 夜雨聆风
夜雨聆风





AI 开始批量生产论文了
最近自动科研这条线,确实有点卷得离谱。
过去我们说 AI 辅助科研,通常指的是帮你查文献、润色论文、写代码、画图、整理实验结果。它更像一个科研助手,研究者仍然是主驾驶。可是从 The AI Scientist、AI Scientist-v2、ResearchAgent、Google AI co-scientist、EvoScientist,到最近的 PaperOrchestra,事情开始变味了:AI 不再只是帮你写几段文字,而是在试图接管科研流程里的一个个环节。
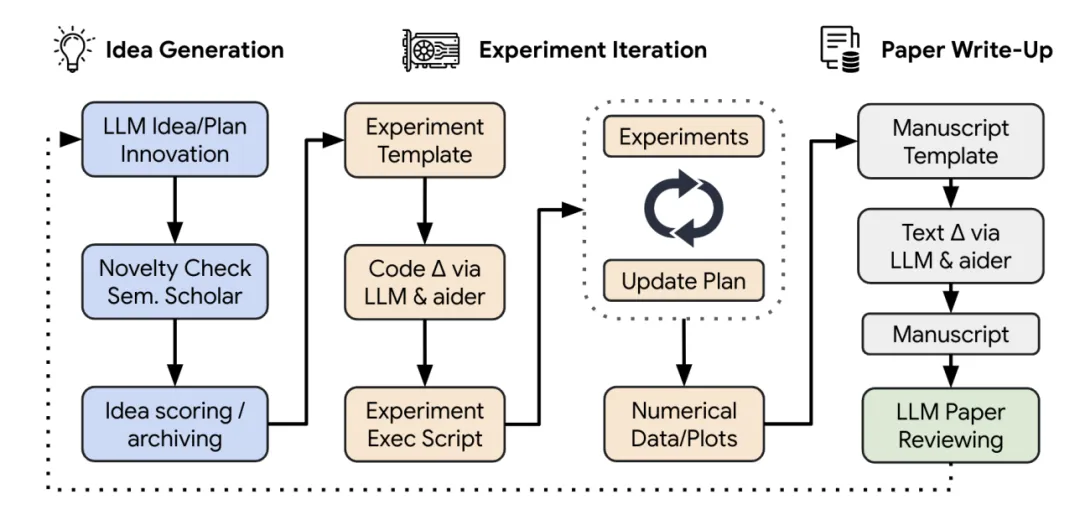
The AI Scientist
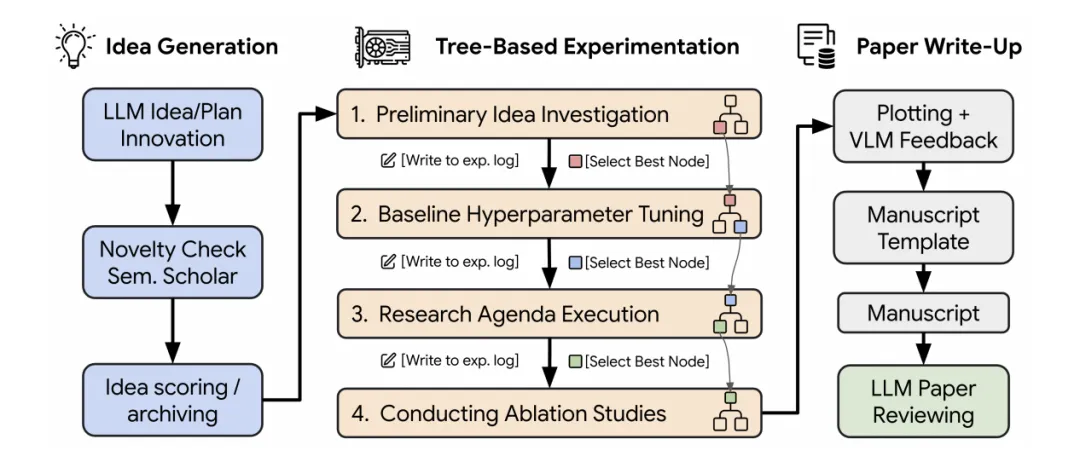
AI Scientist-v2

ResearchAgent
Google AI co-scientist

PaperOrchestra
有些技术变化刚出现时,看起来只是工具升级;但它真正改变的,是一个行业的生产关系。
AI 写论文就是这样的变化。
最开始,我们以为它只是帮研究者润色英文、改改摘要、补几段 related work。后来,它开始帮你读文献、写代码、跑实验、做图表。再往后,The AI Scientist 这类系统已经可以从 idea 生成、代码实现、实验执行、结果可视化,到论文撰写和模拟评审跑完整流程。Sakana AI 在 The AI Scientist 中把它描述为一个面向开放式科学发现的全自动框架,能够生成研究想法、写代码、运行实验、可视化结果、写成论文,并进行模拟评审。
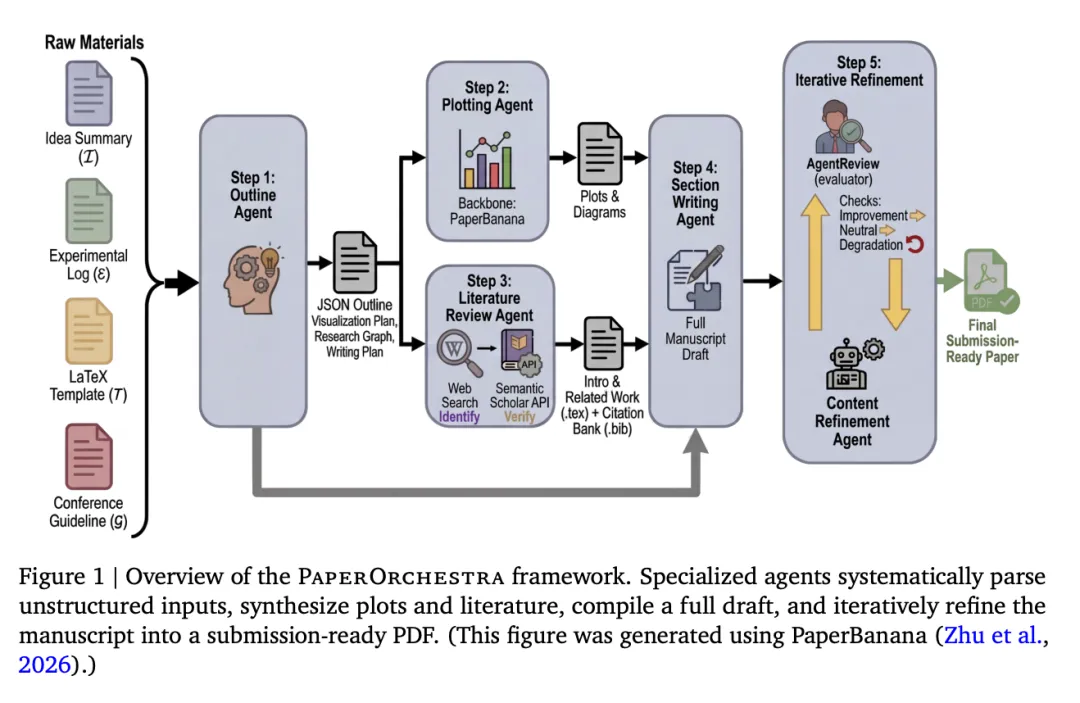
到了 PaperOrchestra,事情又往前拧了一下。
它没有直接宣称“我要替代科学家”,而是选了一个更现实、也更扎心的切口:论文成稿。
很多研究者都知道,科研最累人的地方不一定是最初的灵感,而是把一个已经做完的实验,整理成一篇能投出去的论文。实验日志是散的,消融结果是乱的,图表还没画,related work 需要补,LaTeX 模板要对齐,引用要核,方法要讲清楚,故事线要重新编排。真正写过论文的人都知道,一项研究从“有结果”到“能投稿”,中间隔着一条很长、很烦、很消耗意志力的河。
