 夜雨聆风
夜雨聆风





〖OpenClaw系列〗接入本地模型:Ollama/LM Studio
上篇回顾
第12篇〖OpenClaw系列〗模型故障切换与多模型策略我们建立了完整的 Fallback 机制:当云端模型故障时,自动切换到备用模型。但 Fallback 链的最后一环——本地模型——才是真正实现完全自主可控的关键。
本文将解决:
-
如何在本地运行开源大模型 -
如何让 OpenClaw 无缝接入本地模型 -
如何构建「云端+本地」混合架构
为什么需要本地模型
三大核心场景
|
|
|
|
|---|---|---|
| 数据隐私 |
|
|
| 成本控制 |
|
|
| 离线环境 |
|
|
把表格里的痛点与方案画出来,对比更直观:
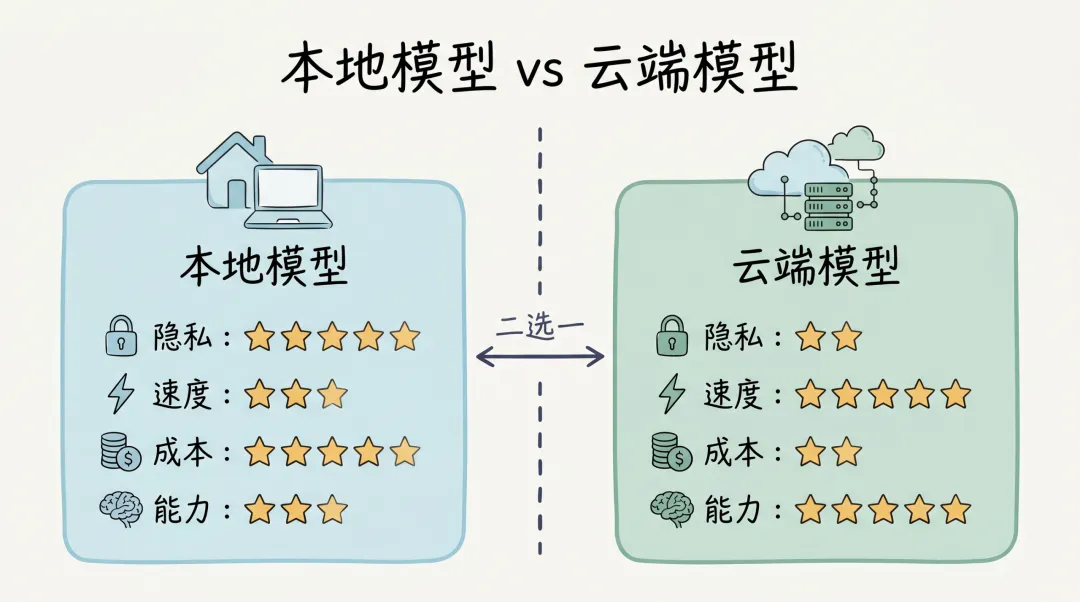
性能对比(参考值)
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
结论:本地小模型(<14B)延迟可媲美甚至超越云端。
Ollama 安装与配置
什么是 Ollama
Ollama 是本地运行大模型的最简单方案:
-
一行命令安装 -
一键下载模型 -
提供 OpenAI 兼容 API -
支持 macOS/Linux/Windows
Ollama 在本地的运行架构
在动手装之前,先把 Ollama 是怎么跑起来的看一遍——这样后面的命令你才知道对应到哪一块:
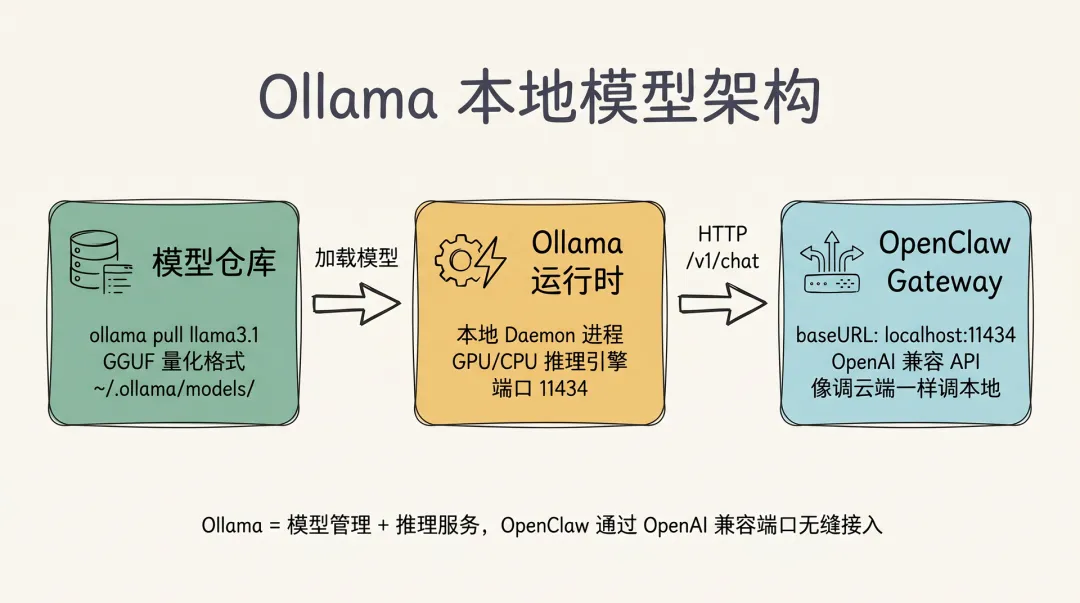
Ollama 把”模型管理 + 推理服务”封装成一个本地 daemon,对外暴露一个 OpenAI 兼容端口(默认 11434),OpenClaw 通过这个端口像调用云端模型一样调用本地模型——这就是为什么后面只需要把 baseURL 指向 http://localhost:11434 就能接进来。
安装 Ollama
# macOS
brew install ollama
# Linux
curl -fsSL https://ollama.com/install.sh | sh
# Windows
# 下载安装包: https://ollama.com/download/windows
验证安装:
ollama --version
# 输出: ollama version 0.4.x
下载模型
# 下载 Llama 3.1 (8B,适合入门)
ollama pull llama3.1
# 下载 Qwen 2.5 (14B,中文友好)
ollama pull qwen2.5:14b
# 下载 DeepSeek R1 (推理模型)
ollama pull deepseek-r1:14b
# 查看已安装模型
ollama list
启动 Ollama 服务
# 前台启动(调试时使用)
ollama serve
