OpenClaw、Hermes、OpenHuman:假如它们是三种团队
OpenClaw、Hermes、OpenHuman 源码架构拆解
本人对工具的逻辑有很多好奇心,本次调研也是从非开发人员角度,看一看当前主流的agent工具逻辑。文中展示了大量的比喻,争取能通俗易懂。
OpenClaw、Hermes、OpenHuman 是三个代表——GitHub 上都有几万星,但长得完全不一样。这篇文章用团队比喻把三者的设计逻辑拆开:
各自在解决什么问题、用什么方法、优点在哪、缺点在哪。
总台统一接全部来电,按号码转到对应座席。每人一条热线,互不串线。新业务线随时加。
Hermes → 一个会写 SOP 的项目组长,带三个助手。
每次项目结束,组长自己写操作手册。下次接同类型项目,档案柜自动弹出手册。
一个人、一台电脑、一套方法。数据不出本地。不依赖公司,不需要和任何人协调。
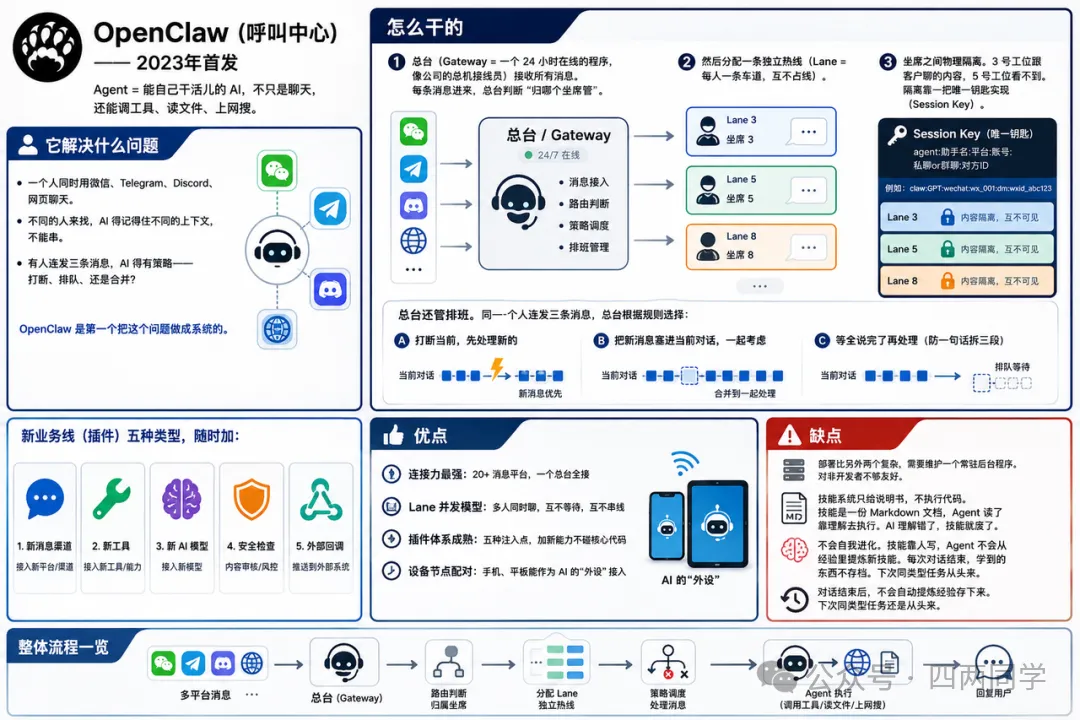
① OpenClaw(呼叫中心)—— 2023年首发
(Agent = 能自己干活儿的 AI,不只是聊天,还能调工具、读文件、上网搜。)
一个人同时用微信、Telegram、Discord、网页聊天。不同的人来找,AI 得记得住不同的上下文,不能串。有人连发三条消息,AI 得有策略——打断、排队、还是合并?
