AgentScope 源码剖析(一):Msg 是如何设计的?
一开始看智能体框架,很容易直接去看 Agent、ReActAgent、Tool Calling、Memory 这些模块。它们确实重要,但真正读源码时会发现,这些模块之间都绕不开一个更基础的对象:
如果不先理解 Msg,后面再看 memory.add(msg)、formatter.format(msgs=…)、工具调用结果、RAG 检索结果、长期记忆内容时,很容易只看到函数调用,却看不清信息到底是如何在框架里被组织和传递的。
所以这一篇先看 AgentScope 的 Message 模块。
AgentScope 是如何设计 Msg 这个消息对象的?
01 为什么先看 Message 模块?
RAG 检索内容、长期记忆检索内容,也都需要被放入上下文中,参与后续推理。
因此,在看 Agent 如何推理之前,先要看一个更基础的问题:
它应该作为 user、assistant 还是 system 进入模型?
AgentScope 对这个问题的回答,就是 Msg。
02 Message 模块的源码结构
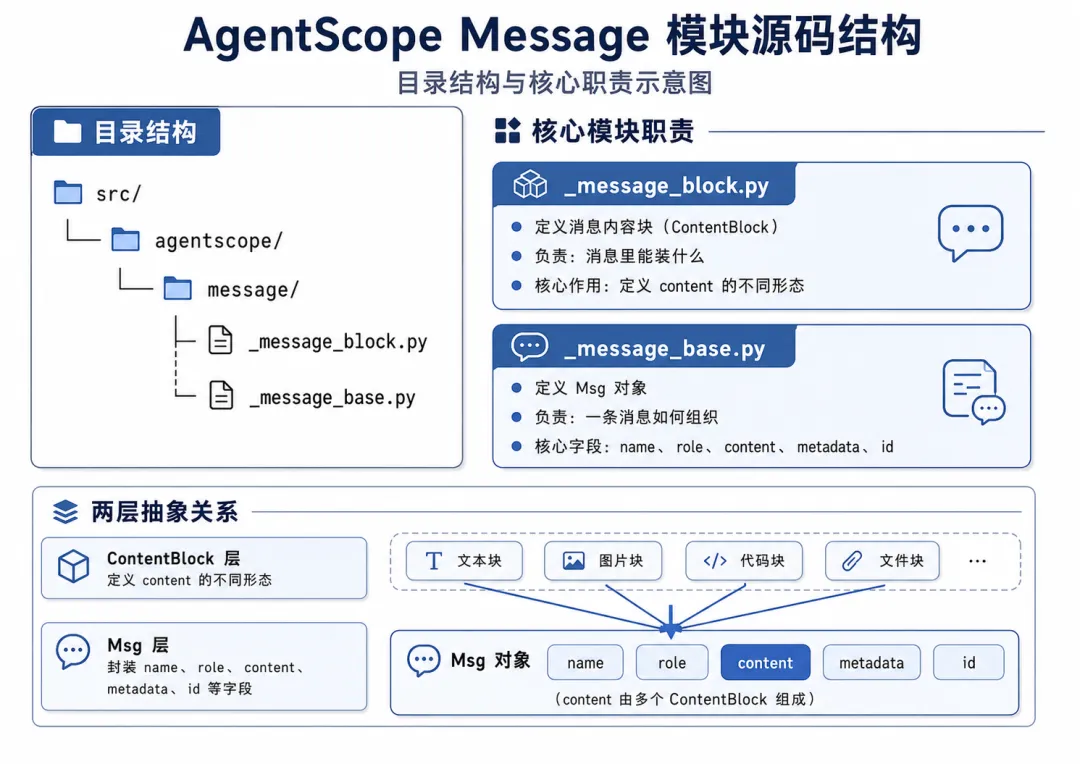
_message_block.py 负责定义消息内容块。
_message_base.py 负责定义 Msg 这个消息对象。
换句话说,AgentScope 并不是直接把消息设计成一个简单的类,而是分成了两层:
第一层是内容块系统,负责说明消息内容里可以放什么。
第二层是消息对象本身,负责说明一条完整消息应该如何组织。
【图1:Message 模块源码结构图】图注:AgentScope message 模块的源码结构。_message_block.py 定义内容块,_message_base.py 定义 Msg 对象。
因为如果只看 Msg 这个类,很容易以为它只是一个带有 name、role、content 的普通数据对象。
但从源码结构看,AgentScope 实际上是在表达:
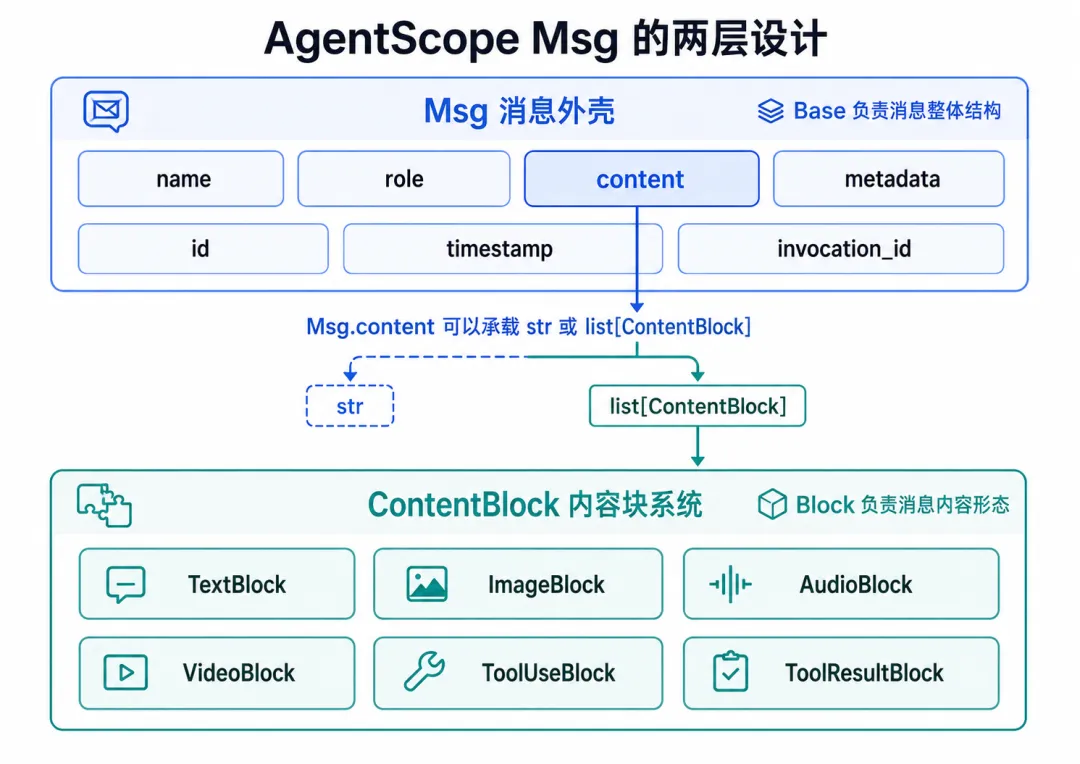
Msg 不是单纯的字符串封装,而是由“消息外壳”和“内容块系统”共同组成的消息抽象。
03 _message_block.py:content 为什么不是简单字符串?
