 夜雨聆风
夜雨聆风





一篇 OpenClaw 多 Agent 协作完整教程,从任务台账到守夜人监控,把「开工了」变成「能交付」

事情是这样的。
我最近一直在折腾 OpenClaw 的多 Agent 协作。
一开始想得挺美。
一个 Leader 负责理解需求和拆任务,一个 Agent 查资料,一个 Agent 做结构,一个 Agent 写初稿,一个 Agent 审稿,还有一个 Agent 盯着任务别断线。
听起来是不是很像一个小型内容工作室?
你把需求丢进去,它们自己分工、自己推进、自己交付。你泡杯水回来,文章、图片、审稿意见、发布包,一整套东西都摆在那里。
想想就挺爽。
但真跑起来之后,我发现最容易出问题的地方,根本不是 Agent 不够聪明。
而是你不知道它们现在到底在干嘛。
哪个任务已经完成了?
哪个任务卡住了?
哪个任务嘴上说 done,其实文件根本不存在?
哪个 Agent 已经停了,但台账还显示 running?
哪个任务其实在等你确认,但没人把它标成 waiting?
这种感觉非常熟悉。
不是失败。
是看起来还在工作。
这才吓人。
很多 Agent Team 跑一半停住,不是因为模型能力不行,也不是因为 Prompt 不够长,而是因为它没有一套像团队一样工作的秩序。
我后来越来越确定一件事。
多智能体真正难的,从来不是让几个 Agent 同时开工。
真正难的是,让每个任务可见、可追踪、可验收、可恢复。
也就是今天这篇文章想讲的东西,任务监控机制。
你以为自己组了一个团队,其实只是开了几个聊天窗口
很多人第一次玩 Agent Team,脑子里都会有一个很爽的画面。
我把需求丢给 Leader。
Leader 自动理解目标,自动拆任务,自动派人,自动收结果,最后啪一下,给我一个成品。
听起来像一个永不疲惫的小公司。
但现实通常没这么丝滑。
因为真实任务不是一问一答。
它有上下游,有中间产物,有卡点,有返工,有「看起来完成了,其实还没验收」的灰色地带。
比如写一篇技术文章。
它不是「写正文」这么简单。
前面要定角度、查资料、筛事实、设计读者路径。
中间要写稿、做图、调结构、统一口吻。
后面还要审风险、查敏感信息、确认图片能不能用、准备发布格式。
如果只有一个 Agent,它当然也能做。
但它很容易一路从 Leader 变成研究员,再变成作者,再变成审稿人,最后还顺手当发布助理。
看起来很勤奋。
实际上风险非常大。
因为一个角色既负责执行,又负责验收,又负责宣布自己可以交付,这事儿放在人类团队里都离谱,放到 Agent Team 里也一样离谱。
多 Agent 的价值,不是给一个模型换几套人格皮肤。
它真正有用的地方,是把复杂任务拆成边界清楚的工作单元。
有人负责找资料。
有人负责生产产物。
有人负责独立审查。
有人负责盯状态。
有人负责最后收口。
这才叫团队。
不然只是几个聊天窗口一起热闹。
