 夜雨聆风
夜雨聆风
题图摄于宁夏古长城
回顾 AI 狂飙的这三年,我们经历了两次“大迁徙”。
Token 成了这个时代的“原油”。 消耗量急剧上升,股价随之翻番,大家开始正经讨论起 “Token 经济”。
然而,Token 账单也成了用户心中挥之不去的阴影。很多重度用户都有一个共同的疑惑:我明明只是追问了一句,为什么计费跳得这么快?
真相是:在现有的 Transformer 推理机制下,你每发一条新消息,系统都要把之前的提示词、背景文档和工具定义等信息重新丢给模型“阅读”一遍。 几万甚至几十万 Token 的上下文,每轮对话都要重新全量计费。
这种“每次都要从头读起”的笨办法,是 Transformer 架构的固有代价。为了打破这个成本魔咒,业界祭出了关键的一招—— KV Cache 。
KV Cache 的原理:跳过重复计算
要理解 KV Caching,先得明白大模型推理时在干什么。
大语言模型主流技术都是基于 Transformer 算法,每处理一个 token,注意力机制都要为它计算两个矩阵:
Key (K):这个 token“代表什么“ Value (V):它被关注时“贡献了什么信息”
这两个矩阵在模型的每一层都要算一遍。对于一个 5000 token 的系统提示,就意味着 5000 × 层数 次矩阵运算。每次对话都从头算,既慢又贵。
KV Cache 做的事情很简单:把算好的 K/V 矩阵存到服务器的显存里。下次请求如果 prompt 的前缀完全一致,直接读取已有结果,跳过计算。这就是为什么缓存命中时延迟能降低 85%——不是网络快了,是根本没算。
有一点必须记住:缓存只做前缀匹配。开头哪怕改了一个 token,后面所有缓存全部失效。所以最佳实践始终是:把最稳定的内容放最前面(系统提示、工具定义、背景文档),动态内容(用户输入、时间戳)永远放最后。
两种缓存模式:显式 vs 隐式
基于 KV Caching,各家厂商在API/服务计费上实现了 Prompt Caching(提示词缓存),以减少计费和提升响应速度,主要分为两种流派:
隐式缓存(Implicit / Automatic Caching):系统自动判断,无需修改代码。只要prompt前缀一致且达到最小token阈值,服务端自动命中。开发者几乎零配置,但对命中与否没有控制权。OpenAI 是这种方式的典型代表。Anthropic最近也增加了隐式缓存。
显式缓存(Explicit Caching):开发者主动标记哪些内容需要缓存(如通过cache_control 断点),控制粒度高、折扣更大,但需要额外配置。Kimi支持此模式。
两种方式各有取舍:隐式省心但不确定,显式可靠但略复杂。
Anthropic Claude 和 Google Gemini 目前均同时支持两种完整模式:既可以通过显式标记 cache_control 断点精确控制缓存位置,也提供自动缓存让系统智能判断。此外,Google Gemini 还额外支持视频、音频等多模态文件缓存,这是其相较于其他平台较为突出的能力。
三大主流平台横向对比
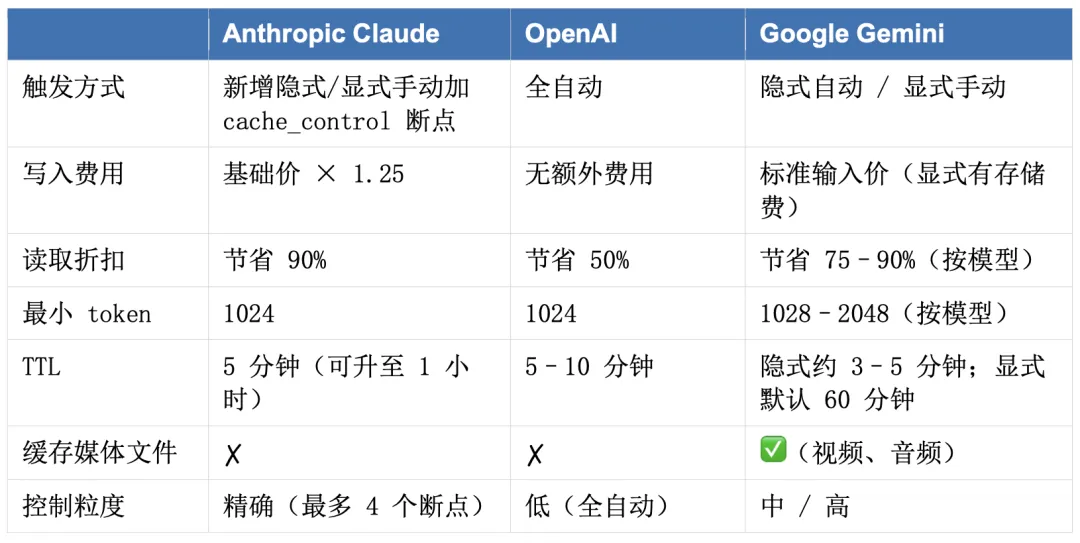
选型建议
想省心、零配置 → OpenAI 自动缓存 需要精确控制 + 最高折扣(90%)+ 复杂 RAG → Anthropic 显式缓存 要处理视频/音频/超长文档(百万 token) → Gemini 显式缓存 高频应用、不想付存储费 → Gemini 隐式缓存
五、在 OpenClaw 中配置各家缓存
0. 全局基础配置:防止时间戳破坏缓存
OpenClaw 默认会在系统提示词( System Prompt )中注入动态时间戳,这是缓存失效的头号杀手。因此,我们可以通过“时间戳圆整”技术,将系统提示词中原本精确到毫秒的动态时间按 10 分钟取整 。其核心原理是满足大模型缓存机制对“前缀完全一致”的苛刻要求 。
如果不进行圆整,每一秒变动的时间戳都会破坏 Prompt 前缀,导致模型将其视为全新请求 。开启该配置后,10 分钟内的请求前缀保持恒定,从而稳定触发 OpenAI、Gemini 或 Claude 的缓存,不仅能实现“秒回”级的响应,还能节省高达 90% 的费用 。
具体配置:

