 夜雨聆风
夜雨聆风





AI行为研究|学新的,忘旧的,为何微调之后幻觉更重?

编者按:大语言模型(LLM)经监督微调(SFT)后普遍存在学会新知识、遗忘旧知识的幻觉问题,核心诱因是微调破坏了模型预训练阶段已形成的内部知识。如何让模型在适配新任务、吸收新知识的同时,守住事实记忆,成为大模型微调落地的关键难题。
来自耶路撒冷希伯来大学、伊利诺伊大学厄巴纳–香槟分校、以色列理工学院与南加州大学的研究团队,将SFT引发的幻觉重新定义为持续学习中的“事实遗忘”,并证实这类遗忘的核心驱动是新旧知识的语义表示重叠。团队据此提出两类方案,既厘清了SFT幻觉的底层机制,也为大模型微调提供了理论支撑与实践方法。
补充术语说明
SFT(Supervised Fine-Tuning):监督微调,大模型标准训练环节
事实可塑性(Factual Plasticity):模型学习新事实知识的能力
事实稳定性(Factual Stability):模型保留原有事实知识的能力
自蒸馏(Self-Distillation):通过正则化约束模型输出分布贴近微调前状态,防止知识遗忘
SLiCK:模型知识分类方法,将知识划分为高度已知、可能已知、未知等层级
01 大模型微调隐患:
学习新知识触发 “事实遗忘”
现有研究已证实,使用新增事实知识进行监督微调(SFT)时,会导致模型对预训练阶段已掌握的事实准确性显著下降,表现为幻觉增多。
为了厘清这一现象的本质,本研究采用SLiCK 方法将模型知识严格划分为三类,实现了「任务格式学习」与「事实知识学习」的完全解耦,为后续实验搭建了清晰的评估框架。
-
D_Known(已知事实):模型预训练阶段已掌握的「高度已知」事实,参与训练,核心作用是让模型学习问答任务的格式模板。
-
D_Unk(未知事实):模型预训练阶段未掌握的「未知」事实,参与训练,核心作用是测试模型的事实可塑性(学习新知识的能力)。
-
