夜雨聆风
夜雨聆风





【统计分析软件SPSS】62、交叉表(续)——统计量与显示选项
链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
由于微信公众号已发布文章的内容及排版顺序无法二次编辑,为了方便大家后续查阅、检索,同时便于我对内容进行补充更新与完善,我会将所有已发布的推文,在个人网站上以结构化文档的形式重新整理、归档。欢迎前往查看:
https://www.mizhushare.com/docs/
在前一篇文章中,介绍了SPSS中【交叉表(Crosstabulation)】功能的具体操作流程:
作为前述内容的深化与补充,本文将重点解析「交叉表·统计」与「交叉表·单元格显示」这两个关键对话框,并逐一解读其中各项统计量与显示选项的具体含义。

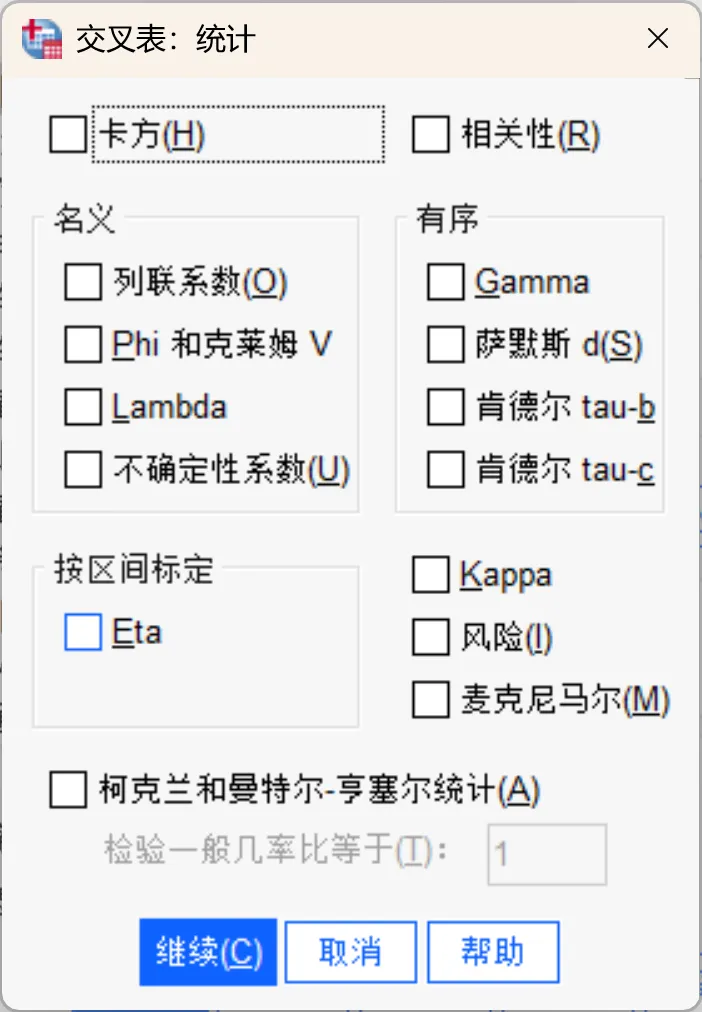
该对话框主要用于选择要输出的统计量,以判断变量间是否存在显著关联。
-
卡方:对于「2行 x 2列」的表格,勾选该选项会计算皮尔逊卡方、似然比卡方、费希尔精确检验和耶茨校正卡方(连续性修正)。对于任意行数和列数的表格,勾选该选项会计算皮尔逊卡方和似然比卡方。当两个表格变量都是定量变量时,勾选该选项会生成线性关联检验。
-
相关性:对于行和列都包含有序值的表格,勾选该选项会生成斯皮尔曼相关系数rho(等级顺序之间关联性的度量)。当两个表格变量(因子)都是定量变量时,勾选该选项会生成皮尔逊相关系数R(变量间线性关联的度量)。
-
名义:适合名义数据的统计量。
|
|
|
|
列联系数 |
基于卡方统计量计算的关联性度量。取值范围介于0到1 之间,0表示行变量和列变量之间没有关联,接近1的值表示变量之间有高度关联。需要注意的是,其理论最大值受表格维度(行数和列数)限制,因此不同维度表格的列联系数不可直接比较。 |
|
Phi和克莱姆V |
Phi是一种基于卡方的关联性度量,即卡方值除以样本量后开方。 克莱姆V也是一种基于卡方的关联性度量,但对自由度进行了调整。 |
|
Lambda |
一种基于误差减少比例(PRE)的关联性度量。它反映了利用自变量预测因变量时,预测误差减少的程度。 值为1意味着自变量能完美预测因变量,值为0意味着自变量对预测因变量没有帮助。 |
