当前时间: 2026-05-03 18:29:19
更新时间: 2026-05-03
分类:软件教程
评论(0)
软件架构的演化与维护
大家好,欢迎参加本次分享。今天我们将探讨一个至关重要的话题——软件架构的演化与维护。
我们常说,软件的生命在于运动,架构也不例外。它并非一成不变的蓝图,而是一个随业务、技术和环境不断演化的动态实体。
在接下来的时间里,我们将深入探讨架构演化的动因、过程、策略与实践,希望能为大家在实际工作中提供一些有益的思路。
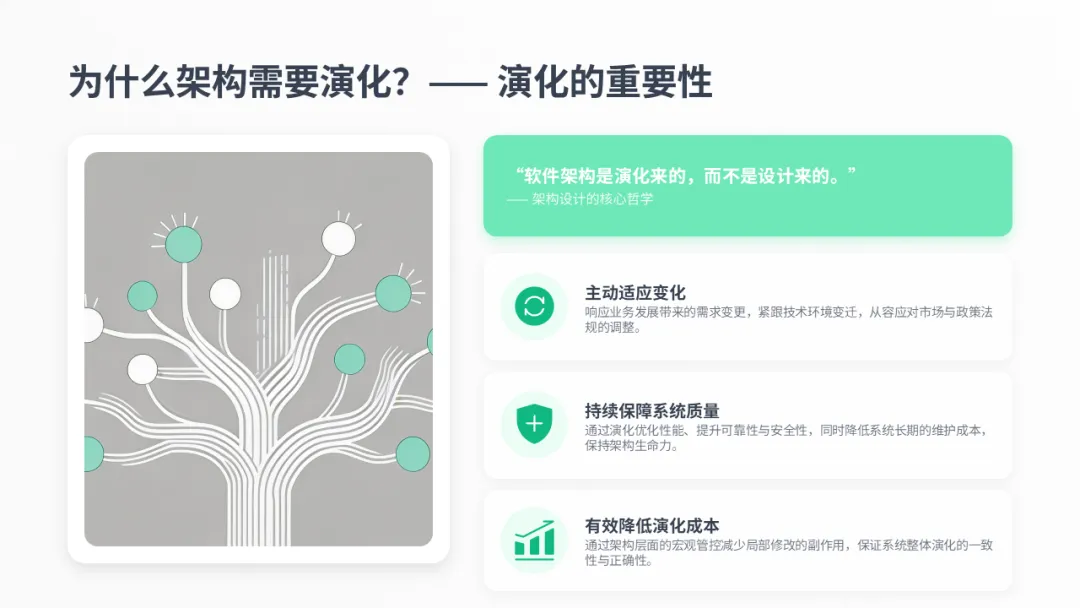
那么,为什么架构需要演化呢?一个广为流传的观点是:“软件架构是演化来的,而不是设计来的。” 这背后有三大驱动力。首先是适应变化,无论是用户需求、业务环境还是技术本身,都在不断发展。其次,演化是为了保障系统质量,包括性能、可靠性、安全性和可维护性。最后,通过架构层面的宏观管控,可以有效降低修改成本,并保证系统整体的一致性。
要理解架构演化,我们必须回到它的本质。回顾一下,软件架构由组件、连接件和约束这三大核心要素构成。因此,演化的本质就是对这三者进行增加、修改或删除。