这个文件的核心作用,是定义 Msg.content 可以有哪些内容形态。
在普通聊天程序里,消息内容通常就是一段字符串。例如:
但 AgentScope 面向的是智能体场景。智能体上下文里的内容,往往不只是文本。
它可能是普通文本,也可能是 reasoning 内容。
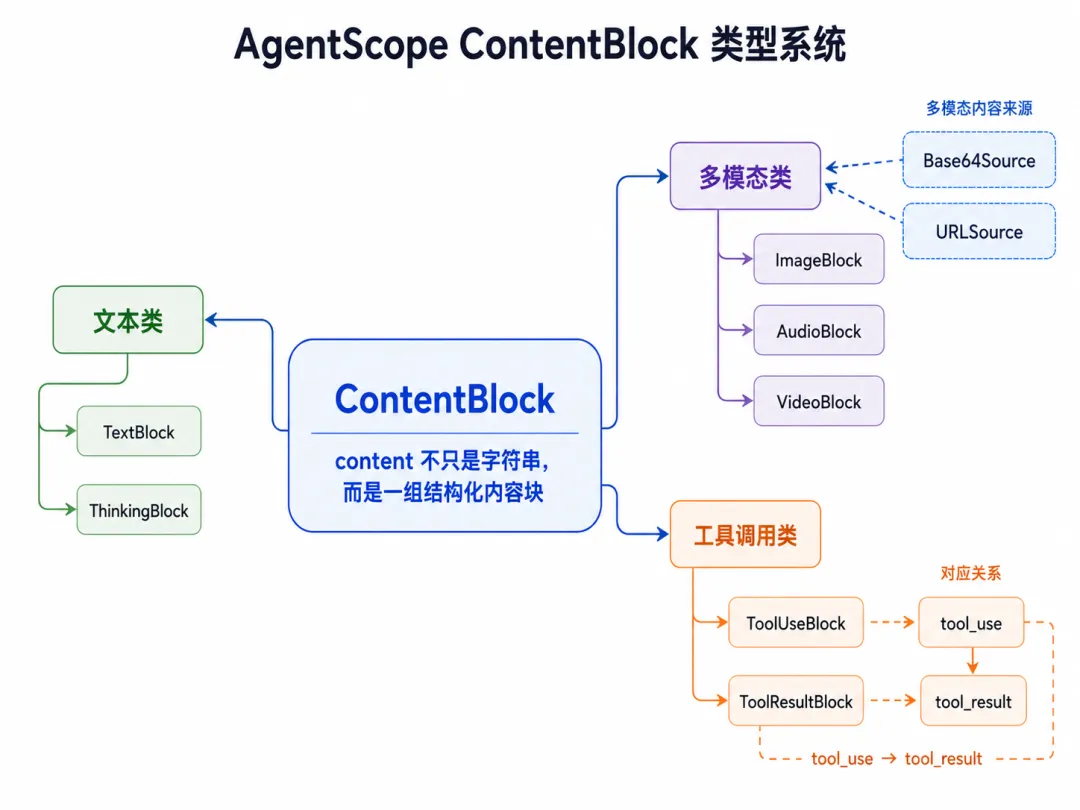
所以 AgentScope 设计了一组 ContentBlock,用来表达不同类型的消息内容。
第一类是文本类 Block,用来表示文本内容和推理内容。
第二类是多模态类 Block,用来表示图片、音频、视频等内容。
第三类是工具调用类 Block,用来表示工具调用请求和工具返回结果。
【图2:ContentBlock 类型系统图】图注:ContentBlock 类型系统。Msg.content 不只是字符串,而是一组结构化内容块。
因为字符串只能表达内容本身,却很难稳定表达内容的类型。
调用 search 工具,参数是 {“query”: “AgentScope”}
这当然可以被人读懂,但对框架来说,它只是一段普通文本。
如果它被表示成 ToolUseBlock,系统就能明确知道:这是一次工具调用,工具名是什么,参数是什么,调用编号是什么。
如果工具结果只是普通文本,后续模块很难判断它是 assistant 的自然语言回复,还是某个工具调用对应的结果。
所以,_message_block.py 的价值在于:
它为 Msg.content 提供了结构化表达能力。
这也是 AgentScope 能够支持工具调用、多模态内容和复杂智能体推理链路的基础。
04 _message_base.py:Msg 是如何组织一条消息的?