第一个大坑,Leader 变成全能老妈子
Agent Team 里最常见的错误架构,是所有事情都指向 Leader。
用户把需求给 Leader。
Leader 拆任务。
子 Agent 做一点东西,结果也都回给 Leader。
任务卡住了,Leader 处理。
资料缺了,Leader 补。
图没出来,Leader 重新做。
审稿没完成,Leader 自己审。
最后整个系统看起来有很多 Agent,其实只有 Leader 一个真正忙到冒烟。
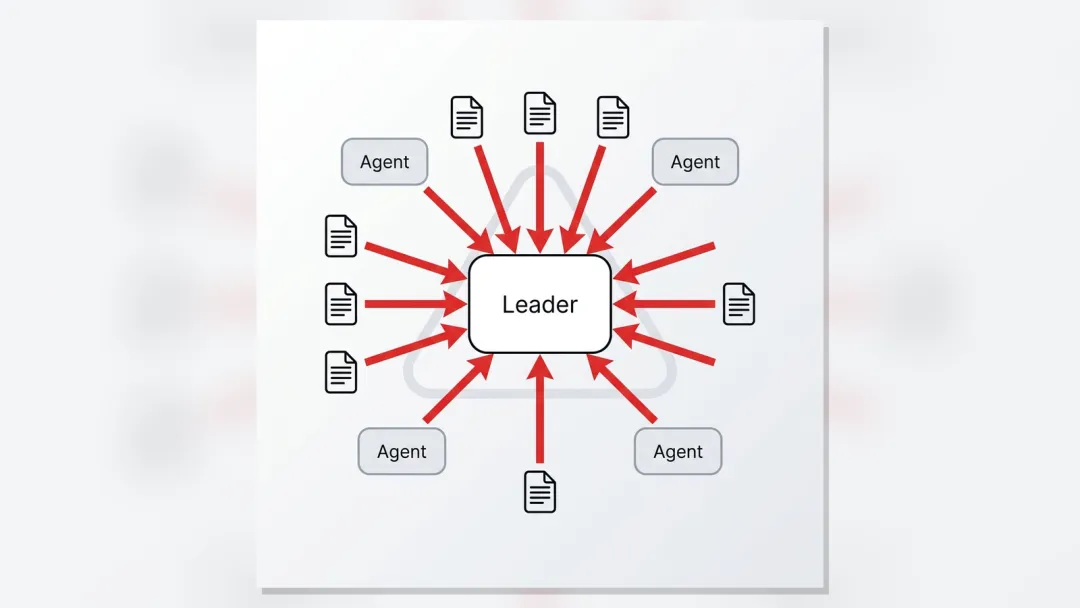
这个架构最大的问题,不是慢。
慢只是表象。
真正的问题是,Leader 成了所有信息、状态、产物和异常的唯一入口。
只要 Leader 没看到,任务就等于不存在。
只要 Leader 忘了查,卡点就会一直卡在那里。
只要 Leader 误信了一个 done,假完成就会直接混进最终交付。
这就不是团队协作了。
这是 Leader 代劳。
我以前也踩过这个坑。
刚开始特别容易兴奋,觉得终于可以派活了,于是一个任务拆出去三四条线。结果回收的时候才发现,每条线都要自己追,每个产物都要自己找,每个异常都要自己判断。
最后 Agent 是多了,Leader 的脑负担反而更重。
这就很尴尬。
你本来是想搭一个团队,结果搭出一个更复杂的单点瓶颈。
所以第一个判断很重要。
Leader 不应该常规代劳所有任务。
Leader 该做的是拆解、调度、验收、收口。
真正的执行、审查、监控,要从 Leader 身上拆出去。
正确结构不是人多,而是边界清楚
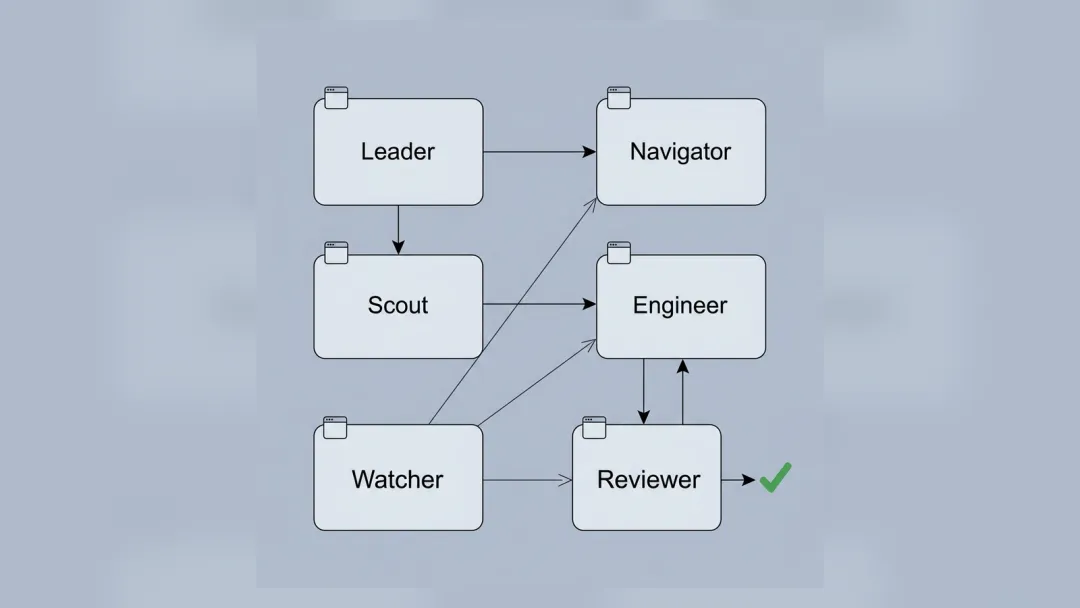
我现在更愿意把一个最小可用 Agent Team 拆成五个抽象角色。
Leader,负责理解目标、拆任务、派发、收口。
侦察员,负责资料、事实、证据链和不确定项。
工程师,负责脚本、文件、自动化、图片、产物生成。
审稿人,负责独立验收,判断 PASS、REWORK、FAIL,必要时升级给人。
守夜人,负责定期巡检任务台账、产物、状态漂移和恢复动作。
这里的名字不重要。
你叫它研究员、执行员、Reviewer、Watcher 都行。
重要的是边界。
谁负责做,谁负责审,谁负责盯,谁负责最后拍板。
这些要分开。
OpenClaw 的好处,是它天然适合把这些角色组织起来。
你可以给不同 Agent 设定不同职责,用独立 workspace 减少文件污染,用 session 保留任务现场,用 cron 做周期性检查,用 skills 固化高频工序。
但这里有个容易误会的点。
OpenClaw 给的是协作的可能性,不是自动替你设计协作机制。
你能派活,不等于你会协作。
你能开多个 Agent,不等于它们天然知道怎么交接。
中间差的,就是一套任务台账和监控机制。
这个东西一点都不玄学。
甚至可以很土。
一个 Markdown 文件就能开始。