比如,增加一个新模块就是组件演化;改变模块间的调用方式就是连接件演化;而调整系统的配置参数则属于约束演化。
需要特别注意的是,任何一个要素的变更都可能引发连锁反应,也就是我们所说的“波及效应”,影响到依赖它的其他元素。
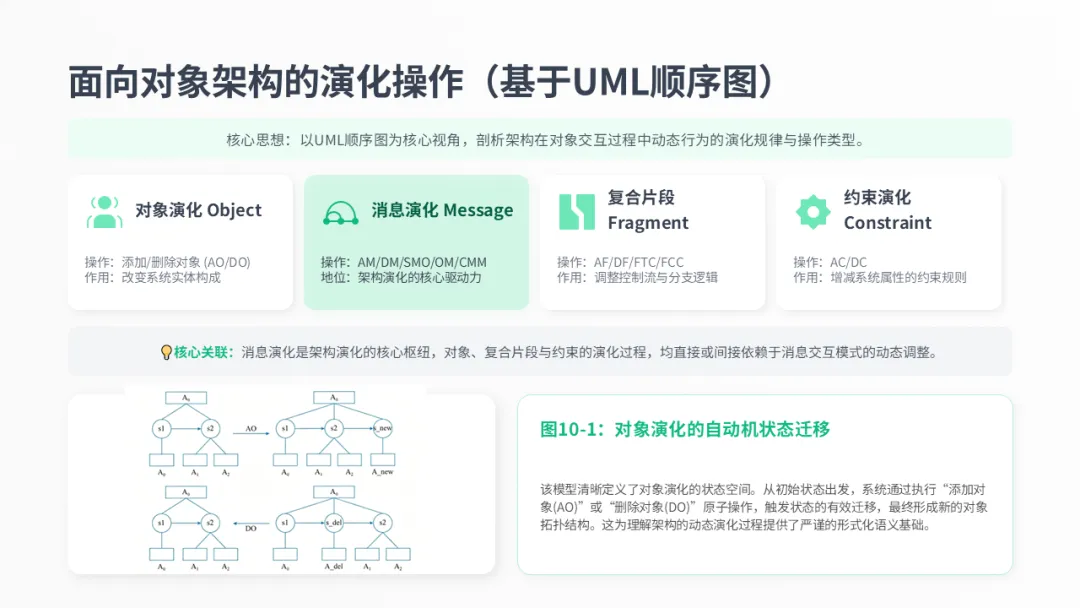
接下来,我们进入第二部分,详细探讨架构演化的具体过程与操作。在这一部分,我们将从微观层面,通过UML顺序图等工具,来剖析架构动态行为的演化类型和具体操作。
从面向对象的视角来看,架构演化可以分为四大类型。首先是对象演化,即增加或删除对象。其次是消息演化,这是最核心的类型,包括增加、删除、交换甚至反转消息等多种操作。第三是复合片段演化,涉及到控制流的变化,比如增加一个循环或分支。最后是约束演化,即对系统属性的约束进行调整。
屏幕下方的这张自动机图,就非常直观地展示了对象演化的过程。它通过状态迁移的方式,形式化地定义了“添加对象”和“删除对象”这两个核心操作是如何改变系统状态的。理解这张图,有助于我们更好地掌握架构动态演化的底层逻辑。
根据演化发生的时机,我们可以将架构演化分为两大类:静态演化和动态演化。