1. Anthropic Claude —— 控制最精确
OpenClaw 对 Claude 的缓存支持最完善,通过 cacheRetention 参数直接控制:

•mode: "cache-ttl" 是最关键的开关,会在缓存失效前自动修剪上下文。
•cacheRetention 可选 none | short(5 分钟)| long(1 小时)。
•keepLastAssistants: 3 保留最近 3 轮对话,维持短期记忆连贯性。
进阶技巧:心跳保温(Heartbeat)
担心长时间不对话导致云端缓存被释放?配置心跳包:

心跳建议用最便宜的模型(如 Haiku),只要能触碰到相同的缓存前缀即可保温。
2. Google Gemini —— 两种模式,按场景选
短上下文(< 32k tokens):隐式缓存,无需额外配置,只要保证 roundTimestampMinutes 已开启即可。
长上下文 / 多模态文件:显式缓存配置如下:

Gemini 是唯一能缓存视频、音频 token 的平台。如果你需要对同一个小时级视频反复提问,强烈建议开启显式缓存——媒体文件的 token 量极大,缓存命中后成本接近于零。
3. OpenAI(GPT-4o / GPT-5 系列 / Codex)—— 自动缓存,持续进化
OpenAI 的缓存机制始终是全自动的——无需任何配置开关,无额外费用。但随着模型系列从 GPT-4o 演进到 GPT-5.4,缓存能力也在持续增强。
基础机制:128 token 递增粒度
所有 OpenAI 模型的缓存均以 1024 token 为起点、128 token 为一格递增命中。也就是说 cached_tokens 的值永远是 1024、1152、1280… 这个序列中的某个数,多出来的零头照常收费。缓存命中可节省约 50% 的输入 token 费用,延迟最多降低 80%。
OpenClaw 唯一需要做的是开启全局时间戳圆整,并遵守结构原则:不变量在前(系统提示、Tool 定义、背景文档),动态内容在后(当前用户输入)。配置方法见前文。
GPT-5.1 引入了扩展缓存(Extended Prompt Caching),缓存保留时间最长可达 24 小时,远超之前 5~10 分钟的默认 TTL。这对长时间运行的多轮对话、编程会话或知识检索工作流尤为有利。
GPT-5.4 引入了 Tool Search 机制,从根本上解决了工具定义膨胀破坏缓存的问题。过去,当 Agent 挂载大量工具时,所有工具定义会在请求开头全量注入,轻则增加数万 token,重则导致每次请求前缀不稳定、缓存频繁失效。
在 OpenClaw 中,如果你的 Agent 挂载了多个 Skill,升级到支持 GPT-5.4 的版本后,工具定义膨胀问题会自动得到缓解,无需额外配置。
4. Kimi(Moonshot AI)—— 工具定义缓存效果极佳
Kimi 采用【命中即打折】的自动前缀缓存模式,对重复的系统指令特别敏感。如果 OpenClaw 挂载了大量 Skill(插件),Kimi 会自动缓存这些工具定义,二次响应速度明显提升。

