 夜雨聆风
夜雨聆风- 2026年再看KV Cache卸载,已经证明:存储不是成本,是算力放大器。白皮书来自三星官网,所有信息均为互联网公开信息,实验仅限LLaMA-3.1-8B、LMCache、特定SSD),缺乏对不同模型、不同缓存管理策略的对比。只能大致参考一下。
一、实验背景与挑战
背景
大语言模型在处理长文本、多轮对话、Agent任务时,需要反复使用历史生成的“键值对”来生成下一个词。为了不重复计算,这些键值对被暂存在一个叫 KV Cache 的缓冲区中。
挑战
· 显存有限:上下文越长,KV Cache越大,GPU的HBM很快被占满。
· 多轮交互与迁移:在Agent系统中,任务可能跨GPU迁移,若KV Cache只存在本地GPU,迁移后必须重新计算,导致延迟飙升。
· 并发压力:高并发下,GPU既要计算又要缓存,成为性能瓶颈。
二、解决的问题
核心问题:如何在不显著增加延迟的前提下,突破GPU显存限制,支持更多并发用户,同时降低功耗和成本?
解决思路:将KV Cache从昂贵的GPU HBM 卸载(Offloading) 到更大、更便宜的NVMe SSD中,需要时再加载回GPU,从而:
· 释放GPU显存用于计算
· 支持更长上下文与更多并发
· 减少重复计算(Prefill阶段)
三、场景信息和实验数据
1. LLM推理流程与KV Cache
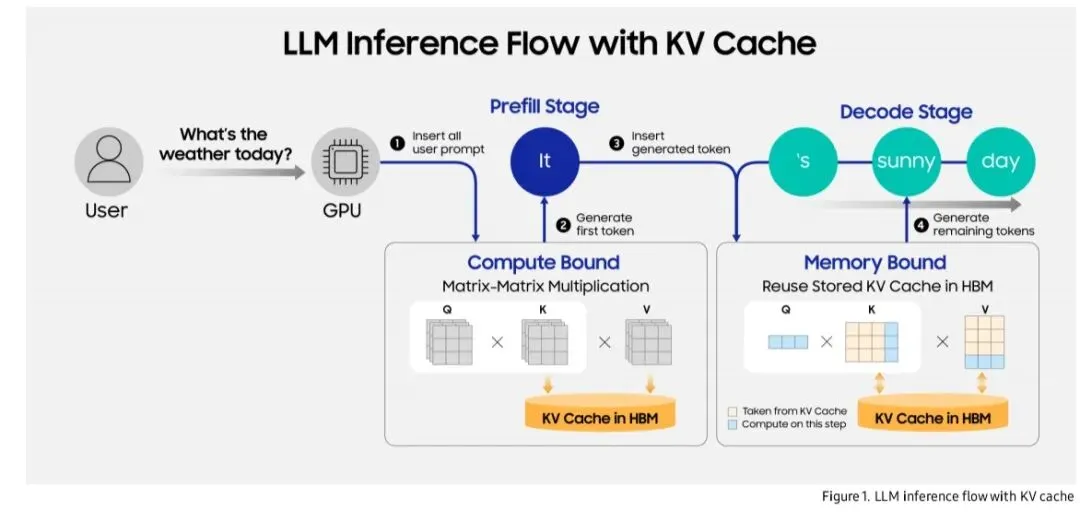
上图展示了KV Cache在LLM推理中的位置,区分了Prefill与Decode两个阶段。
· Prefill阶段:处理完整输入,生成初始KV Cache,计算密集。
· Decode阶段:逐词生成,内存密集。
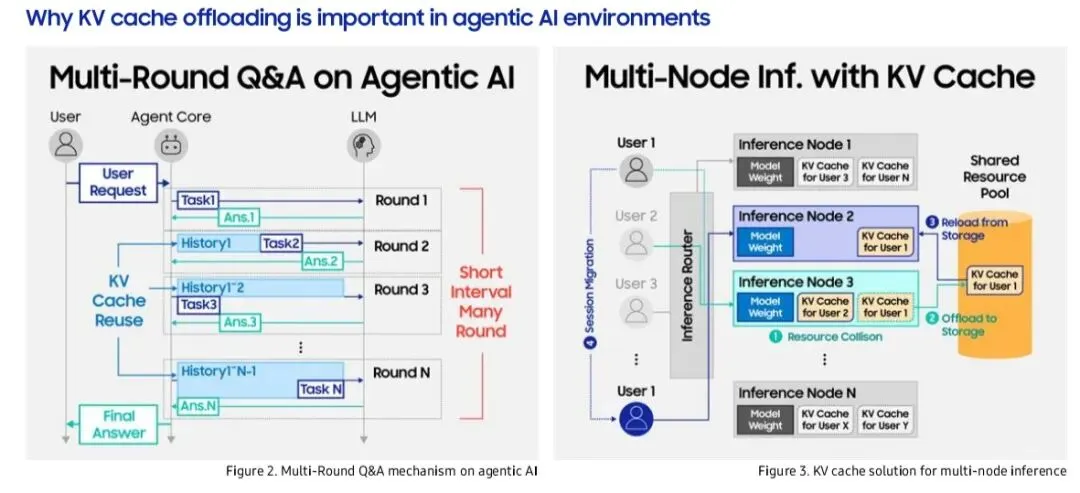
2. Agentic AI中的KV Cache复用