PaperOrchestra 盯上的,正是这条河。
PaperOrchestra 是 Google Cloud AI Research 提出的多智能体自动论文写作框架。它把 idea summary、raw experimental logs、venue-specific LaTeX templates 这类松散的 pre-writing materials,转化为 submission-ready LaTeX manuscripts,并自动生成文献综述、统计图和概念示意图。它还构建了 PaperWritingBench,从 200 篇顶级 AI 会议论文中反向构造原始写作材料,用来标准化评估 AI 写论文的能力。
这意味着,AI 不再只是帮你写一句话,而是在接管论文生产链条中的“最后一公里”。
而这最后一公里,恰恰是过去科研系统里最依赖人类手工劳动的部分。
从科研助手到科研流水线

过去我们谈 AI for Science,更多指的是 AI 帮助科学家做局部工作。比如 AlphaFold 帮助预测蛋白结构,AI co-scientist 帮助科学家生成新假设和研究 proposal,文献工具帮助读论文,代码助手帮助写实验脚本。Google Research 在介绍 AI co-scientist 时,也明确把它定位为基于 Gemini 2.0 的虚拟科学合作者,用于帮助科学家生成新假设和研究 proposal,加速科学与生物医学发现。
但现在的自动科研系统,已经开始不是“工具”那么简单。
The AI Scientist 做的是从 idea 到论文的端到端自动化;AI Scientist-v2 进一步引入 agentic tree search 和 experiment manager agent,去掉对人工代码模板的依赖,并声称已有 AI 生成论文通过了 ICLR workshop 的同行评审门槛。
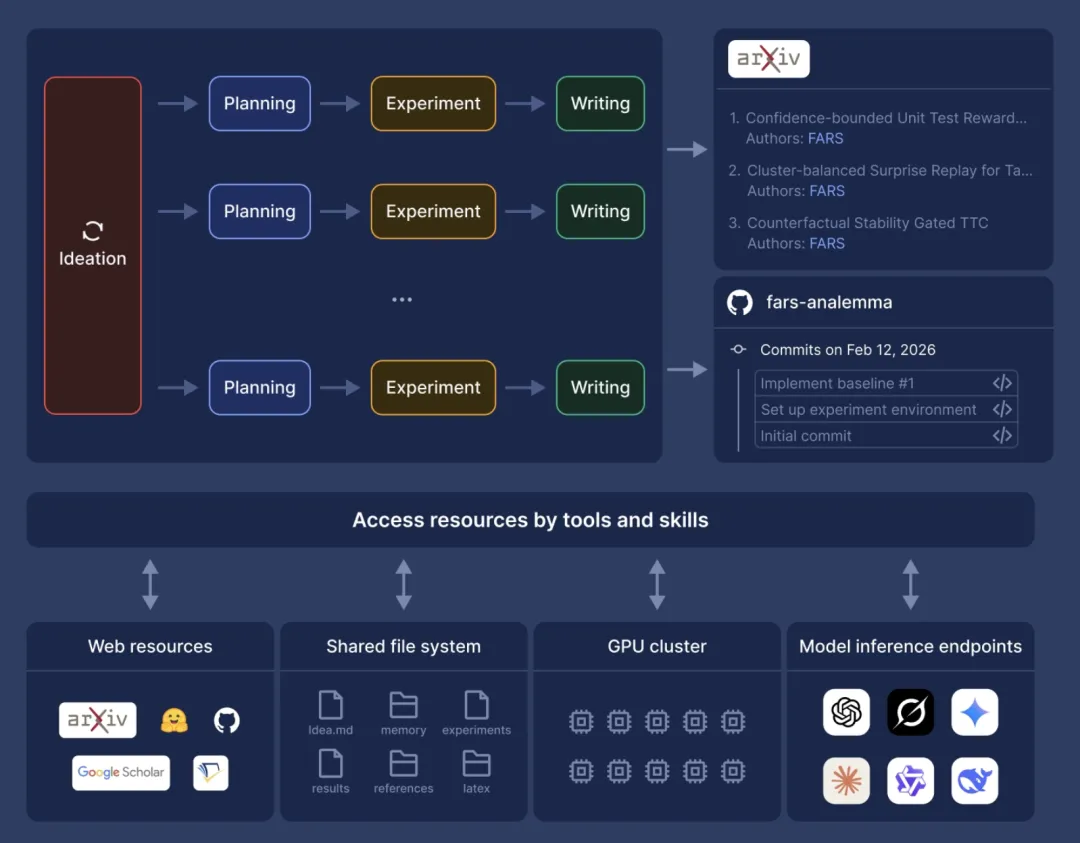
FARS 更直接,把自己定义为 Fully Automated Research System。它由 Ideation、Planning、Experiment 和 Writing 四类 agent 组成,目标是自动生成假设、规划实验、运行实验并产出论文。官方介绍甚至提到,它希望公开连续运行,产出 100 篇完整研究论文,以暴露自动科研系统在规模化生产时的真实质量分布。(Analemma AI)
