 夜雨聆风
夜雨聆风





AIOps探索:用OpenCode做智能运维助手
研究AIOps已有大半年,目前手里有不少可落地的方案了,接下来会把这些方案全部整理到我的大模型课程里。
阿铭,公众号:阿铭linux所有做运维的朋友注意了,今年一定要关注一下这个领域!
这周计划给同学们直播时讲讲OpenCode,所以这两天一直在用它,同时也尝试着用它做了一个智能运维助手,体验下来感觉它比Dify更加灵活和轻量。
既然你看到了这篇文章,我相信你对OpenCode并不陌生,没错它就是一个类似Claue Code、Codex CLI这样的AI编程工具。而OpenCode最大的特点是开源、终端体验感强、权限可控以及适合深度定制。
今天跟大家分享一个用OpenCode做智能运维助手的案例。
01 | 架构概览
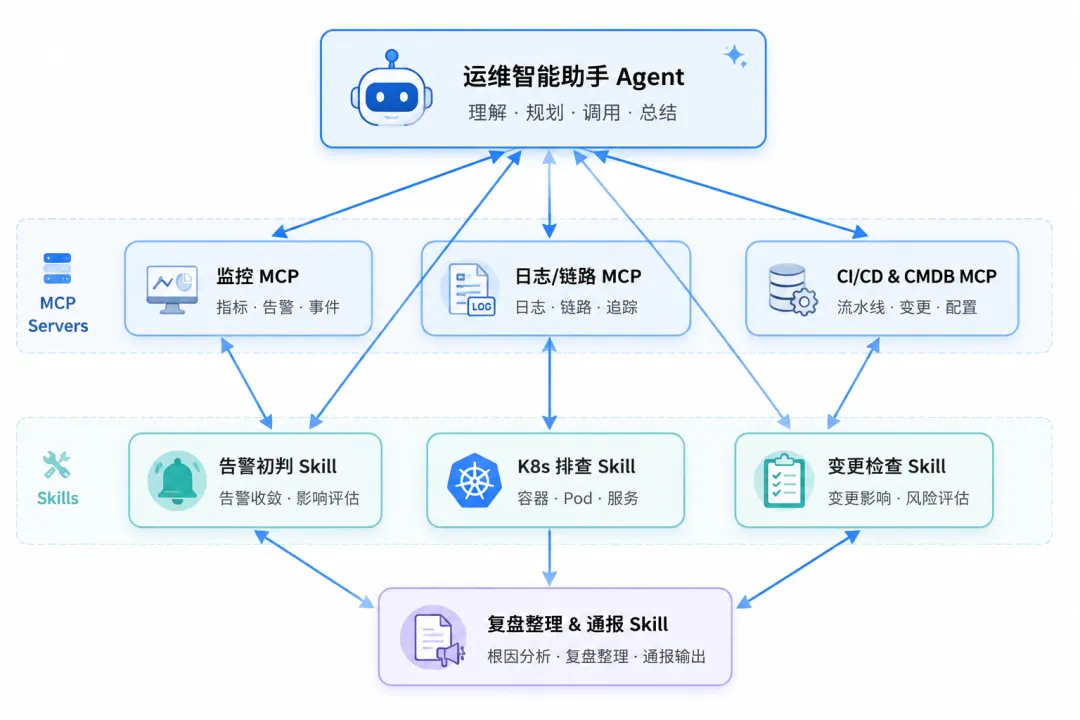
02 | 分层设计
1)交互层:一个能理解运维语言的Agent
用户入口可以是命令行、聊天窗口、值班群机器人,或者内部运维门户。这里的核心不是UI,而是让使用者可以直接说运维语言,比如:
-
“帮我看一下支付服务为什么5分钟内错误率飙升”
-
“对比一下这次故障前后发布记录和节点异常”
-
“按S1标准生成一个事故通报草稿”
-
“根据SOP给我一份回滚前检查项”
Agent负责理解意图、拆解任务、决定要调哪些MCP工具,以及是否需要加载某个skill。OpenCode的skills机制本身就是为这种“先发现可用skill,再按需加载”的流程设计的。
2)能力层:用MCP统一接入运维系统
这一层是整个方案能否落地的关键。常见会接入几类MCP Server:
-
监控与告警:Prometheus、Grafana、Alertmanager
-
日志与链路:ELK、Loki、Jaeger、Tempo
-
资源与环境:Kubernetes、云平台、CMDB
-
发布与变更:CI/CD、Git平台、制品平台
-
协同与记录:工单系统、知识库、群通知、事故复盘库
MCP的意义,不是替代这些系统,而是给agent一个统一访问入口。模型不必知道每个平台细节,只需要知道“有哪些工具可用、每个工具能做什么、什么时候应该调用”。
3)经验层:把运维经验写成Skills
如果没有skills,AI很容易变成“每次都临场发挥”。而运维最怕临场发挥,因为生产故障处理讲究的是一致性、可审计、可复盘。所以我们通常会把高频流程沉淀成skills,比如:
-
告警初判skill
-
Kubernetes故障排查skill
-
变更前检查skill
-
故障通报生成skill
-
事故复盘整理skill
-
发布回滚决策辅助skill
4)治理层:权限、审计与边界控制
这里是很多PoC容易忽略、但生产环境必须补齐的一层。因为一旦agent不只是“读”,还开始“写”或者“执行”,就必须明确:
-
哪些动作只允许查询,哪些动作允许执行
-
哪些操作必须人工确认
-
哪些结果必须记录审计日志
-
哪些系统只能在测试环境生效
-
哪些高危操作必须走审批链
MCP只是能力协议,不会自动帮你完成治理;Skills也只是流程封装,不会自动保证安全。真正落地时,必须在工具层和业务层同时加护栏。
03 | 智能助手工作流程
某晚21:40,支付网关服务触发高优先级告警:5分钟错误率从0.3%升到8.7%,部分核心接口RT同时升高。用OpenCode智能助手的过程是这样的:
第一步:值班同学发起自然语言请求
值班同学不需要先打开十几个页面,而是直接对智能运维助手说:
“帮我排查一下支付网关的高错误率,先判断是不是发布导致的,如果是,给出回滚建议;如果不是,继续看节点和依赖情况。”
这个请求本身就包含了一个很典型的运维流程:先做初判,再做归因,再给出建议。