总台(Gateway = 一个 24 小时在线的程序,像公司的总机接线员)接收所有消息。每条消息进来,总台判断”归哪个坐席管”。然后分配一条独立热线(Lane = 每人一条车道,互不占线)。
座席之间物理隔离。3 号工位跟客户聊的内容,5 号工位看不到。隔离靠一把唯一钥匙实现(Session Key = agent:助手名:平台:账号:私聊or群聊:对方ID)。
总台还管排班。同一个人连发三条消息,总台根据规则选择:
新业务线(插件)五种类型,随时加:新消息渠道、新工具、新 AI 模型、安全检查、外部回调。
-
-
Lane 并发模型:多人同时聊,互不等待,互不串线
-
-
设备节点配对:手机、平板能作为 AI 的”外设”接入
-
部署比另外两个复杂,需要维护一个常驻后台程序。对非开发者不够友好。
-
技能系统只给说明书,不执行代码。技能是一份 Markdown 文档,Agent 读了靠理解去执行。AI 理解错了,技能就废了。
-
不会自我进化。技能靠人写,Agent 不会从经验里提炼新技能。每次对话结束,学到的东西不存档。下次同类型任务从头来。
-
对话结束后,不会自动提炼经验存下来。下次同类型任务还是从头来。
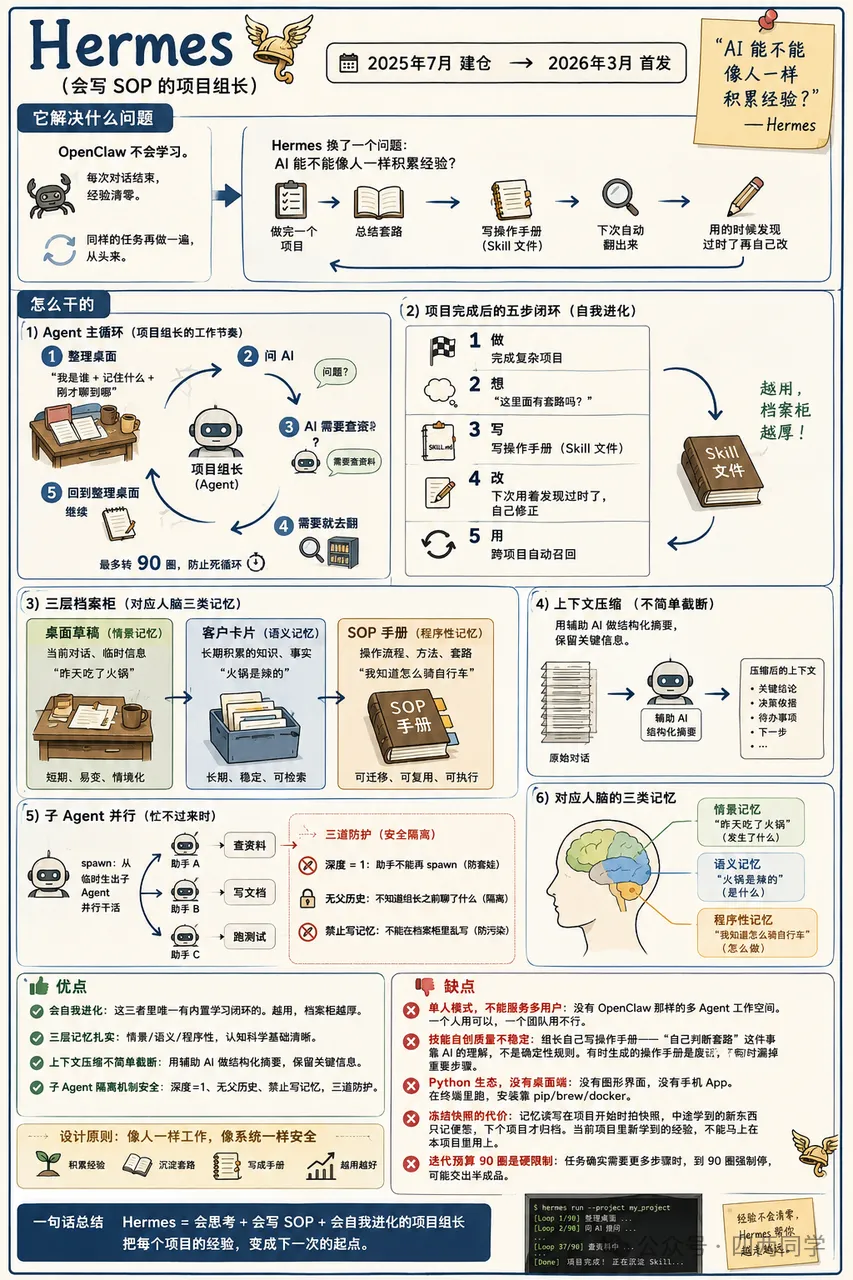
② Hermes(会写 SOP 的项目组长)—— 2025年7月建仓,2026年3月首发
OpenClaw 不会学习。每次对话结束,经验清零。同样的任务再做一遍,从头来。
Hermes 换了一个问题:AI 能不能像人一样积累经验?
