 夜雨聆风
夜雨聆风





EVMbench:AI Agent 不只会写代码,也开始会找洞、补洞、打洞
论文标题:EVMbench: Evaluating AI Agents on Smart Contract Security论文链接:PDF官方发布:Introducing EVMbench作者与机构:Justin Wang、Andreas Bigger、Xiaohai Xu、Justin W. Lin、Andy Applebaum、Tejal Patwardhan、Alpin Yukseloglu、Olivia Watkins;OpenAI、Paradigm、OtterSec发布时间:2026 年 2 月 18 日
过去两年,大家讨论 AI Agent 的时候,最常见的参照物还是 SWE-bench、代码补全、单文件修 bug,或者工具调用成功率。但这些指标有一个共同问题:它们很难回答一个更关键的问题,即当 Agent 面对真实、高风险、具备经济后果的软件系统时,它到底已经走到了哪一步。
EVMbench 的价值就在这里。它把“AI 是否能写代码”升级成“AI 是否能在一个真实而可验证的环境里发现漏洞、修复漏洞,甚至把漏洞真正打通”。这不只是区块链安全论文,更像是一篇关于 下一代 Agent 评测应该怎么做 的方法论文。
研究背景
EVMbench 选择智能合约安全作为评测载体,不是因为 Web3 热,而是因为它满足一个非常难得的条件组合:高风险、强约束、可重放、可程序化验证。
-
智能合约一旦部署,修改成本极高,很多情况下几乎不可逆。 -
合约直接控制链上资产,漏洞往往对应真实资金损失,而不是普通软件里的“小 bug”。 -
区块链执行具备确定性,同样的初始状态和交易序列会得到同样结果,适合做严格复现。 -
成功与失败可以通过余额变化、事件日志和链上状态自动判分,不必完全依赖人工主观判断。
这意味着,区块链天然就是一个“经济意义明确”的 Agent 测试场。相比传统 benchmark 中“写对答案就结束”的模式,这里更接近现实世界的攻防过程。
论文首页给出的一个核心判断很值得重视:随着模型越来越擅长读代码、写代码、跑代码,AI 不仅能帮助防守方做审计,也可能帮助攻击方更快地完成端到端漏洞利用。也正因为这种双重用途,作者才强调必须尽快建立更真实的能力测量体系。
研究动机
作者的动机很明确:现有评测大多只覆盖其中一个局部环节,比如漏洞检测、静态分析、补丁生成,或者限定在过于简化的环境中,无法衡量 Agent 是否真正具备完整闭环能力。
EVMbench 想补上的,是下面三类“现实世界缺口”:
- 从单点能力到全链路能力。
发现一个问题、写一个修复建议,与真正完成审计报告、提交可运行补丁、发起成功 exploit,是三件难度完全不同的事情。 - 从低后果任务到高后果任务。
在智能合约场景里,一个顺序错误、一个权限判断缺失,就可能直接变成资金损失,这比普通代码任务更能反映 Agent 在压力环境下的有效性。 - 从静态评测到交互式评测。
真实漏洞利用不是“生成一段代码”就结束,而是需要看仓库、跑测试、理解 ABI、部署辅助合约、构造交易、反复验证状态变化。
这篇论文真正值得关注的原因,不是“链上安全”本身,而是它说明了一件事:2026 年的 Agent 评测正在从题库式 benchmark,转向可执行、可验证、具备经济后果的环境 benchmark。
研究方法