理解了内容块,再看 _message_base.py。
如果说 _message_block.py 关注的是“消息内容可以有哪些形态”,那么 _message_base.py 关注的就是“一条完整消息应该包含哪些信息”。
其中最值得关注的是 name、role、content 和 metadata。
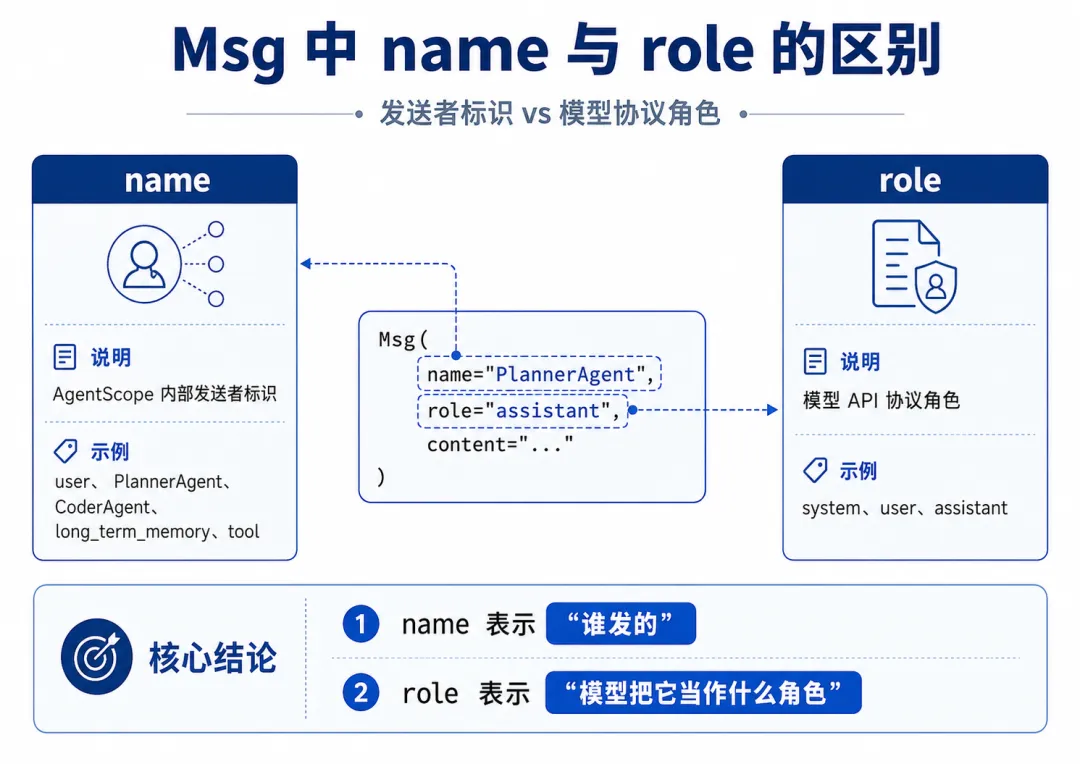
在简单场景里,它可能是 user 或 assistant。
但在多 Agent 场景中,它可以是 PlannerAgent、CoderAgent、ReviewerAgent,也可以是 long_term_memory 或某个工具名称。
所以,name 更偏 AgentScope 框架内部的身份标识。
这也解释了为什么 name 和 role 要分开。
AgentScope 内部可能有很多消息发送者,但模型 API 通常只接受有限的角色类型。
【图3:name 与 role 的区别图】图注:name 和 role 的区别。name 是框架内部发送者身份,role 是模型协议中的角色。
content可以是普通字符串,也可以是 ContentBlock 列表。
这就把 _message_block.py 和 _message_base.py 连接起来了。
_message_block.py 定义内容形态,_message_base.py 用 content 字段承载这些形态。
metadata:额外结构化信息,它和 content 的职责不同。
content 更偏消息正文。metadata 更偏附加状态、结构化输出或额外结果。