# 验证服务状态
curl http://localhost:11434/api/tags
预期输出:
{
"models": [
{
"name": "llama3.1:latest",
"model": "llama3.1:latest",
"size": 4661224676,
"digest": "sha256:..."
}
]
}
OpenClaw 配置 Ollama
基础配置
{
models: {
providers: {
ollama: {
baseUrl: "http://127.0.0.1:11434",
// Ollama 默认无需 API Key,如需可配置:
// apiKey: "${OLLAMA_API_KEY}"
}
}
},
agents: {
defaults: {
model: {
primary: "anthropic/claude-sonnet-4-6",
fallbacks: [
"openai/gpt-5.2",
"ollama/llama3.1" // 本地模型兜底
]
},
// 允许使用本地模型
models: {
"anthropic/claude-sonnet-4-6": {},
"openai/gpt-5.2": {},
"ollama/llama3.1": {
alias: "local"
}
}
}
}
}
远程 Ollama(局域网/服务器)
{
models: {
providers: {
ollama: {
// 远程 Ollama 服务器
baseUrl: "http://192.168.1.100:11434"
}
}
}
}
注意:远程 Ollama 需设置环境变量允许跨域:
export OLLAMA_ORIGINS="*"
export OLLAMA_HOST="0.0.0.0:11434"
ollama serve
配置验证
# 验证配置语法
openclaw config validate
# 查看模型目录(应包含 Ollama 模型)
openclaw models list
# 测试本地模型连接
openclaw doctor
LM Studio 集成方案
什么是 LM Studio
LM Studio 是带图形界面的本地模型管理工具:
-
可视化模型下载/管理 -
一键启动本地推理服务器 -
支持 GGUF 格式模型 -
内置 Chat 界面测试
Ollama 与 LM Studio 的”卖点”对照如下:
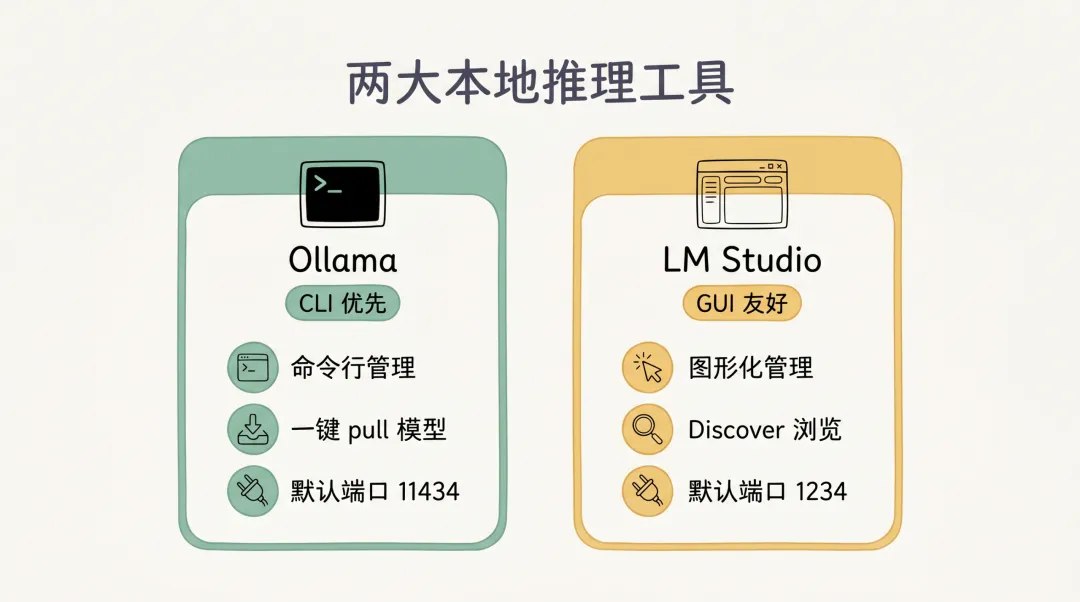
安装与配置
-
下载安装
# macOS
brew install --cask lm-studio
# 或官网下载: https://lmstudio.ai -
下载模型
-
打开 LM Studio -
进入 “Discover” 标签 -