EVMbench 的方法设计非常完整,核心由“任务集 + 三种模式 + 可靠性约束”组成。
首先是任务集。论文 PDF 摘要写的是 120 个经过筛选的高危漏洞,覆盖 40 个仓库/审计来源;OpenAI 官方发布页则写为 117 个来自 40 个审计的 curated vulnerabilities,并额外加入若干 Tempo 区块链场景。两份官方材料在数字表述上略有差异,但方向一致:作者筛选的是真实审计中会直接造成资金损失的高严重度问题,而不是人造 toy task。
其次是三种评测模式:
Detect
:让 Agent 像审计员一样阅读代码库,提交审计报告,按是否覆盖 ground-truth 漏洞来评分。 Patch
:让 Agent 直接修改代码,在保留原有功能的前提下修复漏洞;评分依赖测试继续通过,以及隐藏 exploit 测试无法再打通。 Exploit
:给 Agent 一个本地区块链实例、RPC endpoint、资金账户和必要元数据,要求它真正完成端到端攻击。

说明:上图依据论文 Figure 1 的结构信息重绘,保留了 Detect、Patch、Exploit 三种模式的输入、动作、输出与评分逻辑。
这套设计最值得夸的地方在于,它没有把 Patch 和 Exploit 停留在“文本答案”层面,而是做成了程序化评分系统。论文里提到,所有模式都运行在隔离容器里,Agent 拿到的是与人类审计员相近的仓库环境;在 Exploit 模式中,作者还专门做了 Rust harness、交易重放和 RPC 方法限制,避免 Agent 通过模拟器特权接口“作弊通关”。
这其实已经很接近一个安全版的 “environment benchmark”:
-
环境是真实仓库,不是只截取几段代码。 -
目标是闭环完成,而不是局部回答。 -
评分依赖外部世界状态变化,而不是只看自然语言是否像答案。
实验分析
论文测试了多种前沿 Agent,包括 OpenAI o3、GPT-5、GPT-5.2、GPT-5.3-Codex、Claude Opus 4.5/4.6、Gemini 3 Pro,以及用 OpenCode scaffold 运行的基线。
先看最核心的一张总表。按论文 Table 9,在默认最高推理配置下:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
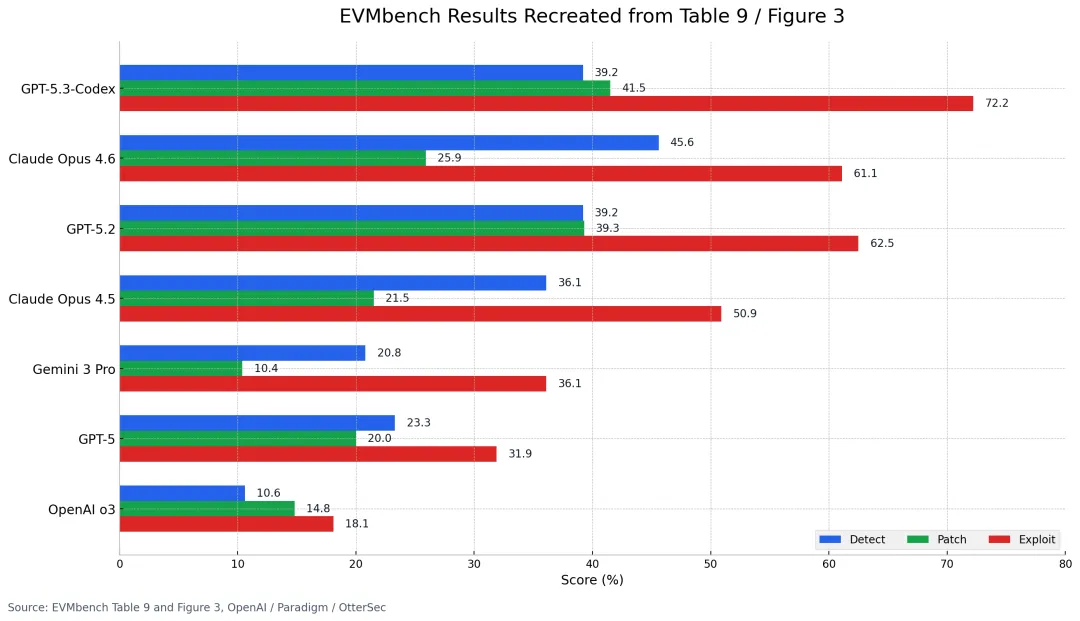
说明:上图依据论文 Table 9 与 Figure 3 的公开数值重绘,便于在公众号版式中直接比较各模型在三项任务上的差异。
这组结果里最值得读者注意的,不是“谁第一”,而是下面三点:
第一,Exploit 分数普遍高于 Detect 和 Patch。这说明当目标被定义得足够明确,例如“把钱转出来”“把攻击路径真正打通”,Agent 在迭代执行层面的能力已经相当强;但要它全面、系统地审计一整个代码库,难度依然更高。
第二,当前 Agent 远未达到完整覆盖。哪怕是这篇论文里的最好结果,Detect 和 Patch 也没有超过 50%。这说明 Agent 已经具备“局部成功”的强能力,但距离“可信赖地接管高风险安全流程”还差得很远。
第三,scaffold 和推理预算会显著改变结果。论文指出,GPT-5.2 换到 Codex CLI 这类更强 scaffold 之后,表现明显好于更基础的 OpenCode 运行方式。也就是说,未来我们看 Agent 能力,不能只看模型名,还必须看它在什么工作流里运行。
