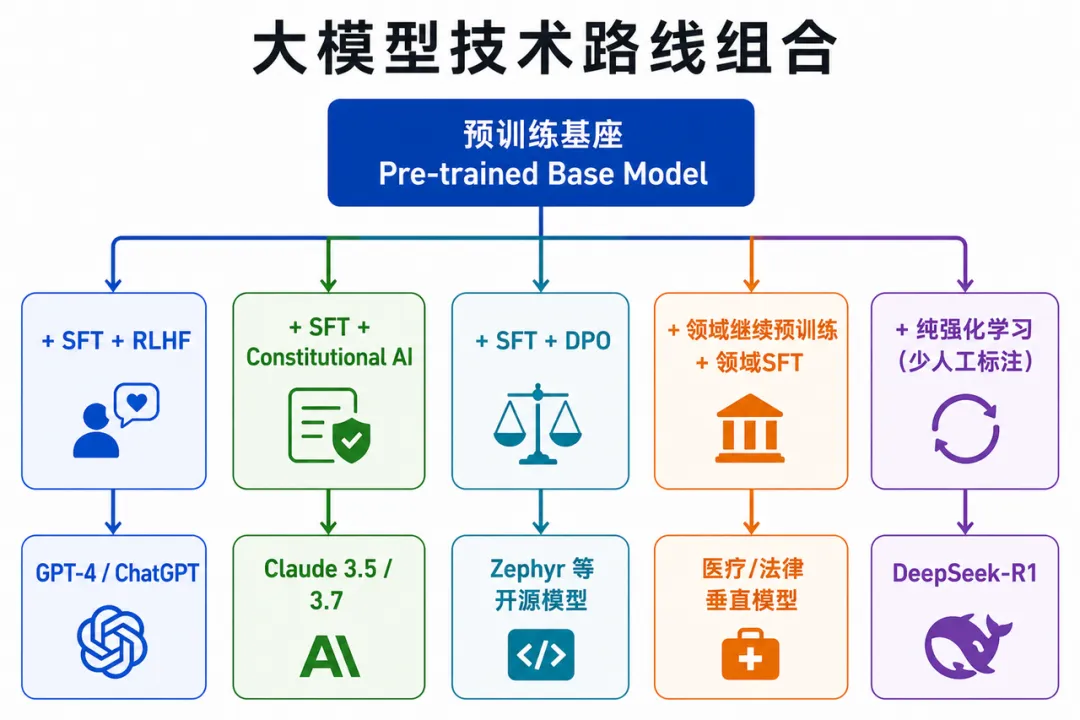
三者是递进依赖,不是并列替代。但实践中存在多种组合路线:
|
|
|
|
|
|
|
预训练 + SFT + Constitutional AI
|
|
|
|
|
|
|
|
|
|
|
案例一:ChatGPT / GPT-4o——RLHF路线的商业验证
技术路线: GPT系列预训练 → SFT → RLHF
ChatGPT是RLHF从论文走向大规模商业落地的第一个现象级案例。2022年11月上线,2个月用户破亿。
对理解三个概念的价值: 它验证了”对齐质量可以超越规模优势”,也让整个行业意识到——用户真正需要的不只是”能说话的模型”,而是”说得好、用得上、不出错”的助手。
截至2025年,GPT-4o的多模态能力(实时语音+图像+文本)和o系列的深度推理能力,代表了这条路线的最新演进方向。
案例二:Claude——Constitutional AI的差异化路线
技术路线: 预训练 + SFT + Constitutional AI
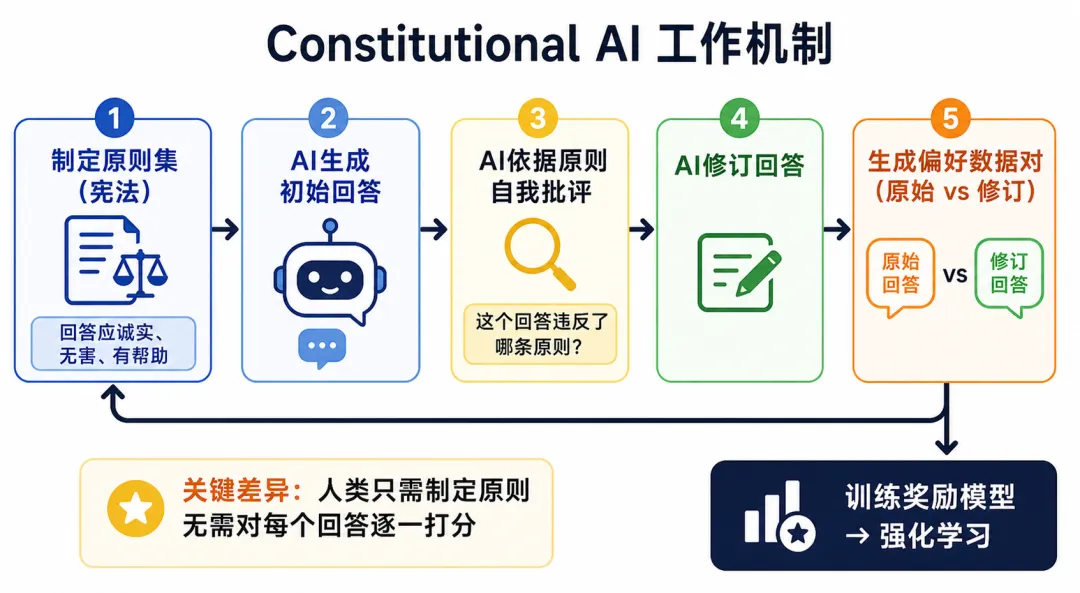
Constitutional AI不是简单的”用AI替代人类标注”,机制上有本质差异:
先给AI一套明确的原则集(”宪法”)→ 让AI依据原则批评自己的回答 → AI根据批评修订输出 → 用AI生成的(原始 vs 修订)对作为偏好数据训练奖励模型 → 再用奖励模型做强化学习