做完一个项目 → 总结套路 → 写操作手册 → 下次自动翻出来 → 用的时候发现过时了再自己改。
项目组长(Agent 主循环)的工作节奏是一圈一圈来的:整理桌面(”我是谁 + 记住什么 + 刚才聊到哪”)→ 问 AI → AI 说”需要查资料”?→ 需要就去翻 → 回到整理桌面继续。最多转 90 圈,防止死循环。
做 → 想(”这里面有套路吗?”)→ 写(写操作手册,叫 Skill 文件)→ 改(下次用着发现过时了,自己修正)→ 用(跨项目自动召回)。
桌面草稿(当前对话)→ 客户卡片(长期积累的知识)→ SOP 手册(操作流程)。对应人脑的三类记忆——”昨天吃了火锅”(情景)、”火锅是辣的”(语义)、”我知道怎么调火锅蘸料”(程序性)。
忙不过来时,可以同时派三个助手(spawn = 从 Agent 里临时生出子 Agent 并行干活)。助手不能自己再招实习生(防套娃),不知道组长之前聊了什么(隔离),不能在档案柜里乱写(防污染)。
-
会自我进化。这三者里唯一有内置学习闭环的。越用,档案柜越厚。
-
三层记忆扎实。情景/语义/程序性,认知科学基础清晰。
-
上下文压缩不简单截断。用辅助 AI 做结构化摘要,保留关键信息。
-
子 Agent 隔离机制安全。深度=1、无父历史、禁止写记忆,三道防护。
-
单人模式,不能服务多用户。没有 OpenClaw 那样的多 Agent 工作空间。一个人用可以,一个团队用不行。
-
技能自创质量不稳定。组长自己写操作手册——”自己判断套路”这件事靠 AI 的理解,不是确定性规则。有时生成的操作手册是废话,有时漏掉重要步骤。
-
Python 生态,没有桌面端。没有图形界面,没有手机 App。在终端里跑,安装靠 pip/brew/docker。
-
冻结快照的代价。记忆读写在项目开始时拍快照,中途学到的新东西只记便签,下个项目才归档。当前项目里新学到的经验,不能马上在本项目里用上。
-
迭代预算 90 圈是硬限制。任务确实需要更多步骤时,到 90 圈强制停,可能交出半成品。
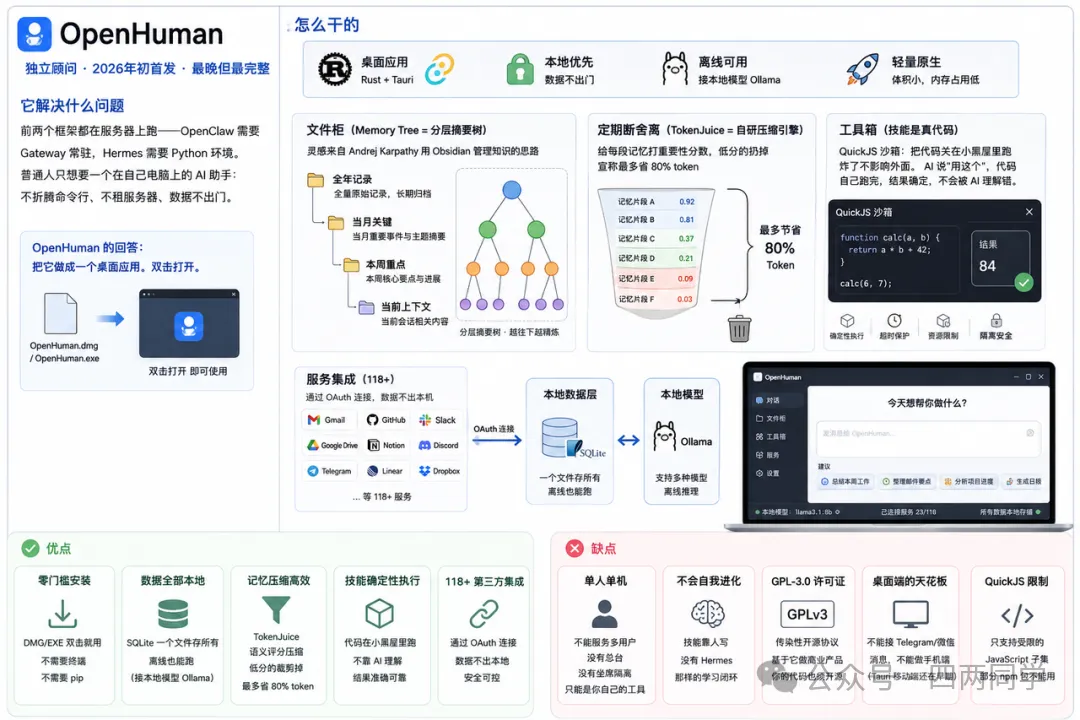
③ OpenHuman(独立顾问)—— 2026年初首发,最晚但最完整
前两个框架都在服务器上跑——OpenClaw 需要 Gateway 常驻,Hermes 需要 Python 环境。普通人只想要一个在自己电脑上的 AI 助手:不折腾命令行、不租服务器、数据不出门。
OpenHuman 的回答:把它做成一个桌面应用。双击打开。
Rust = 性能极高、不容易崩的编程语言。Tauri = 让开发者用网页技术写界面、但最终生成的是原生窗口程序——体积小,不占内存。
文件柜(Memory Tree = 分层摘要树)有层级目录:全年记录 → 当月关键 → 本周重点 → 当前上下文。
压缩成树状层级结构。灵感来自 OpenAI 联创 Andrej Karpathy 用笔记软件 Obsidian 管理知识的思路。
定期断舍离(TokenJuice = 自研压缩引擎):给每段记忆打重要性分数,低分的扔掉。
宣称最多省 80% token。Token = AI 计费最小单位,约 0.75 个英文单词。
工具箱里的技能是真代码(QuickJS 沙箱 = 把代码关在小黑屋里跑,炸了不影响外面)。AI 说”用这个”,代码自己跑完,结果确定,不会被 AI 理解错。