D_Held(保留事实):模型预训练阶段已掌握的「高度已知」事实,不参与训练,核心作用是评估模型的事实稳定性(是否遗忘旧知识)。
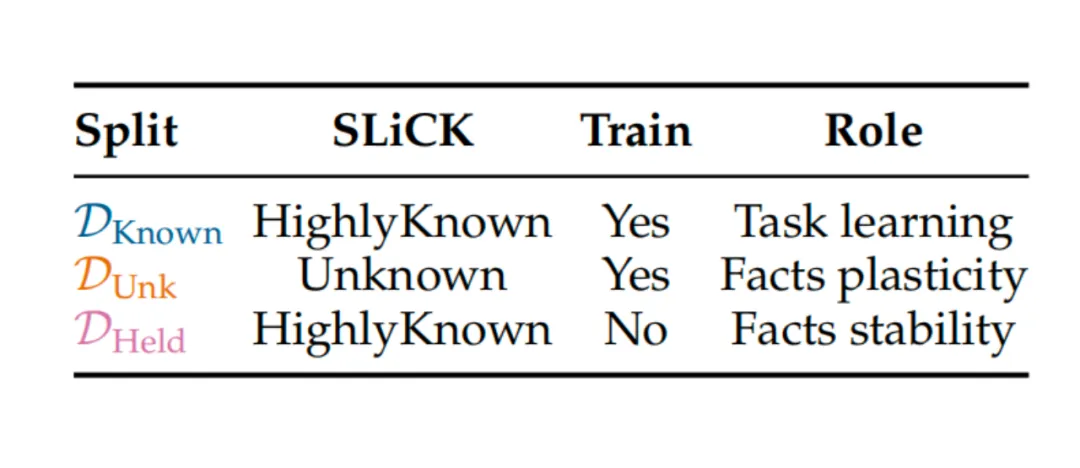
表1:SLiCK 数据划分规则与实验角色定义
基于这一划分,研究团队设计了两组对照实验:
-
标准SFT(Standard SFT):即常规监督微调,训练数据同时包含D_Know和D_Unk,模型一边学习问答格式,一边吸收新知识,用来模拟真实业务中的微调场景。
-
仅用已知事实SFT(Only Known SFT):作为对照实验,训练数据仅包含D_Known,完全不引入D_Unk,模型仅学习问答格式,不接触任何新知识,用来验证“没有新知识时是否会发生遗忘”。
图 1 对比了两种训练模式下,模型在三类数据上的准确率变化:
-
左图(标准SFT)呈现典型的两阶段特征:模型初期快速适配问答格式,D_Known(蓝线)准确率迅速达到100%;随后随着D_Unk(橙线)新知识的持续习得,D_Held(粉线)的准确率逐步下降,遗忘幅度约15%。
-
右图(仅用已知事实SFT)中,由于训练数据不含任何D_Unk,模型在快速掌握任务格式后,D_Known(蓝线)、D_Held(粉线)的准确率全程稳定在高位,未出现任何遗忘现象。
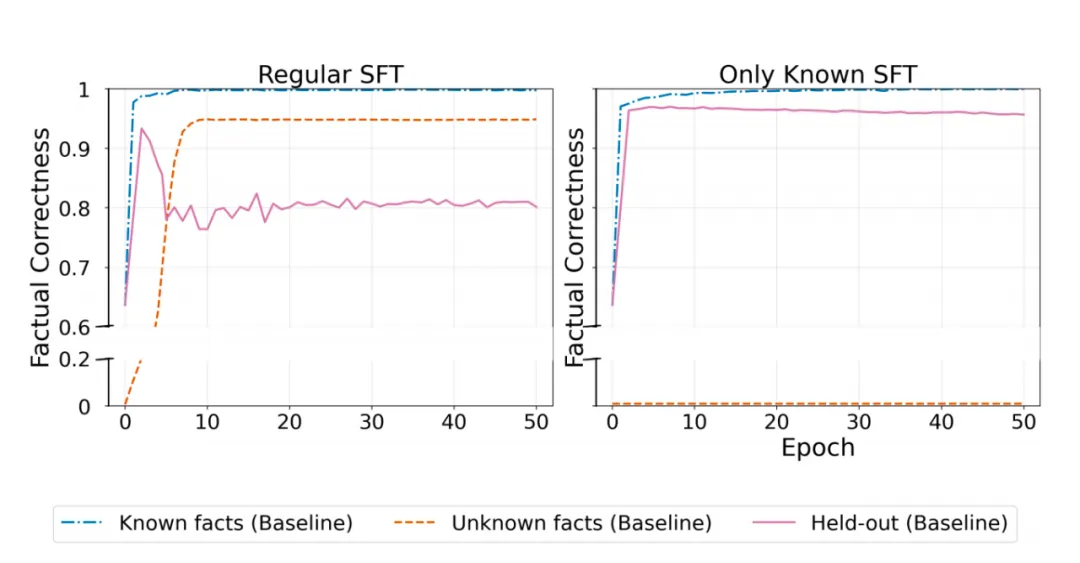
图1:事实遗忘由新知识习得驱动,而非微调本身
两组实验的对比直接排除了“微调本身会导致遗忘”的可能,实验证明:
幻觉并非微调本身导致,而是新知识习得引发的事实遗忘(Factual Forgetting)。
这一现象本质上反映了模型在「事实可塑性」(学习新知识的能力)与「事实稳定性」(保存旧知识的能力)之间的内在权衡。
02 根源探究:
语义重叠引发表征空间局部干扰
为什么学习新知识会破坏旧知识?是因为模型的存储容量不够了吗?还是因为微调改变了模型的行为模式?