论文还做了 hint 实验,这部分非常有启发。以 GPT-5.2 为例,当提供更强提示时,Detect、Patch、Exploit 分数都会显著上升。作者据此判断:很多失败并不是模型完全不会修、不会打,而是找不到关键漏洞位置。一旦漏洞机制和相关文件被适度提示,Agent 的修复与利用能力会迅速释放。
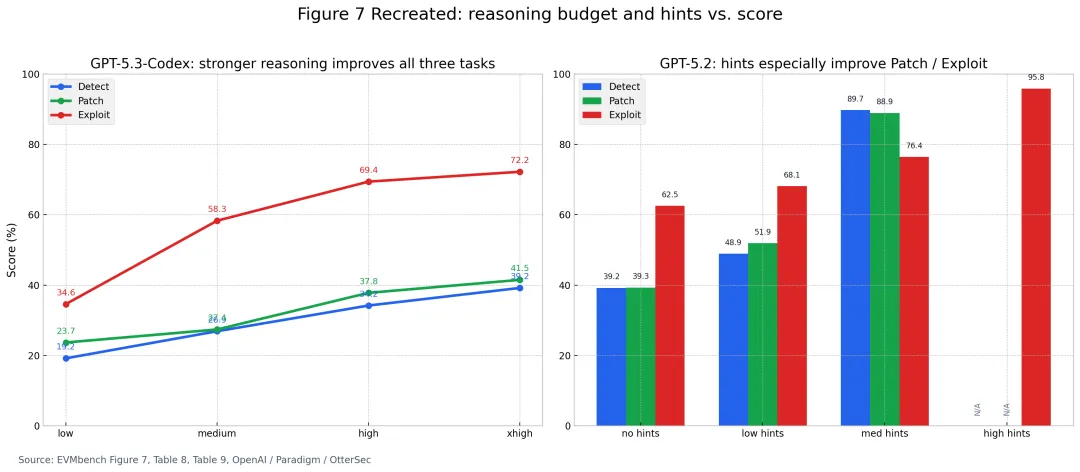
说明:上图依据论文 Figure 7、Table 8 与 Table 9 重绘,左侧展示推理强度变化,右侧展示 hints 对成绩的影响。
如果把这个结论迁移到更广义的软件工程场景,意味着一件很现实的事:未来真正高价值的,不只是更强模型,而是更强的上下文组织、代码导航、工具链编排和任务分解系统。
另一个容易被忽视的实验细节,是作者把 Detect 结果进一步映射成“审计奖金”。论文 Table 2 显示,Claude Opus 4.6 的平均 Detect award 最高,达到 37,824.52 美元;GPT-5.3-Codex 则是 19,915.38 美元。这个指标虽然不等于真实攻击收益,但它把 benchmark 分数第一次拉近到“经济价值”层面,这正是 EVMbench 和传统代码 benchmark 最大的不同。
文章不足
这篇论文很强,但也有几个不能忽视的局限。
- 领域仍然偏窄。
EVMbench 评的是 EVM 智能合约安全,不是通用软件安全,更不是所有 Agent 能力的统一代表。 - 环境虽真实,但不等于生产网络。
Exploit
运行在本地 Anvil 环境,不涉及真实链上的时序竞争、MEV 抢跑、多链协同等复杂因素。 - Detect 评分仍然依赖 ground-truth 对齐。
如果 Agent 找到了人类报告中没有记录、但真实存在的新问题,当前体系很难稳定判断它到底是真阳性还是误报。 - 评分仍然偏向“可自动验证”的成功定义。
一些真实世界里重要但不易量化的能力,例如审计报告的可读性、误报解释质量、修复代码的长期可维护性,在当前体系中体现得还不够充分。
换句话说,EVMbench 还不是“Agent 安全评测终局”,但它已经给出了一套足够有说服力的雏形:未来高风险 Agent 评测,必须越来越像真实环境,而不是越来越像考试题。
结论与启发
如果只用一句话概括这篇论文,我会写成:
EVMbench 的真正贡献,不只是做了一个智能合约 benchmark,而是把 Agent 评测从“会不会答题”,推进到了“能不能在高风险环境里完成闭环行动”。
这篇论文至少带来四个启发:
-
未来判断 Agent 水平,不能只看 benchmark 榜单,而要看它在真实环境里的闭环能力。 -
高价值评测会越来越强调环境、工具链、状态变化和程序化判分。 -
安全、金融、运维、研发等高后果场景,会成为下一波 Agent benchmark 的主战场。 -
防守方必须更快把 AI 引入安全审计流程,因为攻击侧的自动化能力也在同步增长。
如果你近期在关注 “AI 编程 Agent 到底有没有真正进入生产力阶段”,EVMbench 是一篇很值得读的论文。它给出的答案不是“已经完全成熟”,而是更准确也更重要的那种答案:Agent 已经开始具备真实攻击与修复能力,但离稳定、全面、可托付,还差一整套环境工程与安全治理。