对外接了 118+ 个服务(Gmail、GitHub、Slack…),通过 OAuth 连接。OAuth = 点一下”用谷歌登录”,不把密码告诉对方,对方发临时令牌。数据全程在本机。
-
零门槛安装。DMG/EXE 双击就用,不需要终端,不需要 pip。
-
数据全部本地。SQLite 一个文件存所有。离线也能跑(接本地模型 Ollama)。
-
记忆压缩高效。TokenJuice 语义评分压缩,低分的裁剪掉。
-
技能确定性执行。代码在小黑屋里跑,不靠 AI 理解。
-
-
单人单机,不能服务多用户。没有总台,没有坐席隔离。它只能是你自己的工具。
-
不会自我进化。技能靠人写,没有 Hermes 那样的学习闭环。
-
GPL-3.0 许可证。传染性开源协议,基于它做商业产品,你的代码也须开源。
-
桌面端的天花板。不能接 Telegram/微信消息,不能做手机端(Tauri 移动端还在早期)。
-
QuickJS 沙箱只支持受限的 JavaScript 子集,部分 npm 包不能用。
把 AI 从”一问一答的聊天机器人”变成”看得见生活、记得住事情、能动手干活的日常伙伴”。
信它管得住渠道(OpenClaw),信它自学的东西靠谱(Hermes),信它拿数据不外传(OpenHuman)。
前面讲的是机器怎么记。先倒过来看看人脑怎么记。搞清楚这个,三个框架的差异会变得更直观。
情景记忆——”昨天和王哥在海底捞吃了顿火锅。” 有具体的时间、地点、人物。脑子里能回放那个画面:王哥坐对面,锅里红油翻滚,他说”再加份脑花”。
语义记忆——”火锅是辣的,毛肚七上八下十五秒。” 脱了具体场景也能说的知识。不需要想起”谁教的”,反正知道。鸳鸯锅一半辣一半不辣,这也是语义记忆。
程序性记忆——调蘸料的肌肉记忆。 蒜泥两勺、香油没过碗底、蚝油一甩、香菜一把。手自己会动,脑子不用想。让你写步骤反而写不全——”蚝油放多少?就一甩嘛。”
同一次火锅,三种记忆都在场。记得和谁吃的(情景)、知道毛肚怎么烫(语义)、手自己会调蘸料(程序性)。
|
|
|
|
|
|
|
|
|
五步闭环记录的是”我在什么情况下做了什么事、结果如何”——正是情景记忆
|
|
|
|
|
插件和技能是标准化的知识条目,脱了单次对话也能用——正是语义记忆
|
|
|
|
|
桌面操作(打开文件、发邮件、调系统设置)练多了就成肌肉记忆——正是程序性
|
没有一个框架能同时覆盖三种记忆。Hermes 记得住情景但管不了多人的语义库,OpenClaw 的插件是语义级的但不会从对话里自学,OpenHuman 动手能力强但不会跨会话提炼经验。三种记忆——三个框架各占一块。
下面用同一个真实任务——调研中国第二款干细胞药 RY_SW01 的上市过程和临床路线设计——演示三个框架分别是怎么通过 API 向大语言模型发提示词的。
这个任务是典型的多轮复杂调研:搜信息→筛来源→交叉验证→补缺口→结构化输出。每个框架的 prompt 构建方式和 LLM 调用模式完全不同。
用户在企业微信里发了一句话:”帮我调研一下睿源生物 RY_SW01 这款药,写一份分析。”
第一步:Gateway 总台接收消息,做意图分类。
Gateway 拿到这条消息,先不发任务——先调用一次 LLM,用一段简短的分类 prompt:
你是一个意图分类器。判断用户消息属于哪个领域:- 医药调研- 日常办公- 代码开发- 其他用户消息:"帮我调研一下睿源生物 RY_SW01 这款药,写一份分析。"输出:医药调研
LLM 返回”医药调研”,Gateway 把这条消息路由到配置了”医药调研技能包”的 Lane(坐席)。
第二步:Lane 内的 Agent 开始工作。 它拿到的是 Gateway 已经”预处理”过的消息。它的 System Prompt 已经被技能包注入了一段固定的专业描述:
你是一个医药行业调研助手。工具列表:- web_search:搜索互联网- web_fetch:抓取网页内容- read_file:读取本地文件- write_file:写入文件回答风格:客观、引用来源、标注数据局限。
第三步:Agent 循环开始。 和 Hermes 一样是 ReAct 循环——思考→行动→观察→再思考。但核心差异在于:OpenClaw 的 Agent 每轮都带完整 System Prompt(含技能包固定描述),不会从本次任务中”学到”新东西加到 System Prompt 里。
User: "帮我调研一下睿源生物 RY_SW01 这款药,写一份分析。"→ Agent 思考 → 决定:先搜基本信息和临床数据→ 调用 web_search → 收到结果
→ Agent 思考 → 提取关键来源 → 调用 web_fetch 抓取详情页→ 收到页面内容 → 发现"三条策略嵌套"是关键信息→ 调用 write_file → 写入本地文件
OpenClaw 的 prompt 特点:System Prompt 是固定的(来自技能包的一次性注入)。Agent 不会在这次任务结束后把”干细胞药调研”的经验写成新技能——下次遇到类似任务,还是从头搜。记忆中只有本次会话内的对话历史。
同一句话:”帮我调研一下睿源生物 RY_SW01 这款药,写一份分析。”
第一步:Hermes 直接进入 Agent 循环。 没有 Gateway,没有总台——用户直接和 Agent 对话。
第二步:Agent 的 System Prompt 和 OpenClaw 不同。 Hermes 注入了一段”你是有学习能力的 Agent”的描述:
你是一个能自我进化的 AI 助手。完成任务后,你会:1. 从本次任务中提炼可复用的操作步骤2. 将步骤保存为 Skill3. 下次遇到类似任务时自动调用这个 Skill工具列表:web_search, web_fetch, read_file, write_file, save_skill, recall_skill
注意最后两个工具——save_skill 和 recall_skill——OpenClaw 没有这两个。
第三步:Agent 完成调研。 过程类似——搜索→抓取→交叉验证→补缺口→写文件。但任务结束后多了一步:
Agent: "任务完成。我从中提炼了一个可复用的流程。"→ 调用 save_skill({name: "医药调研-干细胞新药",trigger: "用户要求调研某款未上市的干细胞药物",steps: ["1. 搜索'药品名称 + CDE/优先审评/临床数据'","2. 抓取CDE公示页和药品数据库","3. 搜索'公司名称 + 股东/融资/创始人'做交叉验证","4. 重点分析临床路线设计——I期拆分、适应症跳跃、报产并行","5. 查患病率和市场空间评估商业化前景","6. 输出结构化分析:药品本身→适应症→路线设计→管线→局限" ],context_patterns: ["干细胞", "未上市新药", "优先审评", "临床路线"] })