第二步:Agent自动选择工具与Skill
此时agent不会只回答“可能是配置问题”。它会根据任务意图,先加载“告警初判skill”或“故障排查skill”,再调用多个MCP工具:
1)查询最近15分钟核心指标走势
2)查询最近1小时的发布记录
3)拉取异常Pod/节点状态
4)检查下游依赖调用失败率
5)汇总过去类似事故的处置经验
这正体现了MCP + skills的分工:MCP负责“查什么、调什么”,skill负责“先后顺序和判断框架”。
第三步:助手输出结构化结论,而不是一堆原始数据
优秀的智能运维助手,不是把十张图和二十条日志甩给你,而是先给结论框架:
-
现象:支付网关21:38后错误率快速上升,主要集中在
/createOrder接口 -
初步判断:与21:31的灰度发布时间窗口高度重合
-
证据:
-
新版本Pod错误率显著高于旧版本
-
节点层面无明显资源争用
-
下游库存服务RT有波动,但未达到主因级别
-
建议:
-
立即暂停灰度扩大
-
保留1个异常实例做诊断
-
将其余新版本实例回滚
-
同步值班群发布一级故障通报草稿
这里的关键不是“AI 会总结”,而是它能按skill里定义的SOP,把多源数据组织成适合决策的输出。
第四步:进入半自动执行阶段
如果团队治理成熟,可以再往前走一步。比如对于低风险动作,agent可以在确认后自动执行:
-
暂停发布流水线
-
触发指定服务回滚
-
拉起标准通知模板
-
自动生成事故单草稿
-
整理本次排障过程为复盘初稿
但这里一定要强调:自动化不等于全自动。在运维场景里,更合理的方式通常是“AI 辅助决策 + 人工确认执行”,尤其是涉及生产回滚、扩缩容、熔断、切流这类高风险动作时。
04 | 智能助手落地思路
1)环境准备
-
安装OpenCode(终端/IDE/桌面版均可)
-
配置LLM API
-
配置本地或远程MCP Server接入权限
2)MCP接入
根据运维需求,至少接入以下MCP Server:
-
监控:Prometheus / Grafana MCP Server
-
日志:ELK 或 Loki MCP Server
-
链路追踪:Jaeger / Tempo MCP Server
-
容器/资源管理:Kubernetes MCP Server
-
发布流水线:CI/CD MCP Server(Jenkins / GitLab)
-
资产与配置:CMDB MCP Server
-
协同/工单:工单系统 MCP Server(Jira / ServiceNow)
MCP Server的作用是把外部系统功能统一标准化,让agent可以通过统一接口调用。
3)Skills配置(推荐模块)
-
告警初判Skill:根据告警类型自动汇总关键指标和日志
-
Kubernetes排查 Skill:查询 Pod、节点状态、事件和依赖服务
-
变更检查Skill:检查发布版本、发布记录、变更审批状态
-
复盘整理Skill:根据故障数据生成事故复盘初稿
-
通报生成Skill:生成事故通报和内部通知草稿
Skills用SKILL.md 定义,每个Skill尽量聚焦单一职责、包含触发条件、操作步骤、输出格式。
4)Agent配置
-
创建运维智能助手Agent
-
加载已安装MCP Servers和 Skills
-
设置权限策略(只读 / 建议 / 执行分层)
-
配置对话入口(命令行、Web控制台或聊天机器人)
我的运维大模型课上线了,目前还有很大优惠。友情提醒:AI红利剩余时间真的不多了,千万不要错过!AI越来越成熟了,大模型技术需求量也越来越多了,至少我觉得这个方向要比传统的后端开发、前端开发、测试、运维等方向的机会更多!
扫码咨询优惠(粉丝优惠力度大)