搜索并下载模型(如 Qwen/Qwen2.5-7B-Instruct-GGUF) -
启动本地服务器
-
切换到 “Local Server” 标签 -
选择模型 -
点击 “Start Server” -
默认地址: http://localhost:1234
OpenClaw 配置 LM Studio
LM Studio 提供 OpenAI 兼容 API:
{
models: {
providers: {
// 将 LM Studio 配置为 openai 兼容 provider
lmstudio: {
baseUrl: "http://localhost:1234/v1",
apiKey: "lm-studio", // 任意值,LM Studio 不验证
api: "openai-completions"
}
}
},
agents: {
defaults: {
model: {
primary: "anthropic/claude-sonnet-4-6",
fallbacks: [
"lmstudio/qwen2.5-7b" // LM Studio 模型
]
},
models: {
"lmstudio/qwen2.5-7b": {
alias: "local-lm"
}
}
}
}
}
本地模型性能优化
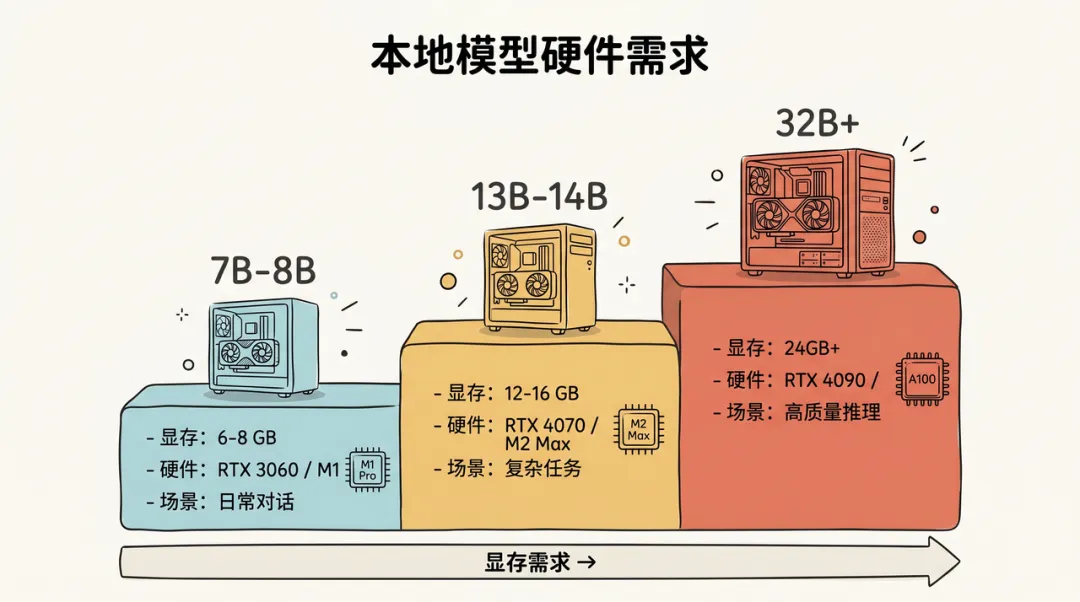
硬件要求参考
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
把这张表立起来看,就是一道由低到高的硬件阶梯:
Ollama 优化参数
# 设置环境变量优化性能
# 使用 GPU 加速(默认自动检测)
export OLLAMA_GPU_LAYERS=999
# 限制并发请求数
export OLLAMA_NUM_PARALLEL=1
# 设置上下文长度
export OLLAMA_CONTEXT_LENGTH=8192
# 启动服务
ollama serve
模型量化选择
量化降低显存占用,但会损失精度:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
显存占用与精度损失的权衡,画出来一目了然:
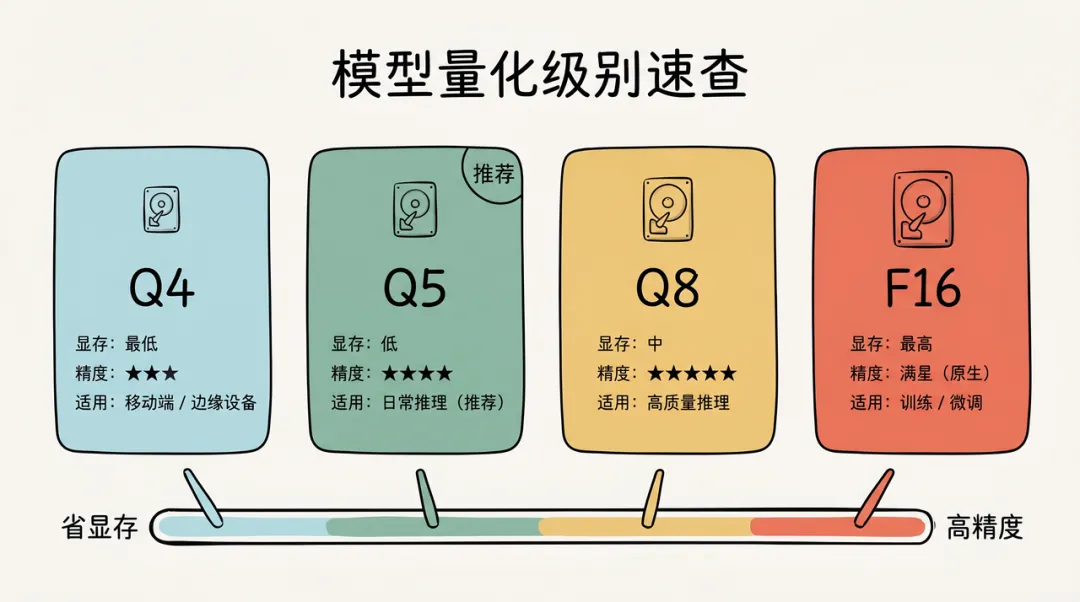
# 下载特定量化版本
ollama pull qwen2.5:14b-q5_k_m
纯离线环境部署
场景:完全隔离的内网环境
┌─────────────────────────────────────────────────────────┐
│ 离线服务器/内网 │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ OpenClaw │◄────►│ Ollama │ │