研究团队假设,真正的驱动因素是“结构性干扰”:
当新实体与旧实体在字面或语义上相似时,它们在模型内部的表示区域会发生重叠,更新新知识的权重就会不可避免地“误伤”旧知识。
本实验设计了两类完全可控的新实体,用于验证“语义重叠是致幻根源”的假说:
-
“语义键(Semantic keys)”:通过重新组合真实地名的 token 生成(听起来像真实地名,如 Bergadena)。
-
“UUID 键”:由随机的 8 位十六进制字符组成(如 Loc_fcfb42ee),与真实实体毫无字面重叠。
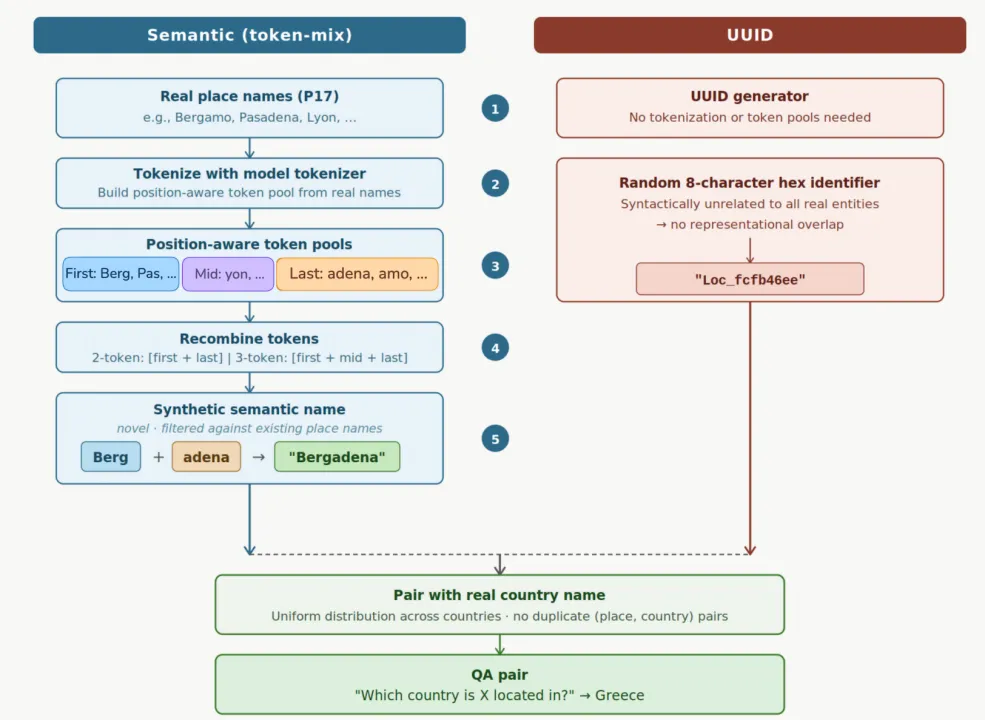
图2:两大实体的构建流程
这两类实体的关键差异,在于它们与模型内部已有知识的语义表示重叠程度。研究团队正是利用这一差异,验证了“结构性干扰”假说:
当新实体与旧实体在语义空间中共享表示区域时,微调过程中对新实体的参数更新,会直接干扰旧实体的记忆,进而引发幻觉。
图 3 直观阐释了新旧知识的语义重叠如何引发事实遗忘:
-
模型的内部语义空间中,真实城市(如巴黎、米兰)的实体表示是共享的。当学习一个与真实地名语义高度相似的虚构实体(如Bergadena)时,其表示会与真实城市发生重叠,导致模型对已有事实的记忆被干扰,引发大量幻觉;
-
而学习与真实实体无任何字面/语义关联的随机标识符(如 Loc_fcfb42)时,由于二者的表示空间完全不重叠,即便新增百万级事实,也不会引发任何相关幻觉;
-
左右两侧的柱状图进一步量化了这一差异:
随着新增语义相似事实数量的增加,幻觉率急剧上升;而新增随机标识符事实的数量,对幻觉率几乎没有任何影响。
两组实验的对比直接排除了“容量限制”假说,证明不是模型装不下新知识,而是新知识与旧知识的语义重叠,导致了表征空间的局部干扰,最终引发事实遗忘。
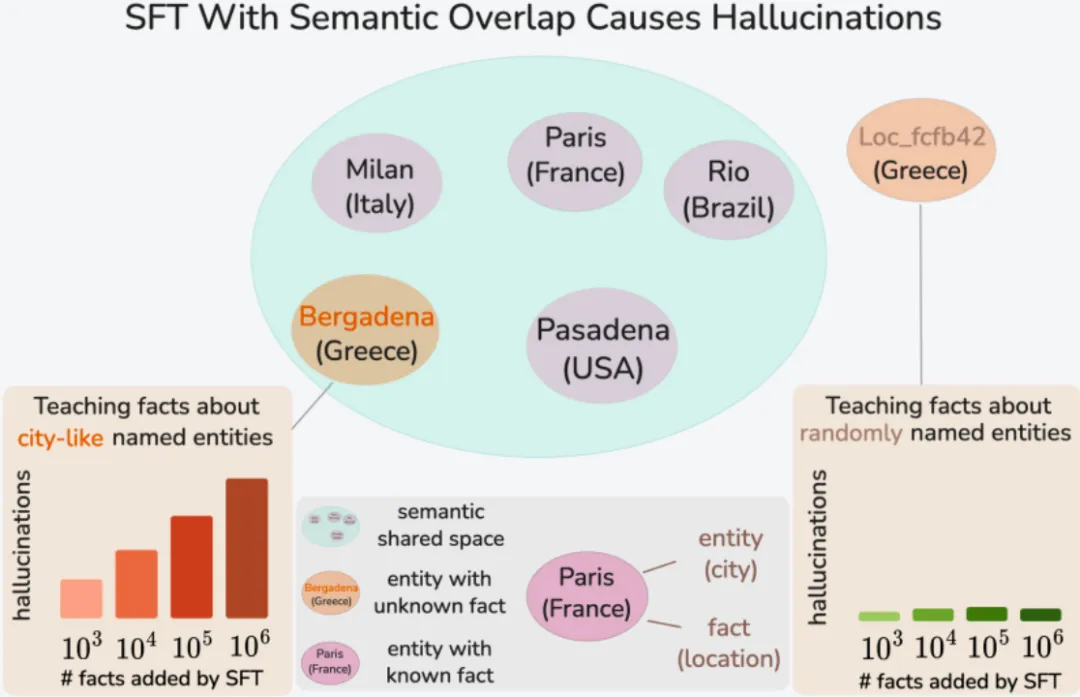
图3:语义重叠是SFT 引发幻觉的核心驱动
03 两种幻觉缓解方案
基于“语义重叠引发表征干扰”的核心机制,研究团队提出了分场景适配的两类解决方案,覆盖大模型微调全场景需求,实现了事实可塑性与事实稳定性的动态平衡。
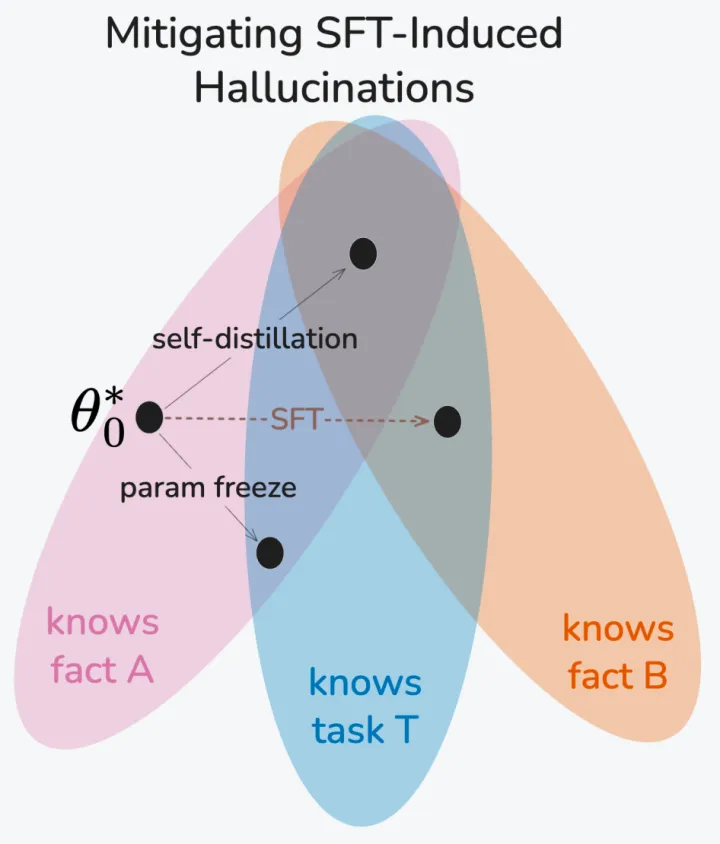
图5:三种微调策略的参数空间对比
本图直观呈现了标准SFT、参数冻结、自蒸馏三种策略的差异:
-
标准SFT(虚线箭头):为学习新事实B,会偏离原有事实A的参数区域,导致旧知识被“冲掉”;
-
参数冻结(param freeze):能保留旧事实,但会完全阻断新知识的吸收;
-
自蒸馏(self-distillation):则能同时保留旧事实、掌握新事实与任务能力,是兼顾二者的最优路径。
方案一:限制事实可塑性(无需学习新知识场景)
在对齐微调、格式学习等无需吸收新事实的场景中,我们的核心目标是掌握任务格式、不吸收新知识、不引发旧知识遗忘。研究发现,通过选择性冻结参数,可以精准限制模型的事实可塑性,从而最大化保护事实稳定性。
具体而言,冻结前馈网络(FFN)而仅更新注意力层(Attention layers),能够让模型完美掌握问答任务的格式,同时几乎完全阻断对新事实的吸收。