与标准RLHF的核心差异: 人类判断的介入点从”对每个回答打分”前移至”制定原则”——减少对大规模人工标注的依赖,同时使对齐标准更显式、可审计。
Claude 3.7(2025年)引入”扩展思考(Extended Thinking)”模式,在复杂推理任务上的深度进一步提升。
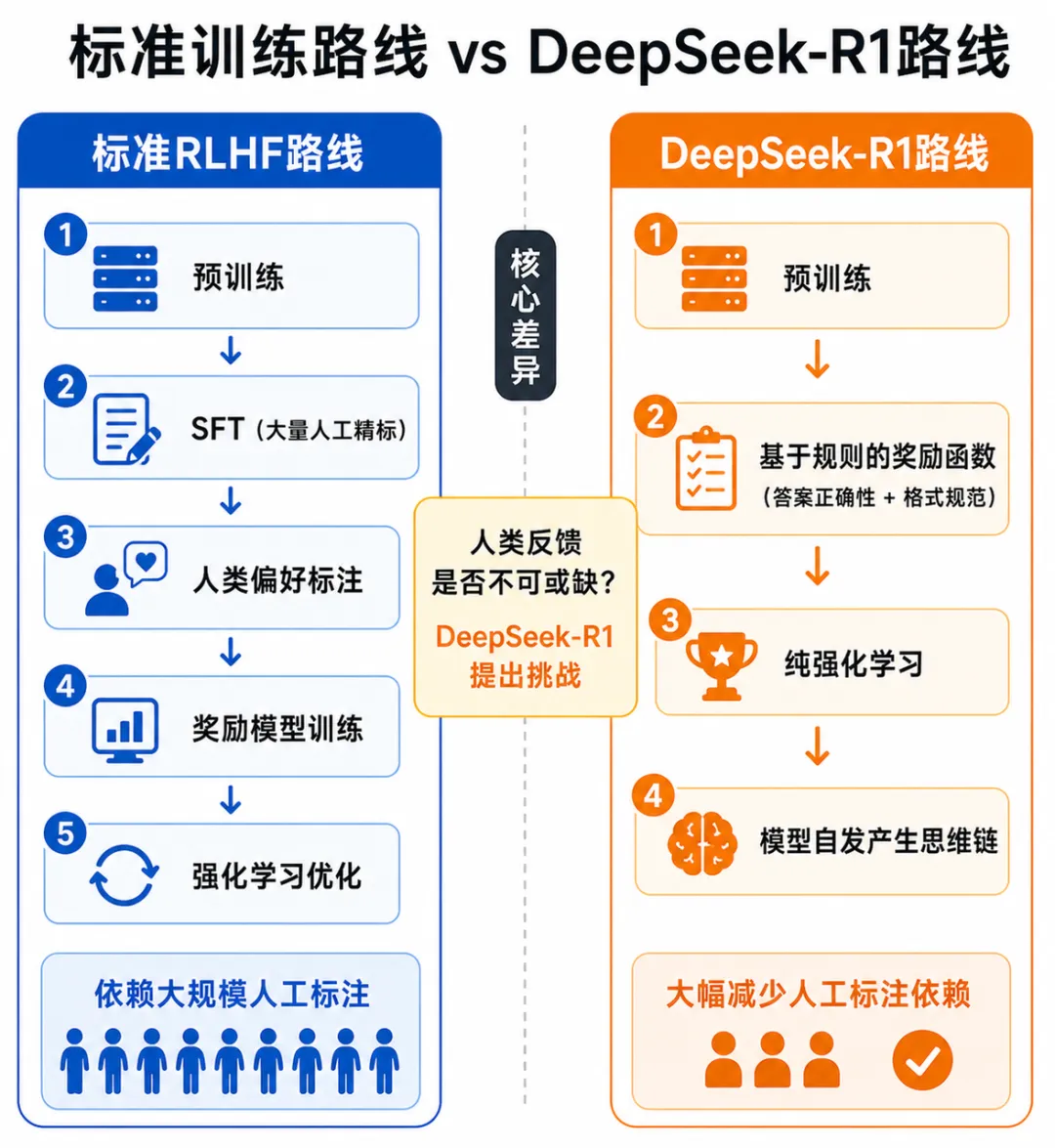
案例三:DeepSeek-R1——对标准路线的实质性挑战
DeepSeek-R1(2025年1月)在数学推理和代码任务上达到与OpenAI o1相当的水平,且以开源形式发布,引发全球关注。它的核心意义不在于性能,而在于技术路线的挑战性:
|
|
|
|
|
使用基于规则的奖励函数(答案正确性、格式规范性),大幅减少人工标注依赖
|
|
|
纯RL训练下,模型自发产生”自我反思”和”长思维链”行为
|
对从业者的判断意义: DeepSeek-R1对”人类反馈是否不可或缺”这一问题提出了实质性挑战,也让推理时计算(Test-Time Compute)的价值重新进入行业视野。
o系列和DeepSeek-R1的核心思路是:把更多计算放在推理时(让模型”多想一想”),而非全部依赖训练时对齐。这可能改变”更好的模型 = 更多预训练算力”的既有判断框架。
随着模型能力超越人类评估者在特定领域的判断能力,”人类反馈”本身的可靠性会系统性下降。这不是工程优化能解决的问题,而是对RLHF范式的根本性挑战。
方向三:Benchmark Overfitting
当前模型选型高度依赖基准测试,但基准被过度优化已是显著问题。评测方法的设计本身,正在成为一个独立的技术挑战。
RLHF中的”对齐”,本质是对齐到特定标注员群体的偏好。谁来定义”好的回答”,是技术问题之外的权力分配问题。目前这一权力高度集中在少数头部实验室,缺乏有效的外部校验机制。
对齐税是有实验支撑的现象:过度对齐的模型在某些任务上通用能力会下降。SFT和RLHF的强度、方向、数据构成都在影响这个权衡,没有普遍适用的最优点。在具体场景中,明确评估对齐策略的实际成本,是比选择哪家模型更值得花时间的判断。
|
|
|
|
|
Attention Is All You Need(2017)
|
|
|
Training language models to follow instructions with human feedback(2022)
|
|
|
Constitutional AI: Harmlessness from AI Feedback(2022)
|
|
|
DeepSeek-R1 Technical Report(2025)
|
|
|
Are Emergent Abilities of Large Language Models a Mirage?(2023)
|
|
|
|
|
|
Andrej Karpathy: State of GPT(YouTube)
|
 夜雨聆风
夜雨聆风