第四步:下次用户说要调研另一款干细胞药,Hermes 会自动召回这个 Skill。 System Prompt 中动态追加了之前保存的步骤——不用重新探索”应该搜什么、按什么结构写”。
Hermes 的 prompt 特点:System Prompt 是动态增长的。每次任务结束后,Agent 从对话中提炼经验,存入记忆系统。下次同类任务,这些经验自动注入 System Prompt——不是重新从零开始,而是”上次我是这么干的,这次直接套”。
第一步:用户在桌面客户端输入。 没有 Gateway,没有多个 Agent——只有一个独立顾问。
第二步:System Prompt 比前两个更”个人化”。 OpenHuman 的 System Prompt 注入了用户的本地上下文:
你是用户的桌面 AI 助手。你能访问用户的本地文件。当前可以使用的工具:local_search(搜索本地文件), web_search(搜索互联网), local_write(写入本地文件)。用户的文件目录结构:- /调研笔记/- /写作项目/- /财务数据/隐私规则:任何用户数据不得上传到云端。web_search 只能发送搜索关键词,不能附带用户本地文件内容。
第三步:Agent 的循环和前两个类似,但工具调用的”边界”不同。
-
web_search 发出前,Agent 先剥离任何可能含用户隐私的上下文——搜索词只能是”RY_SW01 临床数据”,不能带”我老板让我调研的”这种信息
-
-
最终输出直接 local_write 到用户的本地文件夹——不经过任何云端中转
OpenHuman 的 prompt 特点:隐私规则是硬编码在 System Prompt 里的,不是”建议”而是”红线”。每次调 API 前,Agent 先检查 Prompt 是否含敏感信息,含了就裁掉再发。
前面三个框架是”底层思路”。日常工作用的是落地的产品。以下产品按实际架构来归类,不用标签套。
底座层是 Agent 循环(理解→规划→调用→监控),和 OpenClaw 一样有技能系统(20+ 内置技能包),该产品负责人明确说没使用 OpenClaw 任何一行源码。
最核心的差异在”半自动”——WorkBuddy 刻意加了人工确认环节,不会在未授权情况下自主对外发布内容。执行模式分两种:敏感数据走本地(数据不出电脑),复杂推理走云端沙箱(任务完成数据自动删除)。
它像谁:不直接等于任何一个开源框架。从功能形态看,最接近 OpenHuman 的”独立顾问”路线——桌面端、读本地文件、一个用户一个实例。但它比 OpenHuman 多了云端能力和企业微信/飞书/钉钉多端接入,比 OpenClaw 少了完全自主执行。
实际架构:Tool Use Loop 无限循环 + 流式并行工具执行。
核心是 while(true) 包裹的 Agent 循环:
用户输入 → 调模型 API(streaming 输出)→ 模型边输出边并行执行工具 → 结果拼回对话 → 下一轮。