这样设计之后,Msg 不仅能表示“说了什么”,还能携带一些不直接作为正文展示的结构化信息。
id、timestamp、invocation_id:消息的可追踪性
Msg 还会带有 id、timestamp、invocation_id 这类字段。
这说明 Msg 不是临时传递的一段字符串,而是一个可追踪、可管理、可恢复的信息对象。
比如后面 Memory 删除消息时,就可以围绕 msg.id 进行精确管理。
05 Msg 不只是存数据
如果 Msg 只是把字段收在一起,那它只是一个普通数据类。
因为 content 可能是字符串,也可能是 block 列表,所以如果每个模块都自己判断内容类型,代码会非常混乱。
上层模块不需要关心 content 到底是字符串还是 block 列表,只需要通过这些方法获取文本内容、指定类型的 block,或者判断消息中是否包含某类 block。
比如 ReActAgent 中判断模型是否产生工具调用,就可以通过 has_content_blocks(“tool_use”) 来完成。
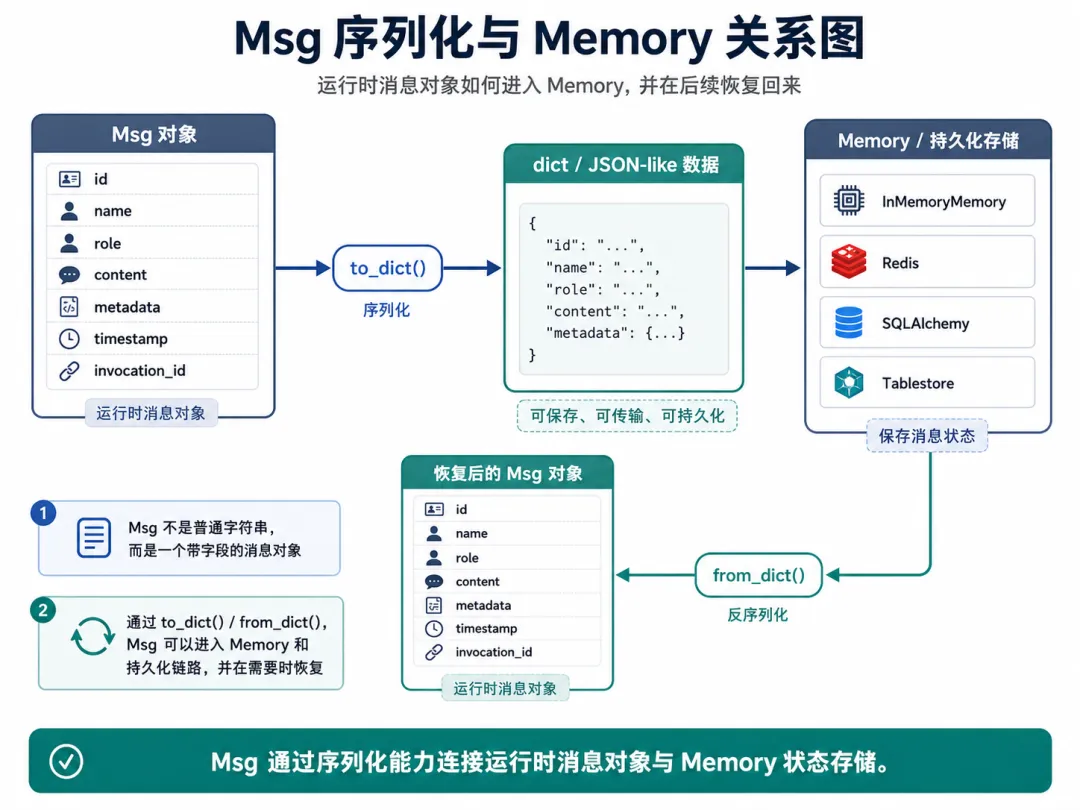
因为消息进入 AgentScope 主流程后,不只是运行时对象。
它还可能被 Memory 保存,被状态系统导出,被持久化到外部存储中,并在后续重新恢复出来。
如果 Msg 不能稳定地转成字典,再从字典恢复,就很难支持 Memory 和状态管理。
【图4:Msg 序列化与 Memory 关系图】图注:Msg 的序列化与恢复。消息对象通过 to_dict() 和 from_dict() 进入 Memory 和持久化链路。