任务台账,别让任务只活在聊天记录里
我后来越来越讨厌一种状态。
任务进度只存在于聊天记录里。
因为聊天记录是流。
当时看着很清楚,过一会儿就被冲走了。
你想知道某个子任务到底完成没,就只能往回翻。
翻着翻着,你会开始怀疑人生。
到底哪一句是最终结论?
哪个文件才是最新版本?
这个 Agent 说完成了,它输出到哪里了?
另一个 Agent 说有风险,风险处理了吗?
这时候你就需要一个账本。
也就是 ledger,任务台账。
任务台账不需要一开始就很复杂。
最小版本只要记录几件事。
任务 ID。
任务目标。
负责人。
状态。
输出文件。
最后更新时间。
下一步动作。
阻塞原因。
验收标准。
也就是这些。
# Task: <title>
- Task ID: <task-id>
- Owner: Leader
- Status: running
- Updated: <time>
- User Goal: <original goal>
## Acceptance Criteria
- [ ] 产物文件存在且非空
- [ ] 覆盖用户目标
- [ ] 没有敏感信息
- [ ] 已经过独立审稿
## Subtasks
| ID | Role | Status | Output | Last Update | Next Action | Blocker |
| --- | --- | --- | --- | --- | --- | --- |
| S1 | Scout | running | artifacts/research.md | 09:20 | 等资料底稿 | - |
| S2 | Engineer | blocked | artifacts/chart.png | 09:18 | 重试生成图 | 图片文字异常 |
| S3 | Reviewer | queued | artifacts/review.md | - | 等初稿 | - |
## Monitor
- interval: 10m
- staleThreshold: 20m
- checkObjects: ledger, sessions, deliverables, blockers
- recoveryStrategy: update ledger -> inspect -> retry/split/fallback -> waiting/failed
- exitCondition: accepted or failed, then close monitor
你看,它并不高级。
但它非常救命。
因为从这一刻开始,任务状态不再靠 Leader 的记忆。
它被写进了一个所有角色都能对账的地方。
这件事对 Agent Team 特别关键。
人类团队里,大家可以在群里追一句,谁那边怎么样了。
Agent Team 不一样。