下 图:Agent系统在多轮交互中,KV Cache被反复复用,避免重复计算。
3. 跨节点KV Cache迁移
下图:当会话从GPU A迁移到GPU B时,KV Cache需从外部存储(SSD)快速加载,否则需重新计算。
4. I/O特性分析
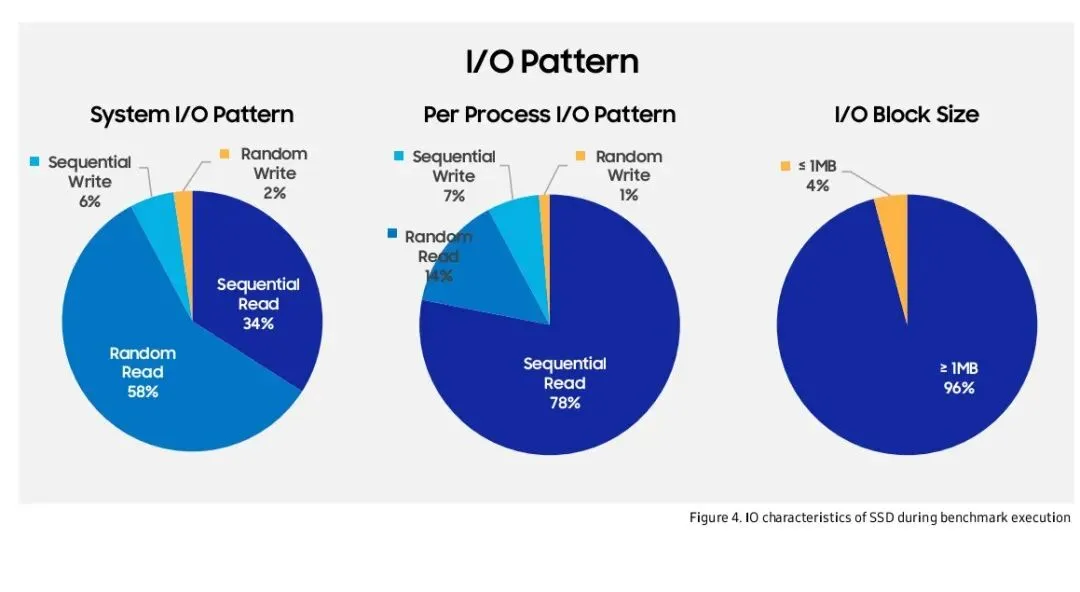
上图展示SSD在测试中的I/O特征:
· 读取占92%,写入8%
· 系统层面58%随机,34%顺序;但单进程78%顺序读
· 96%的I/O请求超过1MB
5. LBA访问模式
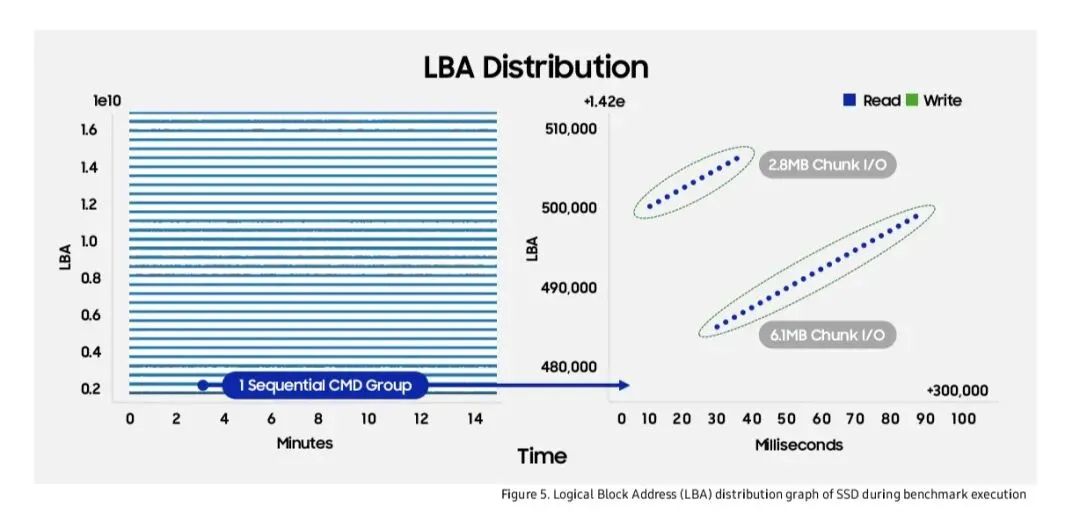
逻辑块地址分布,说明多个并发顺序流在NVMe设备上交错,设备需具备良好的顺序检测能力。
6. 吞吐量与队列深度
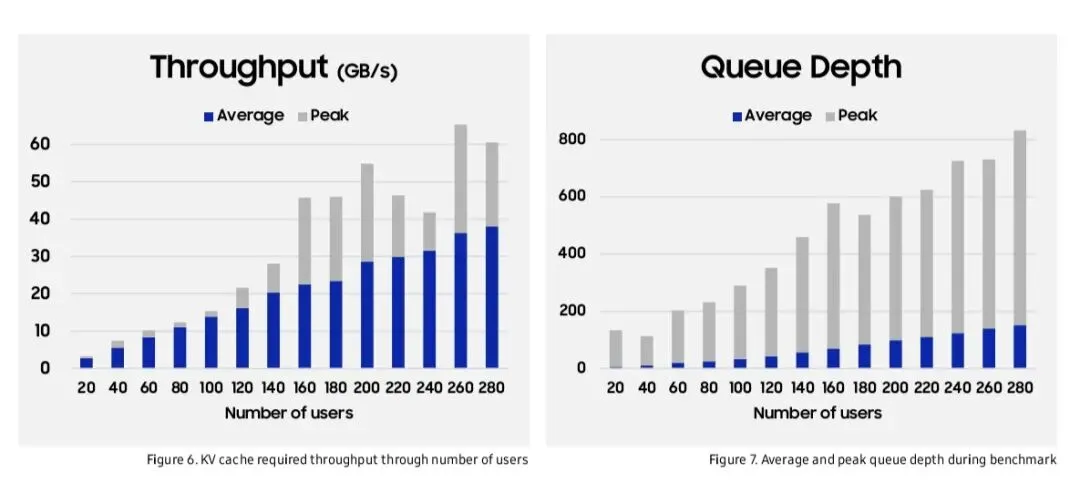