│ │ Gateway │ │ Server │ │
│ └──────────────┘ └──────┬───────┘ │
│ │ │
│ ┌────────┴────────┐ │
│ │ 本地模型文件 │ │
│ │ (预下载) │ │
│ └─────────────────┘ │
└─────────────────────────────────────────────────────────┘
离线部署步骤
-
联网机器准备模型
# 下载模型
ollama pull llama3.1
ollama pull nomic-embed-text
# 查看模型文件位置
# macOS: ~/.ollama/models
# Linux: /usr/share/ollama/.ollama/models
# Windows: C:\Users\<user>\.ollama\models -
复制模型文件到离线机器
# 打包模型
tar -czf ollama-models.tar.gz ~/.ollama/models
# 传输到离线机器并解压 -
离线机器配置
# 安装 Ollama(离线安装包)
# 复制模型文件到对应目录
# 启动服务
ollama serve -
OpenClaw 离线配置
{
// 完全离线配置,无云端依赖
models: {
providers: {
ollama: {
baseUrl: "http://localhost:11434"
}
}
},
agents: {
defaults: {
model: "ollama/llama3.1",
models: {
"ollama/llama3.1": {},
"ollama/qwen2.5:14b": {}
}
}
}
}
高级配置
按 Agent 配置本地模型
{
agents: {
list: [
{
id: "offline-assistant",
name: "离线助手",
// 完全使用本地模型
model: "ollama/qwen2.5:14b",
workspace: "./workspace-offline"
},
{
id: "coding",
name: "编程助手",
// 云端优先,本地兜底
model: {
primary: "anthropic/claude-opus-4-6",
fallbacks: ["ollama/deepseek-coder-v2"]
}
}
]
}
}
本地 Embedding 模型
Ollama 也支持 Embedding 模型,用于记忆搜索:
{
agents: {
defaults: {
// 本地 Embedding 模型
imageModel: {
primary: "ollama/nomic-embed-text"
},
memorySearch: {
embedding: {
