夜雨聆风
夜雨聆风





让 OpenClaw 或 Hermes 自己给自己加一个新模型
让 OpenClaw 或 Hermes 自己给自己加一个新模型
*加模型不该是你背字段,而应该是 Agent 读文档、接线、验证,最后把新通道插进系统里。*
前两篇,一篇讲认知,一篇拿 Telegram 做了个案例。这一篇收尾,换个更能说明问题的场景:
给一个 Agent,加一个它自己要用的新大模型。
为什么说这个场景”更能说明问题”?因为接 Telegram,多少还有个直观画面——发消息嘛,谁都懂。但”加一个模型渠道”,对绝大多数人是纯抽象的。base_url 是啥,provider 是啥,model 那个名字为什么这么长,API key 又该塞哪——每一个都是劝退点。
恰恰是这种”我完全不懂里面是啥”的场景,最能照出新老两条路的区别。
先说老路子有多劝退
模型这东西,更新太快了。这个月还在用的,下个月可能就有个更便宜更快的出来。于是你想给你的工具换一个、加一个。
老路子大概是这样:
你先去翻你工具的配置,找到放模型的那一坨。你照着已有的那个,复制一份。然后开始对着新模型供应商的文档,一个字段一个字段改:接口地址改成它的,模型名字改成它那个长长的字符串,还得判断它是”跟 OpenAI 那套兼容的”还是”自己一套的”——这俩配法不一样。改完,API key 往哪儿塞又是个问题,塞错地方要么不生效,要么更糟,塞进了会被记到日志里的地方。
最后你重启,发个请求。报错。报错信息还特别不友好,就一句”鉴权失败”或者”模型不存在”。到底是 key 错了、地址错了、还是模型名多了个空格?你不知道。你回去一行行对,对到怀疑人生。
我形容得这么细,是因为这条路我亲自走废过好几次。每一次都觉得,这活儿里没有一步是”我”非干不可的,但每一步又都得我干。
新路子:我连那些字段叫什么都不用知道
换成现在,我说的是这么一句:
“我想给你加一个新模型,是某某家的某某模型。你先去看它的官方文档,搞清楚接口怎么调、模型名叫什么、key 怎么传,确认是不是 OpenAI 那套兼容的。配好之后,用一个最小的请求验证它真能通,通了再告诉我。key 我单独发你,别写进任何会被看到的地方。”
这句话里,我没有说出任何一个具体字段。我没说 base_url 填什么,没说 model 填什么,没说 provider 类型选哪个。
因为这些本来就不该我来记。这些是会变的细节,是该去查的东西,不是该背的东西。
它干的第一件事,还是读文档
跟接 Telegram 一样,它没有凭记忆开干。它先去读那个模型供应商的官方文档。
它要从文档里确认几件事:接口地址是什么,模型的准确名字是什么(这个字符串经常带版本号、带日期,记错一个字符就不通),鉴权怎么传,以及最关键的——这家是不是”OpenAI 兼容”的。
“OpenAI 兼容”这个词你不用懂,但它对 Agent 很关键。很多模型供应商会说自己的接口”跟 OpenAI 那套一样”,这意味着配置方式可以套现成的模板;如果不是,就得按这家自己的方式来。这个判断,是它读文档时自己做的,不需要我参与。
很多供应商的文档里会直接写明这点。下面这张是一个典型例子的位置。
*Agent 读的就是文档里这种位置:接口地址、鉴权头、模型名。它从这里判断该套哪个配置模板,而不是问我。*
它读完会用人话跟我确认一句,类似:”这家是 OpenAI 兼容的,模型名我从文档里抄的是这个长串,我准备这么配,你没异议我就落下去了。” 我看一眼模型名对不对得上我想要的那个,说继续。
API key:这篇里最该被认真对待的一段
加模型这件事,最敏感的不是配置,是那把 key。
一个 API key,基本等于一张可以花你钱的卡。它要是泄露了,别人能拿你的额度狂跑,账单算你头上。所以这一段我要讲重一点。
我做的是:key 单独发给它,并且明确说了”别写进任何会被看到的地方”。
它做的是:key 没有出现在它后面任何一句回复里。没有出现在它写进配置文件的明文里——它放进了更安全的存储,配置里只留一个指过去的引用。没有出现在日志里——这点尤其重要,因为日志最容易被忽略,很多泄露就是 key 被顺手记进了某行日志,然后日志又被发出去了。