吞吐量(最高37 GB/s)与队列深度(峰值达800)随用户数变化,强调存储需具备2倍平均带宽以应对突发。
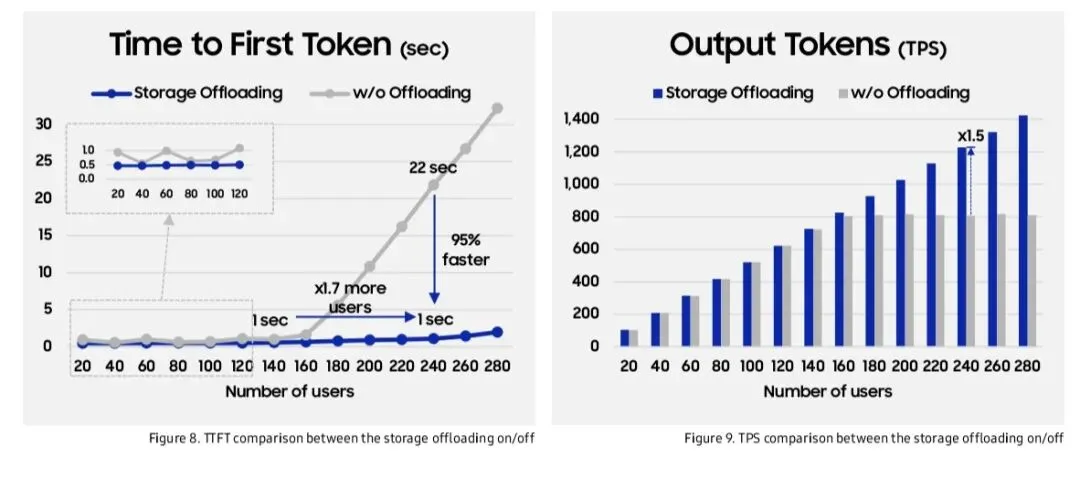
7. 性能对比
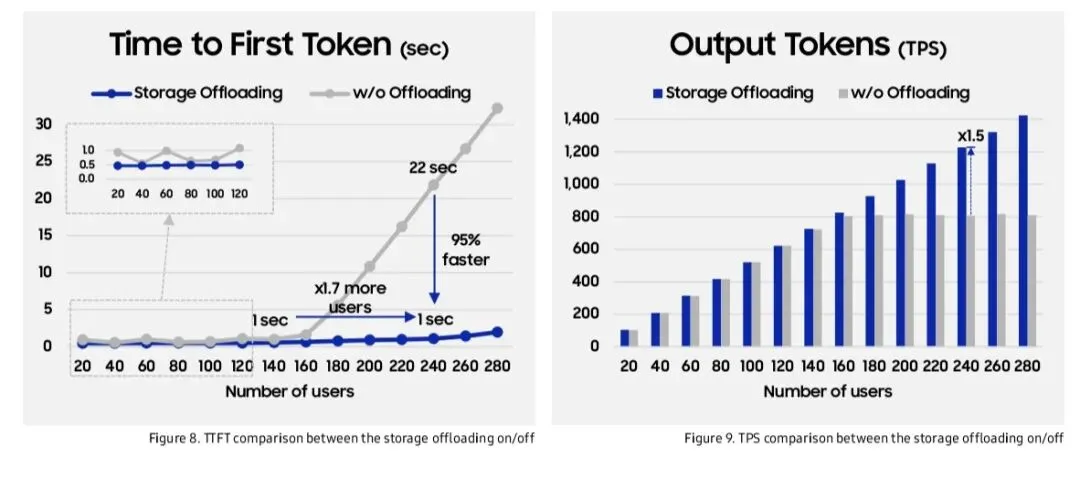
TFT(Time to First Token)对比,卸载方案在240用户时仍<1秒,无卸载方案在140用户后开始升高。
TPS(Tokens Per Second)对比,卸载方案在240用户时TPS提升1.5倍。
8. 功耗与散热
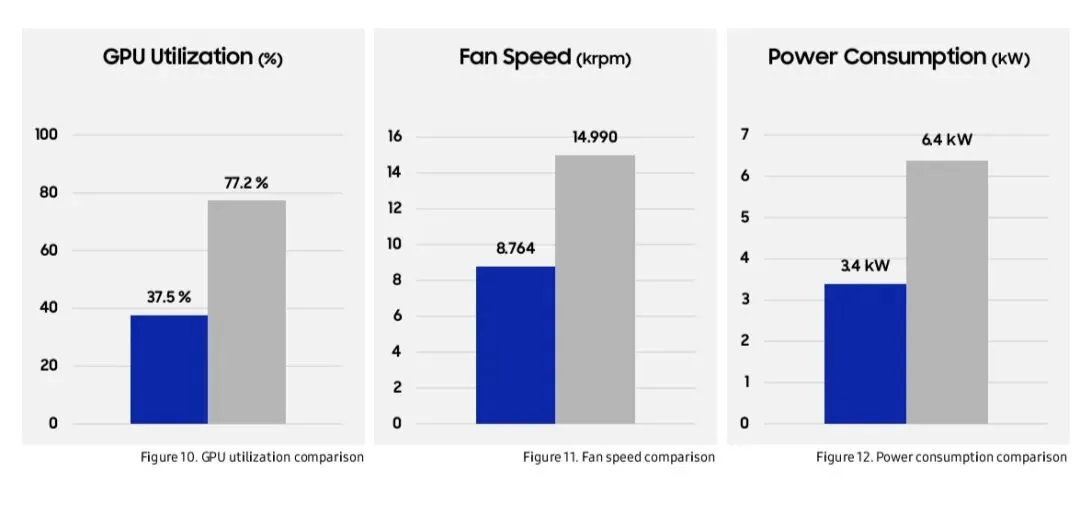
GPU利用率从满载降至49%
风扇转速从15000 RPM降至8800 RPM
总功耗降至无卸载方案的53%
9. 经济与能效
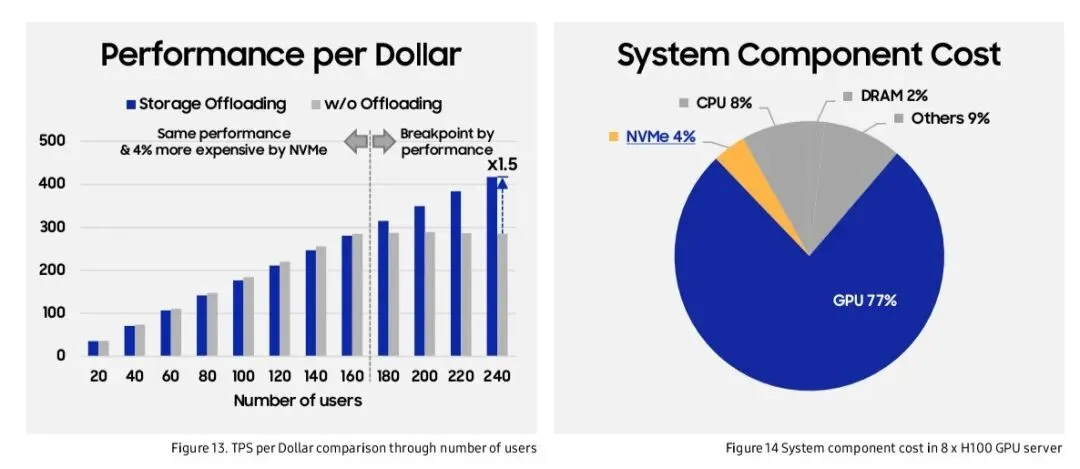