provider: "ollama",
model: "nomic-embed-text"
}
}
}
}
}
模型自动发现
OpenClaw 启动时会自动探测 Ollama 服务:
[INFO] 发现 Ollama 服务: http://localhost:11434
[INFO] 可用本地模型:
- llama3.1 (8B, context: 128k)
- qwen2.5:14b (14B, context: 128k)
- deepseek-r1:14b (14B, context: 64k)
踩坑
坑1:Ollama 连接失败
现象:openclaw doctor 显示 Ollama 不可达
排查:
# 1. 检查 Ollama 服务状态
curl http://localhost:11434/api/tags
# 2. 检查配置中的 baseUrl
openclaw config get models.providers.ollama.baseUrl
# 3. 检查防火墙(远程连接时)
telnet 192.168.1.100 11434
常见原因:
-
Ollama 服务未启动 -
baseUrl 配置了 /v1后缀(Ollama 原生 API 不需要) -
远程连接时未设置 OLLAMA_HOST
坑2:模型响应质量差
现象:本地模型回答明显比云端差
解决:
# 1. 确认模型正确加载
ollama ps
# 2. 尝试更大参数版本
ollama pull qwen2.5:32b # 替代 7b/14b
# 3. 调整 temperature(通过 OpenClaw 配置)
{
agents: {
defaults: {
models: {
"ollama/llama3.1": {
params: {
temperature: 0.7
}
}
}
}
}
}
坑3:显存不足导致崩溃
现象:Ollama 进程被杀或响应极慢
排查:
# 查看显存使用
nvidia-smi # NVIDIA
gputop # Apple Silicon
# 查看系统内存
free -h
解决:
# 使用量化版本
ollama pull llama3.1:8b-q4_0 # 更低显存占用
# 或切换到 CPU 推理
export OLLAMA_GPU_LAYERS=0
ollama serve
坑4:Fallback 到本地模型时上下文丢失
现象:云端模型故障后切换到本地模型,对话上下文被重置
原因:不同模型的上下文窗口大小不同,OpenClaw 可能触发裁剪
缓解:
{
agents: {
defaults: {
models: {
"ollama/llama3.1": {
// 确保本地模型上下文足够大
params: {
max_tokens: 8192
}
}
}
}
}
}
FAQ
Q1: Ollama 和 LM Studio 应该选哪个?