它可能在不同 session 里工作,可能在不同 workspace 里写文件,可能半小时后才回来,可能中间被模型配额、权限、外部服务卡住。
如果没有台账,Leader 很容易变成一个拿着手电到处找文件的人。
找着找着还要安慰自己,应该快好了吧。
朋友们,别这样。
把状态写到账本里。
别让它活在聊天记录里。
done 不等于 accepted
这里我想单独讲一句特别重要的话。
执行者说 done,不等于任务可以交付。
done 只代表执行者认为自己完成了。
accepted 才代表验收机制认为它可以交付。
这两者必须分开。
很多多 Agent 协作翻车,就翻在这里。
一个子 Agent 说,资料底稿已完成。
Leader 很开心,拿来就用。
结果一看,文件路径写错了。
或者文件是空的。
或者内容写了很多,但没有覆盖验收标准。
或者引用了不能公开讲的内部细节。
或者图生成出来了,但里面混进了莫名其妙的英文乱码。
这些都属于 false done。
假完成。
最危险的地方在于,它看起来很像完成。
状态是绿的。
语气是肯定的。
甚至还会说「已完成基础验证」。
但你只要真正打开产物,就会发现,交付还差一截。
所以我建议,Agent Team 里一定要把执行完成和交付完成拆开。
子 Agent 可以标 done。
审稿人要输出 PASS、REWORK、FAIL 或 ESCALATE。
Leader 最后再根据验收结果,把主任务标成 done 或 accepted。
不要让做事的人自己给自己盖章。
这不是不信任 Agent。
这是基本工程纪律。
Prompt 是说明书,不是监控系统
还有一个坑,我自己也踩过。
一旦 Agent 跑偏,第一反应就是加 Prompt。
写更细的角色说明。
加更严格的输出格式。
把步骤拆得更碎。
甚至给它写一大段「你必须认真负责,不能偷懒,不能遗漏」。
这当然有用。
Prompt 写不清楚,任务肯定容易跑偏。
但 Prompt 只能解决出发前讲清楚。
它解决不了路上有没有走丢。
你可以在 Prompt 里要求 Agent 完成后写文件。
但如果它失败了呢?
你可以要求它更新状态。
但如果它忘了呢?
你可以让 Leader 等待所有结果。
但如果某个结果永远不回来呢?
你可以要求图片不能有乱码。
但如果图片生成工具真的生成了乱码呢?
靠一句 Prompt 祈祷它自觉,不是工程化。
这更像在工地门口贴一张纸,写着「请大家安全施工」。
不是没用。
但你不能指望它替代安全员、巡检表和验收流程。
Prompt 是说明书。
监控系统才是现场管理。
守夜人不是将军,它只是定时看一眼
任务台账解决了一个问题,状态有地方写。
但还有另一个问题。
谁来看?
这就是守夜人的价值。
守夜人不需要特别聪明。
它甚至可以很笨。
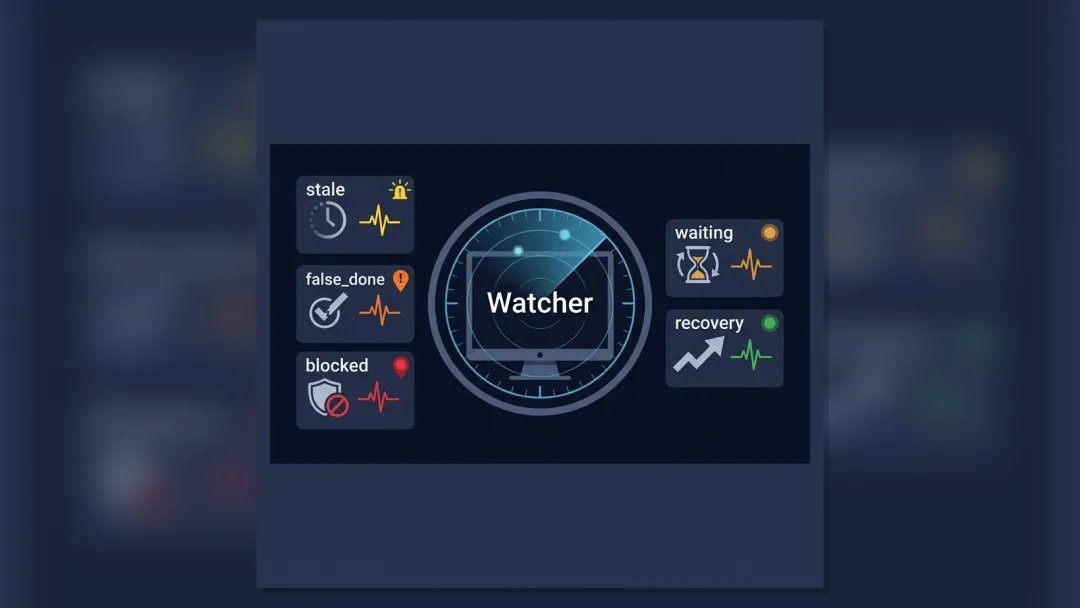
它只需要稳定地问几个问题。
这个任务 running 太久了吗?