|
不确定性系数 |
同样基于误差减少比例的关联性度量,但侧重于信息熵的减少。它表示利用一个变量的信息来预测另一个变量时,不确定性(误差)降低的比例。 例如,系数为0.83意味着如果已知一个变量的值,预测另一个变量值的误差将减少83%。 程序会同时计算对称(不区分自变量/因变量)和非对称(区分自变量/因变量)两个版本。 |
-
有序:适合有序数据的统计量。
|
|
|
|
Gamma |
两个定序变量之间关联性的对称度量,取值范围在 -1 到 1 之间。绝对值越接近 1,表示变量间关系越紧密;越接近 0,则表示关系微弱或无关联。 对于双向表,显示零阶 Gamma;对于三向及以上的多维表,则显示条件 Gamma。 |
|
萨默斯 d |
两个定序变量之间关联性的非对称度量,取值范围同样为 -1 到 1。与 Gamma 类似,绝对值越接近 1 表示关系越强。 萨默斯 d 是 Gamma 的扩展,主要区别在于它考虑了自变量上未结对的配对数(即包含了对自变量同分值的处理)。程序也会计算此统计量的对称版本。 |
|
肯德尔 tau-b |
一种用于定序或等级变量的非参数相关度量,其特点是计算时考虑了“结”(ties,即数值相同的情况)。 系数的符号指示关系的方向(正相关或负相关),绝对值指示关系的强度。取值范围在 -1 到 1 之间,但只有在正方形表格(行数等于列数)中才可能达到 -1 或 +1 的极值。 |
|
肯德尔 tau-c |
一种用于定序变量的非参数关联度量,与 tau-b 不同,它在计算中忽略了“结”的影响。 同样通过符号表示方向,通过绝对值表示强度。 取值范围在 -1 到 1 之间,但也只有在正方形表格中才可能达到 -1 或 +1 的极值。 |
-
按区间标定:适用于一个变量是分类变量而另一个是定量变量的情况,且分类变量必须进行数值编码。Eta是一种用于衡量变量间关联强度的指标,取值范围在0到1之间。值为0表示行变量和列变量之间不存在关联,值接近1表示变量之间存在高度关联。适用于分析一个在区间量表上测量的因变量(如收入)与一个类别有限的自变量(如性别)之间的关系。程序会计算两个Eta值,分别对应将行变量视为区间变量,以及将列变量视为区间变量的情况。