静态演化发生在系统停止运行时,也就是我们常说的软件升级和修复,操作相对简单,只需要关注最终的状态是否正确。
而动态演化则发生在系统运行过程中,也叫热部署。它要求在不中断服务的情况下完成修改,这对技术要求非常高,因为必须保证演化过程中系统的可用性和数据的一致性。这种演化方式主要应用于金融、航空航天等7×24小时无法停机的关键业务系统中。
现在,我们进入第三部分,详细了解静态演化。虽然静态演化听起来简单,但要做到高效、可控,同样需要遵循科学的流程和方法。
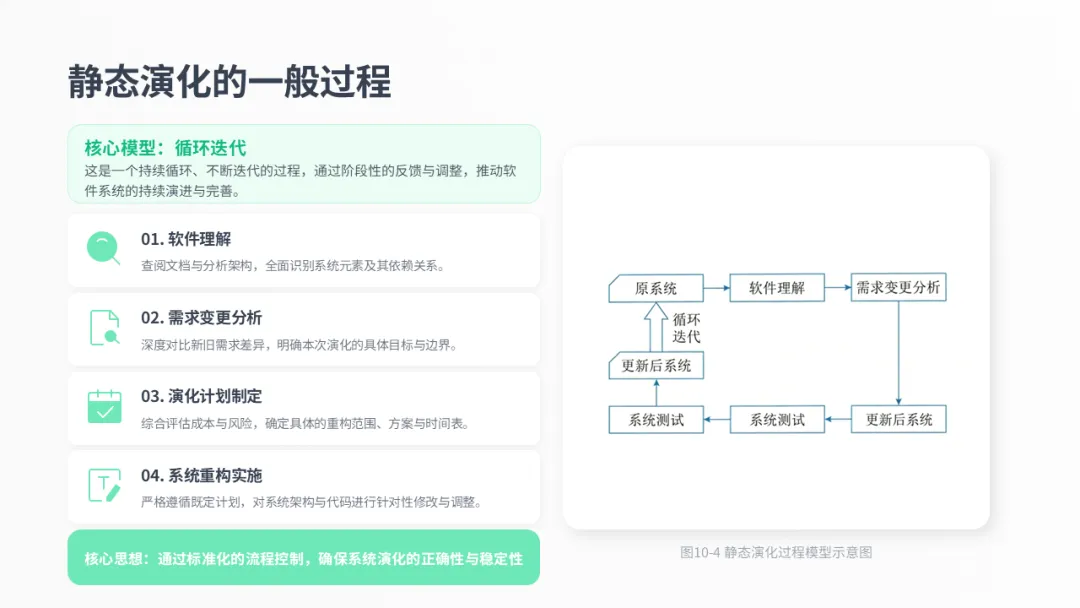
静态演化通常遵循一个循环迭代的过程,如图所示,它包含五个关键步骤:首先是软件理解,搞清楚现有系统;然后是需求变更分析,明确要做什么;接着制定演化计划;然后执行系统重构;最后进行系统测试。这个过程确保了静态演化的每一步都是可控和正确的。
在微观层面,静态演化可以分解为一系列原子操作。这些操作是粒度最小的修改,比如增加一个模块、删除一个依赖等。
我们可以将它们分为与可维护性相关的,如增减模块、调整依赖;与可靠性相关的,如增减交互消息、对象;以及其他操作如用例和参与者的变化。