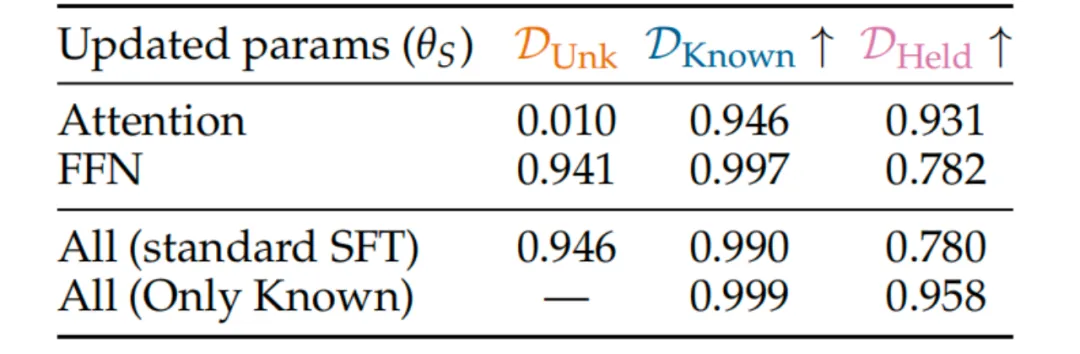
表2:参数冻结策略的效果对比
本实验对比了不同粗粒度参数更新策略下,模型在事实可塑性与稳定性上的表现差异:
-
仅更新注意力层时,模型的新知识学习能力被几乎完全抑制(D_Unk=0.010),同时保留集事实的准确率高达0.931,实现了“任务格式学习+零事实遗忘”的安全微调效果;
-
仅更新FFN 层时,模型的事实可塑性显著增强(D_Unk=0.941),与标准SFT持平,但保留集事实的准确率大幅下降至0.782,遗忘现象依然存在;
-
标准SFT与仅用已知事实训练的基线对比进一步验证:当不引入任何新知识时,模型的保留集准确率可稳定维持在0.958的高水平,证明遗忘是由新知识习得直接驱动的。
为了进一步定位影响事实可塑性的关键模块,研究团队开展了更细粒度的消融实验。
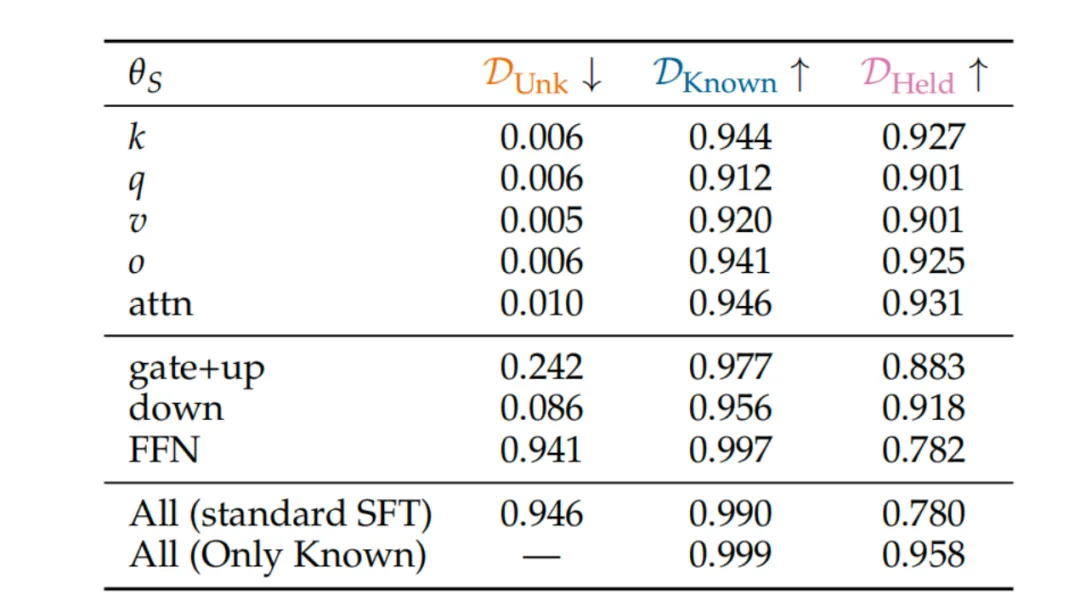
表3:细粒度参数冻结消融实验
本实验对模型的不同参数模块进行了精细化冻结,验证了“事实可塑性与事实稳定性的负相关关系”:
-
仅更新注意力相关参数(k/q/v/o/attn)时,模型的新知识学习能力被几乎完全抑制(D_Unk≈0.005~0.010),同时保留集事实的准确率维持在 0.90 以上,实现了 “任务格式学习 + 零事实遗忘”;
-