这个任务 done 了,但产物存在吗?
这个文件存在,但是不是空的?
这个 blocked 有没有写 blocker?
这个 waiting 写清楚在等什么了吗?
这个子任务结束了,台账更新了吗?
这个主任务已经完成了,临时 monitor 关掉了吗?
守夜人不是将军。
它不负责打仗。
它就是晚上提着手电巡一圈,看谁的灯灭了,谁的门没关,谁卡在仓库里没出来。
但恰恰是这个角色,让系统从「靠运气完成」变成「有机会被救回来」。
在 OpenClaw 里,这件事可以用 cron 做。
cron 本质上像一个闹钟。
每隔一段时间,它唤醒一个监控任务,让它检查台账、session、产物目录、阻塞项和验收状态。
如果发现 stale,就标出来。
如果发现 false_done,就退回 review 或 revise。
如果发现 blocked,就写清 blocker,并尝试恢复。
如果发现 waiting,就确认等待条件是否还成立。
如果发现所有验收项都完成了,就把任务收口,并关闭自己。
这句话也很重要。
监控任务必须会退出。
不然你只是把一个长任务变成了另一个永远空转的长任务。
blocked 和 waiting 要分清楚
我以前经常把这两个状态混着用。
后来发现不行。
blocked 和 waiting 不是一回事。
blocked 是这里坏了,需要处理。
比如脚本失败了。
图片生成异常了。
子任务没有产物。
输出格式不符合要求。
审稿发现敏感信息。
waiting 是这里缺外部条件,需要等待。
比如需要用户确认。
需要权限。
需要模型配额恢复。
需要第三方服务响应。
需要某个人给材料。
这两个状态如果混了,系统就不知道该恢复还是该等。
blocked 应该触发诊断和恢复。
waiting 应该写清楚等待条件。
比如,等待用户确认是否发布。
比如,等待图片人工验图通过。
比如,等待外部 API 配额恢复。
不要把所有没动静的任务都叫 blocked。
也不要把真正坏掉的任务伪装成 waiting。
这会让监控系统变成一个很礼貌但没用的看板。
一个最小可用 OpenClaw Agent Team,我会这样搭
说了这么多,落到实操,我会怎么搭?