它同时具备消息表达、内容访问、状态保存和恢复能力。
06 Msg 如何进入 AgentScope 主链路?
理解了 Msg 本身,再看 AgentScope 其他模块,就会更清楚。
在 AgentScope 中,很多核心模块都围绕 Msg 工作。
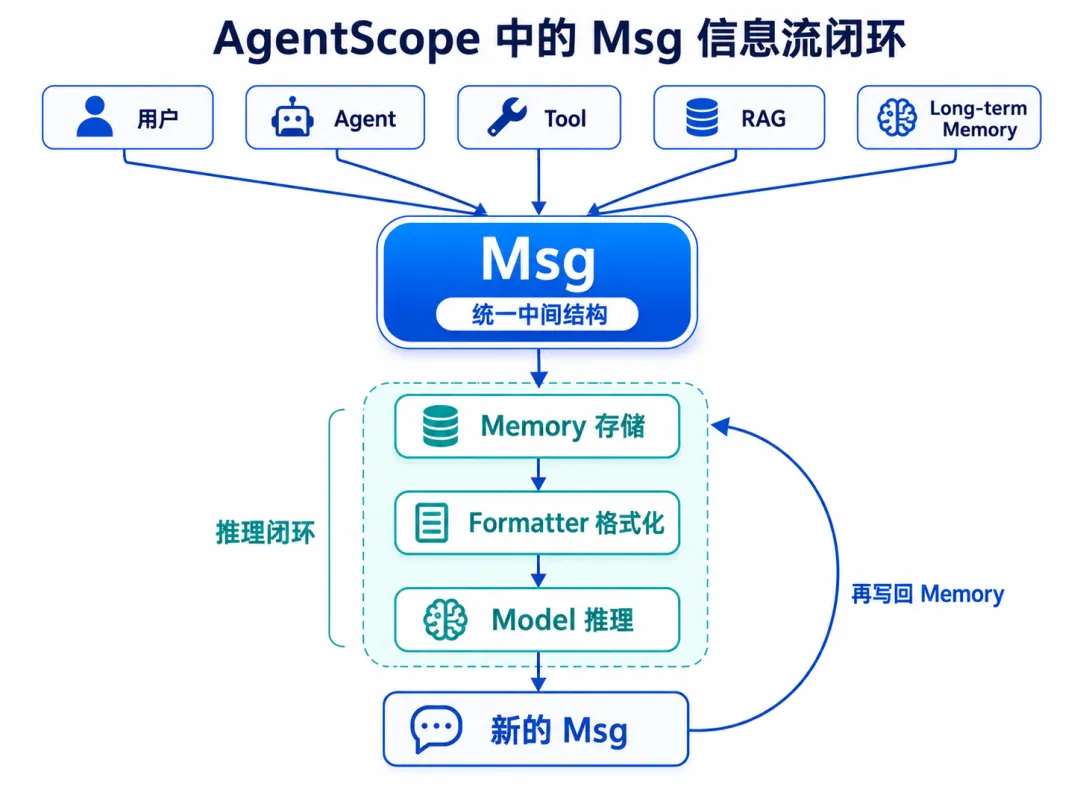
Formatter 负责读取 Msg,并转换成模型 API 需要的输入格式。
Tool、RAG、Long-term Memory 返回的信息,最终也可以被包装成 Msg,重新进入上下文。
它把来自不同来源的信息,统一成一种消息对象,然后再交给 Memory、Formatter、Model 和 Agent 处理。
【图5:Msg 进入 AgentScope 主链路图】图注:AgentScope 中围绕 Msg 展开的信息流闭环。Msg 连接 Memory、Formatter、Model 与后续生成过程。
这也是为什么我觉得 AgentScope 源码学习适合从 Msg 开始。
如果没有先理解 Msg,后面看 Agent 时会觉得很多地方只是在“传对象”。
但理解了 Msg 后,就能看清楚这个对象到底承载了什么信息,以及它为什么能在不同模块之间流动。
前者定义消息内容块,解决 content 里可以放什么。
后者定义消息对象,解决一条完整消息如何组织、访问、序列化和流转。
因此,AgentScope 的 Msg 不是简单的字符串封装,而是一种统一的消息表达与交换协议。
用 name、role、content、metadata、id 等字段表示一条完整消息。
通过 ContentBlock 支持文本、多模态、工具调用和工具结果。
通过 get_text_content()、get_content_blocks()、has_content_blocks() 屏蔽内容形态差异。
通过 to_dict() 和 from_dict() 支持 Memory、持久化和恢复。
所以,理解 AgentScope,确实很适合从 Msg 开始。
因为只有先搞清楚一条消息在框架里是如何被设计出来的,后面再看 Memory、Formatter、ReActAgent 和 Tool Calling,才会真正看到这套系统的信息流是如何被搭起来的。
 夜雨聆风
夜雨聆风