更新FFN 层时,尤其是gate+up模块,模型的事实可塑性显著增强(D_Unk升至 0.242~0.941),但保留集事实的准确率也随之大幅下降至 0.78~0.88;
-
所有配置均呈现一致趋势:新知识学习能力越强,旧知识遗忘越严重,直接证明了事实可塑性是引发SFT 事实遗忘的核心中介变量。
方案二:自蒸馏(必须学习新知识场景)
在领域适配、知识库更新等需要吸收新事实的场景中,我们无法限制模型的事实可塑性,因此需要引入自蒸馏技术,在学习新知识的同时,通过正则化约束模型的输出分布,保护旧知识的表征结构。
自蒸馏的核心逻辑是:以微调早期(仅用已知事实训练一轮)的模型作为Teacher,在后续 SFT 训练中,约束 Student 模型的输出分布尽量贴近 Teacher 模型,避免参数更新对旧知识的表征空间造成过度干扰。
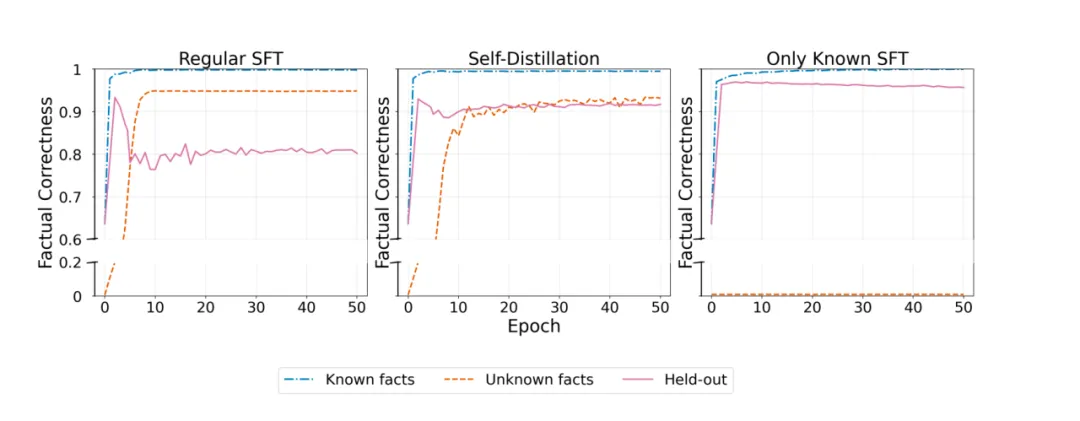
图3:三种训练策略的动态对比(标准 SFT vs 自蒸馏 vs 仅用已知事实 SFT)
本图直观呈现了自蒸馏缓解遗忘的效果:
-
左图(标准SFT):随着未知事实(橙线)的学习,保留集事实(粉线)的准确率下降约 15%;
-
中间(自蒸馏训练):模型学习未知事实的效率与标准SFT 持平,同时保留集事实的准确率仅下降约 3%,大幅缓解了遗忘。
-
右图(仅用已知事实SFT 基线):保留集事实准确率全程稳定,无任何遗忘;
自蒸馏的核心优势在于,它没有像参数冻结那样阻断新知识学习,而是通过输出分布的约束,间接保护了模型内部的表征结构。这种约束使得模型在更新新知识的参数时,不会过度修改与旧知识共享的语义空间,从而在事实可塑性与事实稳定性之间找到了平衡。