-
Kappa:科恩Kappa系数用于衡量两位评估者对同一对象进行评级时的一致性程度。其值为1代表完全一致,为0则意味着一致性水平与随机猜测无异。该统计量基于一个方阵,要求行与列代表相同的评级量表。若某单元格仅在一个变量上有观测值,其计数将被记为0。计算Kappa要求两个变量的数据存储类型(字符串或数值)必须相同;若为字符串变量,则二者的定义长度也必须一致。
-
风险:该指标专用于2×2表格,旨在衡量某个因子的存在与特定事件发生之间的关联强度。如果该统计量的置信区间包含1,则不能断定因子与事件之间存在关联。在因子发生率较低的情况下,优势比(Odds Ratio)可作为相对风险(Relative Risk)的有效估计。
-
麦克尼马尔:一种用于分析两个相关二分变量的非参数检验方法。它利用卡方分布来检验响应是否发生变化,尤其适用于“前后测”设计,以检测实验干预是否引起了显著的响应改变。对于维度大于2×2的方阵,系统会报告麦克尼马尔-鲍克对称性检验的结果。
-
柯克兰和曼特尔-亨塞尔统计:该统计量用于在控制一个或多个分层(控制)变量的条件下,检验二分因子变量与二分响应变量之间的独立性。与其他逐层计算的统计量不同,柯克兰和曼特尔-亨塞尔统计量是对所有层进行一次综合计算。

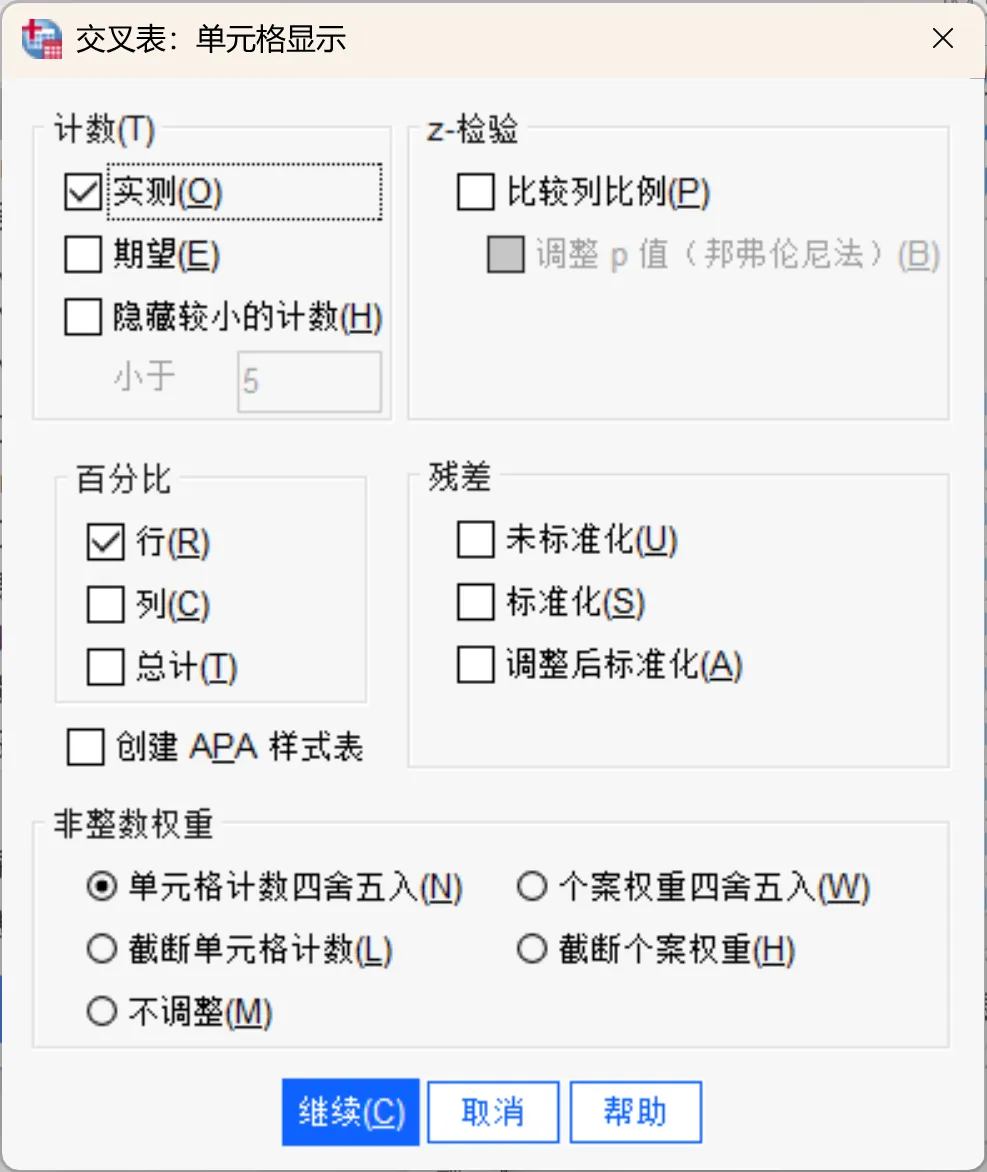
该对话框主要用于指定交叉表单元格内的显示内容,帮助我们发现导致卡方检验显著的数据模式。交叉表过程会显示期望频数以及三种类型的残差(偏差),这些残差用于衡量观测频数与期望频数之间的差异。表格的每个单元格都可以包含所选的计数、百分比和残差的任意组合。
-
计数:实际观测到的个案数,以及假设行变量和列变量相互独立时的期望个案数。
|
|
|
|
实测 |
实际观测到的个案数。 |
|
期望 |
假设行变量和列变量相互独立时的期望个案数。 |
|
隐藏较小的计数 |
选择隐藏小于指定整数的计数。隐藏的值将显示为 <N(N为指定整数)。指定的整数必须≥2,但也允许值为0,表示不隐藏任何计数。 |
-