理解这些原子操作及其对系统质量的影响,是进行架构评估和风险控制的基础。
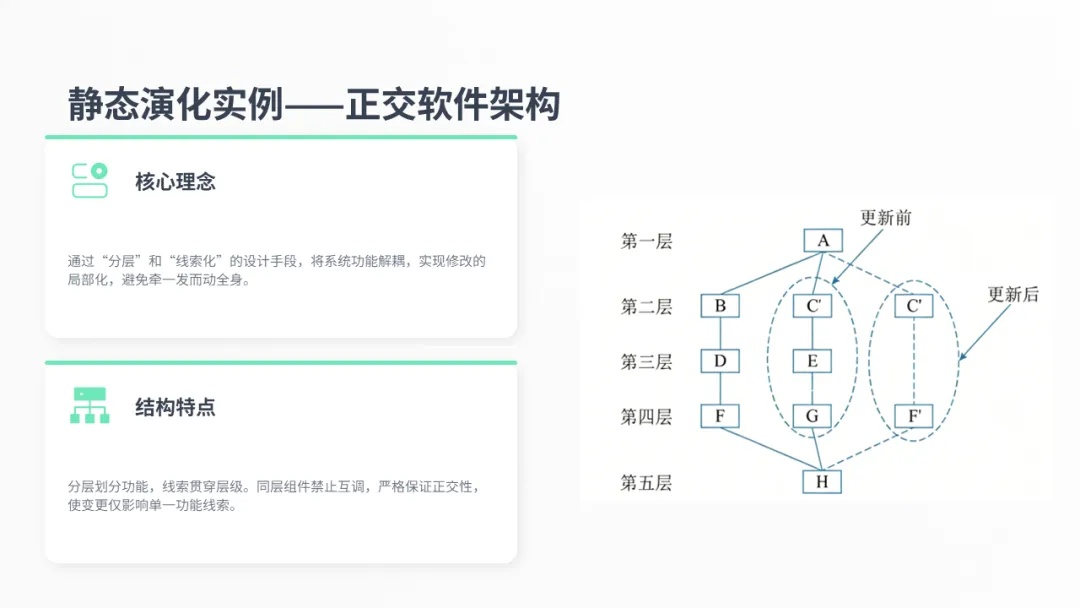
正交软件架构是静态演化的一个很好的实例。它的核心理念是通过分层和线索化,让修改变得局部化。
如图所示,系统被划分为多个层次,每个功能由一条贯穿各层的“线索”完成。由于同一层次的组件不能互相调用,当需求变更时,我们只需要修改对应的那条线索,影响范围被严格控制,从而大大降低了系统的复杂度。
接下来,我们进入第四部分,探讨更具挑战性的动态演化。动态演化是现代高可用系统的核心技术,它允许系统在运行中自我调整和升级。
动态演化的需求主要来自内部执行驱动和外部请求驱动。它在高可用系统和一些新兴技术领域有广泛应用。然而,实现动态演化面临着巨大挑战,如图中这个动态变化的球体所示,我们必须在保证系统数据一致性和服务可用性的前提下,完成复杂的在线修改,这需要非常复杂的运行时支撑环境。
软件的动态性可以分为三个等级:从简单的交互动态性,到修改组件实例的结构动态性,再到最高级的修改架构本身的架构动态性。目前主流的实现技术包括动态软件架构(DSA)和动态重配置(DR),它们通过不同的机制来实现系统在运行时的动态调整。