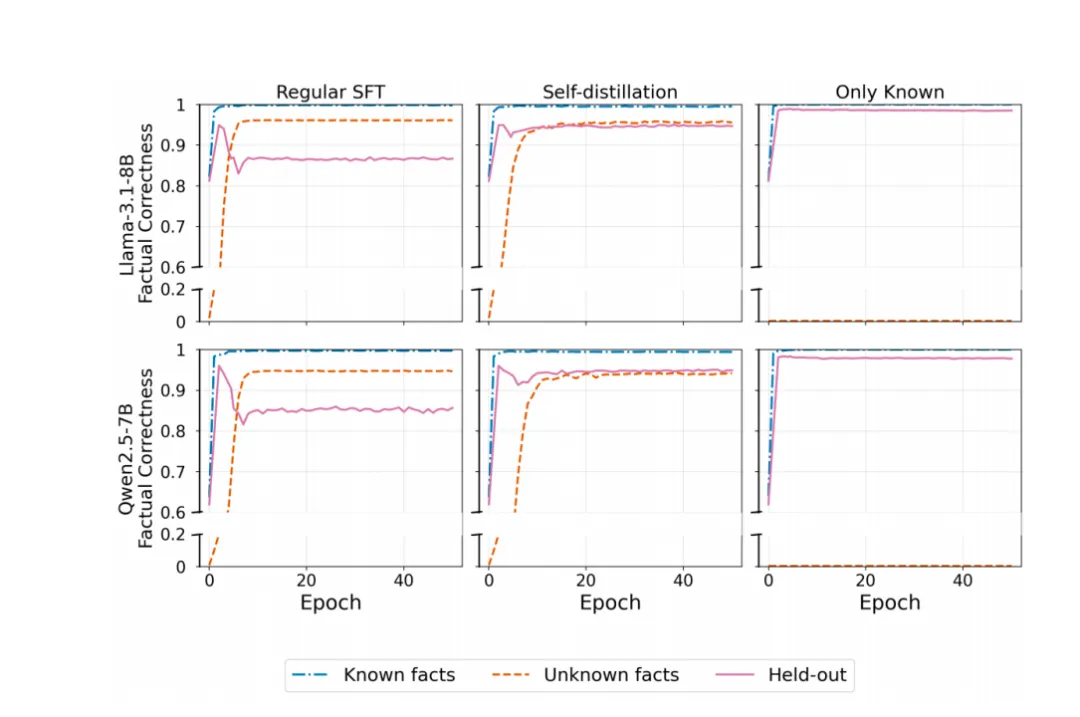
图4:跨模型训练动态验证(Llama-3.1-8B & Qwen2.5-7B)
本图在两个主流模型上重复了三种训练策略的实验,结果高度一致:
-
标准SFT(左列):两个模型都呈现出典型的 “两阶段遗忘” 特征,D_Held(粉线)准确率在学习新知识后出现明显下降;
-
自蒸馏(中列):两个模型的D_Held准确率都得到了显著保护,下降幅度远小于标准SFT,同时D_Unk(橙线)的学习效率并未受到明显影响;
-
仅用已知事实SFT(右列):作为对照,两个模型的D_Held准确率全程稳定,无任何遗忘现象。
跨模型验证的结果证明,自蒸馏缓解SFT事实遗忘的效果不依赖特定模型架构,具有广泛的普适性。这一保护效果不仅体现在模型高度已知的核心知识上,对掌握程度较弱的边缘知识同样有效。
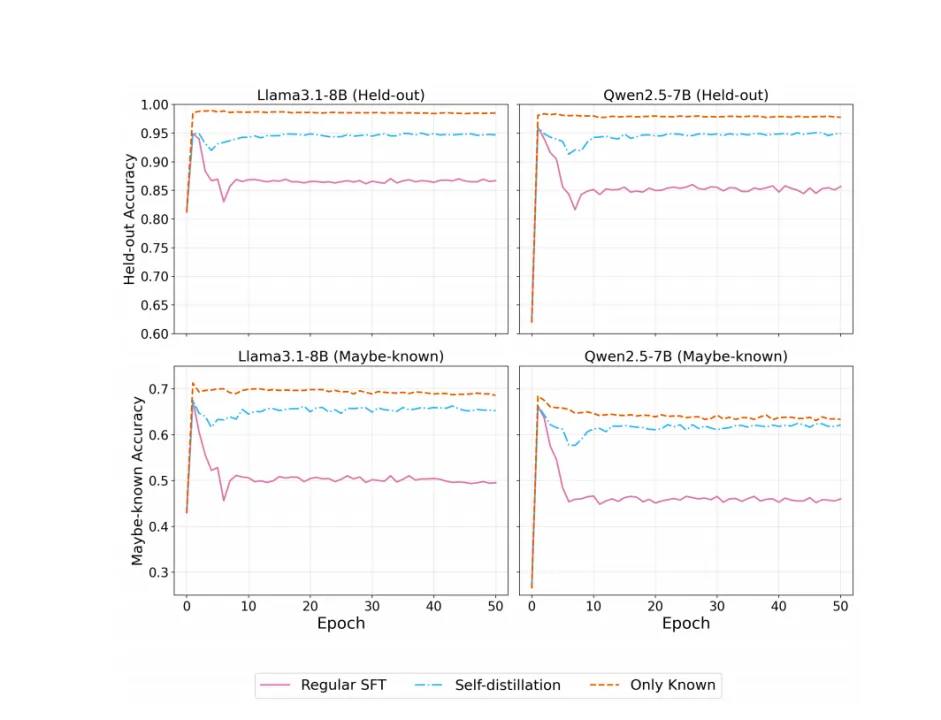
图8:不同知识强度下的保护效果验证(D_Held & MaybeKnown)
本图在Llama-3.1-8B 和 Qwen2.5-7B 上,验证了三种训练策略对不同强度知识的保护效果:
l上排(D_Held高度已知事实):与图7 的结论一致,标准 SFT(粉线)的准确率下降明显,自蒸馏(蓝线)的下降幅度显著降低,仅用已知事实 SFT(橙线)全程稳定;