不用一上来搞很重。
最小版本就六步。
第一步,先选一个稳定任务。
不要一上来让 Agent Team 做一个边界极其模糊的大项目。
先选技术文章、资料调研、小型代码改动、日报生成、发布前检查这类重复性强、产物明确的任务。
第二步,定义角色边界。
Leader 负责拆解和收口。
侦察员负责资料和证据。
工程师负责产物和工具执行。
审稿人负责验收。
守夜人负责监控。
每个角色都写清楚负责什么,不负责什么,输入是什么,输出是什么,什么时候必须升级。
第三步,固定目录和产物路径。
不用暴露真实机器路径,抽象成这样就够。
team/
tasks/<task-id>.md
artifacts/<task-id>/
research.md
draft.md
review.md
final.md
agents/
leader/
scout/
engineer/
reviewer/
重点不是目录长什么样。
重点是公共产物要有固定位置。
Leader 汇总前,必须按产物路径去读,而不是凭印象说「好像完成了」。
第四步,先写任务台账,再派活。
这一步特别反直觉。
很多人是先派 Agent,然后看结果。
我现在建议反过来。
先写 ledger。
把任务目标、验收标准、子任务、输出路径、状态、monitor 信息写进去。
然后再派活。
因为这样每个子 Agent 接到的不是一句模糊的「你去做一下」,而是一张任务卡。
它知道自己属于哪个总任务,输出到哪里,完成标准是什么,遇到问题该标 blocked 还是 waiting。
这一张子任务卡,我建议直接复制。
# 子任务卡
## 背景
这是任务 <task-id> 的一部分,当前目标是 <一句话说明>。
## 你负责什么
- <职责 1>
- <职责 2>
## 你不负责什么
- 不做最终发布
- 不修改其他角色产物
- 不替审稿人宣布 accepted
## 输入材料
- <上游文件或链接>
## 输出要求
- 输出路径:artifacts/<task-id>/<name>.md
- 输出格式:Markdown
- 必须包含:结论、依据、不确定项、下一步建议
## 验收标准
- 文件存在且非空
- 覆盖指定主题
- 没有敏感信息
- 不确定项明确标注
## 状态规则
开始执行标 running。
缺用户确认、权限、配额、外部材料时标 waiting,并写清等待条件。
遇到错误、缺产物、输出不合格时标 blocked,并写清 blocker。
完成执行只能标 done,不能自己标 accepted。
这张卡看着有点啰嗦。
但它解决的是一个特别实际的问题。
不要让子 Agent 猜自己要干什么。
也不要让 Leader 事后猜它到底干了什么。
第五步,给每个长任务配一个临时守夜人。
注意,是临时。
这个守夜人只盯当前任务。
它每隔一段时间检查一次。
发现异常先更新 ledger,再恢复。
恢复动作可以很克制。
先看文件有没有。
再看子任务有没有回传。
再判断要不要重试、拆分、转人工、降级方案。
不要一发现问题就装作看不见。
也不要一发现问题就重新开十个 Agent。
先把账对清楚。
第六步,收尾时做最终验收。
最终验收至少看四件事。
验收标准是不是都满足。
产物是不是都存在并且是最新的。
审稿意见是不是处理了。
临时 monitor 是不是关闭了。
最后这条很容易被忽略。
但如果你讲任务监控,最后自己留一堆监控空转,那就有点像写了一篇节能文章,结果办公室灯开了一夜。
不太体面。
别一上来把系统搭得太复杂
我知道,有些朋友看到这里可能已经开始兴奋了。
状态机、看板、监控、恢复、审稿、目录、角色、cron,全安排上。
先别急。
多 Agent 系统有一个很微妙的坑。
你为了防混乱,设计了一套更复杂的系统。
然后这套系统本身变成了新的混乱来源。