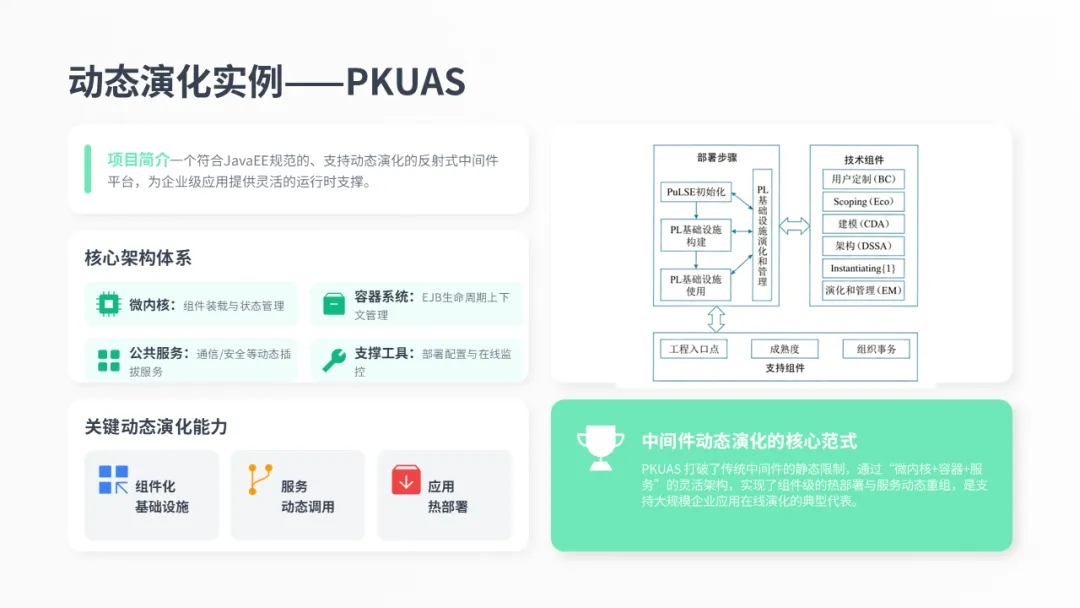
北京大学的PKUAS是动态演化的一个典型实例。它是一个支持动态演化的JavaEE中间件平台。
其核心架构包含微内核、容器系统和可动态插拔的公共服务。微内核负责组件的装载与管理,容器系统管理EJB的生命周期,而公共服务则提供了通信、安全等底层支撑。
通过这些设计,PKUAS实现了组件化的基础设施、服务的动态调用以及热部署等关键能力。这意味着我们可以在应用运行时,动态地增加、替换甚至删除服务,而不需要重启整个系统,为动态演化提供了强大的支持。
演化不是随心所欲的,它需要遵循一定的原则,并进行科学的评估。在第五部分,我们将讨论如何确保架构演化是可持续的,以及如何衡量演化的效果。
为了实现可持续的演化,我们需要遵循一些黄金原则。这些原则涵盖了成本、影响、质量和设计等多个方面。例如,演化成本必须远低于重新开发的成本;修改应该尽可能局部化,以控制影响范围;演化后的系统质量至少不能降低;并且要遵从SOLID等经典设计原则。这些原则就像图中这些稳定连接的几何体,共同支撑起架构的生命力。