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
建议:生产环境用 Ollama,探索/测试用 LM Studio。
Q2: 本地模型能完全替代云端吗?
取决于场景:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Q3: 如何监控本地模型性能?
# Ollama 内置统计
curl http://localhost:11434/api/ps
# 查看 GPU 利用率
watch -n 1 nvidia-smi
# OpenClaw 日志查看响应时间
openclaw logs -f | grep "model.*response"
Q4: 可以在同一台机器运行多个本地模型吗?
可以,但受限于显存。Ollama 会自动管理:
# Ollama 会自动卸载不活跃的模型
# 调整超时时间
export OLLAMA_KEEP_ALIVE="5m"# 5分钟后卸载
完整配置示例
混合部署生产配置
{
// 模型提供商配置
models: {
providers: {
anthropic: {
baseUrl: "https://api.anthropic.com",
apiKey: "${ANTHROPIC_API_KEY}"
},
openai: {
baseUrl: "https://api.openai.com",
apiKey: "${OPENAI_API_KEY}"
},
ollama: {
baseUrl: "http://localhost:11434"
}
}
},
// Agent 配置
agents: {
defaults: {
// 主模型 + 完整 Fallback 链
model: {
primary: "anthropic/claude-sonnet-4-6",
fallbacks: [
"anthropic/claude-haiku-4-5",
"openai/gpt-5.2",
"ollama/qwen2.5:14b" // 本地兜底
]
},
// 允许使用的模型白名单
models: {
"anthropic/claude-opus-4-6": { alias: "smart" },
"anthropic/claude-sonnet-4-6": { alias: "balanced" },
"anthropic/claude-haiku-4-5": { alias: "fast" },
"openai/gpt-5.2": { alias: "backup" },
"ollama/qwen2.5:14b": { alias: "local" }
},
// 本地 Embedding
memorySearch: {
embedding: {
provider: "ollama",
model: "nomic-embed-text"
}
}
},
list: [
{
id: "offline",
name: "离线模式",
model: "ollama/llama3.1",
workspace: "./workspace-offline"
}
]
}
}
总结
本文深入讲解了 OpenClaw 接入本地模型的完整方案:
|
|
|
|---|---|
| Ollama 集成 | baseUrl: http://localhost:11434
|
| LM Studio 集成 |
baseUrl: http://localhost:1234/v1 |
| 性能优化 |
|
| 离线部署 |
|
| 混合架构 |
|
关键认知:本地模型不是云端的替代品,而是互补的伙伴——云端负责高质量,本地负责高可用。
下一篇预告
第14篇:多 Agent 配置与工作区隔离
本地模型让多 Agent 架构更具可行性:
-
为不同 Agent 配置专属本地模型 -
工作区隔离实现数据分离 -
Agent 间协作与通信机制 -
构建「个人 AI 团队」
本文是系列第13篇。你已掌握 OpenClaw 接入本地完整方案,可以构建真正自主可控的 AI 系统。
📌 觉得有用?点个「在看」 👇 👨💻 关注「敏叔侃技术」,每周更新 OpenClaw 实战干货 ⭐ 收藏这篇文章,作为本地模型部署的完整指南