TPS per Dollar,在240用户时提升1.5倍
系统组件成本占比,GPU占绝大部分
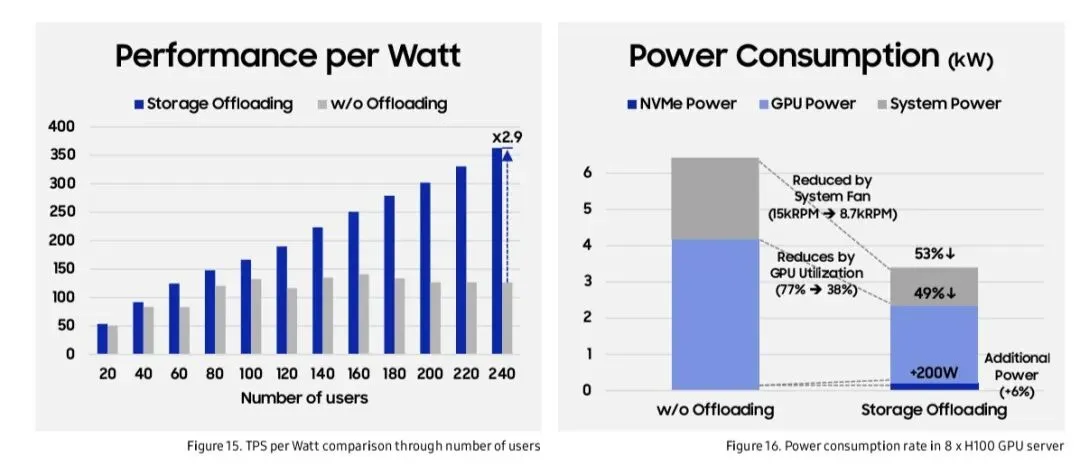
TPS per Watt,在240用户时提升2.9倍
功耗分布,GPU与风扇是主要能耗来源
五、数据指标总结
最大并发用户数: 240(卸载) vs 140(无卸载)
TPS提升: 1.5倍(240用户)
TTFT :<1秒(240用户)
功耗降低: 降至53%
风扇转速降低: 从15000 RPM → 8800 RPM
GPU利用率: 降至49%
性能/美元提升: 1.5倍(240用户)
性能/瓦提升: 2.9倍(240用户)
I/O读写比: 92%读 / 8%写
单进程顺序读占比: 78%
大块I/O占比: 96% > 1MB
峰值队列深度: 800