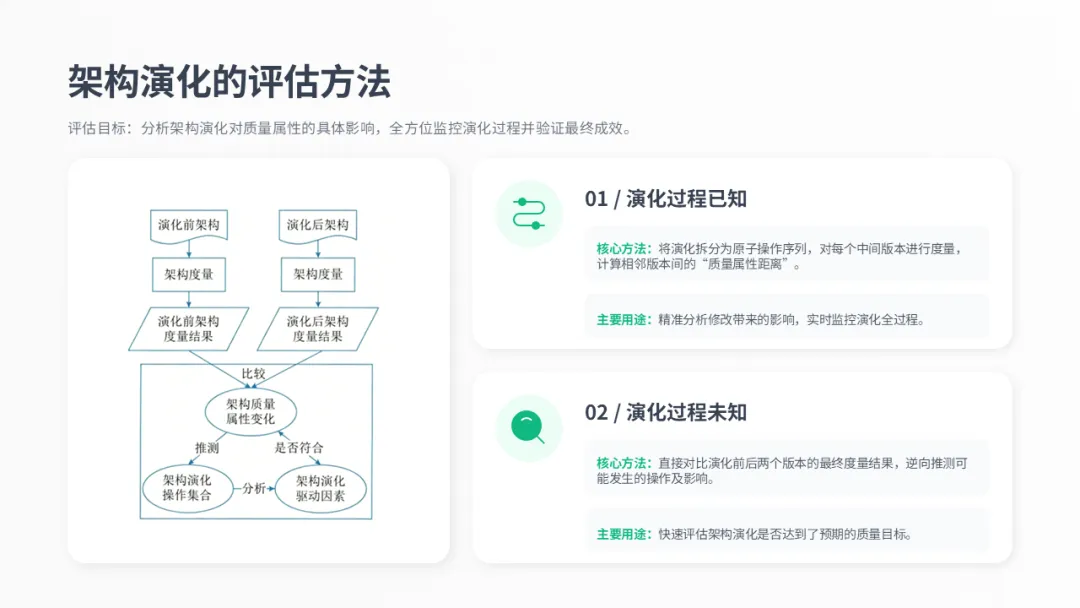
第一种是演化过程已知,我们可以将演化拆分为原子操作,逐一步骤地度量其对质量属性的影响,就像左边这张图展示的流程。这种方法的核心是计算“质量属性距离”,主要用来分析修改的影响范围,并实时监控演化过程。
第二种是演化过程未知,这种情况下,我们不需要关心中间过程,只需对比演化前后两个版本的度量结果。通过这种对比,我们可以逆向推测出可能发生的演化操作,从而评估这次演化是否真正达到了我们预期的质量目标。
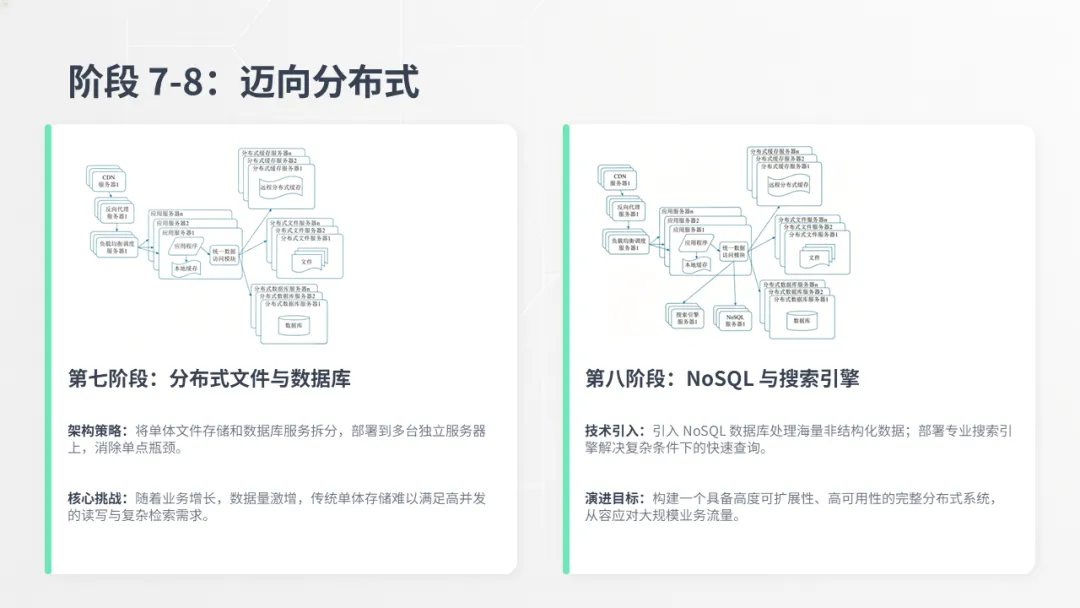
理论讲完了,让我们来看一个真实的案例:大型网站的架构演化之路。面对庞大的用户量和高并发访问,网站架构必须不断演进。这个演化过程通常由性能瓶颈、数据压力和高可用需求驱动,一般会经历从单体到分布式的八个阶段。我们先从最基础的第一阶段开始看起。
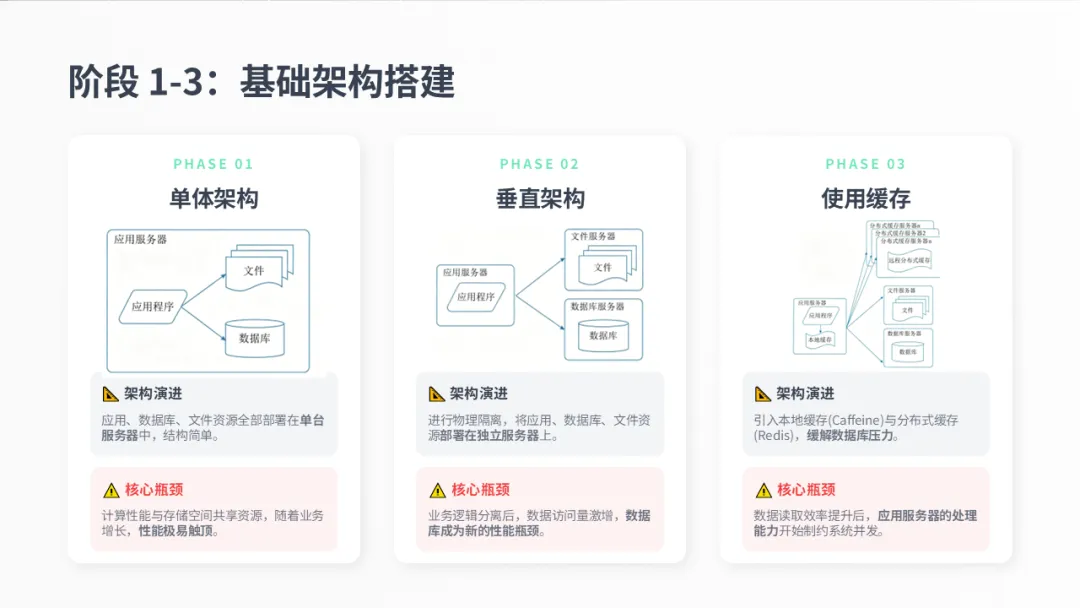