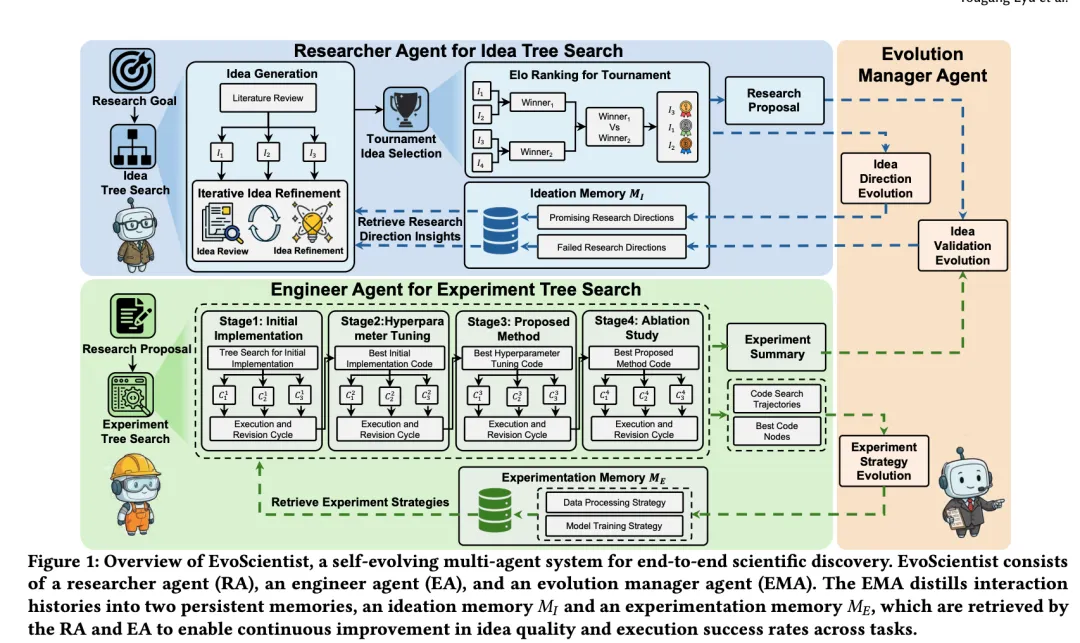
EvoScientist
EvoScientist 则把重点放在“进化”上。它认为现有 AI scientist 系统大多是静态手工 pipeline,容易重复失败实验、忽略有潜力方向、追逐不可行 idea。因此它引入 persistent memory 和 self-evolution,让 Researcher Agent、Engineer Agent 和 Evolution Manager Agent 在过去交互中积累可复用知识,提高 idea 质量和代码执行成功率。
这几条线合在一起看,自动科研正在变成一条流水线。
一个 agent 负责读文献,一个 agent 负责想 idea,一个 agent 负责写代码,一个 agent 负责跑实验,一个 agent 负责画图,一个 agent 负责写论文,一个 agent 负责模拟审稿。过去集中在一个研究者脑子里的科研过程,正在被拆成可调用、可替换、可扩展的模块。
PaperOrchestra 的特殊之处在于,它没有试图包办整个科学发现,而是专攻论文写作这一段。这个切口反而更现实。因为真正的科研发现仍然很难自动化,但把已有材料组织成一篇格式完整、引用扎实、图表齐全、逻辑自洽的论文,已经非常接近 AI 当前能力边界。
这也是它可怕的地方。
它不是在演示一个遥远未来,而是在自动化今天研究者每天都在做的苦活。
PaperOrchestra 狠在细节
自动写论文系统最容易做成“像论文的废话生成器”。标题像论文,摘要像论文,related work 像论文,但引用是编的,图是糊的,方法讲不清,实验对不上,结论空泛,稍微一查就露馅。
PaperOrchestra 的设计比较聪明,它没有让一个大模型从头写到尾,而是把论文写作拆成多智能体协作。项目页介绍,它包含 Outline Agent、Plotting Agent、Literature Review Agent、Section Writing Agent 和 Content Refinement Agent 等模块,分别负责结构规划、图表生成、文献综述、正文写作和基于模拟评审反馈的迭代 refinement。
这里最值得注意的是三点。