这事儿太常见了。
一上来字段太多,Agent 根本不更新。
状态设计太细,最后没人看。
只盯最终输出,不看中间产物。
守夜人只会报错,不会给下一步。
Leader 只看子 Agent 的完成宣言,不打开文件验收。
这些都会让系统变成一种漂亮的自我感动。
所以我建议最小化。
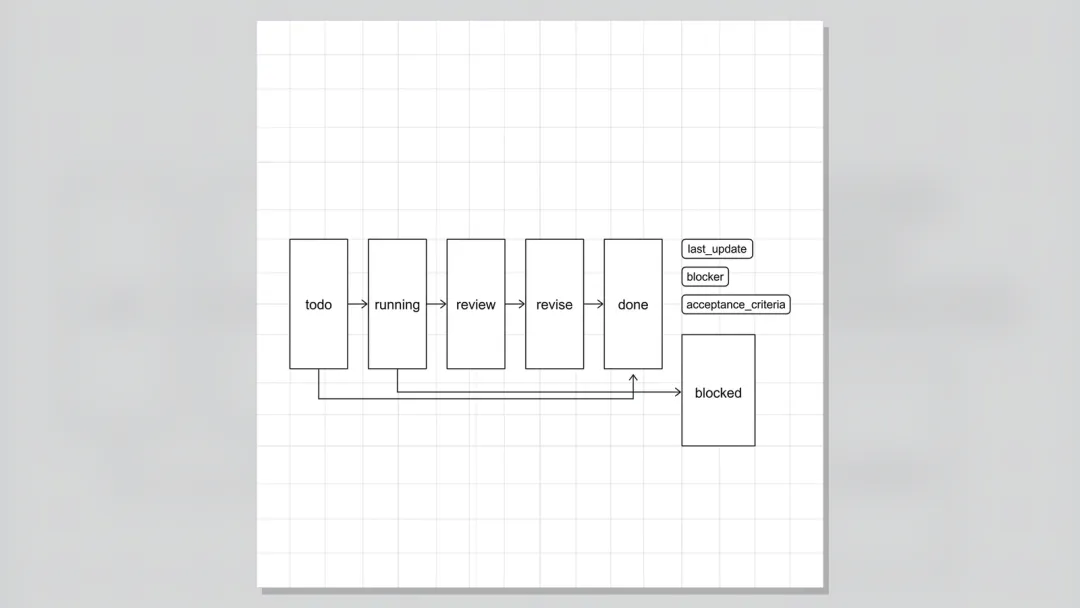
最小状态,queued、running、waiting、blocked、done、failed。
如果你希望把验收也表达得更清楚,可以在 done 后面加一个 accepted,但不要把它们混成一个词。
统一口径大概是这样。
queued -> running -> done -> accepted
running -> waiting -> running
running -> blocked -> running / failed
running -> failed
waiting 是等外部条件。
blocked 是系统里有东西坏了。
done 是执行者说做完了。
accepted 是验收者说可以交付了。
这几个词只要统一,多 Agent 协作就会少掉一大半扯皮。
最小检查,超时了吗,有产物吗,有下一步吗。
最小目录,tasks、artifacts、logs、final。
最小角色,Leader、执行者、审稿人、守夜人。
先跑通。
再加复杂度。
工程化不是把东西做复杂。
工程化是复杂度来的时候,你还能知道哪里坏了。
以后真正值钱的,是 AI 协作的可观测性
我有时候觉得,我们对 AI 的理解正在经历几个阶段。
最早,我们把 AI 当聊天窗口。
问题是,它能不能回答我。
后来,我们把 AI 当执行器。
问题变成,它能不能帮我做事。
现在到了 Agent Team 这一步,问题又变了。
多个会做事的东西,怎么被组织起来?
这就很像软件工程从脚本走到服务,从单进程走到分布式系统。
一个脚本失败了,你重跑就行。
一个分布式系统失败了,你得知道哪个节点挂了,哪条链路断了,哪个状态不一致,哪个告警是真的,哪个告警是噪声。
Agent Team 也会走到这一步。
你喊来更多 Agent,并不会天然获得更强的生产力。
有时候只会获得更多不确定性。
真正值钱的,反而是协作协议、任务台账、状态流转、验收门禁和恢复机制。
也就是 AI 劳动力的可观测性。
这听起来好像有点工程师味。
但说真的,这才是 Agent Team 从玩具变成工具的关键。
最后给你一张可复制清单
如果你想用 OpenClaw 搭一个真正能干活的 Agent Team,我建议先别追求豪华版。
先按这张清单来。
每个项目都有一个任务目录。
每个任务都有唯一 ID。
每个子任务都有明确负责人和输出文件。
每次派任务前,先写任务台账。
每个状态都写进台账,不只写在聊天里。
每个子任务都写清楚完成标准。
每个长任务都配一个临时守夜人。
守夜人检查超时、缺文件、阻塞、假完成。
blocked 要写清故障和恢复动作。
waiting 要写清等待条件。
done 必须经过验收,才能变成 accepted。
主任务收口前,逐项检查验收标准。
任务结束后,关闭临时 monitor。
失败任务也要入账,不要假装没发生。
以前我总觉得 Agent Team 跑一半停住,是因为它还不够聪明。
现在我越来越觉得,很多时候不是它不聪明。
是我们没有给它一套像团队一样工作的秩序。
多智能体不是角色扮演。
它是一套协作系统。
而协作系统最核心的能力,不是热热闹闹地开工。
是每个任务都能被看见,每个异常都有去处,每个完成都经得起验收。
你把这套东西搭起来之后,Agent Team 才真的开始像一个团队。
不是一群 AI 在说「我去看看」。
然后就没有然后了。