平均吞吐需求: 37 GB/s
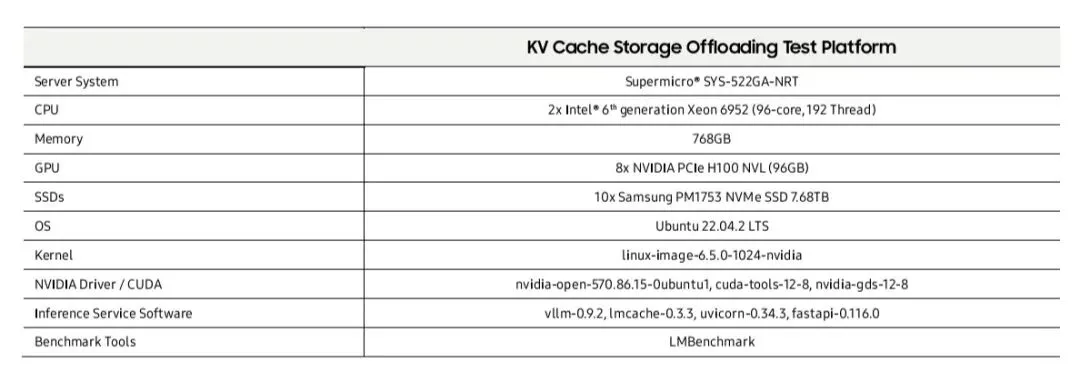
测试环境:
六、应用场景
1. Agentic AI系统:多轮推理、任务迁移、跨GPU调度
2. 长上下文LLM服务:如文档分析、法律合同、代码生成
3. 高并发推理服务:需要支持数千用户同时访问
4. 多租户GPU集群:通过KV Cache卸载提升资源利用率
5. 边缘与数据中心节能部署:降低功耗与散热成本
七、方向
1. KV Cache的智能预取与缓存替换策略
2. 跨节点共享存储架构下的KV Cache一致性
3. 存储设备与GPU之间的高速数据路径(如GDS)优化
4. KV Cache块大小与存储I/O粒度的协同设计
5. 能效优先的推理调度策略,结合存储卸载
八、总结:
- 量化了收益(1.5x TPS,2.9x 能效)
- I/O特征分析:多进程下的顺序与随机交织