首先是引用。
很多 AI 写论文工具最大的问题,是 related work 看起来热闹,实际上引用不可靠。PaperOrchestra 专门强调 literature review,它通过 targeted web search 发现候选论文,再利用 Semantic Scholar API 进行引用真实性和相关性校验。项目页明确把 API-grounded citations 作为其文献综述能力的一部分。
这不是小细节。科研论文里的引用不是装饰,而是研究合法性的地基。引用错了,说明系统连自己站在哪条知识链上都没搞清楚。PaperOrchestra 把 citation verification 单独做成系统能力,说明它真正理解论文写作的风险点。
其次是图。
科研写作不只是写文字。很多论文真正打动审稿人的,是方法图、实验图、消融表、流程图和概念示意图。PaperOrchestra 会自动生成统计图和概念图,这一部分还和 PaperBanana 这类自动学术插图系统形成呼应。PaperBanana 论文的目标正是自动生成 publication-ready academic illustrations,因为学术插图长期是科研工作流中的高耗时瓶颈。
第三是自我评审。
PaperOrchestra 不是一次性写完就结束,而是引入 simulated peer-review feedback 做 refinement。论文摘要显示,在人类 side-by-side evaluation 中,它相对自动化 baseline,在 literature review quality 上获得 50%–68% 的绝对胜率优势,在 overall manuscript quality 上获得 14%–38% 的绝对胜率优势。
这些数字不能被理解成“AI 已经超过人类论文写作”。更准确地说,它说明在自动论文写作系统之间,模块化、多智能体、带引用验证和图表生成的系统,确实比粗暴让模型直接写论文强很多。
也就是说,论文写作正在从 prompt 技巧,变成系统工程。
论文生产会变便宜,但科学不会
这里必须冷静一点。
PaperOrchestra 很强,但它主要解决的是“把研究材料写成论文”,不是“保证研究本身成立”。它输入的是 idea summary、experimental logs 和 LaTeX template。换句话说,研究的前置内容仍然需要存在。它可以帮你组织、表达、引用、画图和修稿,但它不能自动保证实验设计公平、结论可靠、idea 真有贡献。
