1.6 万次下载的公众号爬虫 Skill,我实测后只想提醒一句:别把归档当洗稿
今天测的这个 Skill,叫 wechat-article-spider。
它在 SkillHub 上的中文名是:微信公众号文章爬虫。
将微信公众号文章转换为 Markdown + 本地图片。
从功能上看,它不是一个写作工具,也不是一个排版工具。
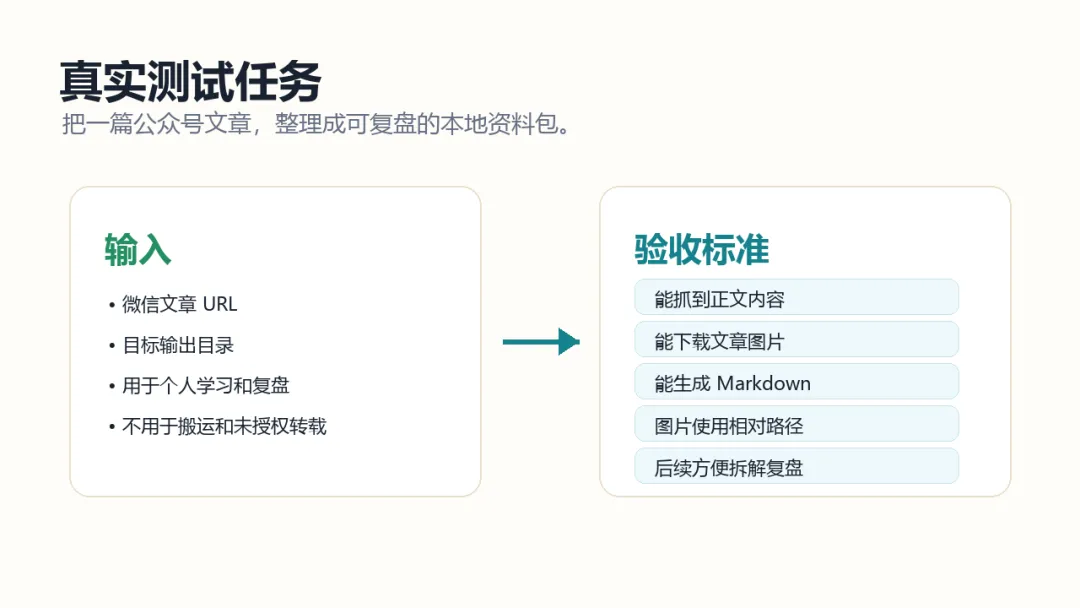
当你看到一篇公众号文章,想把它整理成可保存、可检索、可复盘的资料时,它能把网页内容抓下来,生成 Markdown 文件,并把文章里的图片下载到本地 images/ 文件夹。
所以这篇测评,我不会把它写成“公众号爆文一键搬运神器”。
01 这个 Skill 的基本信息
从 SkillHub API 抓到的信息看,wechat-article-spider 的基础数据是:
安全检测:科恩实验室、云鼎实验室均显示安全、无风险
标签:requires_api_key = false
核心说明在 SKILL.md,脚本在 scripts/ 目录下,包括:
requests、beautifulsoup4、lxml。
这意味着它不是依赖外部大模型 API 的技能,而更像一个传统爬虫脚本被包装成 Skill。
因为它的价值不在“智能生成”,而在“把网页资料结构化保存”。
02 我给它的真实测试任务
比如你看到一篇很值得学习的文章,里面有标题、正文、配图、案例、金句、结构。
03 我按 5 步做测评
pip install -r requirements.txt
https://mp.weixin.qq.com/s/xxxxx
python main.py <文章 URL> [输出目录]
因为微信文章可能有反爬机制,部分动态加载图片可能抓不到,段落格式也可能需要后期整理。
04 它做得好的地方
我认为 wechat-article-spider 最大的价值,是降低内容复盘的门槛。
很多人做内容学习,最大的问题不是看得少,而是看完不沉淀。
这个 Skill 的价值,就是把一篇在线文章变成一个本地资料包:
对于做公众号、课程、选题研究、竞品分析的人来说,这个动作很实用。
它是帮你把别人文章里的结构、案例、表达方式保存下来,方便后续学习和复盘。
05 它的边界也很明显
这个 Skill 最大的边界,不是技术,而是使用方式。
SKILL.md 里提醒:微信文章可能有反爬机制,失败时可稍后重试;部分动态加载图片可能无法获取。
它更适合做日常内容资料整理,而不是高强度批量采集。
06 我的评分
这次我给 wechat-article-spider 的综合评价是:适合内容工作者做公众号文章归档的实用型 Skill。
07 我会怎么用它
把文章结构拆成标题、开头、案例、金句、转折、结尾。
wechat-article-spider 值得放进内容工作者的工具箱。
它真正有价值的地方,是把公众号文章变成可保存、可检索、可复盘的学习资料。
 夜雨聆风
夜雨聆风