需要对超长文档使用显式缓存时,通过 extra_body 透传 cache_id:

5. GLM(智谱 AI)—— 隐式自动,稳定前缀是关键
GLM 系列采用隐式自动缓存,无需手动设置缓存断点。系统识别到完全一致的上下文前缀时自动复用计算结果。日常对话配置:

处理超长文档或代码库时,使用显式缓存模式(GLM 部分高级参数需通过 extra_body 字段透传):

6. MiniMax —— 512 token 起自动触发
MiniMax 的缓存在输入超过 512 token 时自动触发,是几家中阈值最低的。前缀匹配顺序为:工具定义 → 系统提示词 → 历史对话。

建议将静态的工具函数定义、分析框架说明放在 prompt 最前面,命中率最高。
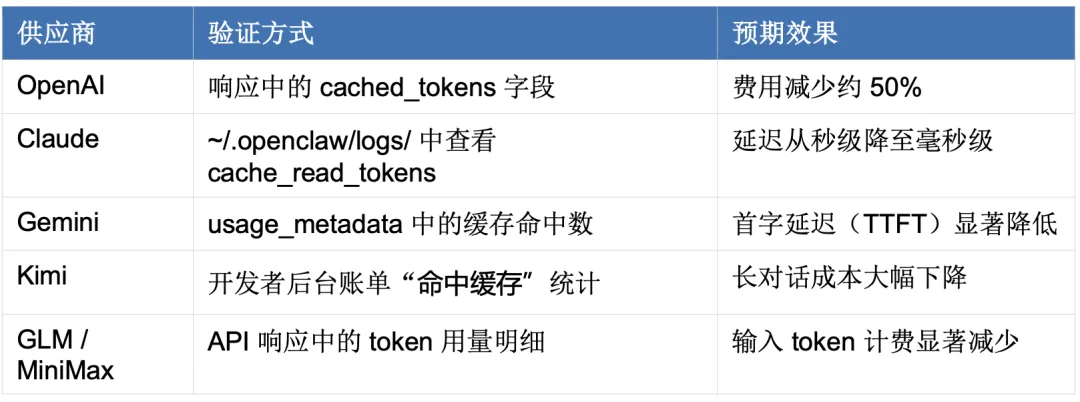
验证缓存是否生效
总结
KV Cache 本质上是一种「记忆复用」机制:把算过的东西存起来,下次直接拿,不重算。这看起来朴素,但在大模型推理里却能带来 90% 的成本节省和 85% 的延迟降低。
在 OpenClaw 中,核心配置原则就三条:
•固定时间戳:roundTimestampMinutes 是所有模型的通用前提
•结构优先:静态内容永远在前,动态内容永远在后
•按场景选模式:短对话用隐式省事,长文档用显式可靠
配置一次,长期受益。
欢迎关注 亨利笔记, 👍 点赞 | ⭐ 收藏 | ↗️ 转发。欢迎评论区聊聊你的看法。
近期文章:
龙虾政策直击:OpenClaw 爆火背后,OPC “超级个体”时代真的来了
别再只会写提示词了!MCP+Skills这两大杀器,正在终结“AI智障”时代!
本公众号聚焦人工智能,云原生和区块链等技术原理,请立即关注亨利笔记( henglibiji ),以免错过更新。