六个层级的上下文压缩(Snip → Microcompact → Collapse → Auto Compact → Reactive Compact → Manual Compact)。多 Agent 有三种模式:Fork 子 Agent(共享缓存)、Coordinator 模式(主 Agent 调度异步 Worker)、Team Agent(进程内 teammate)。
它像谁:Agent 主循环和 Hermes 最像——都是思考→行动→观察的 ReAct 范式。差别在于 CC 不会自我进化(不写 SOP),但它有六层上下文压缩和三种多 Agent 模式,工程深度超过 Hermes。
实际架构:可视化工作流编排 + 插件系统 + 知识库。
智能体 = LLM(大脑)+ 知识库(记忆)+ 插件(手脚),工作流用拖拽节点搭建。
和 OpenClaw 一样是”搭 Bot 给不同场景用”的思路——一个平台,建多个 Agent,分别管不同渠道。
区别是扣子是低代码可视化(拖拽),OpenClaw 是代码级(写 SKILL.md)。
它像谁:最接近 OpenClaw 的”呼叫中心”路线——Bot 工厂,批量生产、各管一摊。但扣子的编排是可视化的,面向业务人员;OpenClaw 的编排是代码级的,面向开发者。
实际架构:钉钉原生 AI 平台,底层是 Agent OS。
深度集成钉钉生态——日程、审批、文档、会议全链路打通。企业级安全管控(组织权限适配、三级风险拦截)。
和 OpenClaw 一样强调”一个入口接所有事”,但它只接钉钉生态内的事。
它像谁:定位上接近 OpenClaw——统一入口、多任务调度。但范围窄得多:OpenClaw 接一切渠道,悟空只管钉钉里的事。
实际架构:1 个 PM Agent + 5 个专业 Agent,端云混合。 PM Agent(项目经理)用混元/DeepSeek V4 理解意图、拆任务、分派。五个专业 Agent 各管一块:File(文件)、Computer(系统设置)、App(操控桌面应用)、Browser(网页)、Search(搜索)。敏感任务纯端侧跑 Qwen 模型,数据零上云。
它像谁:自成一派。 它是操作系统层级的——不是”帮你聊天的工具”,是”替操作系统的 AI 中间层”。这个定位在三个开源框架里没有对应。非要说的话,专业 Agent 的分工方式和 OpenClaw 的多坐席有点像,但 Marvis 是绑定操作系统的,不是 Bot 工厂。
市占率的数据支撑了最简单的选型框架。不需要纠结”哪个更强”——看三件事。
在干什么。 写文章、整表格、搜信息、管文件 → WorkBuddy。写代码、调bug、跑测试 → CC 接 DeepSeek。
数据能不能出门。 财务、法务、HR 等敏感场景 → WorkBuddy 本地模式 或 Marvis 隐私模式。数据零上云是硬底线。
是一个人用还是团队用。 目前还没有比较适合团队用的agent,团队协作还没被提上日程。
-
非代码人员日常办公 → WorkBuddy(桌面端,本地文件,零门槛)
-
开发人员写代码 → CC + DeepSeek(终端 Agent,六层压缩,流式并行)
-
系统级操控电脑 → Marvis(改设置、开应用、跨端协同——别人做不到的)
数据来源:GitHub 仓库 README、官方文档、社区深度分析文章、腾讯云开发者社区 WorkBuddy 架构拆解、Claude Code 源码分析(Yoyo_Lee)、火山引擎扣子开发者文档、CSDN Marvis 架构解析
 夜雨聆风
夜雨聆风