l下排(MaybeKnown 弱已知事实):标准 SFT 对这类知识的遗忘更为严重,准确率下降幅度远大于D_Held;而自蒸馏依然能有效缓解遗忘,保护效果与仅用已知事实SFT 更为接近。
这一结果进一步证明:自蒸馏对模型知识的保护是全面的,不仅能稳定核心事实,也能有效防止边缘知识在微调过程中被“冲掉”。
核心结论与行业启示
本研究将SFT幻觉转化为持续学习中的事实遗忘问题,通过系统性实验得出三大核心结论:
1.降低事实可塑性可减少幻觉:无需学习新知时,冻结FFN 等参数可保留任务性能,同时杜绝事实遗忘;
2.自蒸馏实现“学新知不忘旧知”:通过约束输出分布漂移,在不影响新知识学习效率的前提下,将 SFT 幻觉降至最低;
3.语义重叠是致幻核心:幻觉并非由模型容量瓶颈导致,而是新知识与旧知识的语义重叠,引发表征空间的局部干扰所致。
从行业实践来看,这项研究呼吁将事实稳定性作为微调的核心优化目标,与任务性能同等重视。未来依托持续学习工具,可开发更精准、更可靠的微调技术,让大模型在持续进化中牢牢守住基础事实知识。
论文标题:Why Fine-Tuning Encourages Hallucinations and How to Fix It
作者:Guy Kaplan、Zorik Gekhman、Zhen Zhu、Lotem Rozner、Yuval Reif、Swabha Swayamdipta、Derek Hoiem、Roy Schwartz
单位:耶路撒冷希伯来大学、伊利诺伊大学厄巴纳–香槟分校、以色列理工学院、南加州大学
 责任编辑|陈佳苗
责任编辑|陈佳苗