 夜雨聆风
夜雨聆风





百度把 OCR 卷到“长文档一次读完”:3B 的 Unlimited OCR,靠什么跑出 93.92 分?
一份 40 多页的扫描报告,交给 OCR,最怕的不是“认错字”,而是越读越慢、越读越吃显存。
百度刚开源的 Unlimited OCR,瞄准的正是这个老问题。
它的总参数量是 3B,但一次推理实际激活约 500M 参数;项目披露的 OmniDocBench 综合成绩为:v1.5 达到 93.23,v1.6 达到 93.92。更值得关注的是,它不是把每一页切碎后各自处理,而是尝试在一次推理里连续解析几十页文档。
这不是“又一个 OCR 模型”。它试图解决的是:当文档变长时,端到端 OCR 怎样不被自己的记忆成本拖垮。

500M 激活参数,为什么能和大模型掰手腕?
先把“3B”和“500M”说清楚。
3B 是模型总参数规模;500M 是一次前向计算中实际被激活、参与计算的参数量。对部署者来说,后者往往更接近推理成本的体感:显存、吞吐和并发压力不会只看模型名义尺寸。
根据项目公布的 OmniDocBench v1.5 对比,Unlimited OCR 的 93.23 分高于 Qwen3-VL-235B 的 89.15、Qwen2.5-VL-72B 的 87.02,以及 Gemini-2.5 Pro 的 88.03。v1.6 的 93.92 分,则是项目给出的端到端最新成绩。
但这里不该简单得出“小模型全面赢了大模型”的结论。它比拼的是文档解析这个高度垂直的任务:版面、表格、公式、阅读顺序和文本还原。通用视觉语言模型能做的事更多,优化目标也不同。
真正有意思的是,Unlimited OCR 给了一个反直觉信号:在专用任务里,模型规模并不必然等于效率和准确率。结构对路,可能比堆参数更重要。
长文档 OCR 的瓶颈,原来在“记忆”
许多端到端 OCR 会用视觉编码器把页面压缩成视觉 token,再交给语言模型式的解码器逐字、逐段生成结构化结果。
问题出在解码过程。传统注意力机制需要保存历史 token 的 Key 和 Value,也就是常说的 KV Cache。输出越长,缓存越大;计算量和显存负担随之增长。几十页 PDF 一路读下去,速度变慢、显存膨胀,并不是工程实现不够努力,而是机制本身在累积成本。
Unlimited OCR 的论文把这件事讲得很直白:它在 DeepSeek OCR 的思路上,用 Reference Sliding Window Attention(R-SWA) 替换了解码器中的注意力层。
直观理解,模型并非死记整篇文档产生过的所有内容,而是保留一个滑动的近期窗口,同时参考一组被压缩保留的信息。这样,历史越来越长,KV Cache 仍能维持固定大小。
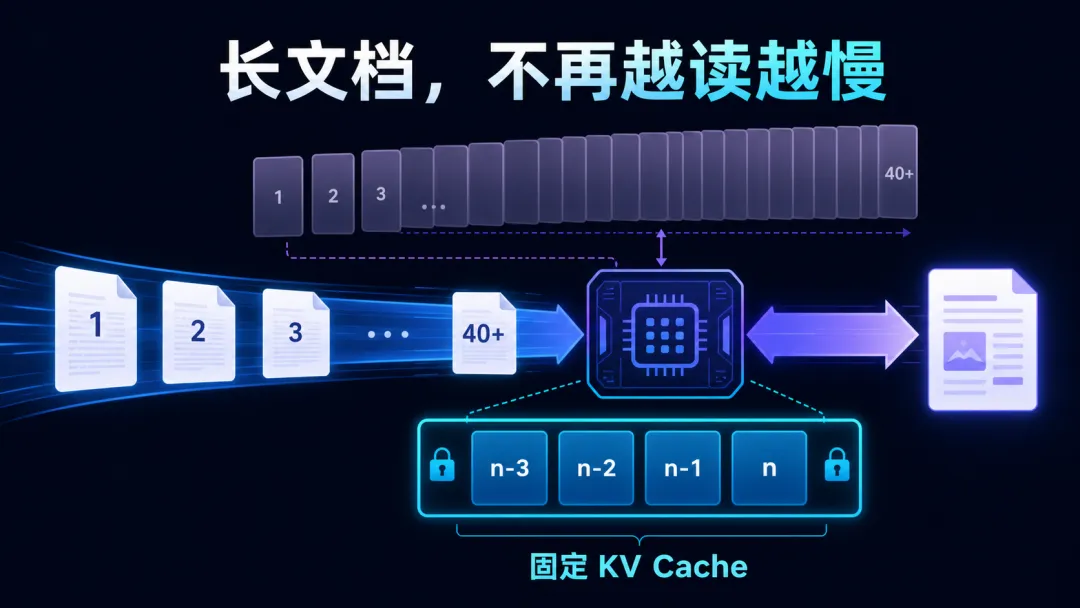
这带来两层价值:
●对使用者:长 PDF 不必被迫拆成许多独立小任务,跨页标题、表格延续、上下文衔接更有机会在同一条推理链路里处理。
●对部署者:显存占用不再随着输出长度线性膨胀,长文档场景的吞吐和成本更可预期。
论文称,在标准 32K 最大长度配置下,它可以一次前向转写数十页文档。注意,这不等于任何 PDF 都会“无限页”稳定处理:扫描质量、页面复杂度、分辨率和输出密度仍会影响结果。但“连续读几十页且缓存恒定”的方向,本身已经足够实用。
它适合放进哪些工作流?
如果你需要的是单张截图提字,成熟的传统 OCR 依然很轻、很快;如果你想让模型理解一张图里有什么,通用多模态模型更灵活。
Unlimited OCR 更像是卡在两者之间、但对长文档特别有价值的选项。比如:
●财报、招股书、审计材料的批量结构化;
●合同、研报、论文的 PDF 转 Markdown / JSON;
●表格、公式、复杂版面混排的知识库入库;
●多页票据、档案、说明书的连续解析。
项目仓库给出了两条推理路径:可直接通过 Transformers 加载,也提供基于 SGLang 的服务化方案。PDF 会先转成页面图片,再交给多页解析接口;示例里使用 infer_multi 传入页面序列,并将上下文长度设为 32768。
对开发者而言,这意味着它已经不是“只放了论文和权重”的研究演示:模型权重、MIT 许可代码、推理示例都已公开。真正进入生产前,建议至少用自己的中文合同、复杂表格和低清扫描件跑一轮评测;基准分数是能力坐标,不是你的业务验收报告。
这次开源,重要的不只是一个榜单分数
过去一段时间,OCR 的热度被大模型重新点燃,但长文档一直是很现实的落地难点:不是模型能不能看懂一页,而是能不能把几十页稳定、经济地读完。
Unlimited OCR 给出的答案不靠把解码器继续做大,而是从注意力机制的“记忆方式”动手。R-SWA 是否会推广到语音识别、翻译等长序列任务,仍有待更多复现和真实负载验证;论文作者已经明确把它定位为可迁移的通用解析注意力机制。
不过,对于每天和 PDF、扫描件、表格打交道的团队来说,这个开源项目已经值得进候选清单:它把 OCR 从“逐页识字”往“长文档连续解析”推了一步。
项目地址
GitHub:https://github.com/baidu/Unlimited-OCR
Hugging Face:https://huggingface.co/baidu/Unlimited-OCR
论文:https://arxiv.org/abs/2606.23050
数据说明:文中 OmniDocBench 成绩与参数激活量均来自项目公开资料;不同硬件、输入分辨率、文档类型和推理配置下,实际性能会有差异。