这就是“自动写论文”和“自动科学发现”的区别。
论文可以是科学的载体,但论文不是科学本身。科学真正困难的地方,在于提出有价值的问题,设计能区分假设的实验,排除混杂变量,理解负结果,判断一个提升是否有意义,知道哪些 claim 不能写过头。AI 可以把结果包装成论文,但包装不等于贡献。
OpenAI 的 PaperBench 就给了一个很好的现实校准。PaperBench 评估 AI agents 从零复现 20 篇 ICML 2024 Spotlight 和 Oral 论文的能力,任务包括理解论文贡献、开发代码库、执行实验,并通过层级 rubric 评分。论文摘要显示,即使表现最好的 agent,在平均 replication score 上也只有 21.0%,尚未超过顶尖 ML PhD 人类基线。
这说明,当任务从“写出像论文的文本”变成“真正复现和验证研究贡献”,难度立刻上升。
所以,对 PaperOrchestra 最准确的评价不是“Google 一键替代科研”,而是:它把科研生产中最可流程化、最耗时、最格式化的一段,向自动化推进了一大步。
这已经足够重要。
因为论文写作的成本一旦下降,整个学术系统都会被影响。
真正危险的不是假论文,而是平庸论文泛滥
很多人一谈 AI 写论文,就立刻想到学术造假:虚构数据、编造引用、AI 代写、批量灌水。这些当然是风险,但我觉得更深的风险不是“全假论文”,而是“平庸论文产能暴涨”。
未来的 AI 辅助论文,未必都是假的。它们可能有真实实验,有真实引用,有真实代码,有正常图表,也通过了基本格式检查。但它们可能只是微小改动、指标小涨、套路组合、缺乏洞察。它们看起来像论文,也确实符合论文格式,却没有太多知识增量。
这类论文最难处理。
假论文可以被查,幻觉引用可以被核,伪造数据可以被追责;但平庸论文会淹没审稿系统。它们不一定违规,却会消耗 reviewer 时间,拉低学术信噪比,让真正有想法的工作被埋在海量格式完整的稿件中。
这就是自动科研对学术共同体真正的冲击。