最初,网站通常采用单体架构,所有东西都在一台服务器上。很快,性能瓶颈出现,于是进入第二阶段,将应用、数据库和文件分离。但数据库又成了瓶颈,因此第三阶段引入缓存来缓解数据库压力。每一步演化都是为了解决前一阶段的主要矛盾。
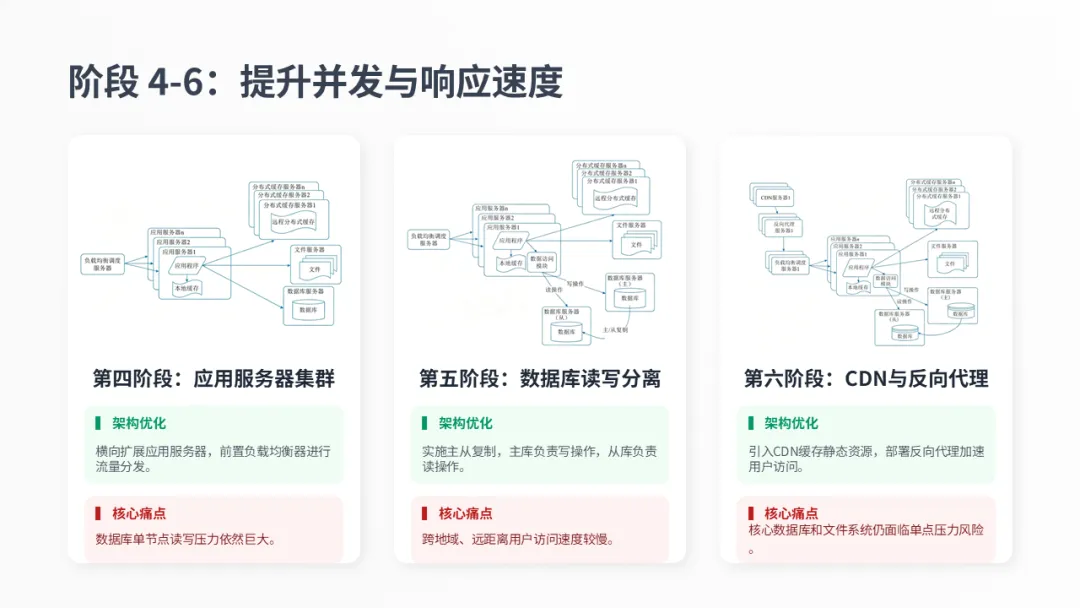
当应用服务器成为瓶颈后,第四阶段通过增加服务器和负载均衡器来解决。接着,数据库压力再次凸显,于是第五阶段进行读写分离。为了提升用户访问速度,第六阶段引入了CDN和反向代理。每一步都在解决不同层面的性能问题。
最后,为了解决数据库和文件系统的单点压力,网站架构迈向了完全的分布式。第七阶段将文件和数据库都进行拆分,而第八阶段则引入了NoSQL和搜索引擎来处理更复杂的数据需求。最终,一个高度可扩展、高可用的分布式系统得以建成。
总结一下今天的内容。我们了解到,架构演化是软件保持生命力的关键,静态和动态演化是两种核心策略。遵循原则并科学评估是成功的保障,而大型系统的演化路径也给了我们很多启示。展望未来,随着AI和云原生技术的发展,架构演化将更加自动化和智能化,“持续演化”将成为设计的核心思想。谢谢大家!
 夜雨聆风
夜雨聆风