我事后专门检查了这几处:它的回复、它写的配置、相关的日志。三个地方都没有那把 key 的明文。这篇文章里你同样不会看到任何真 key,下面所有示意都是占位符。
我把这段单拎出来,是想让你记住一个判断标准:一个 Agent 处理密钥的方式,比它配置跑没跑通更能说明它靠不靠谱。 跑不通可以查可以改,key 泄了,是真金白银的事,而且往往你都不知道它泄在哪了。
配置落地大概是这个意思(示意,key 是占位符,别照抄):
# 示意:真实字段名以该供应商和你的工具文档为准
model_providers:
new_provider:
type: openai_compatible # 它读文档后自己判断的
base_url: "<官方文档里的接口地址>"
model: "<官方文档里那个精确的模型名>"
api_key_ref: "<指向安全存储的引用,不是 key 本身>"
你看 api_key_ref 那行。配置文件里躺着的是一个”引用”,真正的 key 在别处更安全地待着。这个区别,就是”会出事”和”不会出事”的区别。
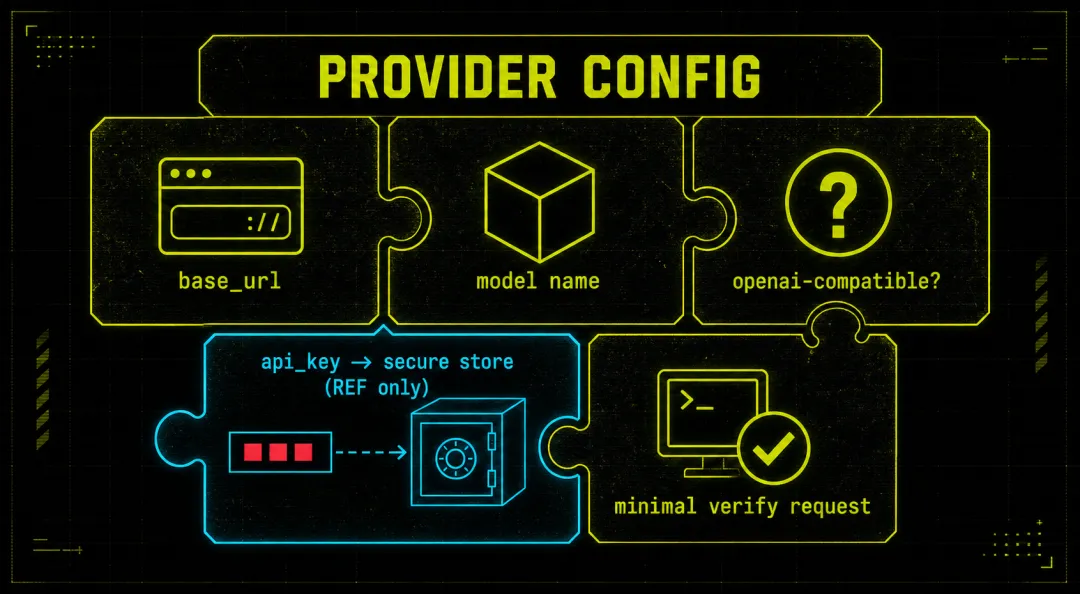
*配置不是玄学,它就是几块拼图;最敏感的那块,永远应该是安全引用,而不是明文 key。*
然后它会失败一次——这才是重点
我必须讲这一段,因为不讲,这篇就又成了一个一切顺利的童话,那是骗你。
它配完,发了第一个最小验证请求。失败了。
不是它笨。加模型这事,第一次就通的概率本来就不高——文档某处有歧义、模型名带了个不显眼的后缀、鉴权头的格式有个小讲究,太常见了。
区别在于失败之后谁来收拾。
老路子里,失败之后是你对着一句没头没脑的报错抓瞎。新路子里,它自己去看日志了。它把那次失败请求对应的日志翻出来,看到具体的错(比如是模型名不被识别,还是鉴权没过),定位到是哪个字段的问题,改掉,再发一次最小请求。
它跟我同步的是这种话:”第一次没通,日志里看是模型名的问题,文档里那个名字带了个版本后缀我漏了,已经修正,重试。” 第二次,通了。它发来一句模型正常返回的最小结果作为证据。
我全程做了什么?我看着它说”失败—查日志—改—重试—通了”,然后说了句”好”。
这一段是这整个系列里我最想让你记住的画面。真正能用的自动化,不是”一次就成”,是”它自己有能力从失败里爬出来”。 一个只会在顺利时干活、一遇到报错就把烂摊子甩回给你的东西,不算帮你干完了活。能查日志、能改、能重试到通,这才算。
*真正可靠的自动化,不是保证不失败,而是失败后能自己查日志、修正、重试,直到给出通过证据。*
*它做最小验证,靠的就是文档里这种最简单的调用示例——用最小的代价确认这条路真的通。*
那我还需要懂什么?
复盘一下,从头到尾我亲手做、亲脑判断的,只有:
一,说清楚我要加哪家的哪个模型。 二,把 key 单独、私下发给它,并划清”别写进任何会被看到的地方”这条线。 三,它确认配置前,瞄一眼模型名对不对得上我要的那个。 四,看它报”通了”那个证据,确认成了。
base_url 填什么、是不是 OpenAI 兼容、模型名那串精确字符、key 在配置里该用引用还是明文、失败了去翻哪个日志——这些我一个都没碰,也不需要懂。
但请注意第二条。我不需要懂技术细节,可我必须懂”key 不能乱跑”这条边界。这就引出整个系列我想收束到的那句话。
三篇说到底,就一句话
第一篇我说,别让 AI 教你点按钮,让它直接把工具装好。 第二篇我用 Telegram 演了一遍,Agent 在你那句话之后到底替你跑了多少活。 这一篇我用加模型说明,你越是不懂里面那些字段,反而越说明这活就不该你干——但有几个地方,你必须懂得停。
把这三篇压成一句,是这样:
会清楚地说出你想要什么、并且知道该在哪儿喊停,比会熟练地操作界面,重要得多。
界面那套关卡,会越来越多地被那个本来就不需要界面的家伙拆掉。你真正要练的,不是手更快,是话更清楚、边界更明白:我要什么、哪里要花钱、哪里碰了我的账号、哪里删了就回不来、哪把钥匙绝对不能乱跑。
把这几样想明白,剩下的,交给它。
我是海海。这个「AI Agent 自动安装和配置工具」系列三篇到这儿就完整了。如果你想让 Hermes 或 OpenClaw 自己读文档、自己加模型、自己跑验证,而不是你对着字段熬夜,欢迎加我个人微信聊,备注「模型」或「Agent」。