过去,论文写作能力、文献整理能力、LaTeX 能力、英文表达能力,本身就是学术生产的一部分隐性门槛。这个门槛并不总是公平,但它确实限制了论文产量。现在,AI 正在降低这道门槛。门槛下降以后,真正稀缺的就不再是“能不能写成论文”,而是“有没有值得写成论文的东西”。
这会迫使学术评价发生变化。
当每个人都能写出结构完整、图表齐全、related work 扎实的论文,审稿人就不能再被形式感打动。未来真正重要的会是代码是否可复现,实验是否公平,数据是否真实,负结果是否诚实,claim 是否克制,方法是否有不可替代性,问题本身是否值得做。
换句话说,AI 会让论文变得更像工业品。
但科学不能只靠工业品维持。
科研者会从“写论文的人”变成“研究系统导演”
如果自动科研继续发展,研究者不会马上消失,但研究者的工作会被重构。
过去,一个研究者需要亲自完成大量执行性劳动:查文献、整理引用、写 related work、调格式、画图、改表格、补 appendix、写 rebuttal。这些工作很耗时间,也确实锻炼能力,但它们不总是科研中最有创造性的部分。
未来,这些低层劳动会逐渐交给 agent。研究者更像一个 research director,负责设定问题、判断方向、设计验证、审查结果、控制风险、决定哪些结论能写,哪些结论不能写。
这不是“人被 AI 替代”,而是“人的位置上移”。
但位置上移并不意味着轻松。相反,它要求研究者有更强的判断力。
因为 AI 会产出更多 idea、更多实验、更多图表、更多论文草稿。你需要知道哪些是噪声,哪些是幻觉,哪些只是指标偶然上涨,哪些实验没有控制变量,哪些结论只是漂亮叙事。你还要知道什么时候该停止,什么时候该补实验,什么时候该承认失败。
不会用 AI 的研究者,效率会吃亏。
但只会让 AI 批量生产论文、自己没有判断力的研究者,也会很快陷入平庸产出的泥潭。
未来真正强的研究者,不是拒绝 AI 的人,也不是盲目依赖 AI 的人,而是能把 AI 组织成科研流水线,同时仍然牢牢掌握问题、证据和责任的人。
自动科研的边界:AI 能加速研究,但不能替代责任
自动科研系统越强,责任问题越重要。
一篇 PaperOrchestra 生成的论文,如果引用错了,谁负责?如果实验日志本身有问题,系统把它包装成漂亮结论,谁负责?如果 simulated reviewer 没发现关键漏洞,人类作者能不能说“这是 AI 写的”?如果 AI Scientist 生成了一个看似有效但不可复现的结果,算谁的研究?