比较列比例:该选项计算列比例的成对比较,并指出哪些列对(针对给定行)存在显著差异。显著差异会在交叉表中使用 APA 格式的下标字母进行标记,并在 0.05 的显著性水平下进行计算。需要注意的是,如果指定了该选项但未选择观测「计数」或「列百分比」,则交叉表中会包含观测计数,并带有 APA 格式的下标字母以指示列比例检验的结果。如果勾选「调整p值(Bonferroni 方法)」选项,列比例的成对比较将使用Bonferroni 校正,该校正会根据进行多次比较这一事实来调整观测到的显著性水平。
-
百分比:百分比可以按行汇总,也可以按列汇总,也可以显示表格中表示的个案总数(一层)的百分比。需要注意的是,如果在「计数」组中选择了「隐藏小计数」,则与隐藏计数相关的百分比也会被隐藏。
-
残差:用于衡量观测值与期望值之间的差异。
|
|
|
|
未标准化 |
观测值与期望值之间的原始差值。期望值是指如果两个变量之间没有关系,预期单元格中会出现的个案数。 正残差表明单元格中的个案数多于行变量和列变量独立时的情况。 |
|
标准化 |
残差除以其标准差的估计值。 标准化残差(也称为皮尔逊残差)的平均值为0,标准差为 1。 |
|
调整后标准化 |
单元格的残差(观测值减去期望值)除以其标准误的估计值。得到的标准化残差以平均值之上或之下的标准差单位表示。 |
-
创建 APA 样式表:创建符合 APA 格式指南的输出表。需要注意的是,选择括号创建 APA 格式表」后,「实测、期望、行、列、总计」这些选项将不可用。
-
非整数权重:单元格计数通常是整数值,因为它们代表每个单元格中的个案数。但是,如果数据文件当前由具有分数值(例如 1.25)的权重变量进行加权,单元格计数也可以是分数值。此时可以选择在计算单元格计数之前或之后截断或舍入,或者在表格显示和统计计算中都使用分数单元格计数。
|
|
|
|
|
按原样使用个案权重,但在计算任何统计量之前对单元格中的累积权重进行舍入。 |
|
|
按原样使用个案权重,但在计算任何统计量之前截断单元格中的累积权重。 |
|
|
在使用前对个案权重进行舍入。 |
|
|
在使用前截断个案权重。 |
|
|
按原样使用个案权重,并使用分数单元格计数。但是,当请求精确统计量(仅随抽样和测试提供)时,单元格中的累积权重会在计算精确检验统计量之前被截断或舍入。 |