 夜雨聆风
夜雨聆风





�� AI Agent 学习笔记10-Agentic RAG介绍与实践

一 什么是 RAG?从”凭空生成”到”查证后输出”
RAG 是一种结合了信息检索和文本生成的混合 AI 架构。它通过在生成回答之前先检索相关的外部知识,显著提升了语言模型在特定领域的准确性和时效性。RAG 技术的核心思想是将 LLM 生成能力与外部知识库的检索能力相结合,解决了传统语言模型在知识更新、事实准确性和领域专业性方面的局限性。
知识幻觉
尽管大语言模型表现出惊人的语言能力和常识理解,但其本质仍是统计驱动的概率模型。它的训练数据截止于某个时间点,且无法实时更新;它对事实的”掌握”来自于海量文本中的共现模式,而非真正的逻辑验证。这意味着,当用户提问超出其训练数据范围,或问题本身存在模糊性时,模型倾向于”填补空白”——用最符合语法和语义逻辑的方式生成答案,哪怕这个答案并不真实。
知识幻觉不仅影响用户体验,更可能在医疗、金融、法律等高风险领域引发严重后果。因此,让大模型”知道自己不知道”并引用可靠来源作答,成为构建可信 AI 系统的刚性需求。
RAG 的本质:先检索,再生成
RAG(检索增强生成)通过整合外部知识库解决大语言模型三大痛点:
- 知识时效性:突破训练数据时空限制领域适应性。
- 快速接入垂直领域知识。
- 事实准确性:降低模型幻觉风险。
RAG 是为此而生。它的核心思想非常朴素:不要只靠脑子想,先去书里查一查,再回答。具体流程如下:
- 用户提问:系统接收输入。
- 语义检索:将问题转化为向量,在外部知识库中查找最相关的文档片段。
- 上下文注入:将检索到的内容作为上下文,拼接到 Prompt 中。
- 生成回答:大模型基于原始问题 + 检索结果,生成最终回复。
- 返回答案 + 来源标注:输出回答的同时附带参考文献或段落出处。
这一过程改变了传统大模型”闭卷考试”式的回答方式,转为开卷答题,极大提升了回答的准确性与可解释性。
二 RAG 系统架构详解:五大核心组件
一个完整的 RAG 系统由五个关键模块构成,形成”数据准备→查询理解→信息检索→内容生成→反馈优化”的闭环。
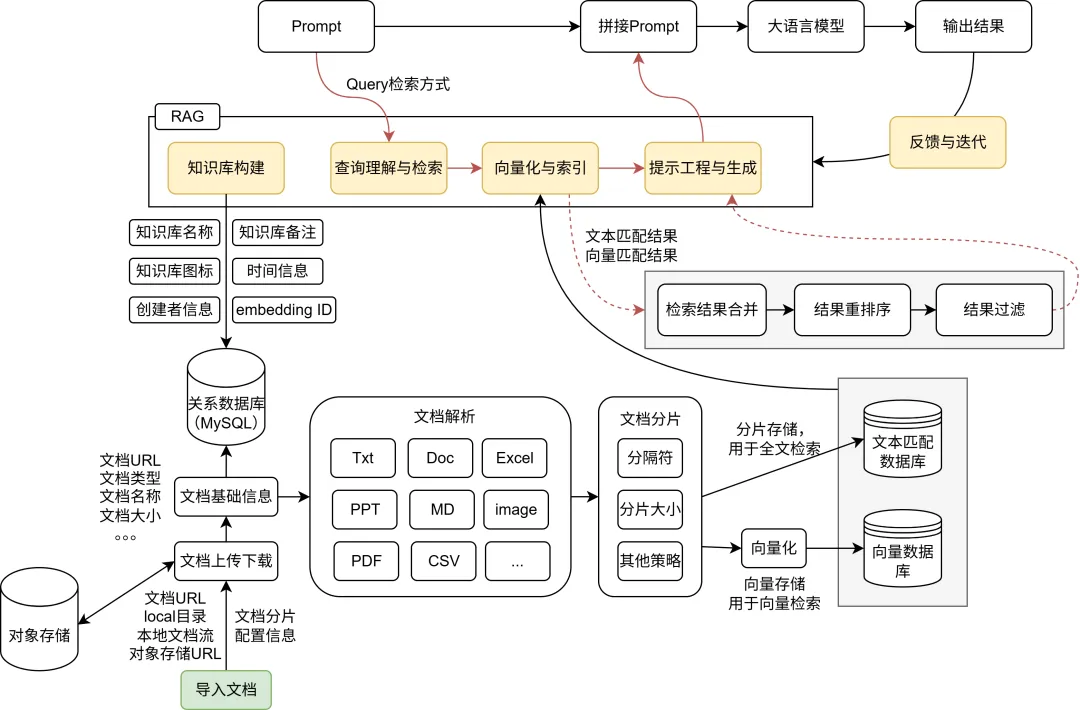
知识库构建(Knowledge Ingestion)