这些问题不是伦理作文,而是马上会发生的现实问题。
AI 参与科研越深,学术共同体越需要新的披露规范。哪些部分由 AI 生成,哪些实验由 AI 自动执行,哪些引用由系统检索,哪些图表由模型生成,哪些文字经过人类审查,哪些结论由人类承担责任,都需要更清晰地写出来。
否则,自动科研会制造一种危险错觉:论文看起来越来越完整,但责任链越来越模糊。
这也是为什么我更愿意把 PaperOrchestra 看成“高级科研写作基础设施”,而不是“全自动科学家”。它可以极大提高论文成稿效率,可以降低写作负担,可以帮助研究者更快组织材料,但它不能替代科学判断,也不能替代作者责任。
科学不是只要有论文就成立。
科学成立,需要证据,需要验证,需要可复现,需要共同体审查,也需要有人为结论负责。
全自动科研不是终点,而是科研生产方式的重构
PaperOrchestra 的出现,说明自动科研已经不再只是一个概念,而是开始切入真实科研工作流中的具体痛点。
The AI Scientist 尝试端到端科学发现,AI Scientist-v2 推进到 workshop-level 自动论文,Google AI co-scientist 聚焦科学假设和 proposal,FARS 试图直播式规模化自动产出研究,EvoScientist 引入持续记忆和自我进化,PaperBench 用复现任务给 AI agent 降温,而 PaperOrchestra 则把实验日志到投稿论文这段流程系统化。
这些东西合起来,不是一个单点新闻,而是一条趋势:
科研正在被 agent 化。
过去,科研像手工作坊。一个研究者或一个小团队,从想法到实验到论文,靠经验、直觉和大量手工劳动推进。未来,科研会越来越像一个可编排系统:idea 可以批量生成,实验可以自动执行,代码可以自动修改,图表可以自动生成,论文可以自动成稿,评审可以模拟,失败经验可以进入记忆,下一轮继续优化。
这会带来效率提升,也会带来噪声爆炸。
它会让优秀研究者释放大量时间,也会让平庸研究者批量生产“像论文的东西”。
它会让科研门槛降低,也会让学术评价压力增大。
它会让知识生产更快,也会让知识验证更重要。
所以,未来科研真正的瓶颈,可能不再是写不出论文,而是验证不过来;不再是缺少 idea,而是缺少判断;不再是缺少产出,而是缺少信号。
AI 可以一键写论文,但不能一键创造科学
PaperOrchestra 的震撼之处,不是它让 AI 会写论文,而是它让我们看到:论文这种曾经高度依赖人类手工组织的学术产品,正在被拆解成一个可自动化的多智能体流程。
这一定会改变科研。
以后,把实验日志整理成 LaTeX,查 citation,写 related work,生成方法图,排版成 PDF,模拟 reviewer feedback,都会越来越便宜。论文的形式成本会下降,科研表达会加速,更多人会更快把自己的结果写出来。
但这并不意味着科学变简单了。
恰恰相反,当论文变得越来越容易生成,真正困难的东西会更加突出:什么问题值得研究,什么实验真正说明问题,什么结果只是偶然,什么结论不能写,什么发现值得共同体认真对待。
未来最危险的研究者,不是会用 AI 写论文的人。
而是没有判断力,却能无限生成论文的人。
未来最强的研究者,也不是拒绝 AI 的人。
而是能把 AI 变成科研流水线,同时仍然牢牢掌握问题、证据、验证和责任的人。
AI 可以把论文变成工业品。
但科学,仍然必须经得起时间、证据和共同体的检验。
https://arxiv.org/pdf/2408.06292
https://arxiv.org/pdf/2504.08066
https://arxiv.org/pdf/2603.08127
https://research.google/blog/accelerating-scientific-breakthroughs-with-an-ai-co-scientist/
https://arxiv.org/pdf/2604.05018
https://www.marktechpost.com/2026/04/08/google-ai-research-introduces-paperorchestra-a-multi-agent-framework-for-automated-ai-research-paper-writing/?utm_source=chatgpt.com