- AI 知识库是实现个性化、专业化服务的关键基础设施。通过知识库帮助 AI 更好地完成任务,目前 AI 知识库构建可以有以下三种方式:提示词工程、微调和嵌入(Embedding)。
- 提示词工程就是直接在提示词中构建知识库,把所有的资料放到提示词中。这种方式适合小规模地使用,但目前的 AI 模型输入的 token 数量基本无法满足这种实现方式。实际上即使随着 AI 发展,到了某一天 AI 的输入窗口足够大到容纳一般的知识库,构建知识库也仍有其价值。
- 微调是学界喜闻乐见的形式了,使用特定的任务数据在预训练模型上进行微调。这种做法其实是适合做一个行业通用的大模型,比如法律行业大模型、医学大模型等。一方面,微调需要的训练数据也不算少,成本也高;另一方面,微调不够灵活,比如根据一两份文档及时调整。微调的过程其实是把训练数据进行学习和泛化,与其说是记忆内容,不如说是增强某个领域的能力。
- 所以目前最主流的构建知识库的方式,大都采用 Embedding 的方式。而这种形式的知识库,也需要配合 RAG 才能发挥作用。
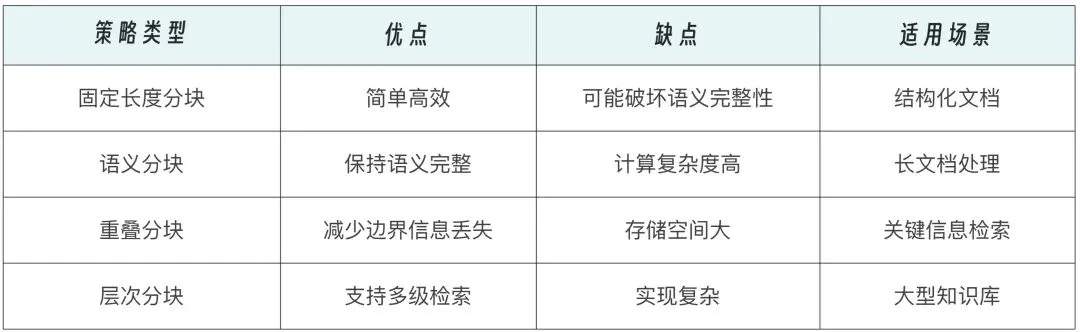
文本分块(Chunking)是 RAG 的一个关键技巧。为了提高检索效率,通常需将长文档切分为较小的语义单元。但分块过大易遗漏细节,过小则丢失上下文。推荐策略包括:
- 固定长度分块(如 512 tokens)
- 按句子 / 段落边界切割
- 使用滑动窗口增加重叠度(overlap)
- 结合语义分割工具(如 LangChain TextSplitter)
向量化与索引(Embedding & Indexing)
为了让机器”理解”文本含义,我们需要将其转换为数学空间中的向量表示。嵌入模型(Embedding Model)能将文本映射到高维向量空间,使得语义相近的文本距离更近。
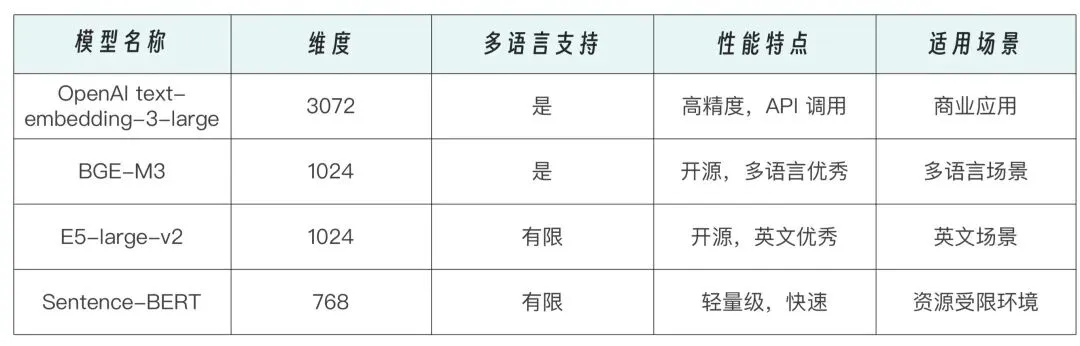
随后,这些向量被存入向量数据库(Vector Database),如 Pinecone、Weaviate、Milvus、Chroma 等,支持高效的近似最近邻搜索(ANN)。
查询理解与检索(Retrieval)
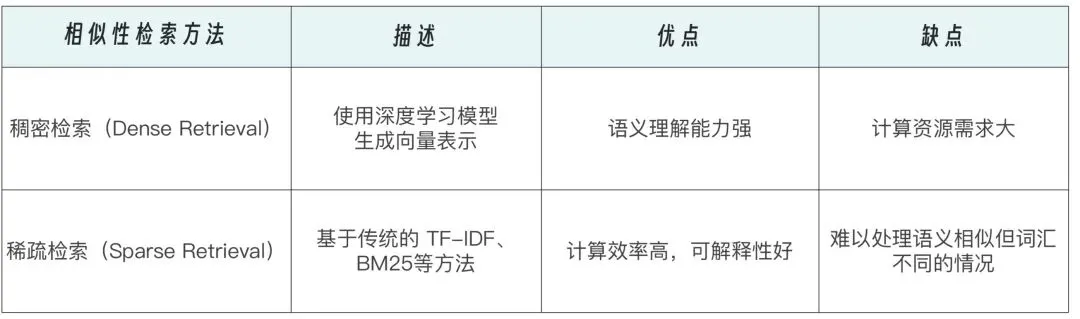
当用户提问时,系统同样将其编码为向量,并在向量库中进行相似度匹配,找出 Top-K 最相关的结果。
进阶优化手段包括:
- 查询扩展:自动补全同义词或上下位词(如”抑郁”→”情绪低落””心境障碍”)。
- 重排序(Re-Ranking):用模型对初筛结果二次打分,提升精准率。
- 混合检索:结合关键词 BM25 与向量语义检索,兼顾精确匹配与语义泛化。
提示工程与生成(Prompt Engineering & Generation)
接下来是提示工程与生成,这是 RAG 的临门一脚。检索到的相关文档必须巧妙融入 Prompt,引导模型正确使用信息。典型 Prompt 结构如下:
prompt.txt
你是一个专业的IT运维,请根据以下参考资料回答用户问题。
【参考资料】
{retrieved_text}
【问题】
{user_question}
【要求】
- 若资料中无相关信息,请明确告知"暂无相关信息"
- 不得编造事实
- 引用来源编号,如[1]这种方式强制模型”看材料答题”,可以显著降低幻觉概率。
反馈与迭代(Feedback Loop)
真正的智能系统是持续进化的。你可以收集用户反馈:回答是否准确?来源是否相关?表达是否恰当?利用这些数据反哺知识库更新、调整分块策略、优化检索模型,形成正向循环。
三、实战演练:为Agent接入Learningspace产品知识库
目标:当用户询问Learningspace产品知识时,优先检索本地知识库。
所需资源:
- 知识源:公司官网PDF 文档。
- 技术栈:Python + LangChain + OpenAI API + Chroma 向量数据库。
实施步骤
步骤 1:加载文档
demo支持 pdf md txt 三种格式:
load_doc.py
# ============== 文档加载(LangChain) ==============
def load_document(file_path: str) -> Tuple[List, str]:
ext = os.path.splitext(file_path)[1].lower()
try:
if ext == ".pdf":
loader = PyPDFLoader(file_path)
elif ext == ".md":
loader = UnstructuredMarkdownLoader(file_path)
elif ext == ".txt":
loader = TextLoader(file_path, encoding="utf-8")
else:
return None, f"[不支持的格式] {ext}"
docs = loader.load()
return docs, None
except Exception as e:
return None, f"加载失败:{str(e)}"步骤 2:处理文档生成向量并存储
build_kb.py
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
length_function=len,
separators=["\n\n", "\n", "。", ". ", " "]
)
def build_knowledge_base(folder: str = DOCUMENT_FOLDER) -> str:
if not os.path.exists(folder):
return f"文件夹不存在:{folder}"
new_count = 0
for filename in os.listdir(folder):
file_path = os.path.join(folder, filename)
if not os.path.isfile(file_path):
continue
ext = os.path.splitext(file_path)[1].lower()
if ext not in [".pdf", ".md", ".txt"]:
continue
existing = kb_collection.get(where={"file_name": filename})
if existing["ids"]:
print(f"跳过(已处理): {filename}")
continue
docs, err = load_document(file_path)
if err:
print(f" -> {err}")
continue
chunks = text_splitter.split_documents(docs)
print(f" -> 切分为 {len(chunks)} 个chunk")
ids = [f"{filename}_{i}" for i in range(len(chunks))]
embeddings = [get_embedding(chunk.page_content) for chunk in chunks]
metadatas = [{
"file_path": chunk.metadata.get("source", file_path),
"file_name": filename,
"chunk_index": i
} for i, chunk in enumerate(chunks)]
texts = [chunk.page_content for chunk in chunks]
kb_collection.add(ids=ids, embeddings=embeddings,
documents=texts, metadatas=metadatas)
new_count += len(chunks)
return f"知识库构建完成!新增 {new_count} 个chunk"步骤 3:实现检索与生成链路
agent_tool.py
# 1. 定义工具描述(TOOLS 列表)
{
"type": "function",
"function": {
"name": "search_knowledge_base",
"description": "[必须调用]检索本地知识库。当用户询问技术文档、产品手册内容时必须使用",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "将用户问题完整传入,作为检索query"}
},
"required": ["query"]
}
}
}
# 2. 调用时让 LLM 自动选择(tool_choice="auto")
response = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=TOOLS,
tool_choice="auto"
)步骤 4:测试效果
构建知识库:
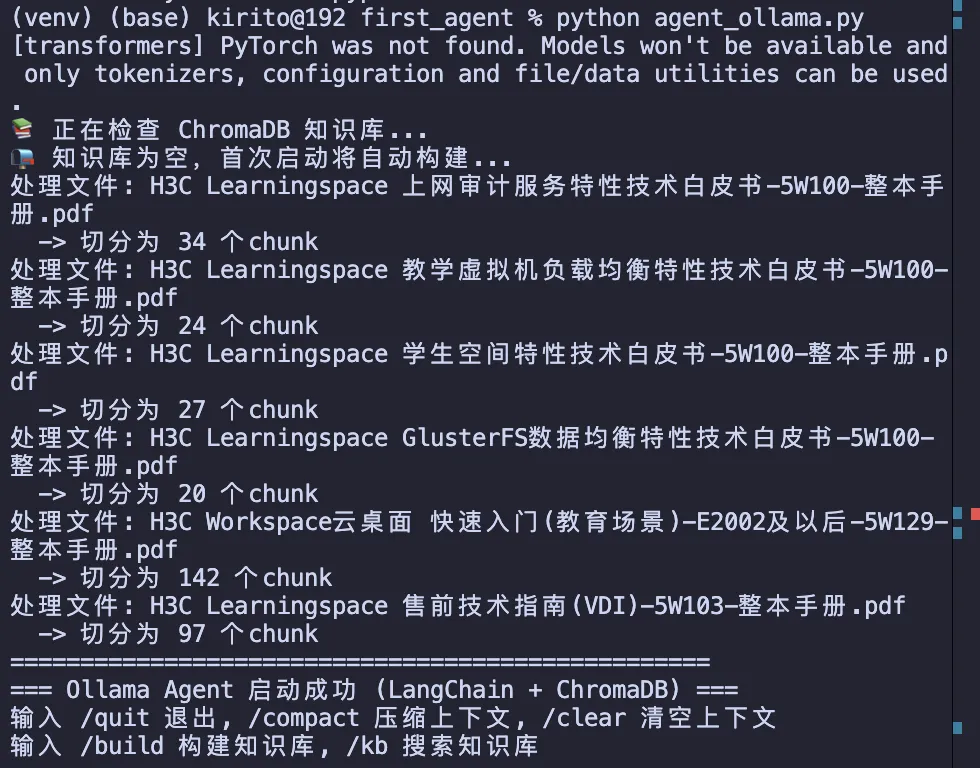
LLM自主决定检索知识库
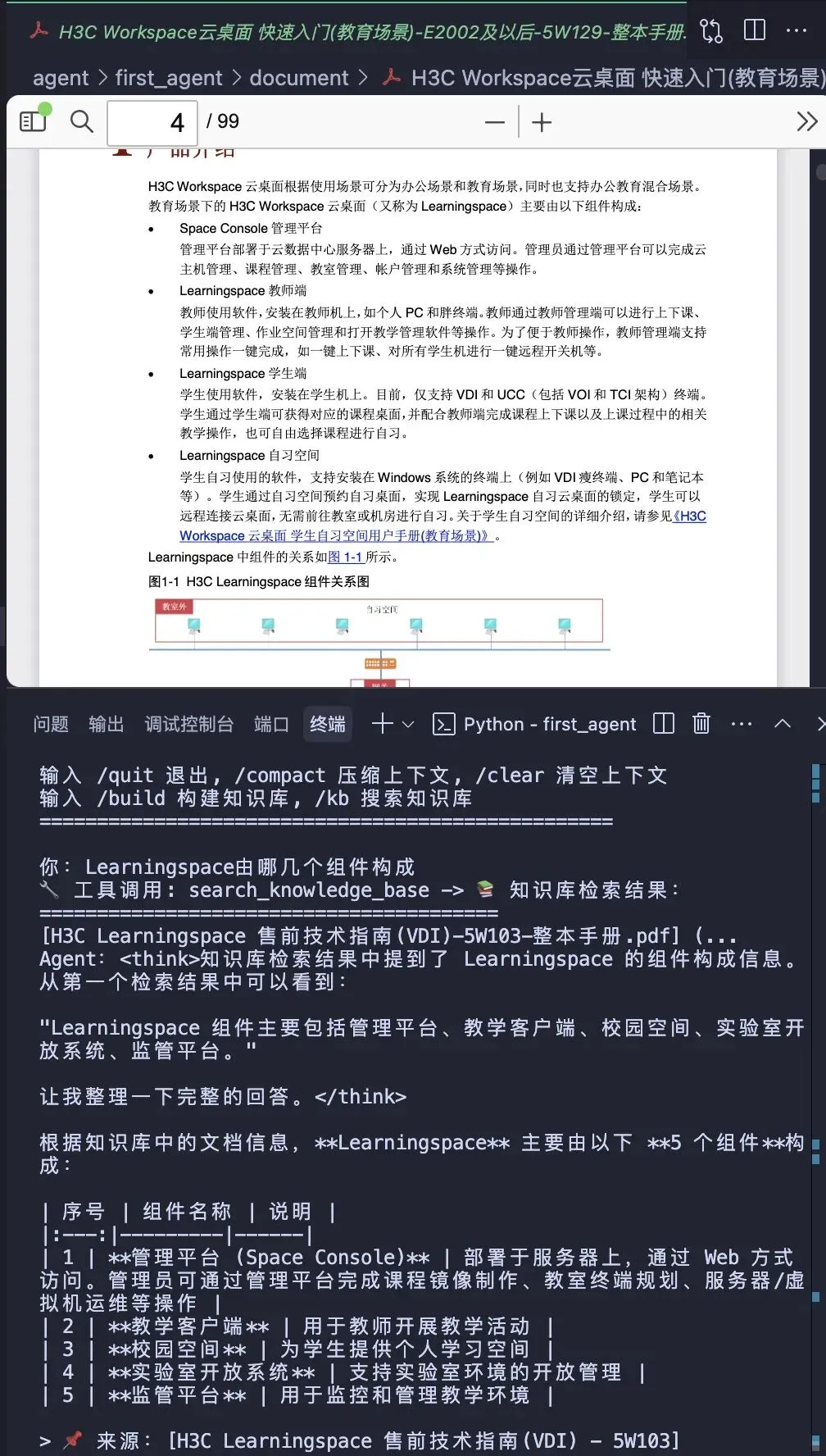
我们今天写的是一个简化版的 Agentic RAG 系统,核心链路已经通了 — LLM 做决策 + 工具执行 + 检索增强。
代码地址:https://github.com/mambo-wang/AI-Agent/tree/main/agent/first_agent